







机器学习吴恩达第二模块笔记
第二模块:神经网络(深度学习算法)以及决策树
第一周:神经网络
1.2,神经元和大脑
对神经网络历史的认识
Neural networks:神经网络
algorithms:算法 mimic:模仿 resurgence:复兴
起源:试图模仿大脑的算法
在20世纪80年代和90年代初被使用
在20世纪90年代末失宠
2005年左右重新复兴
speech:语音 images:图像 text(NLP):文本(自然语言处理)
在大脑中的神经元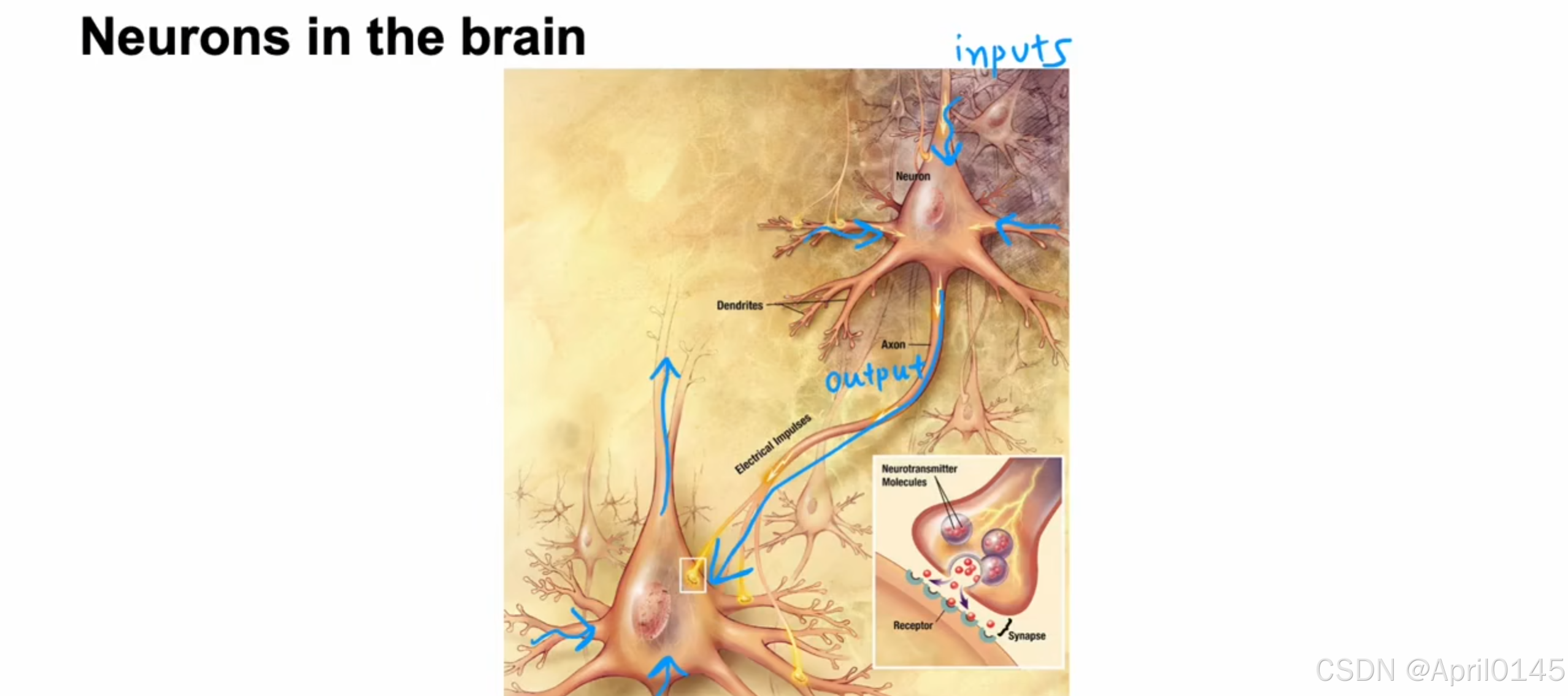
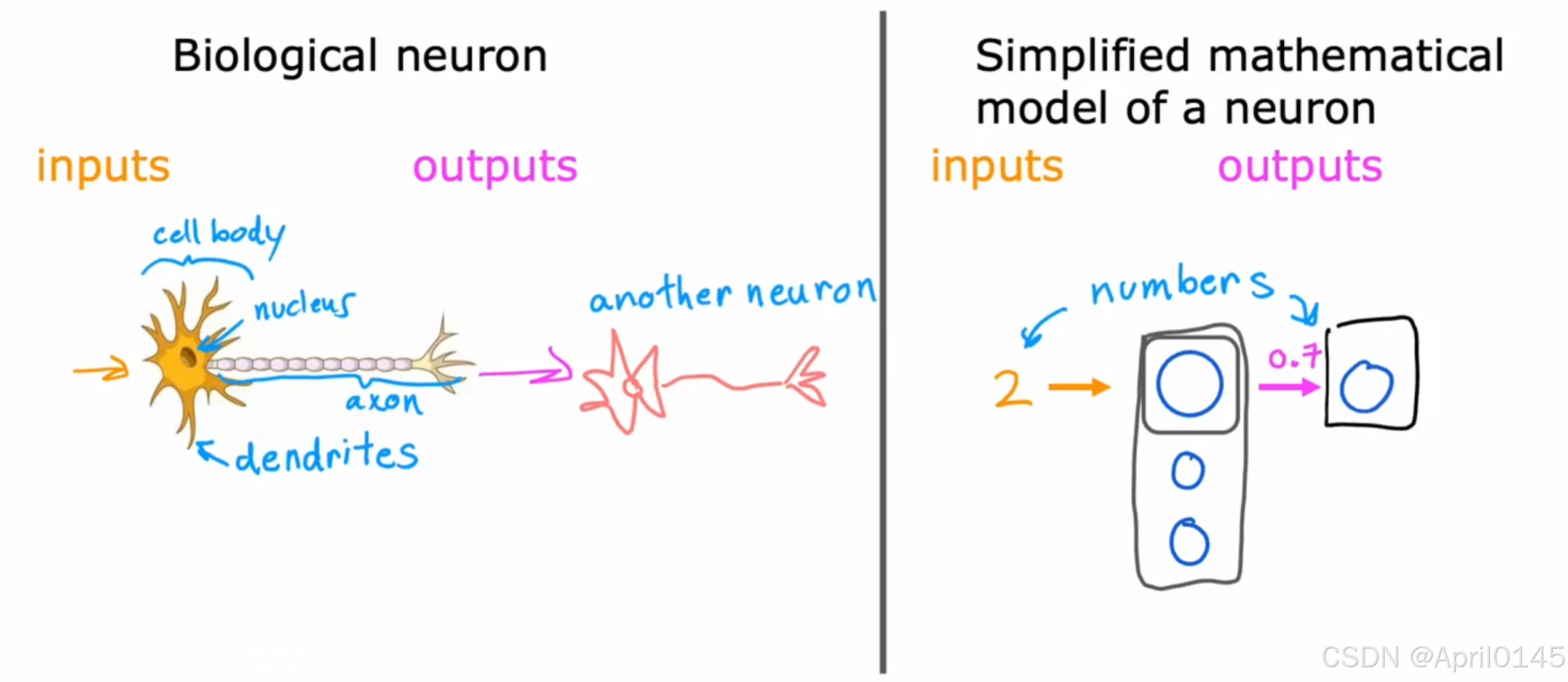
neurons:神经元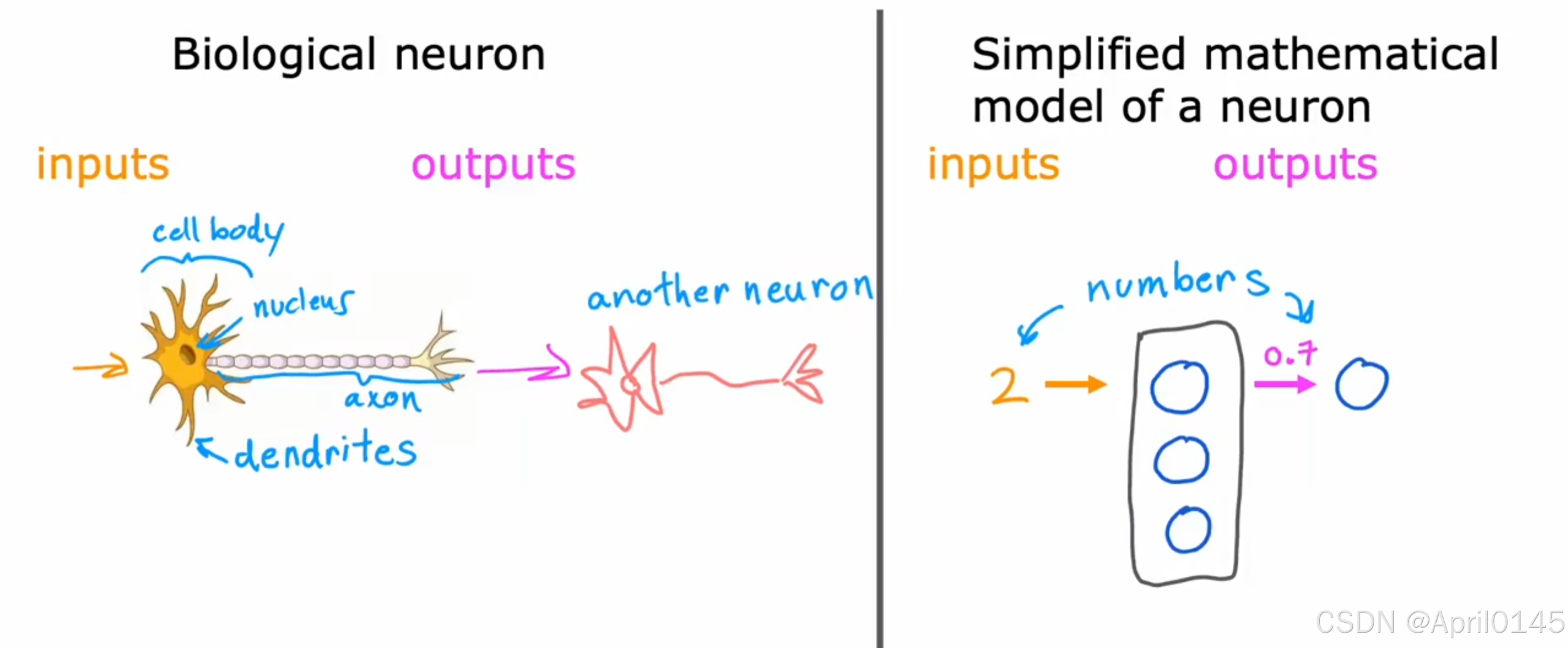
biological neuron:生物神经元 simplified mathematical model of a neuron:神经元的简化数学模型
cell body:细胞体 nucleus:细胞核 dendrites:树突 axon:轴突
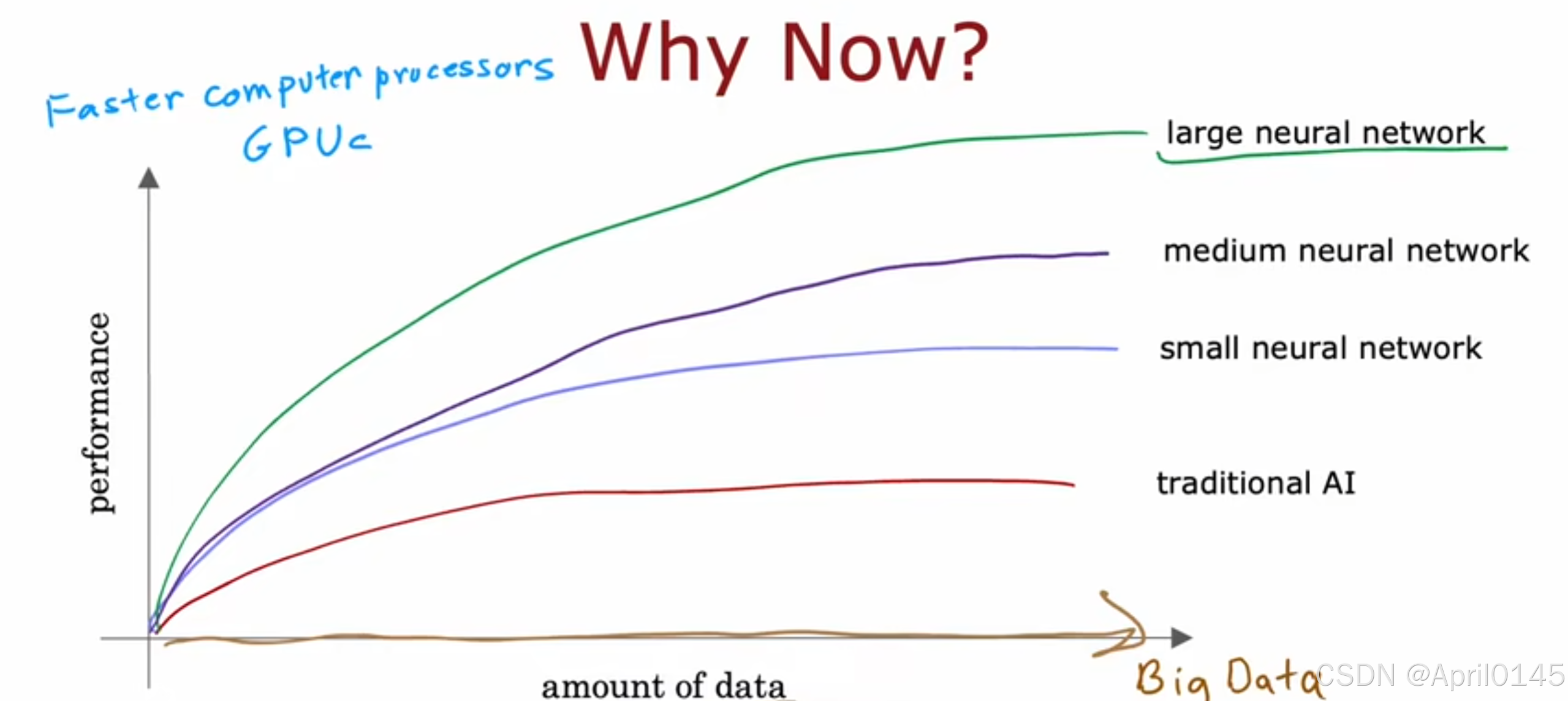
为什么神经网络在现在兴起 performance:高性能的 processors:处理器
1,数据量的增加
2,更快的计算机处理器
1.3,需求预测(神经网络)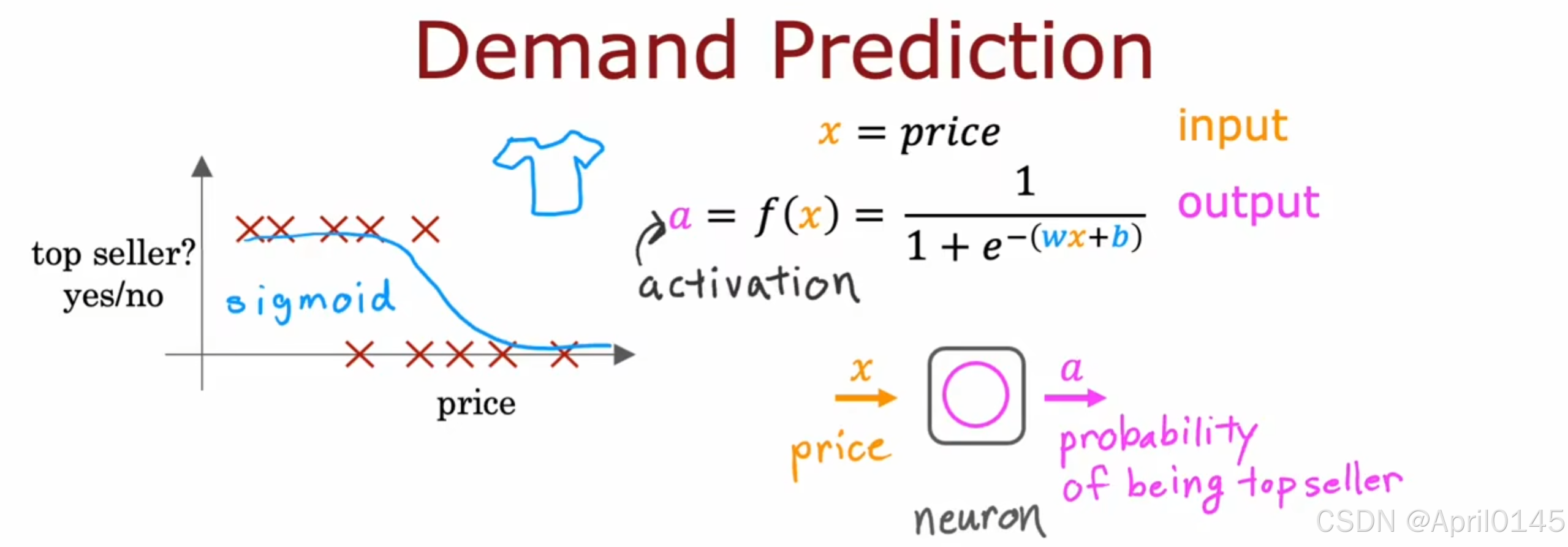
