








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
数仓分层结构一般如下:
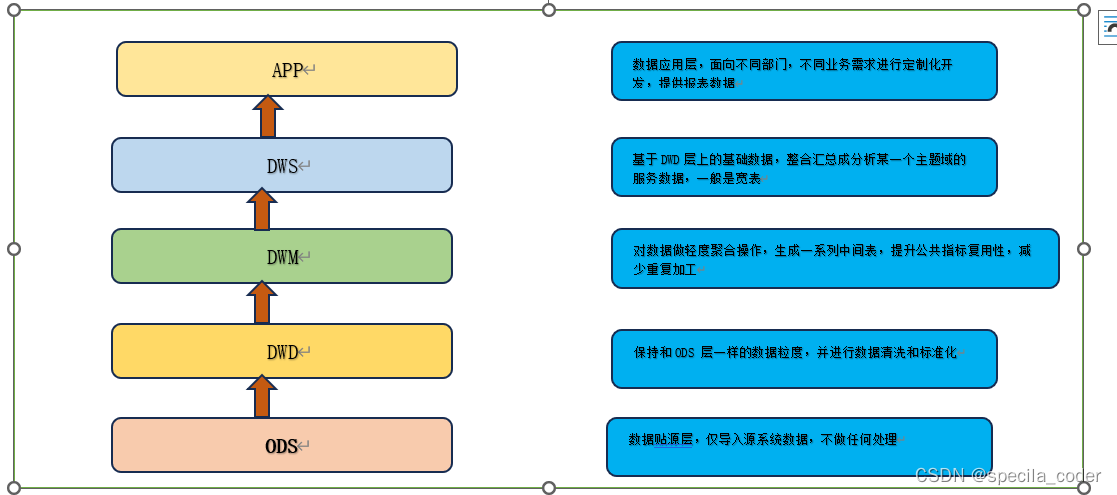
3.2 数仓分层详细介绍
3.2.1 贴源层:ODS(Operational Data Store)
ODS 层,是最接近数据源中数据的一层,为了考虑后续可能需要追溯数据问题,因此对于这一层就不建议做过多的数据清洗工作,原封不动地接入原始数据即可,至于数据的去噪、去重、异常值处理等过程可以放在后面的DWD 层来做。
3.2.2 数据仓库层:DW(Data Warehouse)
数据仓库层是我们在做数据仓库时要核心设计的一层,在这里,从ODS 层中获得的数据按照主题建立各种数据模型。DW 层又细分为DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和DWS(Data WareHouse Servce) 层。
3.2.2.1 数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS 层一样的数据粒度,并且提供一定的数据质量保证。DWD 层要做的就是将数据清理、整合、规范化、脏数据、垃圾数据、规范不一致的、状态定义不一致的命名不规范的数据都会被处理。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化至事实表中,减少事实表和维表的关联。另外,在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性。
3.2.2.2 数据中间层:DWM(Data WareHouse Middle)
该层会在DWD 层的数据基础上,数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。直观来讲,就是对通用的核心维度进行聚合操作,算出相应的统计指标。在实际计算中,如果直接从DWD 或者ODS 计算出宽表的统计指标,会存在计算量太大并且维度太少的问题,因此一般的做法是,在DWM 层先计算出多个小的中间表,然后再拼接成一张DWS 的宽表。由于宽和窄的界限不易界定,也可去掉DW
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1659
1659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









