







简介
在机器学习中,评估模型的性能是至关重要的一步。特别是在二分类问题中,我们需要使用各种指标来评估模型的准确性、召回率、精确度等。本文将先介绍二分类模型评估的相关知识点,包括常用的评估指标、混淆矩阵、ROC曲线和AUC等内容,在此之后将使用代码来演示如何利用Skicit-learn中的相关模块来完成这一系列的任务,最后我会将本文涉及到的数据集放在结尾链接中,有需要则自取,那么让我们的学习之路开始吧!
正文
二分类问题简介
在机器学习中,二分类是一种常见的问题类型,其中目标是将数据分为两个类别。例如,判断一封电子邮件是垃圾邮件还是非垃圾邮件、预测病人是否患有某种疾病等都是二分类问题的示例。而我们的二分类模型就是给机器一堆的有关于此类的数据集,对它进行训练,最后让它预测是正类或负类。那么机器是怎么对样本进行训练的呢?
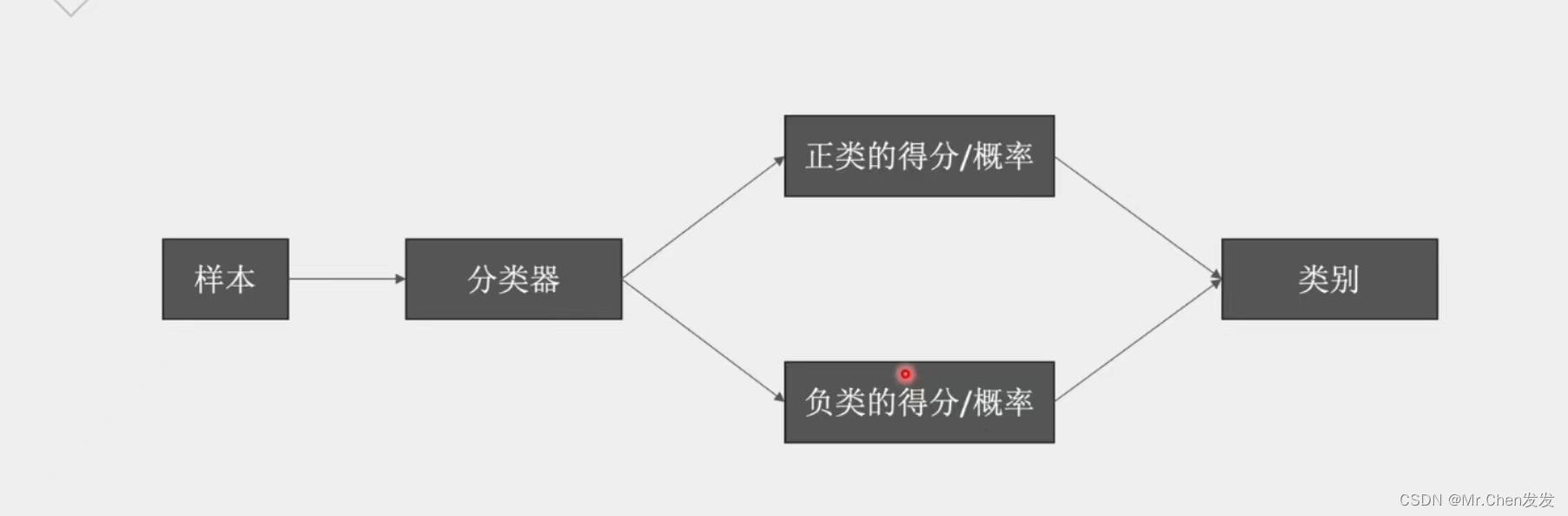
如图所示,机器会将样本分为正类和负类,并给每个样本一个得分值,然后将正类和负类的得分值划分在一个范围内,这样就可以通过得分值来预测正类和父类的概率,一旦概率大于0.5,机器就会预测为对应概率的类型,接下来我们就需要根据预测出来的结果和实际的结果进行对比,然后对模型进行评估,那么在我们的二分类模型中的评估指标有哪些呢?
在说评估指标之前,我们得先学习一个知识点:
混淆矩阵
混淆矩阵是一个二维矩阵,用于展示模型预测结果与真实标签之间的对应关系。它包含了四种情况:真正例(True Positive, TP)、假正例(False Positive, FP)、真反例(True Negative, TN)、假反例(False Negative, FN)。混淆矩阵如下所示:

其中,TP表示真正例(True Positive)、FN表示假反例(False Negative)、FP表示假正例(False Positive)、TN表示真反例(True Negative)。
在清楚了这个知识点后,我们再来说我们的评估指标
评估指标
-
准确度(Accuracy):准确度是指模型预测正确的样本数占总样本数的比例,计算公式为

-
精确度(Precision):精确度指的是模型预测为正例的样本中,真正为正例的比例,即
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









