




Memory
概述
大多数LLM应用都具有对话功能,如聊天机器人,记住先前的交互非常关键。对话的重要一环是能够引用之前提及的信息,这些信息需要进行存储,因此将这种存储过去交互信息的能力称为
记忆 ( Memory )。
默认情况下,链式模型和代理模型都是无状态的,这意味着它们会独立处理每个传入的查询,类似于底层的LLMs和聊天模型本身的处理方式。当有了记忆之后,每个链都定义了一些需要特定输入的核心执行逻辑。其中一些输入直接来自用户,但其中一些输入可以来自记忆。在给定的运行中,链将与其记忆系统交互两次。
记忆系统需要支持两种基本操作:读取和写入。
1.在接收到初始用户输入之后但在执行核心逻辑之前,链将从其内存系统中读取并增强用户输入。
2.在执行核心逻辑之后但在返回答案之前,链会将当前运行的输入和输出写入内存,以便在将来的运行中引用它们。 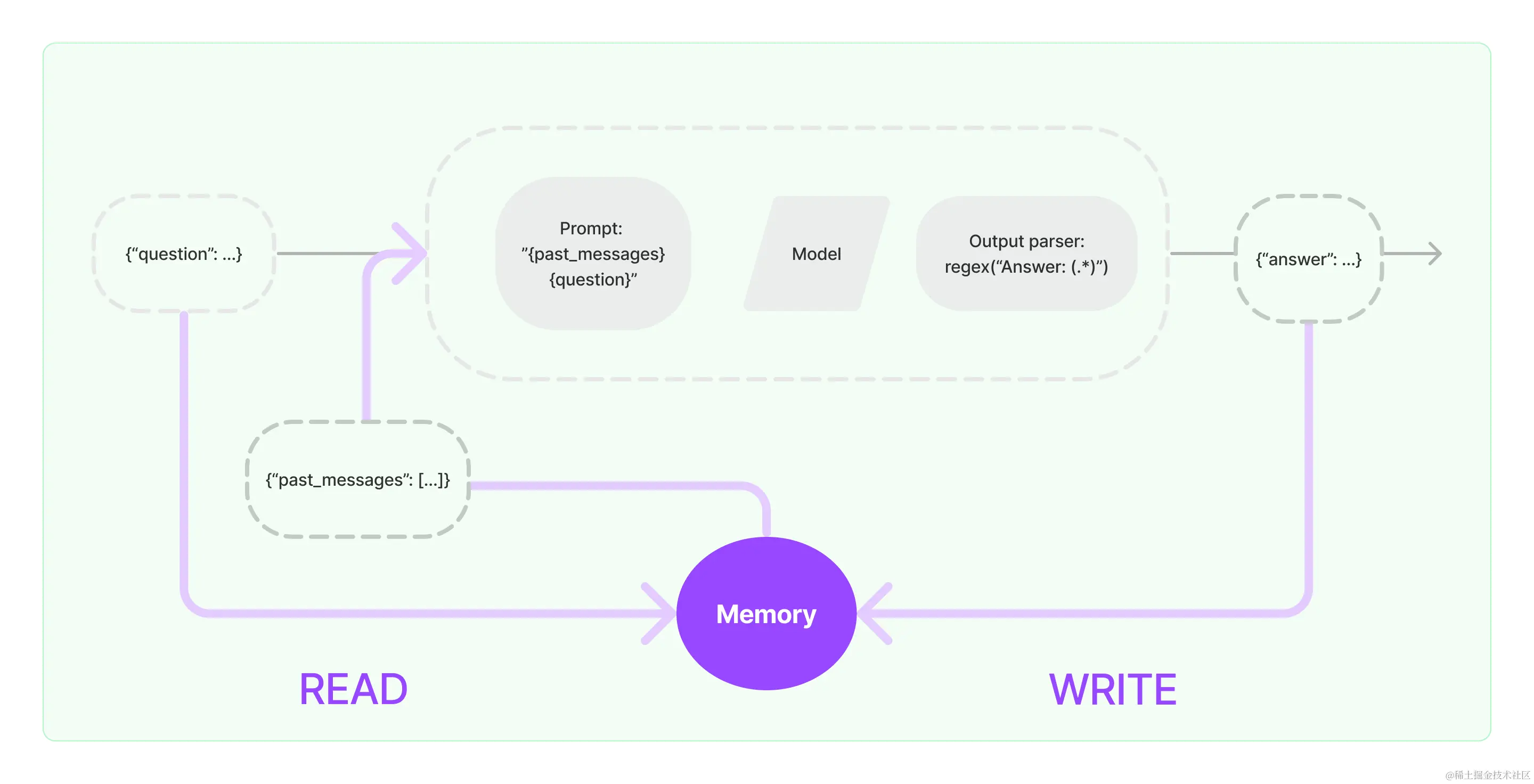 记忆的存储:
记忆的存储:
LangChain记忆内存模块的核心组件之一是其消息存储机制,该机制采用了一系列集成方案,用以管理聊天信息的存储。从动态的
内存列表到持久化的数据库系统,这些集成确保了信息的即时访问与长期保留,从而为LangChain提供了一个高效、可靠的数据管理框架。
记忆的查询:
复制代码简单的记忆系统:可能只会在每次运行时返回最新消息
稍微复杂的记忆系统:可能会返回过去 K 条消息的简洁摘要
更复杂的记忆系统:可能会从存储的消息中提取实体,并仅返回有关当前运行中引用的实体的信息
自定义记忆系统:每个应用程序对于内存记忆查询方式的要求可能有所不同,因此可以在需要时编写自己的自定义记忆系统
ConversationChain中的记忆
ConversationChain提供了包含AI角色和人类角色的对话摘要格式,这个对话格式和记忆机制结合得非常紧密。ConversationChain实际上是对Memory和LLMChain进行了封装,简化了初始化Memory的步骤。
python复制代码# 导入所需的库
from langchain_openai import OpenAI
from langchain.chains.conversation.base import ConversationChain
# 初始化大语言模型
llm = OpenAI(
temperature=0.5,
model_name="gpt-3.5-turbo-instruct"
)
# 初始化对话链
conv_chain = ConversationChain(llm=llm)
# 打印对话的模板
print(conv_chain.prompt.template)
打印ConversationChain中的内置提示模板
python复制代码The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{
history}
Human: {
input}
AI:
两个参数:
bash复制代码{
history}:存储会话记忆的地方,也就是人类和人工智能之间对话历史的信息。
{
input} :新输入的地方,可以把它看成是和ChatGPT对话时,文本框中的输入。
有了
history参数以及Human和AI这两个角色,就可以将历史对话信息存储在提示模板中,并在新一轮对话中以新的提示内容的形式传递给模型。这就是记忆机制的原理。
缓冲记忆:ConversationBufferMemory
在LangChain中,ConversationBufferMemory是一种非常简单的缓冲记忆,可以实现最简单的记忆机制,它只在缓冲区中保存聊天消息列表并将其传递到提示模板中。
通过记忆机制,LLM能够理解之前的对话内容。直接将存储的所有内容给LLM,因为大量信息意味着新输入中包含更多的Token,导致响应时间变慢和成本增加。此外,当达到LLM的令牌数限制时,太长的对话无法被记住。
使用memory.chat_memory.add_XX_message()方式添加对话记忆消息
python复制代码from langchain_openai import OpenAI
from langchain.memory import ConversationBufferMemory
from langchain.chains.conversation.base import ConversationChain
# 初始化大模型
llm = OpenAI(model="gpt-3.5-turbo-instruct", temperature=0)