demand prediction:需求预测 activation:激活
probability of being to seller:成为畅销商品的可能性
通过价格预测该商品是否能成为畅销商品
x=price 作为输入
a=f(x) 作为逻辑回归算法的输出
a也被称为激活,它指的是一个神经元向下游其它神经元发送的一个高的输出
逻辑回归算法可以视为大脑中单个神经元非常简化的模型
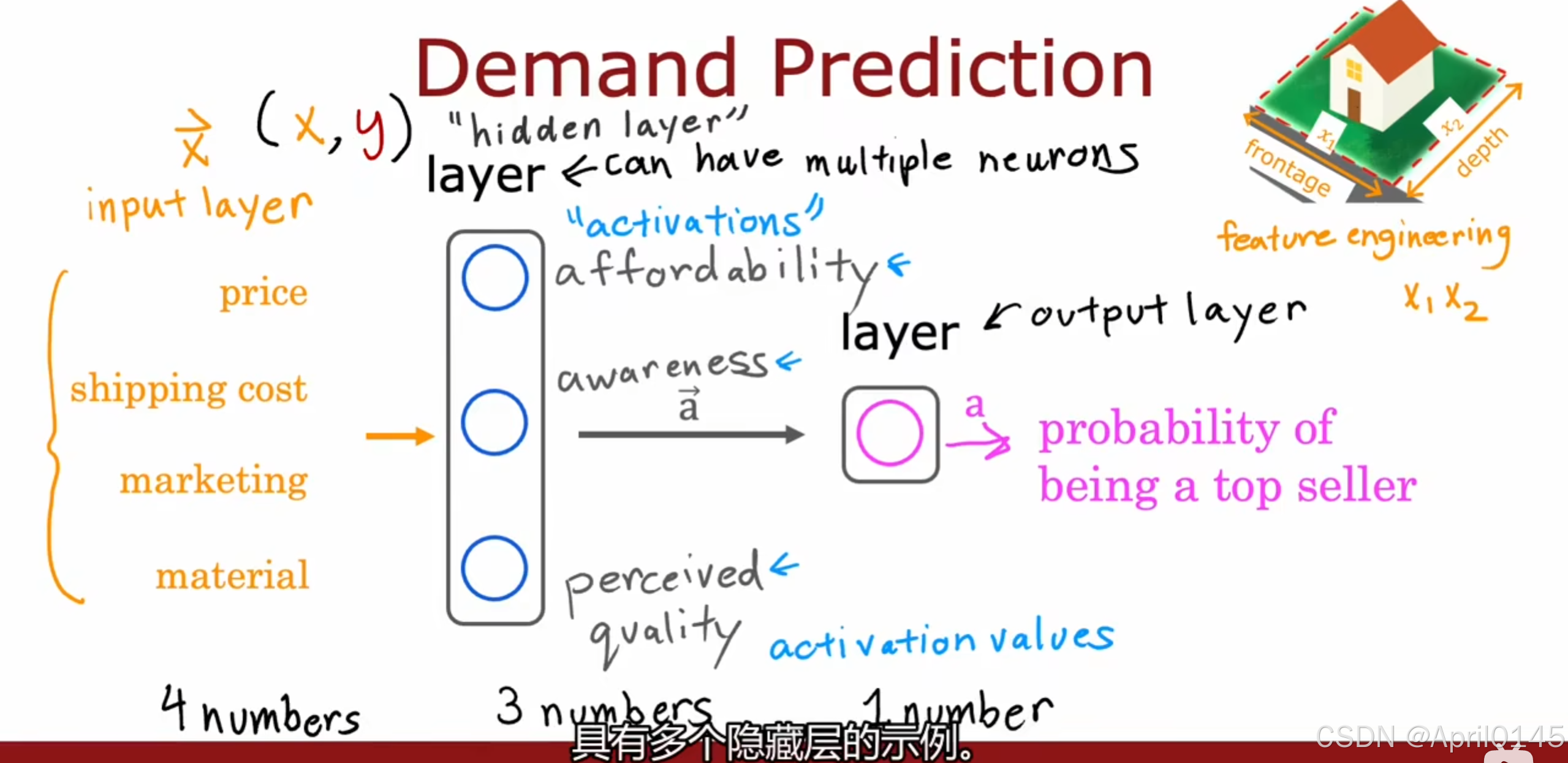
input layer:输入层
hidden layer:隐藏层,可以有多个神经元
output layer:输出层
price:价格 shipping cost:运费 marketing:市场营销 material:材料
afford ability:负担能力 awareness:知名度 perceived quality:品质认可度
隐藏层将输入层的4个值输出为3个激活值,输出层将隐藏层的3个输入值输出为一个激活值
1,神经网络在实践中实现特定层中每个神经元的方式:
比如中间这一层,它的每个神经元都可以访问上一层中的每一个值
2,在前面房价预测问题中,我们必需进行手动特征工程已获得更好的特征,但
在神经网络中不需要手动设计特征,虽然在前面我们决定了负担能力,知名度,品质认可度
但神经网络真正好的特性之一是:从数据中训练它时无需明确决定要做什么,神经网络能够自行决定
它想在这个隐藏层中使用的特征是什么
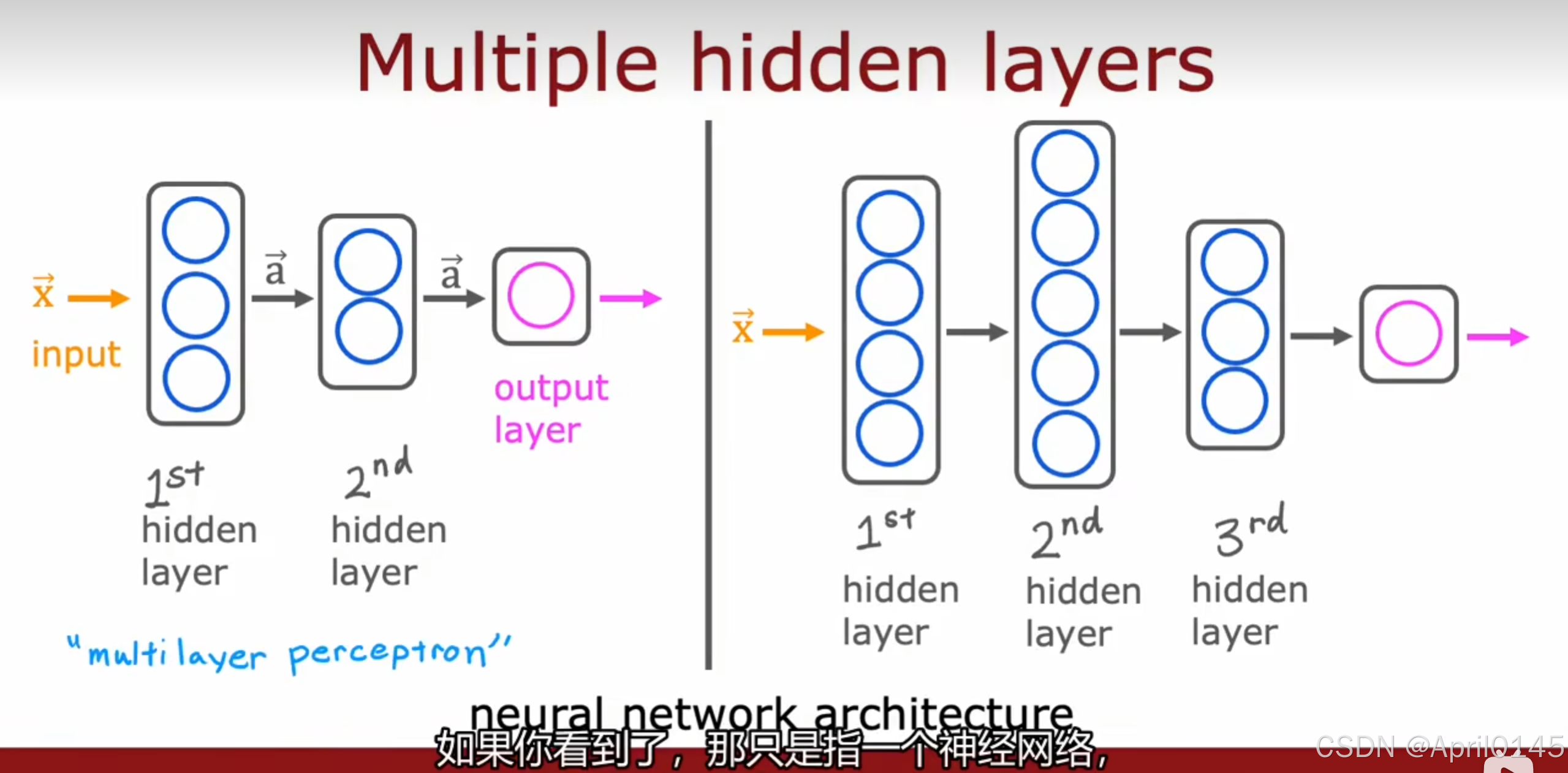
multiple:多个 perception:感知 architecture:架构
multi layer perception:多层感知器(神经网络)
neural network architecture:神经网络架构
1.4,神经网络举例:图像感知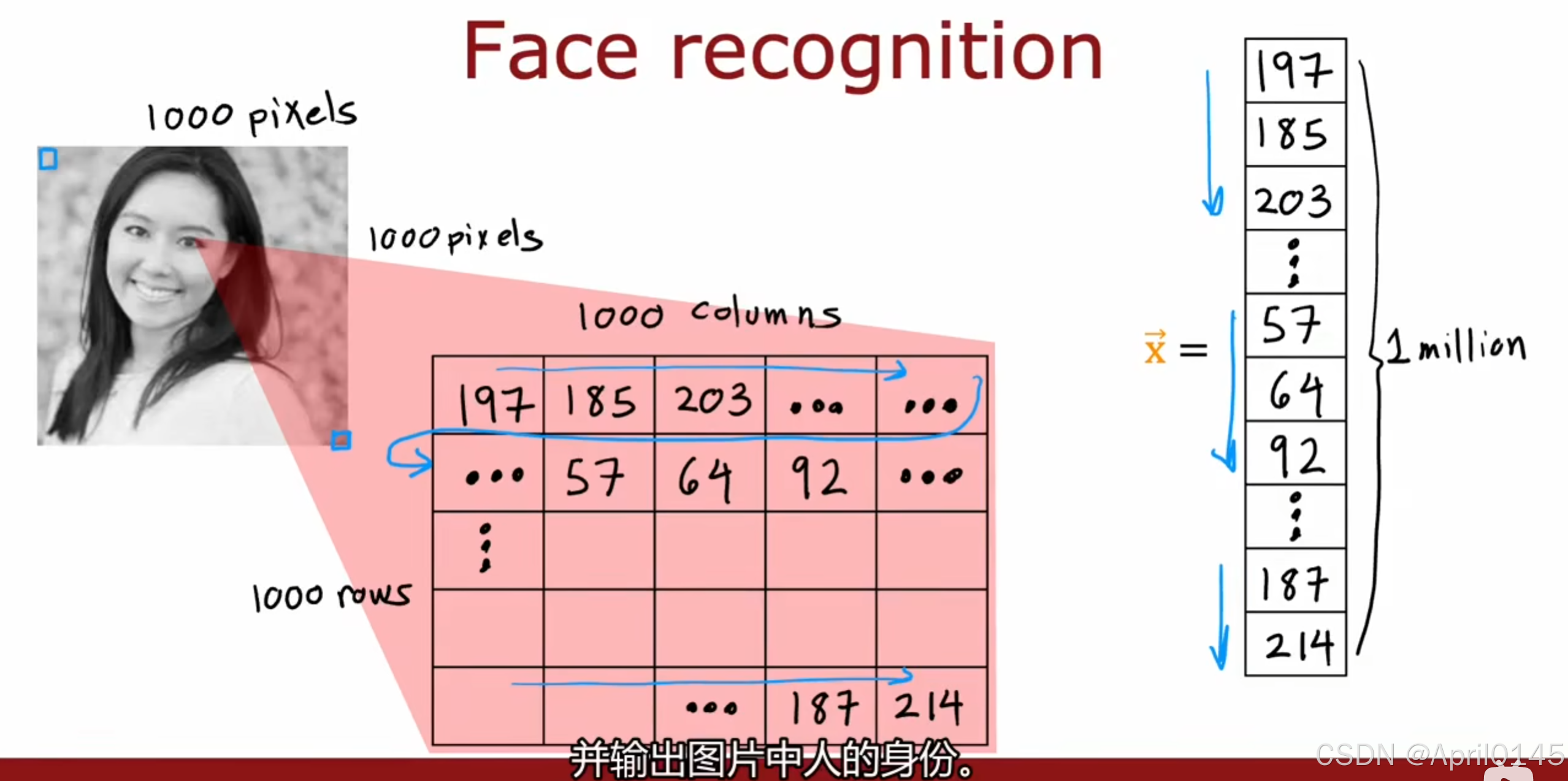
recognition:识别 pixels:像素
输入具有1百万像素的图片,输出图片中人的身份
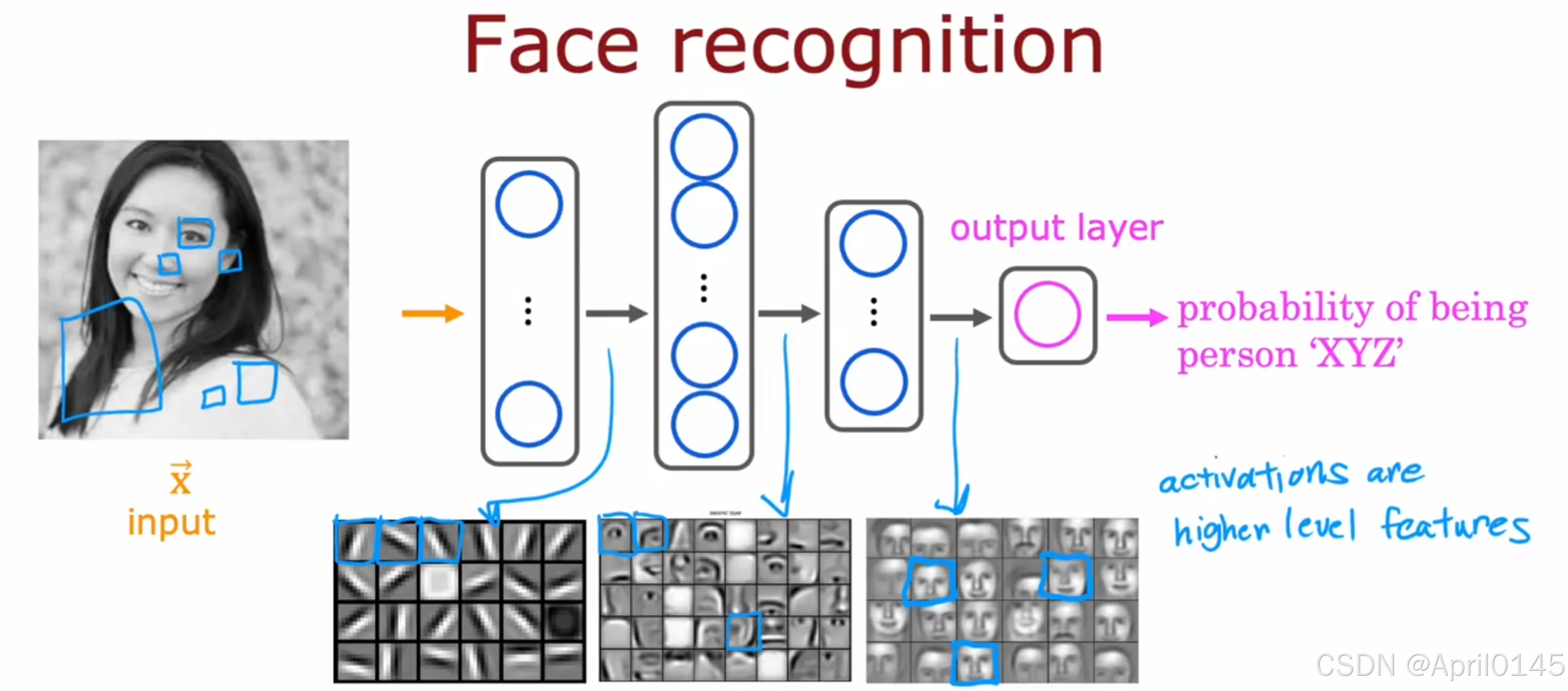
第一个隐藏层输出一些短边
第二个隐藏层输出一些面部特征
第三个隐藏层输出整个面部
activations are higher level features:激活更高水平的特征
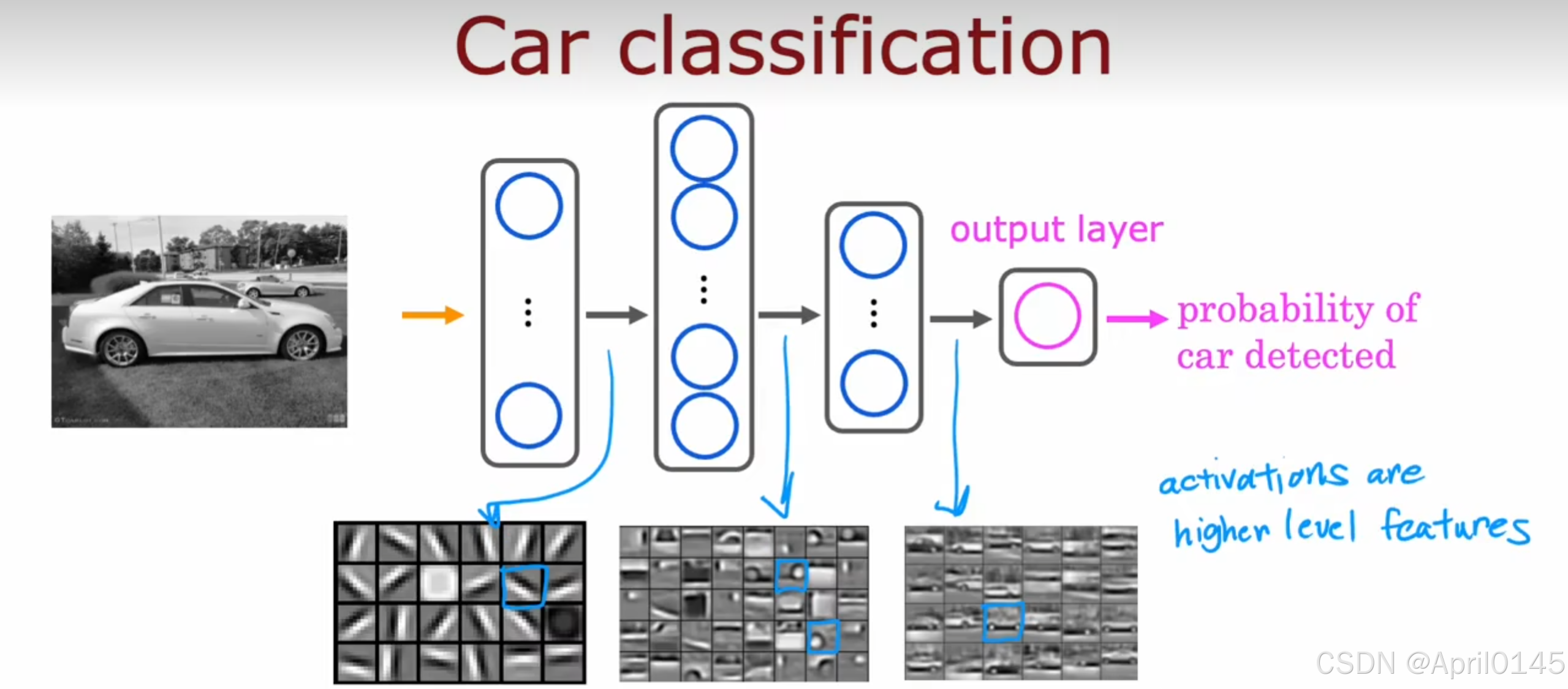
classification:分类 detected:检测
probability of car detected:检测到汽车的可能性
2.1,神经网络层的工作原理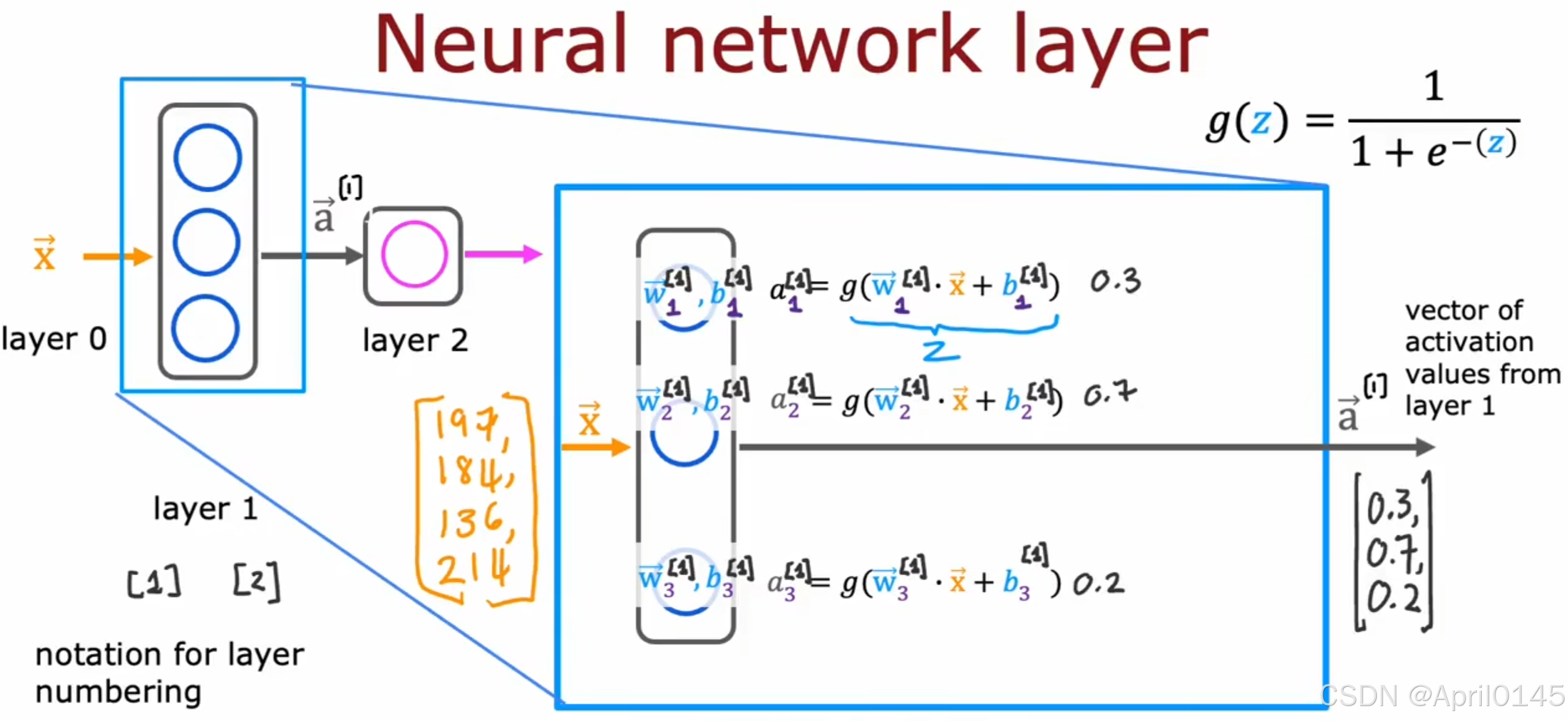
notation:符号 numbering:编号
单个神经元—>单层神经网络—>多层神经网络
上标[1]表示激活值的向量来自第一层
下标1,2,3表示该层中的第一个,第二个,第三个神经元
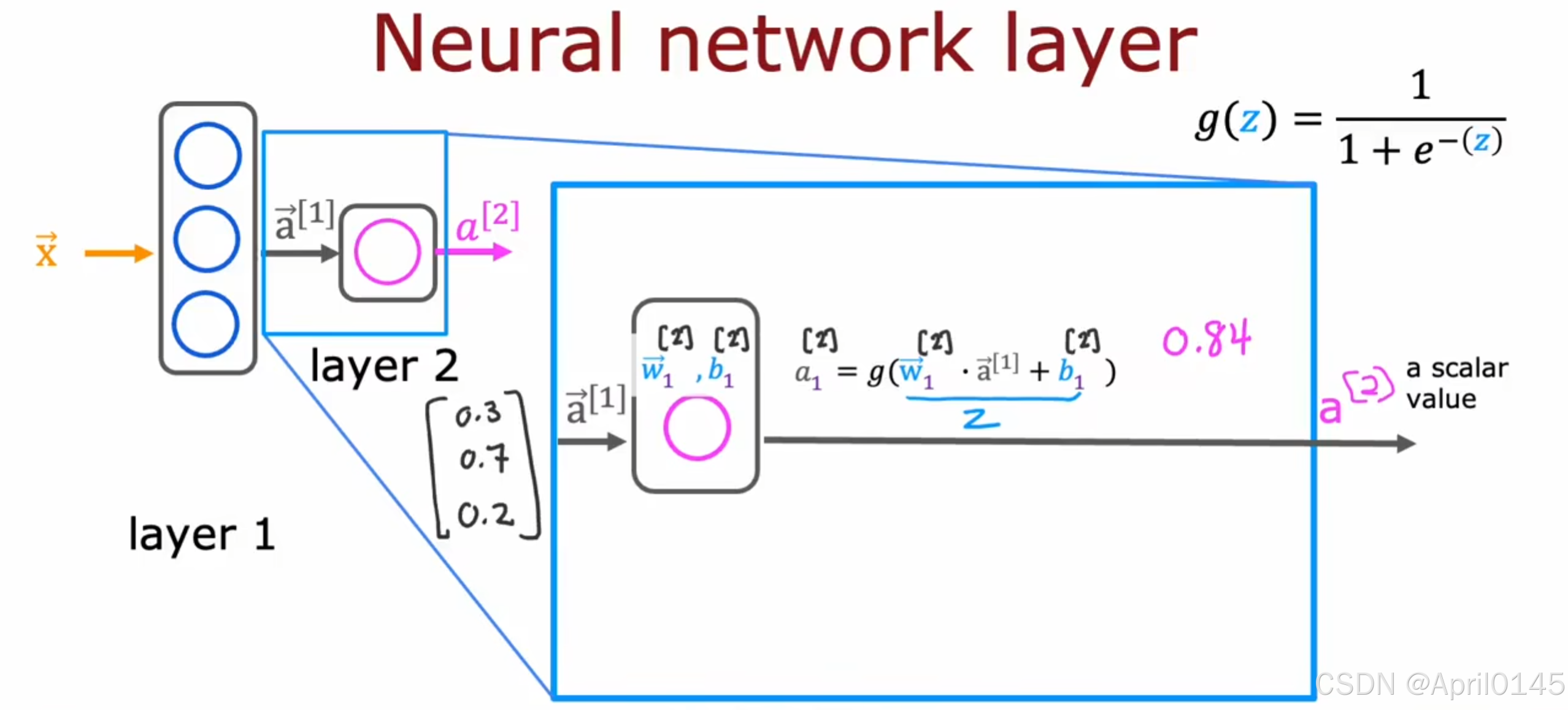