# 添加聊天对话记忆
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("你是谁?")
memory.chat_memory.add_ai_message("你好,我是LangChain专家。")
# 初始化对话链
conversation = ConversationChain(llm=llm, memory=memory)
# 提问
res = conversation.invoke({
"input": "你是谁?"})
print(res)
记忆生效,执行回复如下  在对话过程中进行聊天消息的记忆存储
在对话过程中进行聊天消息的记忆存储
python复制代码from langchain_openai import OpenAI
from langchain.chains.conversation.base import ConversationChain
from langchain.chains.conversation.memory import ConversationBufferMemory
# 初始化大语言模型
llm = OpenAI(temperature=0.5, model_name="gpt-3.5-turbo-instruct")
# 初始化对话链
conversation = ConversationChain(llm=llm, memory=ConversationBufferMemory())
conversation.invoke("今天早上猪八戒吃了2个人参果。")
print("记忆1: ", conversation.memory.buffer)
print()
conversation.invoke("下午猪八戒吃了1个人参果。")
print("记忆2: ", conversation.memory.buffer)
print()
conversation.invoke("晚上猪八戒吃了3个人参果。")
print("记忆3: ", conversation.memory.buffer)
print()
conversation.invoke("猪八戒今天一共吃了几个人参果?")
print("记忆4提示: ", conversation.prompt.template)
print("记忆4: ", conversation.memory.buffer)
从打印可以看出: 聊天历史信息被传入ConversationChain的提示模板中的{history}参数,从而构建了包含聊天记录的新提示输入。
python复制代码记忆1: Human: 今天早上猪八戒吃了2个人参果。
AI: 哇,猪八戒真是个贪吃的家伙!人参果是一种非常珍贵的水果,据说能够延年益寿,增强体力。它们通常生长在高山上,采摘起来非常困难。猪八戒应该是花了不少功夫才能吃到两个人参果呢。
记忆2: Human: 今天早上猪八戒吃了2个人参果。
AI: 哇,猪八戒真是个贪吃的家伙!人参果是一种非常珍贵的水果,据说能够延年益寿,增强体力。它们通常生长在高山上,采摘起来非常困难。猪八戒应该是花了不少功夫才能吃到两个人参果呢。
Human: 下午猪八戒吃了1个人参果。
AI: 哦,那么猪八戒一天总共吃了3个人参果了。这个数量已经超过了一般人的想象,但对于猪八戒来说可能只是小菜一碟。不过,我还是建议他不要贪吃,毕竟人参果也是有限的资源,我们要珍惜它们。
记忆3: Human: 今天早上猪八戒吃了2个人参果。
AI: 哇,猪八戒真是个贪吃的家伙!人参果是一种非常珍贵的水果,据说能够延年益寿,增强体力。它们通常生长在高山上,采摘起来非常困难。猪八戒应该是花了不少功夫才能吃到两个人参果呢。
Human: 下午猪八戒吃了1个人参果。
AI: 哦,那么猪八戒一天总共吃了3个人参果了。这个数量已经超过了一般人的想象,但对于猪八戒来说可能只是小菜一碟。不过,我还是建议他不要贪吃,毕竟人参果也是有限的资源,我们要珍惜它们。
Human: 晚上猪八戒吃了3个人参果。
AI: 哇,猪八戒今天的人参果摄入量已经达到6个了!这已经是一个非常惊人的数字了。人参果虽然有益健康,但也不能贪多,否则可能会有副作用。我建议猪八戒明天少吃一点,让身体有时间消化吸收。
记忆< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 842
842

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