a scalar value:一个标量值
注意这里的向量a[1]
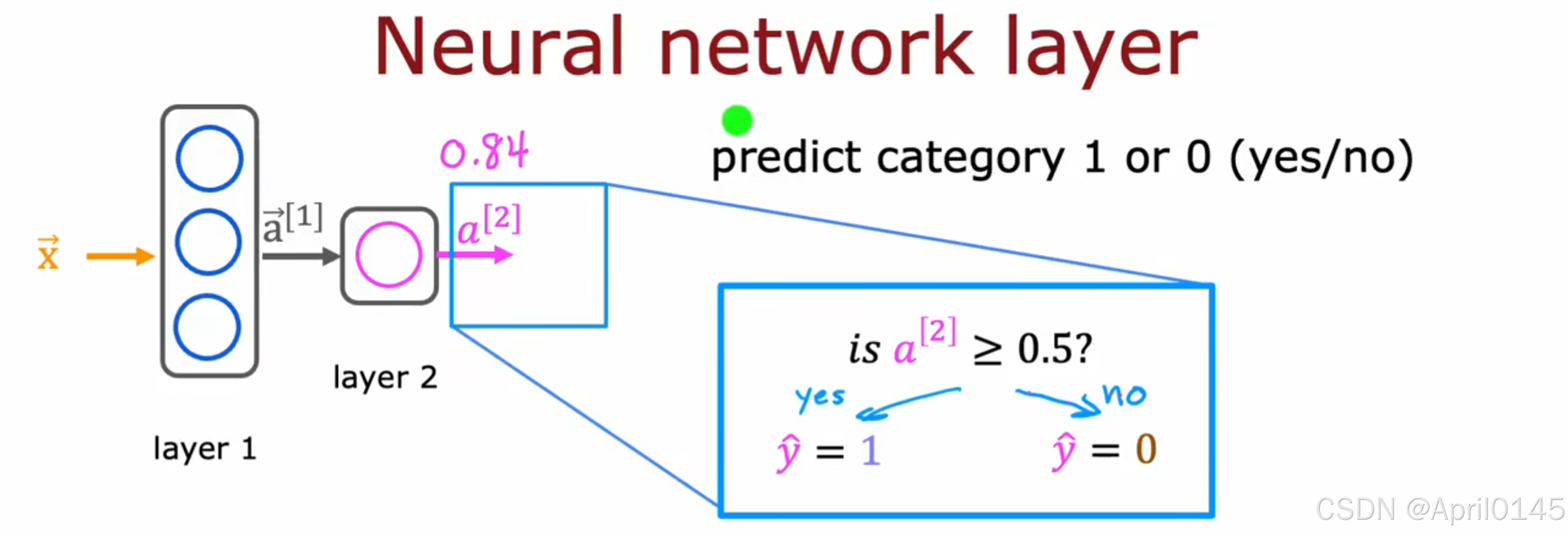
category:类别
2.2,更复杂的神经网络
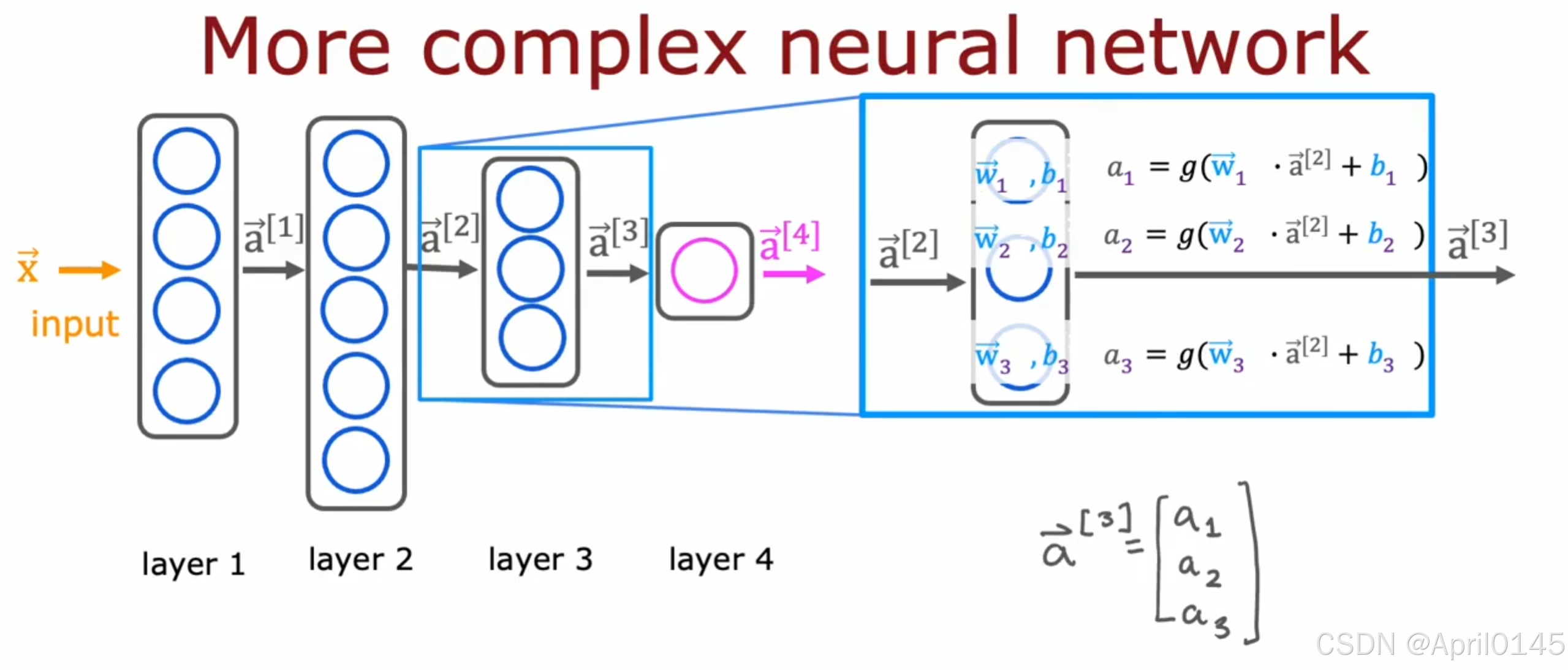
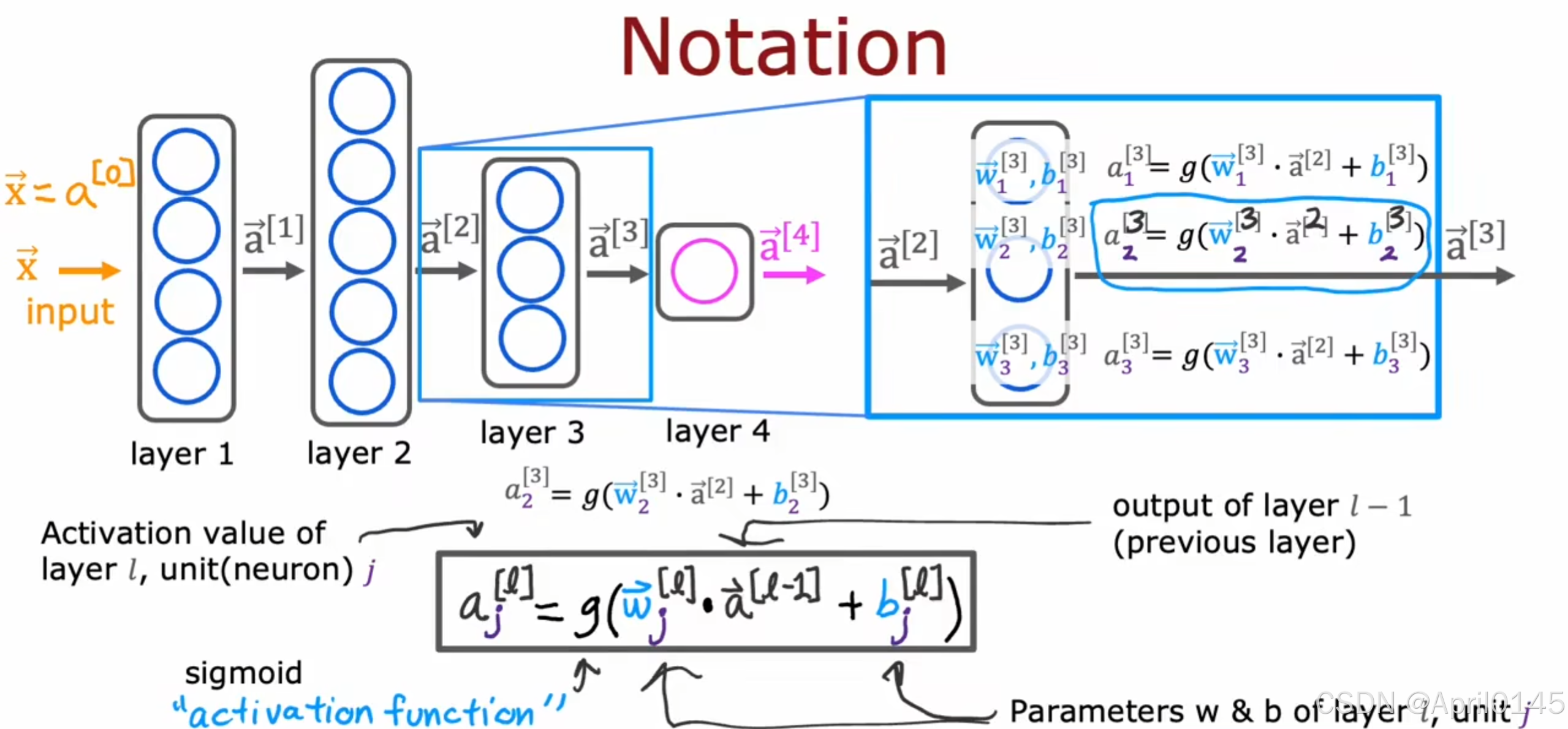 l层的激活值,单元(神经元)j
l层的激活值,单元(神经元)j
l-1层的输出(先前的层)
l层的参数w和b,单元j
这里的sigmoid函数g也被称为激活函数
2.3,神经网络的前向传播
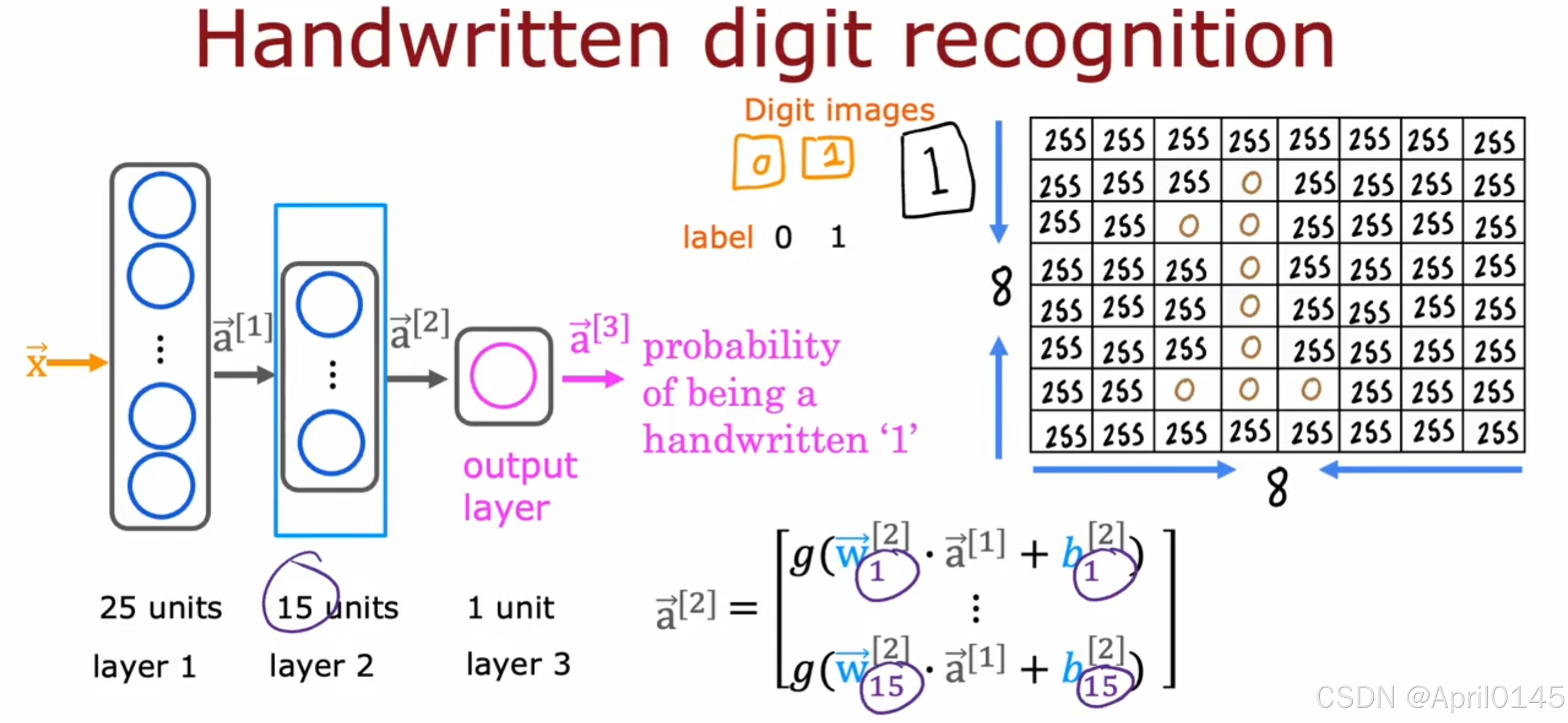
handwritten digit recognition:手写数字识别
这里的向量x也可以表示为a[0]
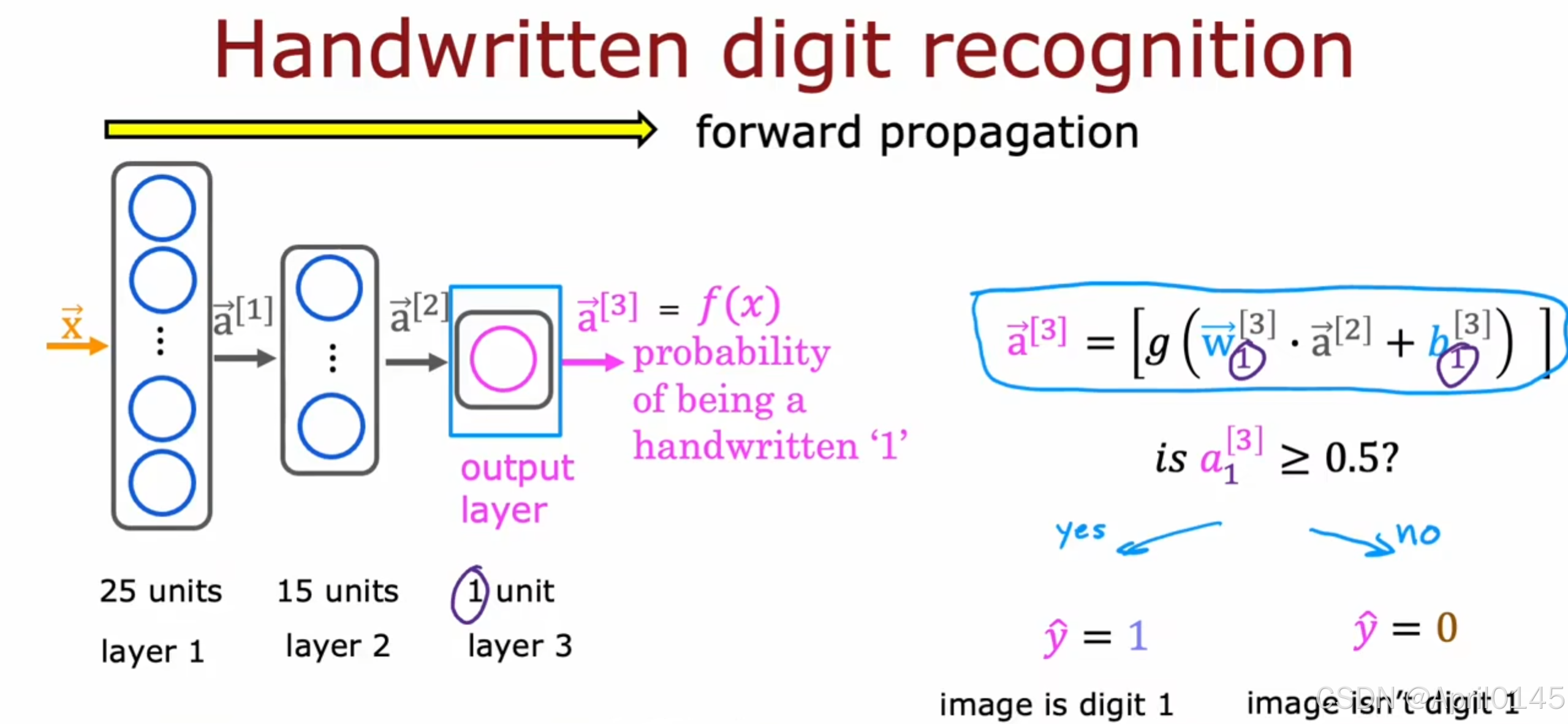 propagation:传播
propagation:传播
forward propagation:前向传播
这种类型的神经网络架构,最初会有更多的神经元,但随着靠近输出层,隐藏单元的数量会减少
5.1,强人工智能
ANI:狭义的人工智能
例如:智能扬声器,自动驾驶汽车,网络搜索,农场和工厂里的AI
AGI:广义的人工智能
例如:做任何人类能做的事
最初设想:模拟足够多的神经元就能模拟人的大脑
行不通的原因
1,逻辑回归模拟的神经元模型实际和任何生物神经元所做的完全不同,它要简单的多
2,直到今天我们任然不知道大脑的工作原理,我们对大脑的认知完全有限

6.2,矩阵乘法(数学补充)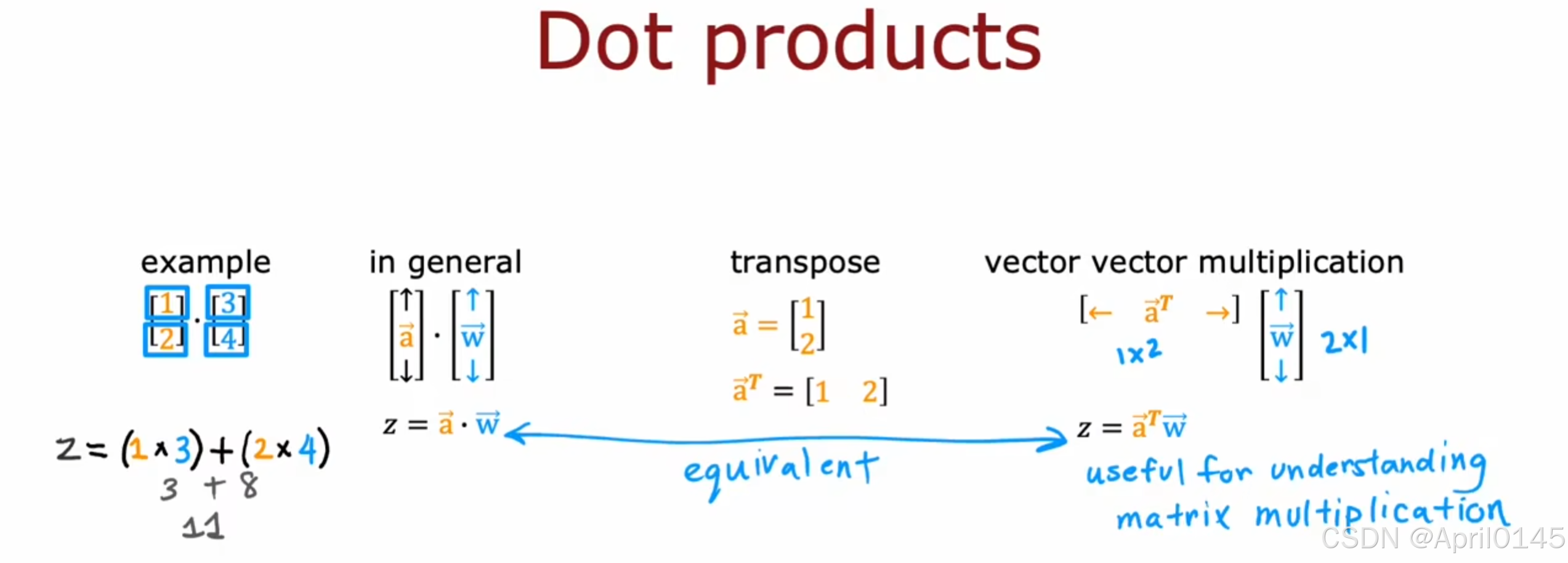
dot products:点积 general:一般的 transpose:转置 vector multiplication:向量乘法 equivalent:相等的

向量矩阵乘法

6.3,矩阵乘法规则



6.4,矩阵乘法的实现

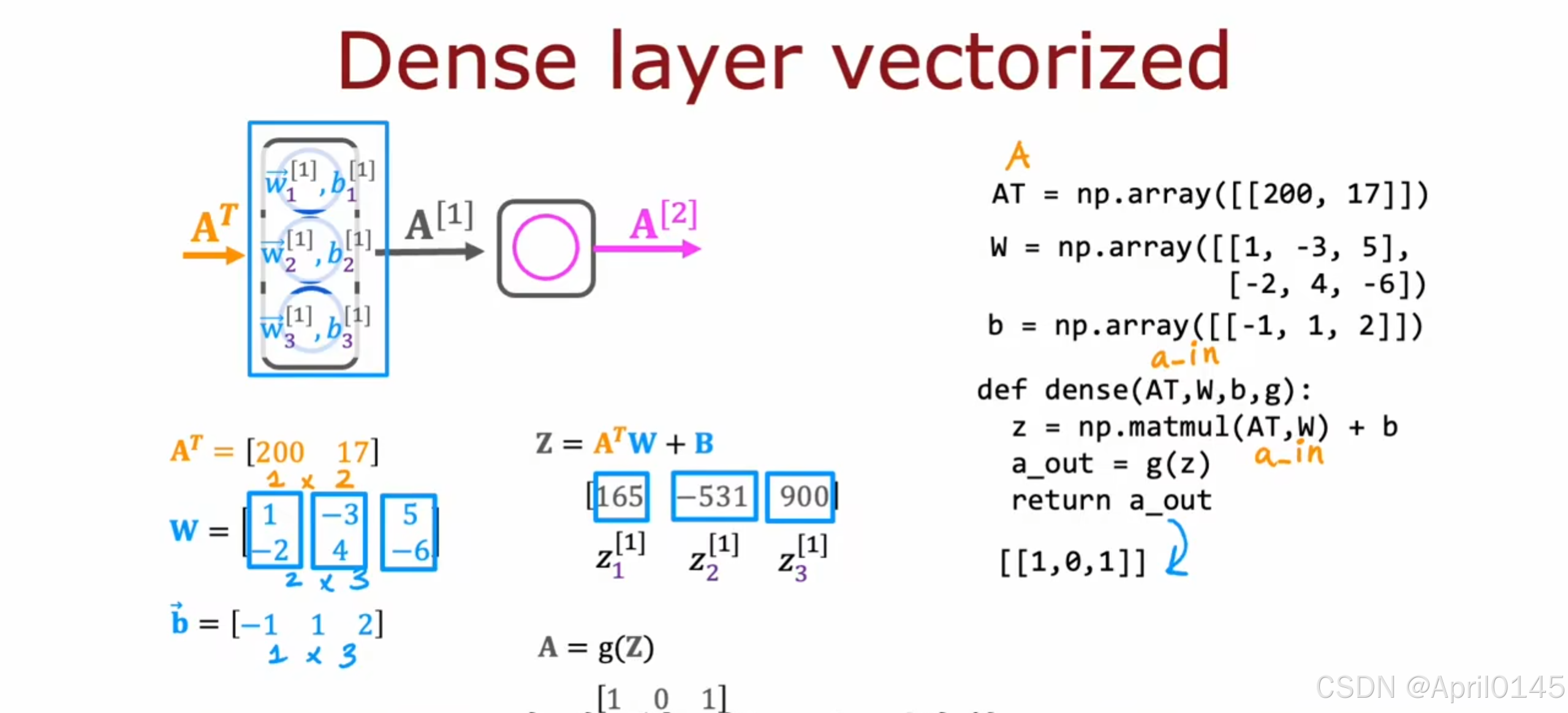 dense:密集的
dense:密集的
第二周:神经网络训练
2.1,sigmoid激活函数的替代方案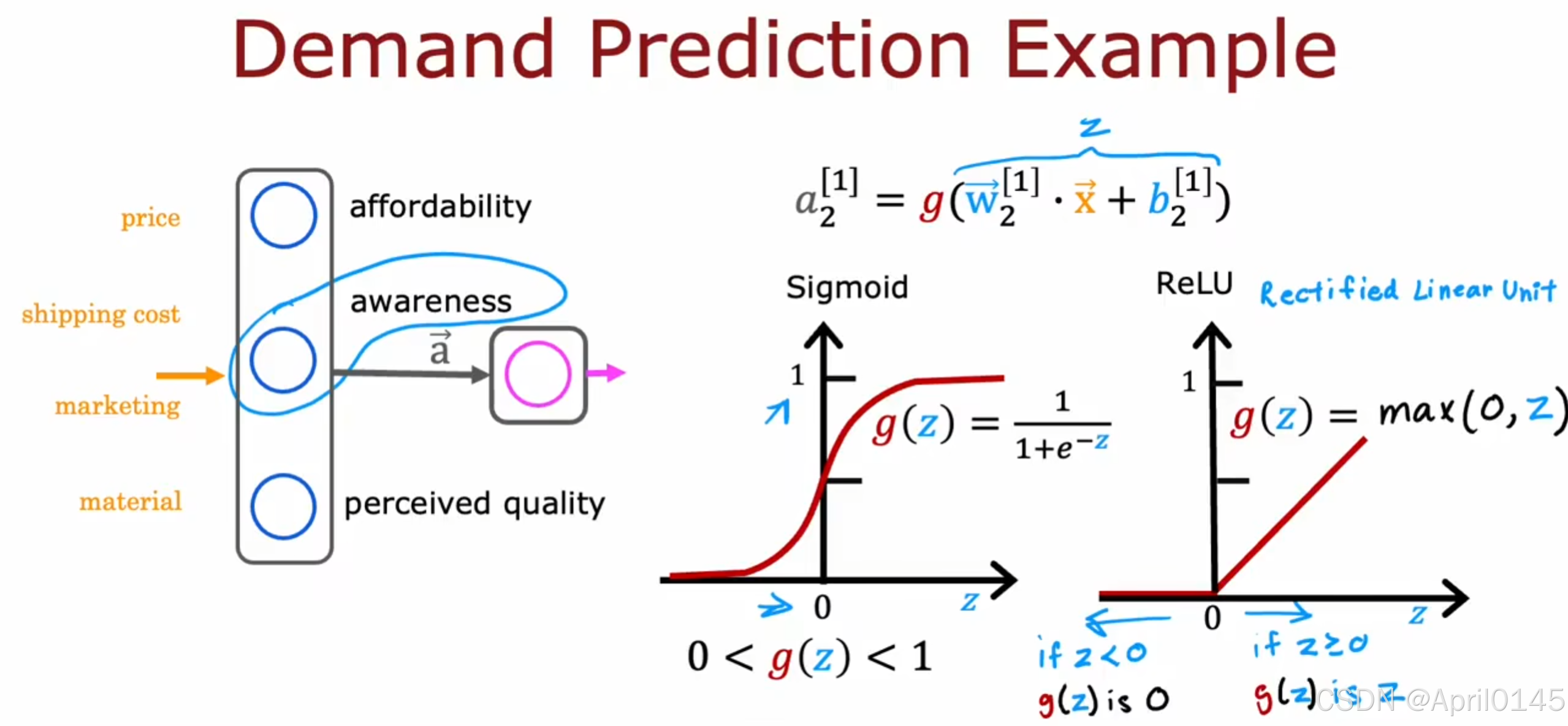
demand prediction:需求预测
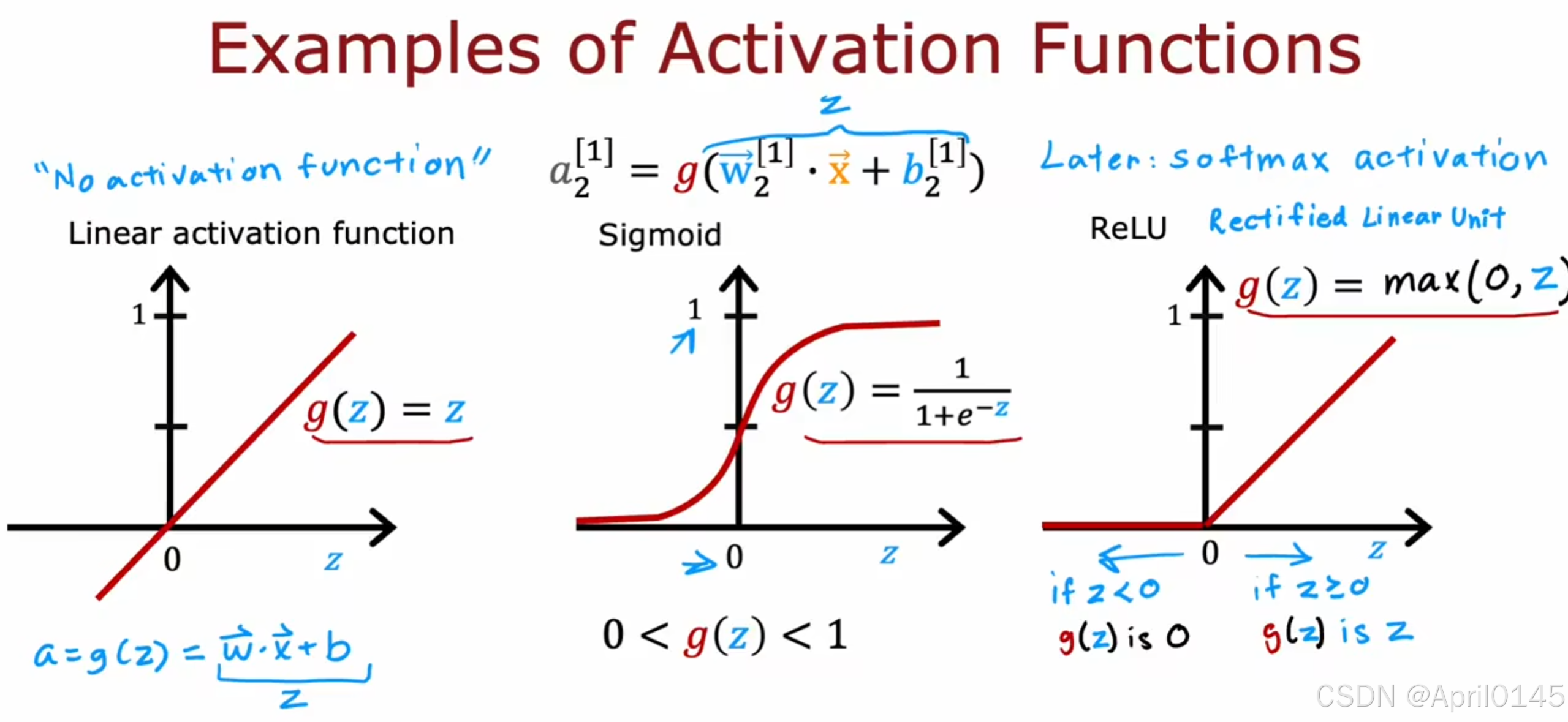
三种最常用的激活函数:
1,线性函数
2,sigmoid函数
3,ReLU函数
后续还会学到softmax函数
2.2,如何选择激活函数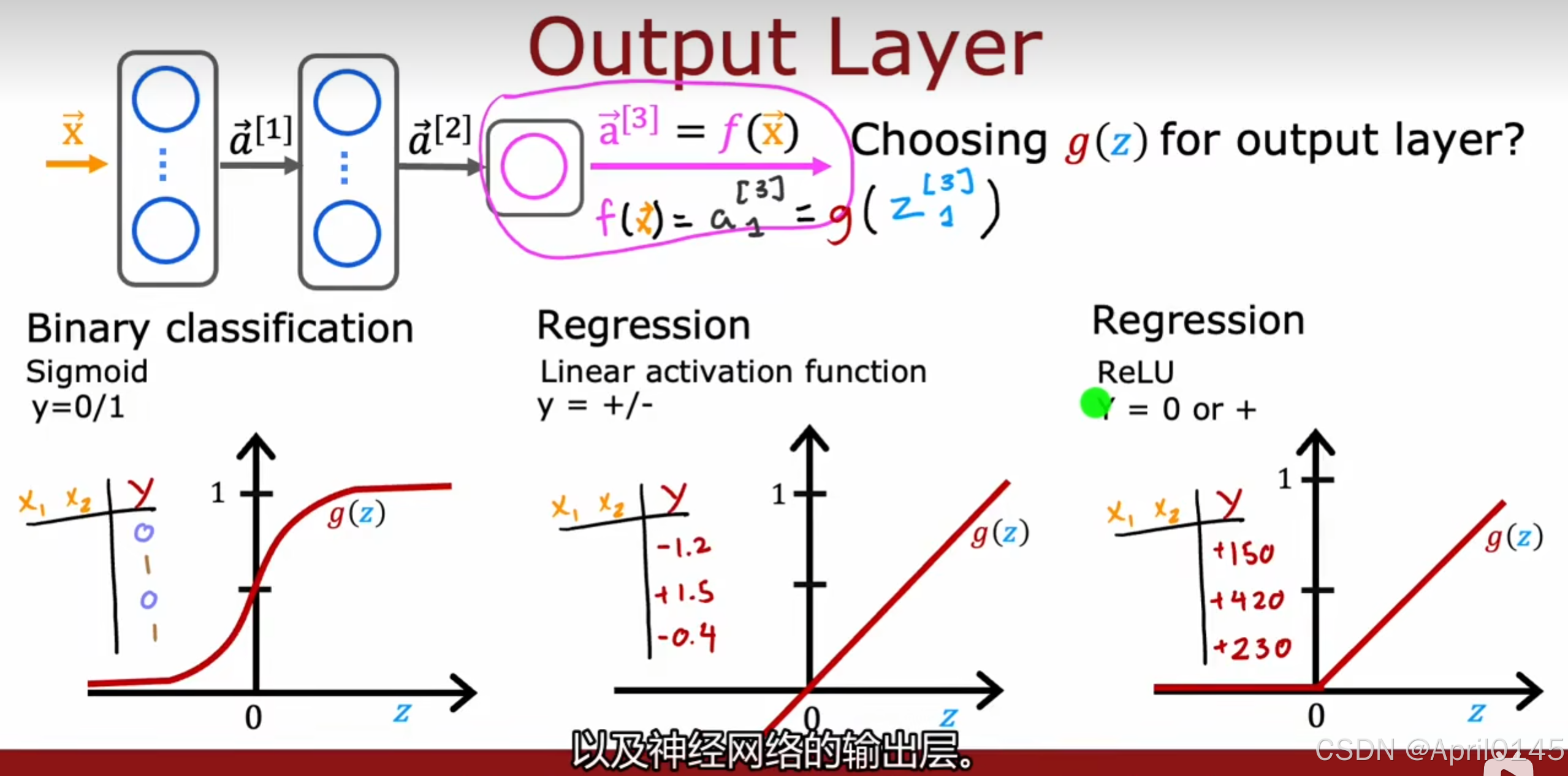
为输出层选择激活函数:
二元分类问题:sigmoid函数
可以取负值的回归问题:线性回归函数
只可以取非负值的回归函数(比如房价预测):ReLU函数
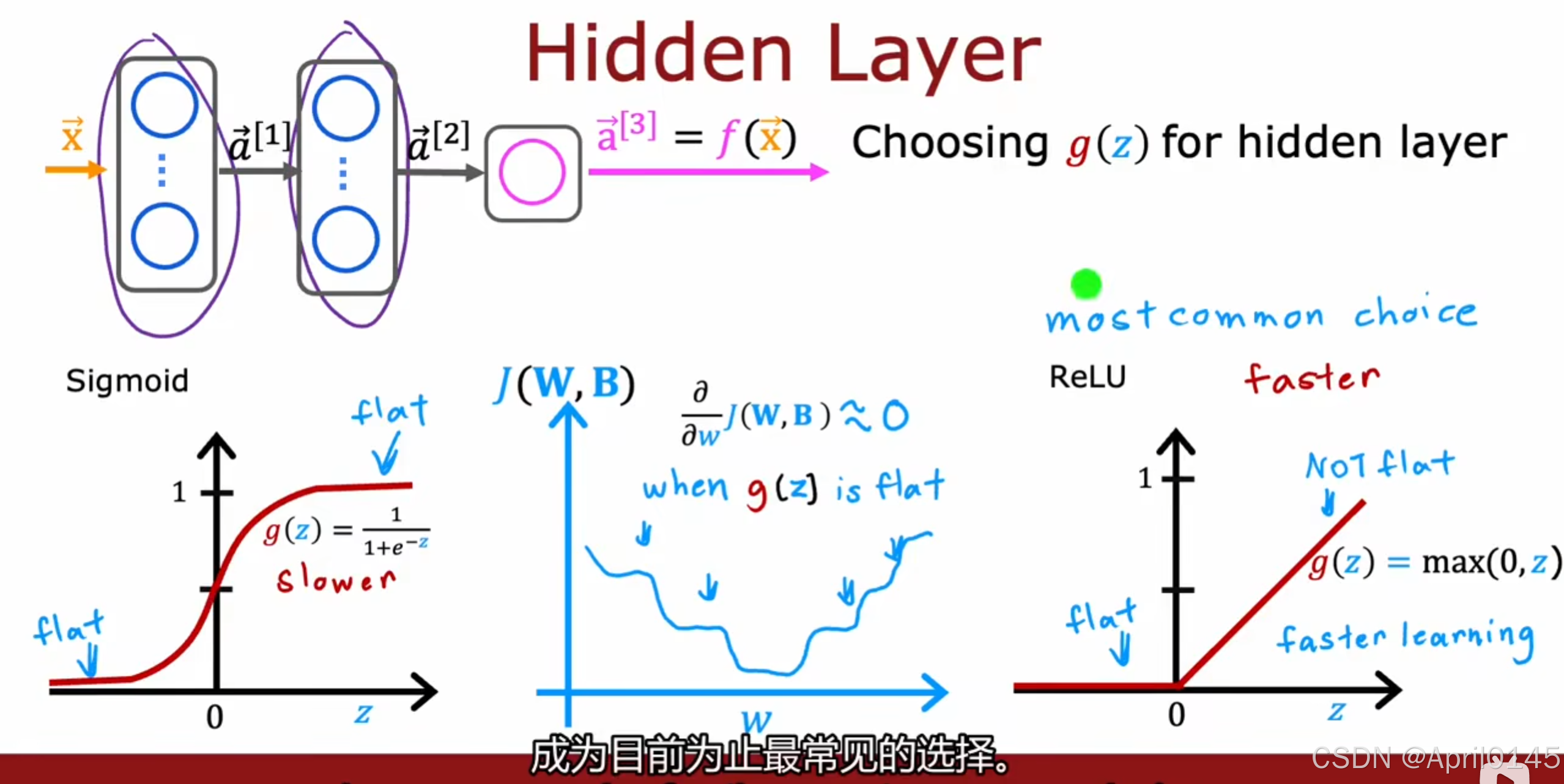
为隐藏层选择激活函数:
通常选择ReLU函数:
为什么不选择sigmoid函数?
1,ReLU函数计算速度更快,因为它只需计算0,z
sigmoid函数则需要取幂然后取逆等等
2,ReLU函数只有左边是平的,而sigmoid函数左右两边都是平的,
这导致了梯度下降变得更慢
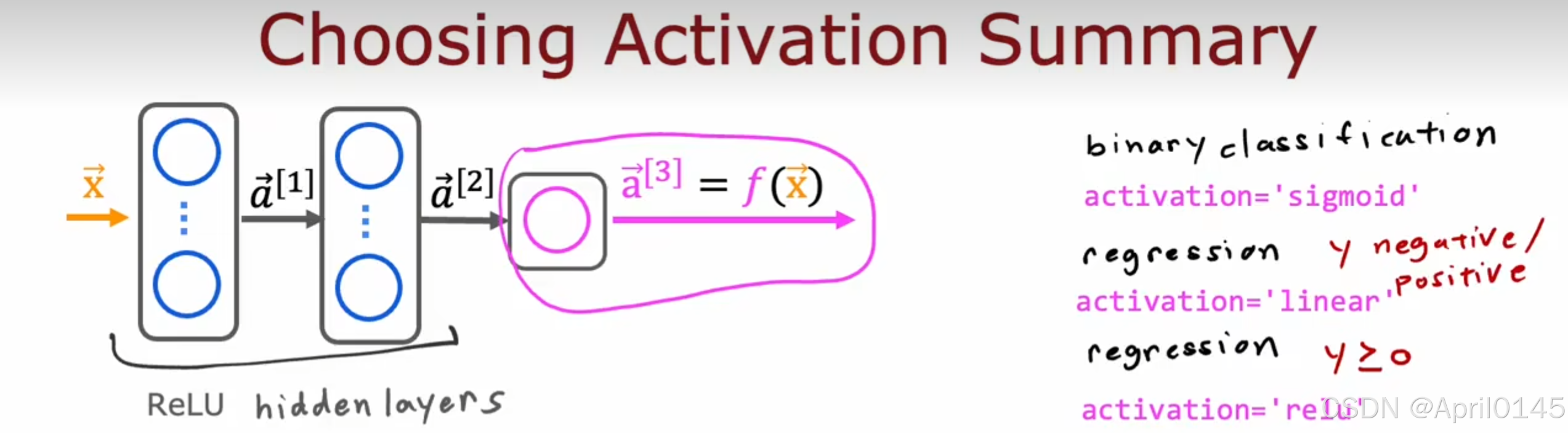
summary:总结
在隐藏层中不推荐使用线性激活函数,因为神经网络仅能进行线性变换,无法处理复杂问题
3.1,多分类问题
多分类问题:标签y多于两个以上可能值
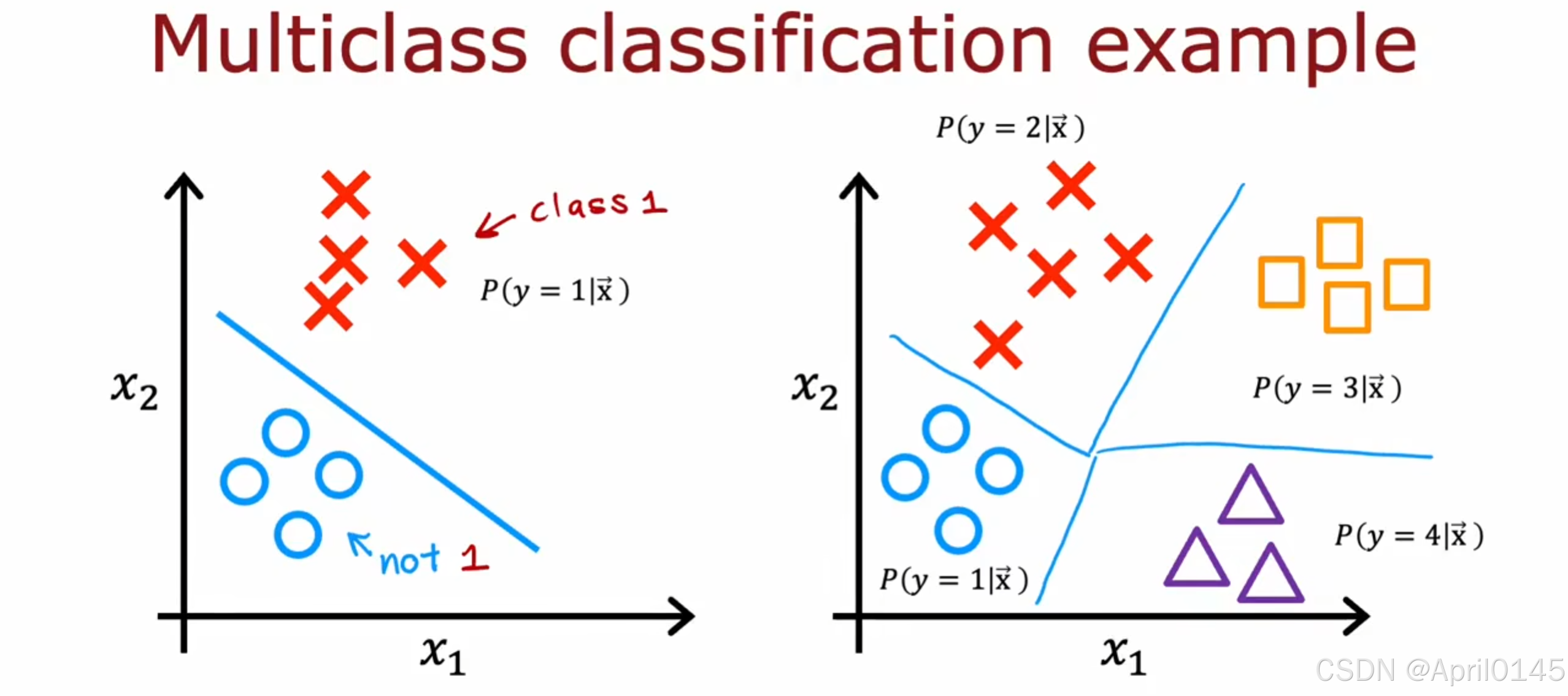
3.2,softmax激活函数
处理有多个可能输出的问题
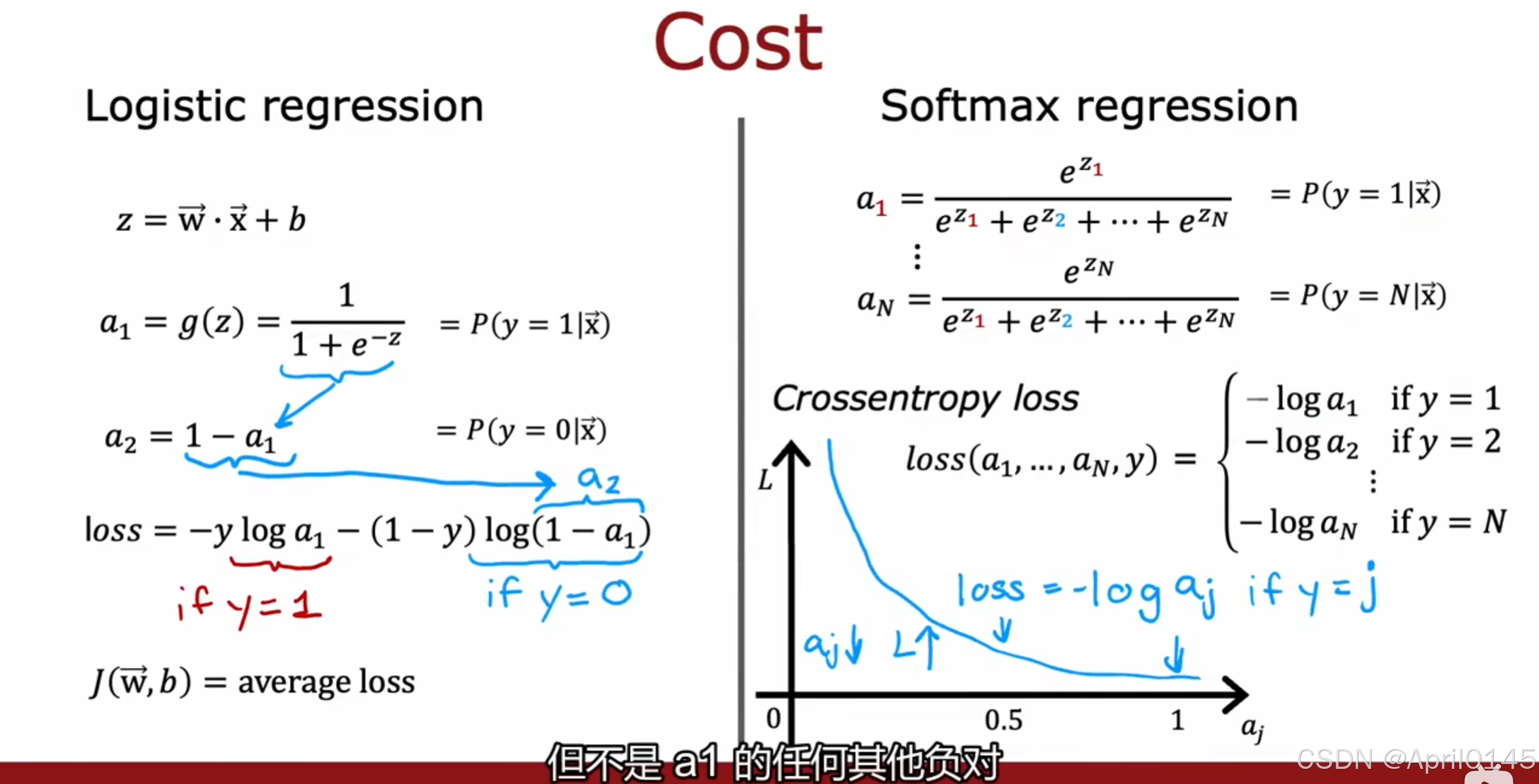
crossentropy loss:交叉熵损失函数
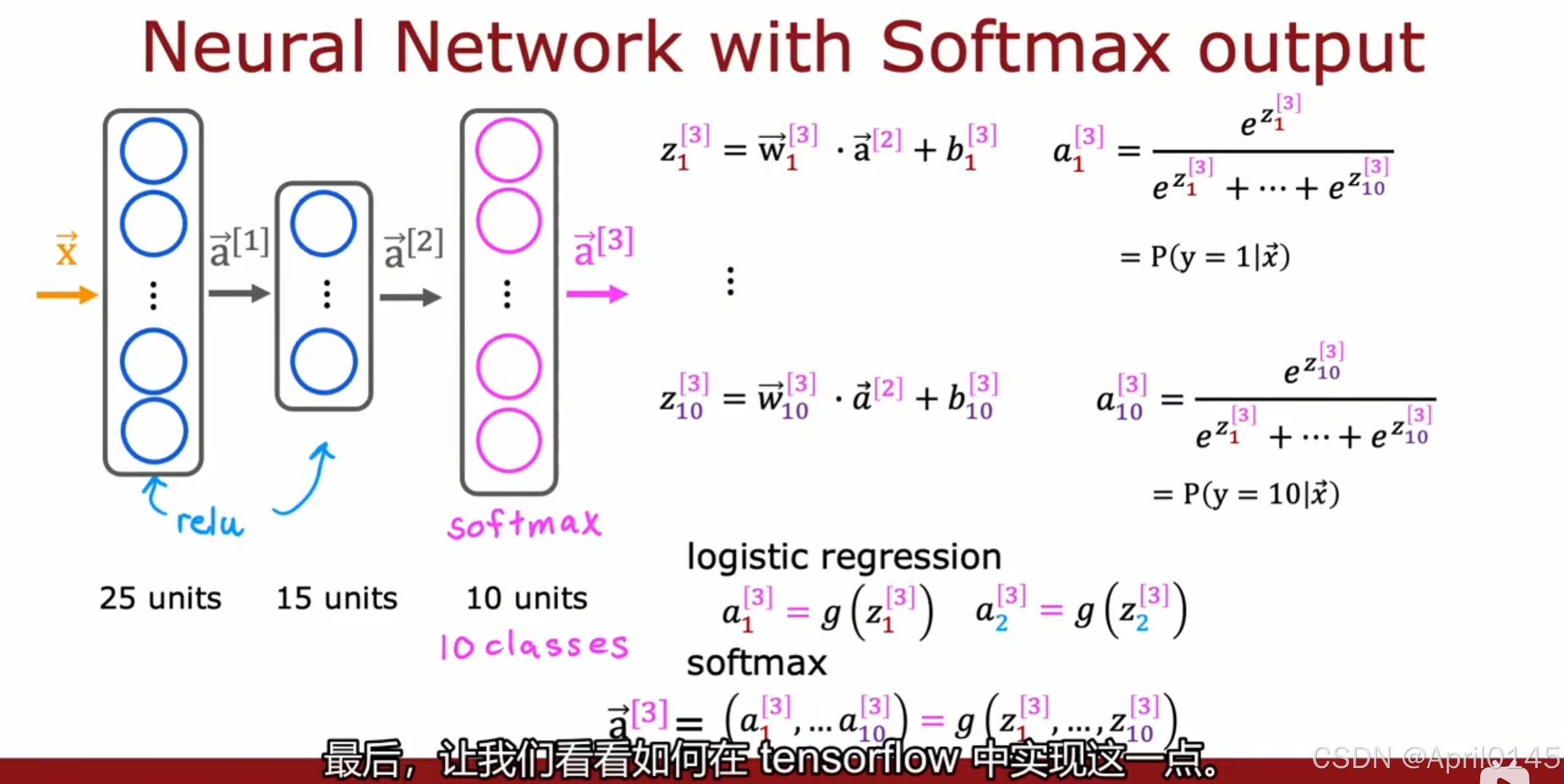
3.3,神经网络的softmax输出
3.5,多标签问题
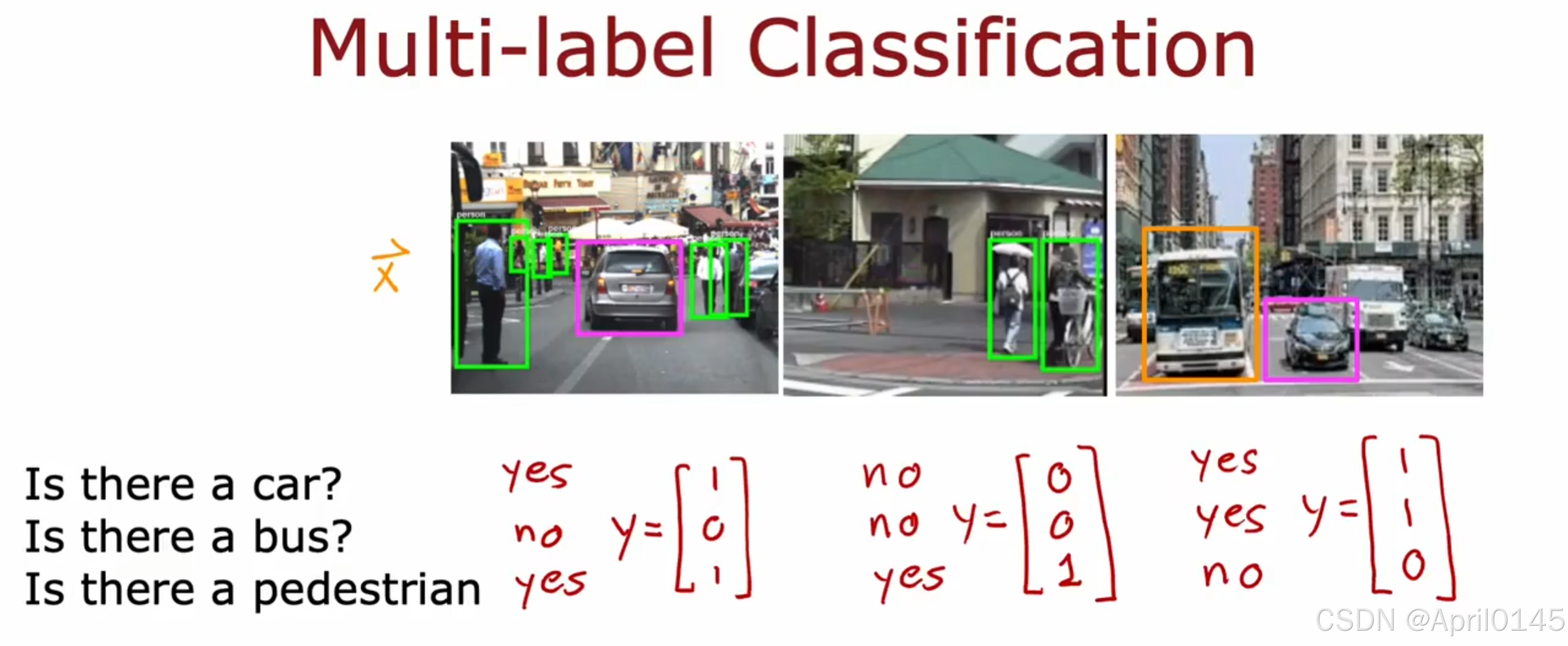
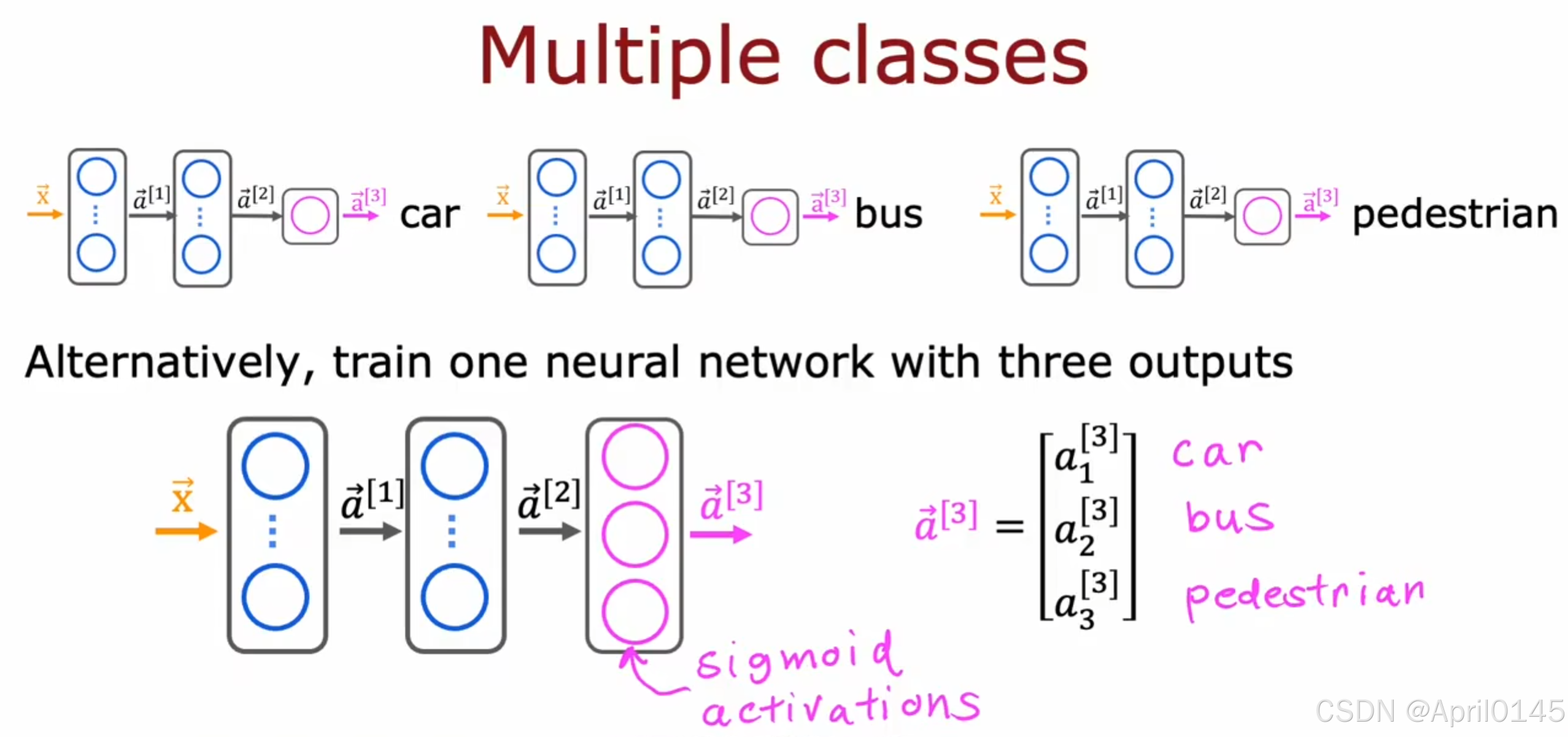 可以使用三个神经网络来分别输出或者训练一个有三个输出的神经网络
可以使用三个神经网络来分别输出或者训练一个有三个输出的神经网络
alternative:或者
4.1,高级优化方法
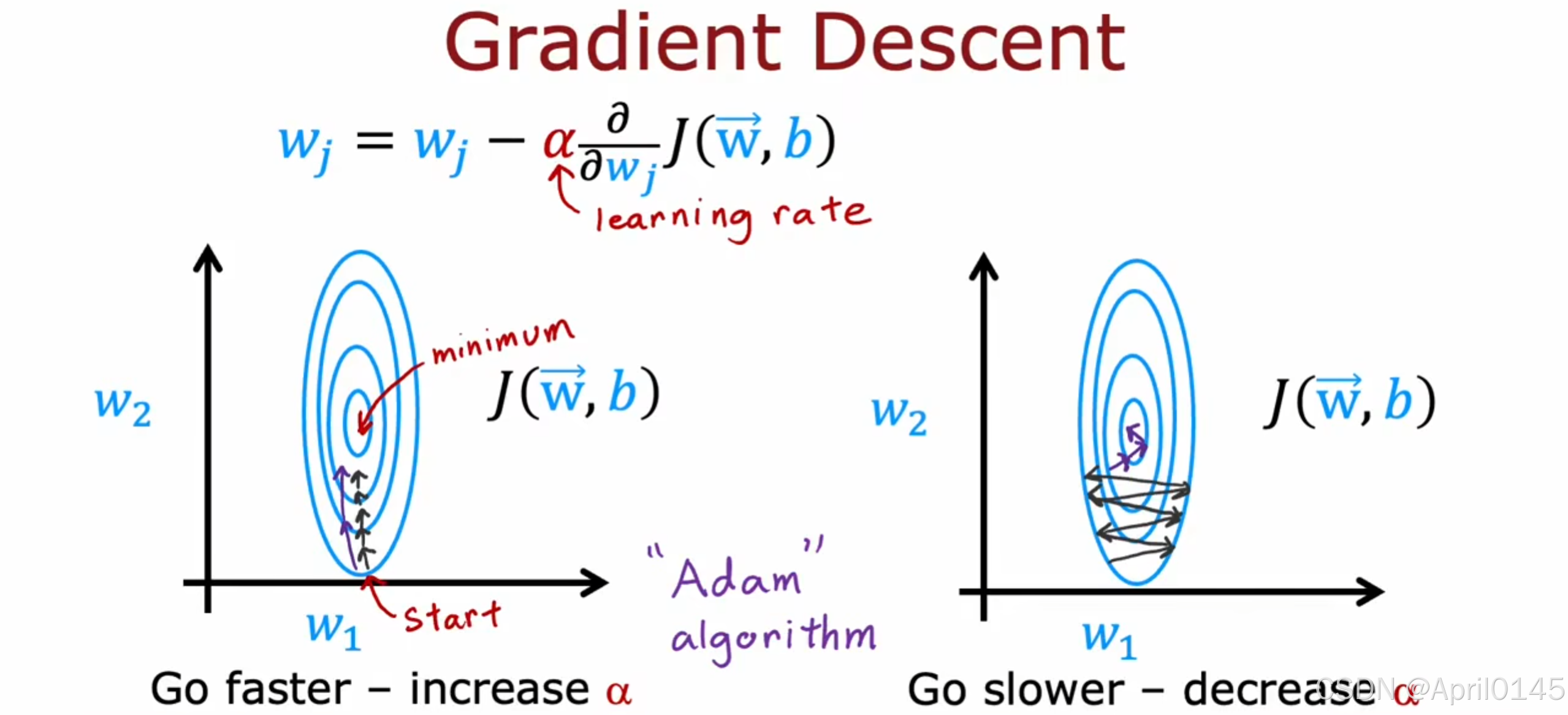 更快:增加& 更慢:减少&
更快:增加& 更慢:减少&

adam算法:可以自动调整学习率&的算法,使用多个&
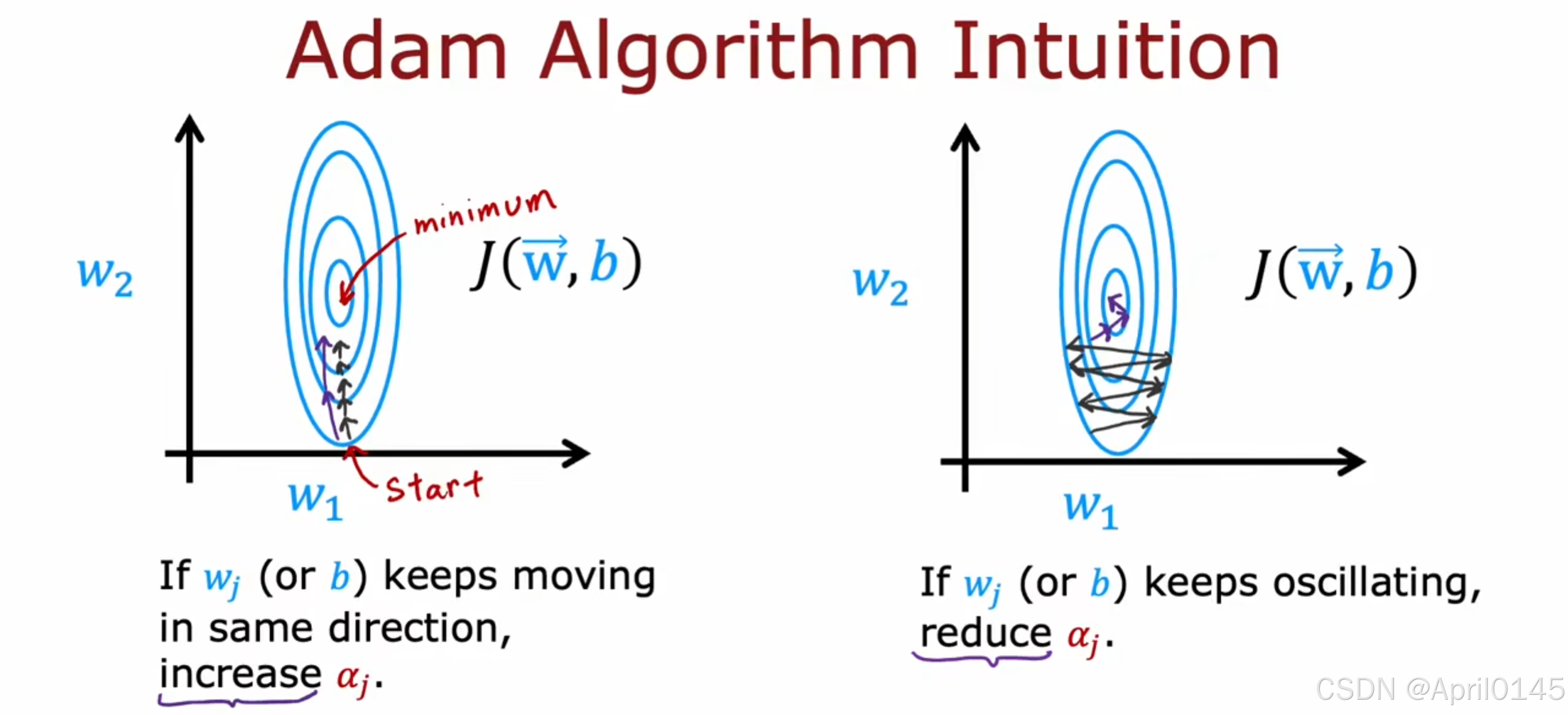
如果w或b在相同的方向保持前进,就增加学习率&
如果w或b来回摆动,就减小学习率&
4.2,其他的网络层类型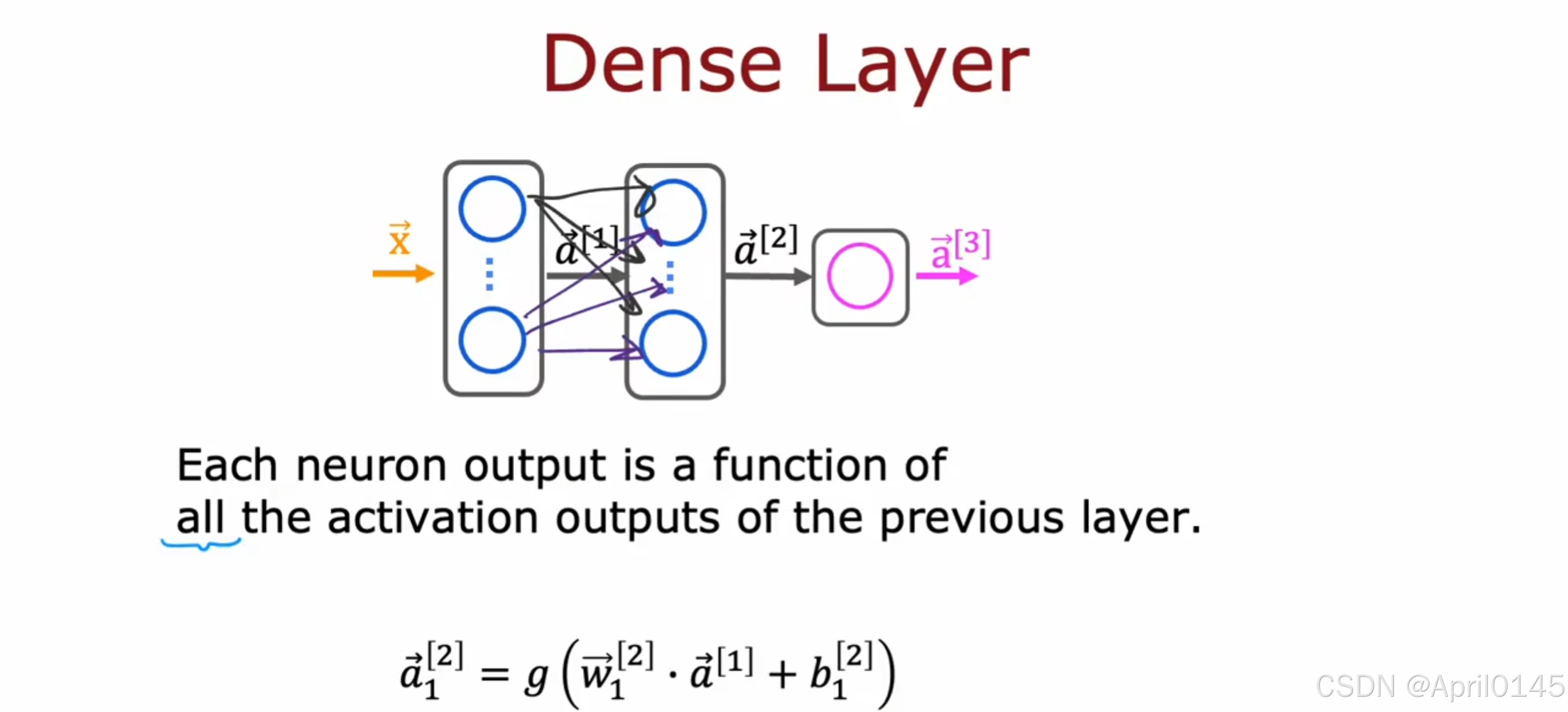
dense layer:密集层:每个神经元输出都是上一层所有激活输出的函数
也称为全连接层(Fully Connected Layer, FC):每个神经元与前一层的所有神经元相连
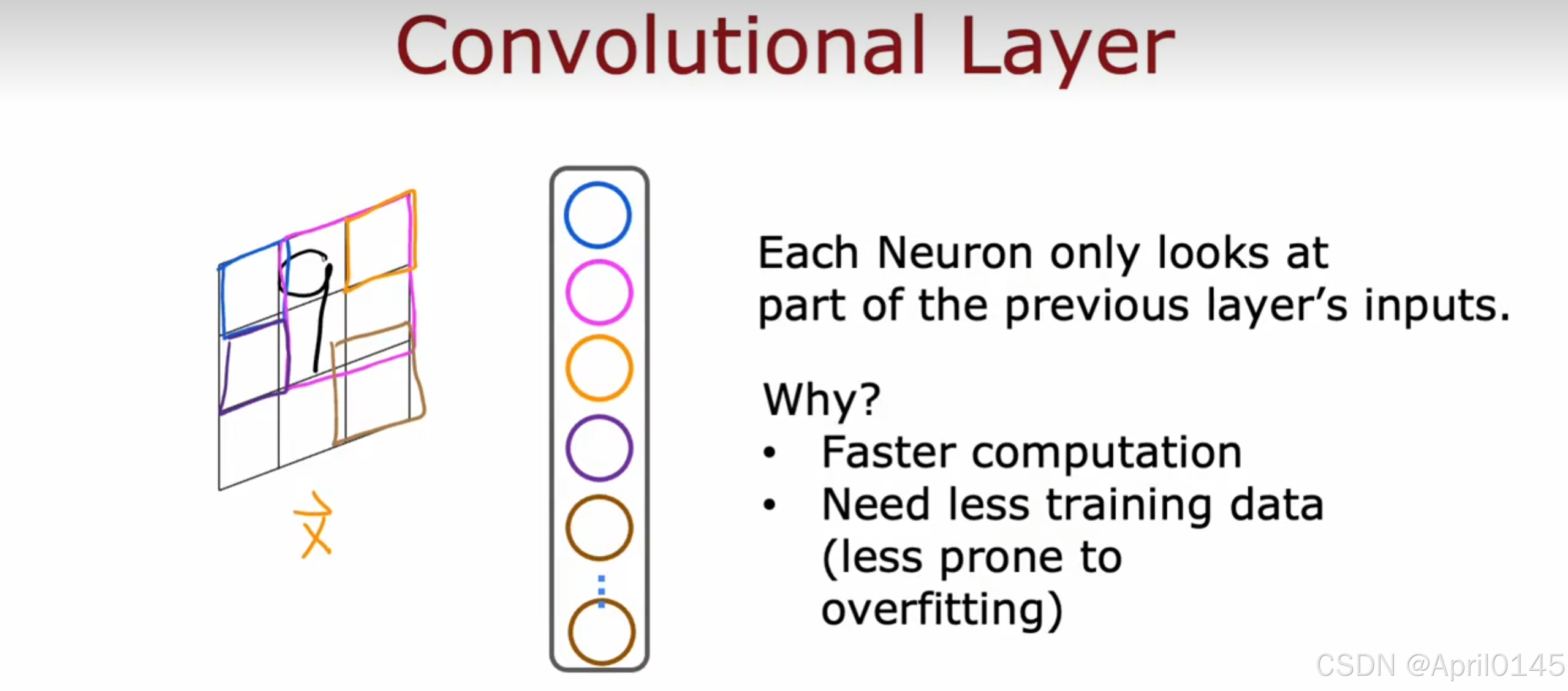
convolutional layer:卷积层(通过卷积操作提取局部特征)
每个神经元只查看上个层的部分输入
为什么?
更快的计算机运行速度
只需要更少的训练集
更不容易过拟合
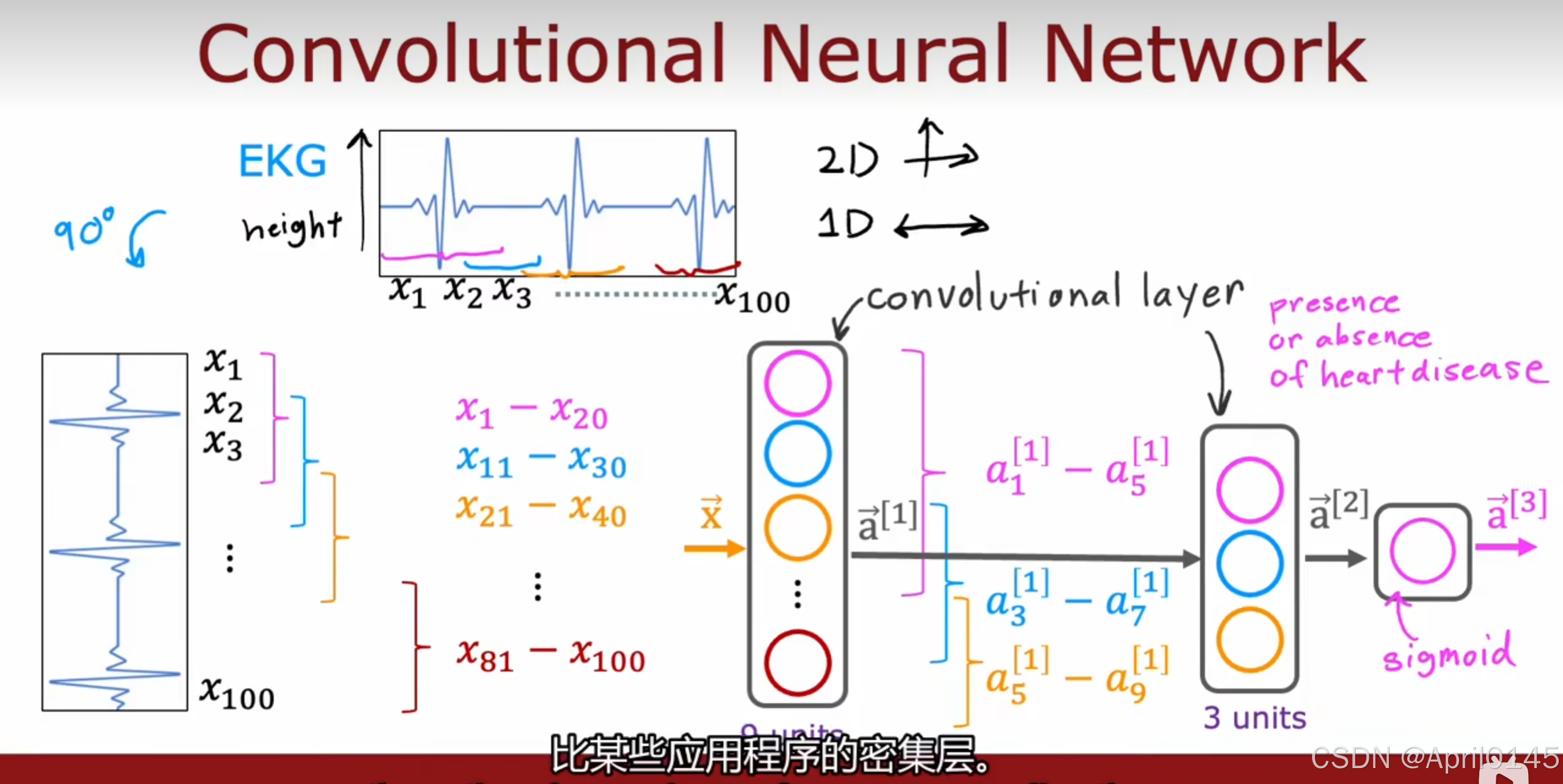
EKG:心电图
最后用sigmoid函数判断是否存在心脏病
第三周:应用机器学习的建议
1.1,下一步要做什么
调试学习算法
你已经对预测房价实现了正则化线性回归
但它在预测中犯了令人无法接受的大错误,你接下来要尝试什么?
获取更多的数据集
尝试更少的特征集
获取更多的特征
尝试添加多项式特征
尝试减少λ
尝试增加λ


机器学习诊断
诊断:运行一个测试来深入了解学习算法中不工作的内容,以获得提高性能的指导
诊断需要时间去实施,但这样做能够帮助你更好的利用自己的时间
1.2,模型评估1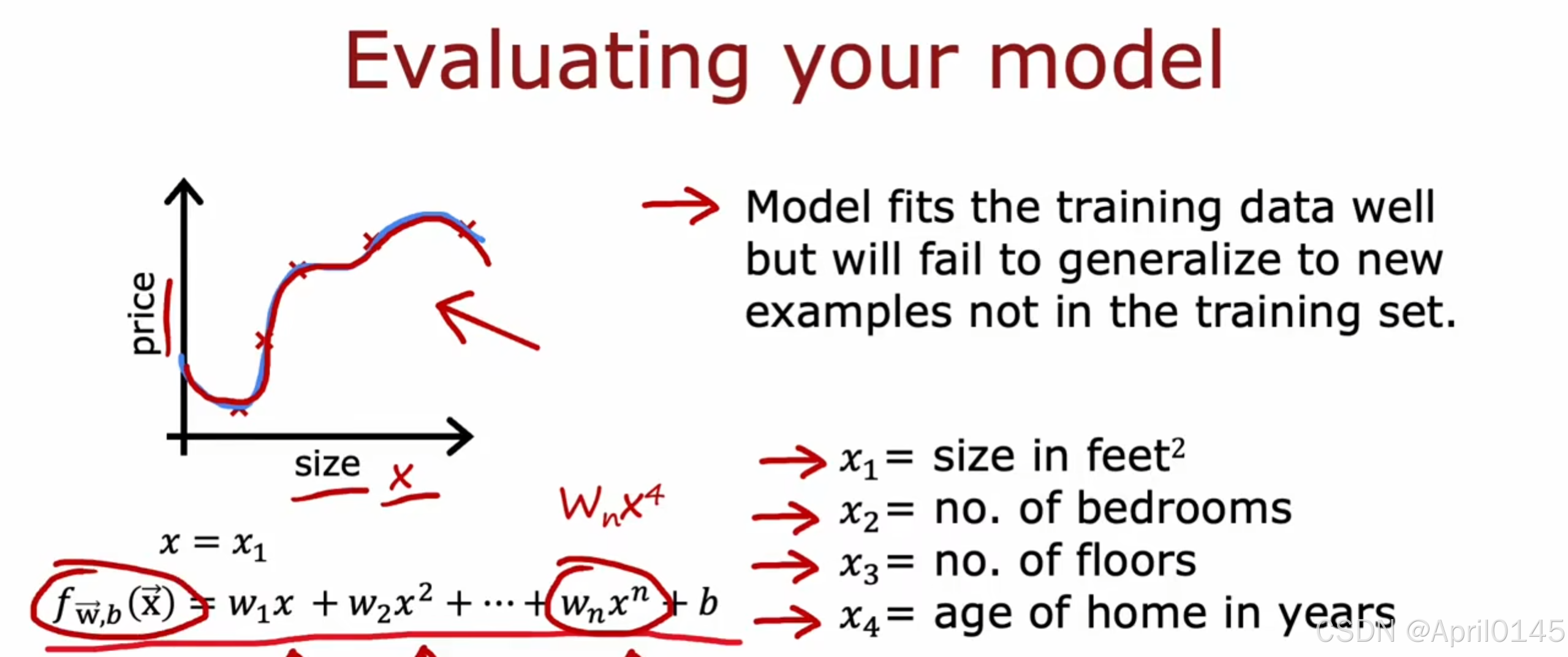
evaluating:评估
评估你的模型
模型非常适合你的训练集,但无法推广到训练集中没有的新示例
我们需要一些更系统化的方法来评估模型的表现

将数据集进行划分,70%为训练集,30%为测试集

对于线性回归的训练/测试程序(使用平方误差损失函数)
通过最小化成本函数来拟合参数J(w,b)
计算测试误差
计算训练误差
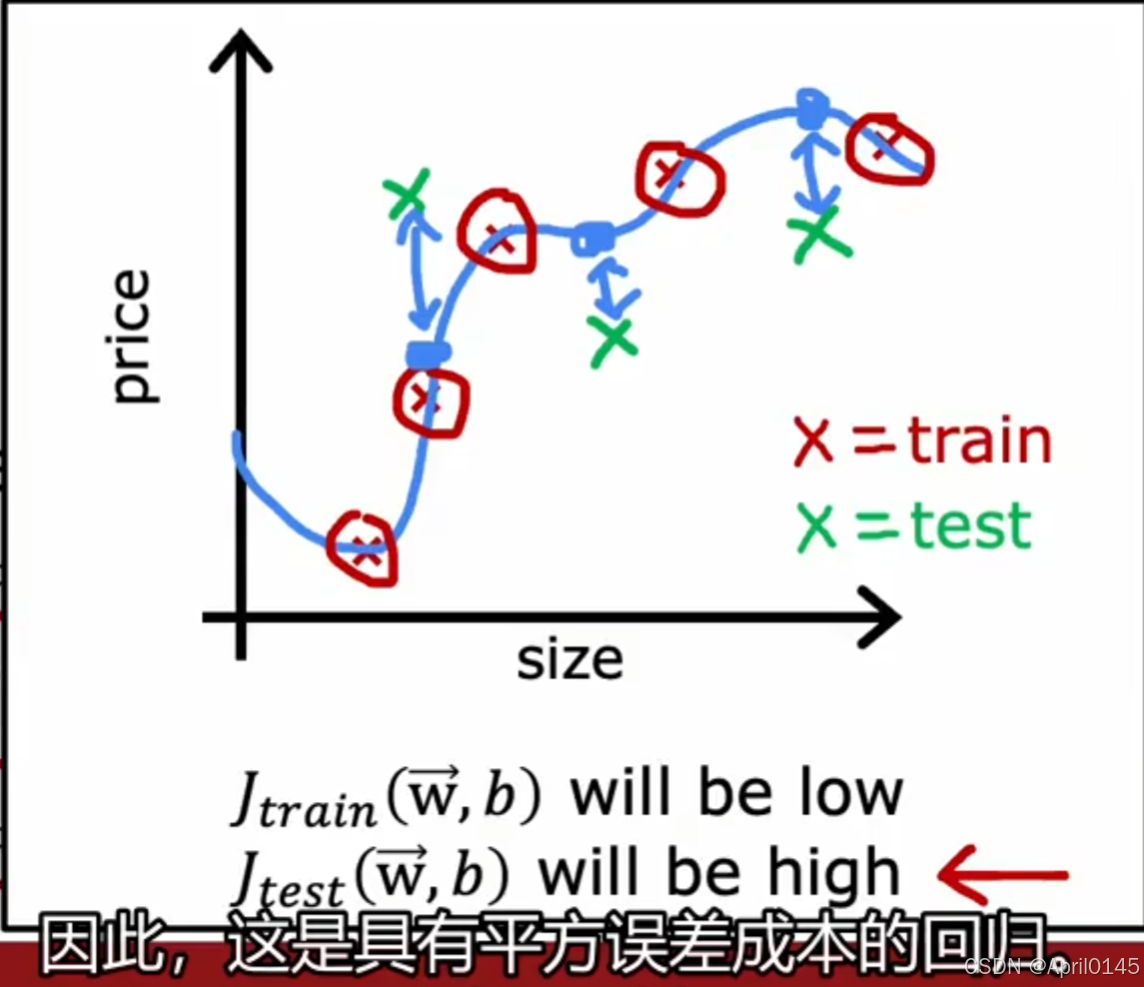
 对于二元分类问题的训练/测试程序
对于二元分类问题的训练/测试程序
方法:获取一个数据集并将其拆分为一个单独的训练集和一个单独的测试集,
通过计算j测试和j训练,你现在可以衡量模型在测试集和训练集上的表现。
1.3,模型选择以及交叉验证
如过只用单个j测试来检测模型的泛化能力,存在一个缺陷,单次j测试可能会对模型的泛化过于乐观(偶然性),我们还需要对模型的泛化能力进行多次验证(交叉验证)

cross validation:交叉验证集
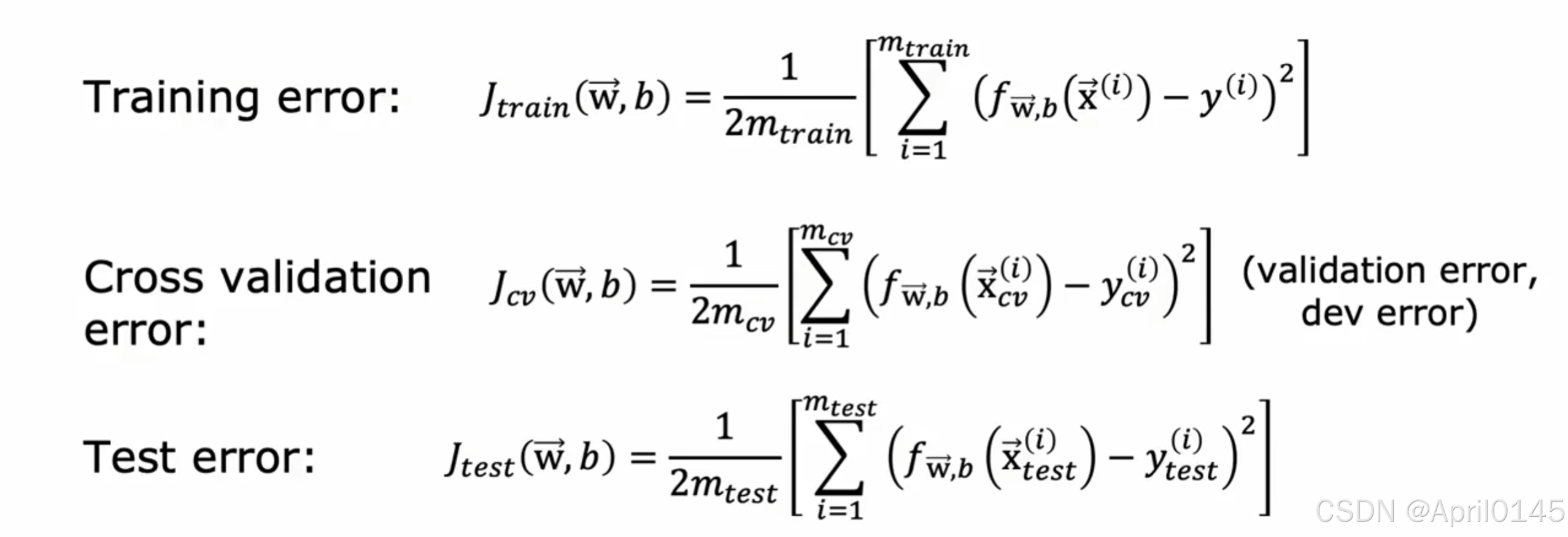
 选择特征数量最优的模型
选择特征数量最优的模型
选择Jcv最小的模型,再用J测试进行二次验证,避免偶然性导致过拟合的情况
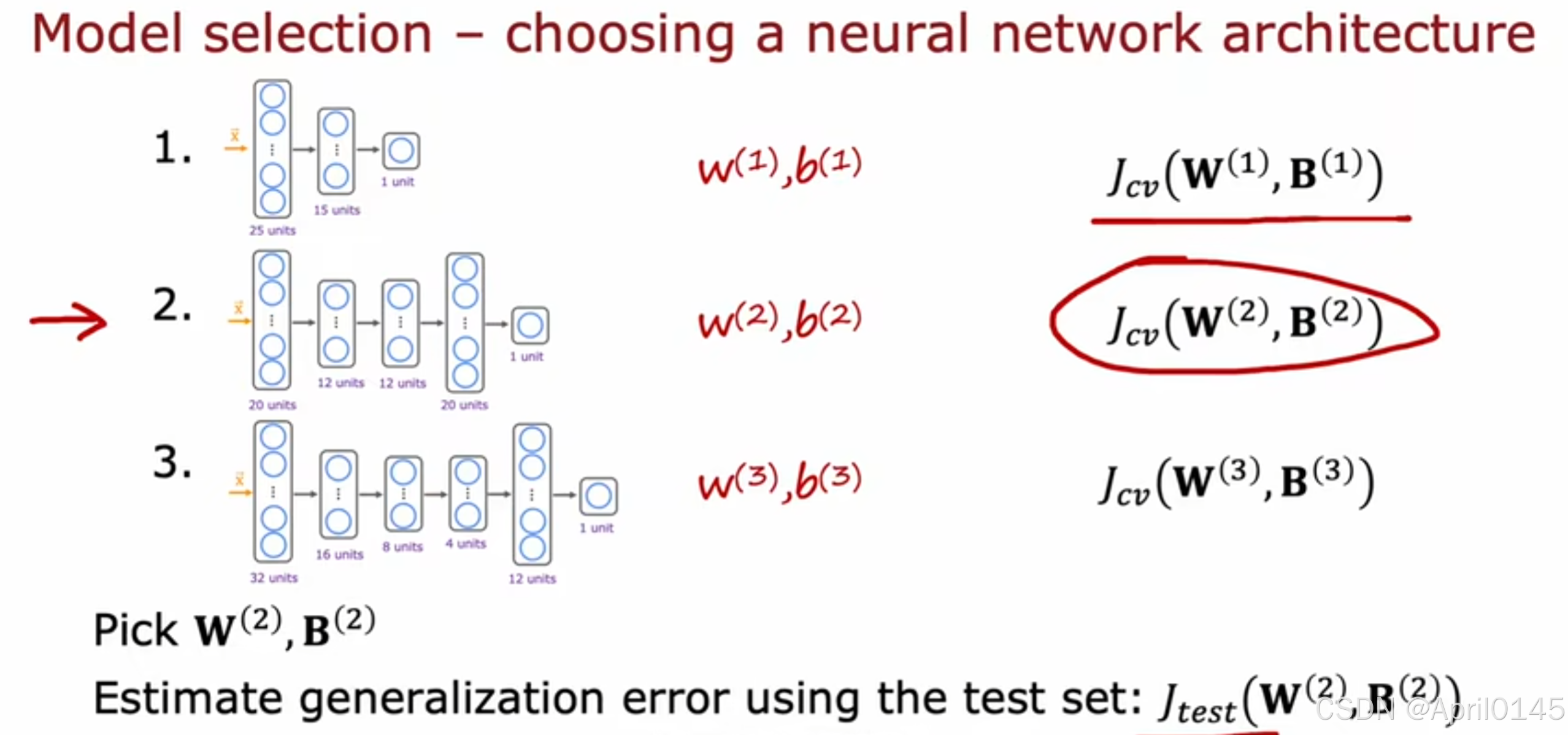
选择神经网络时同样适用
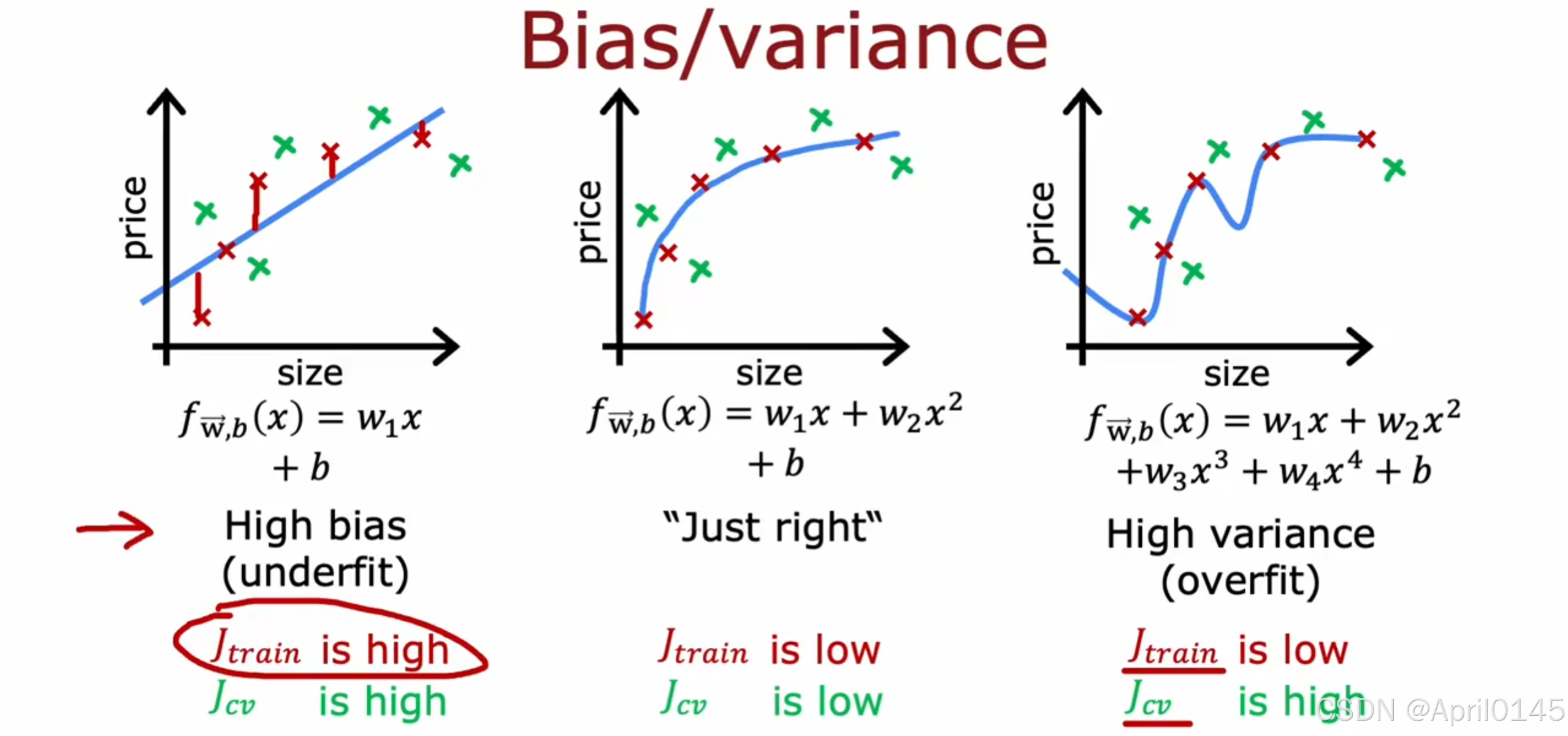
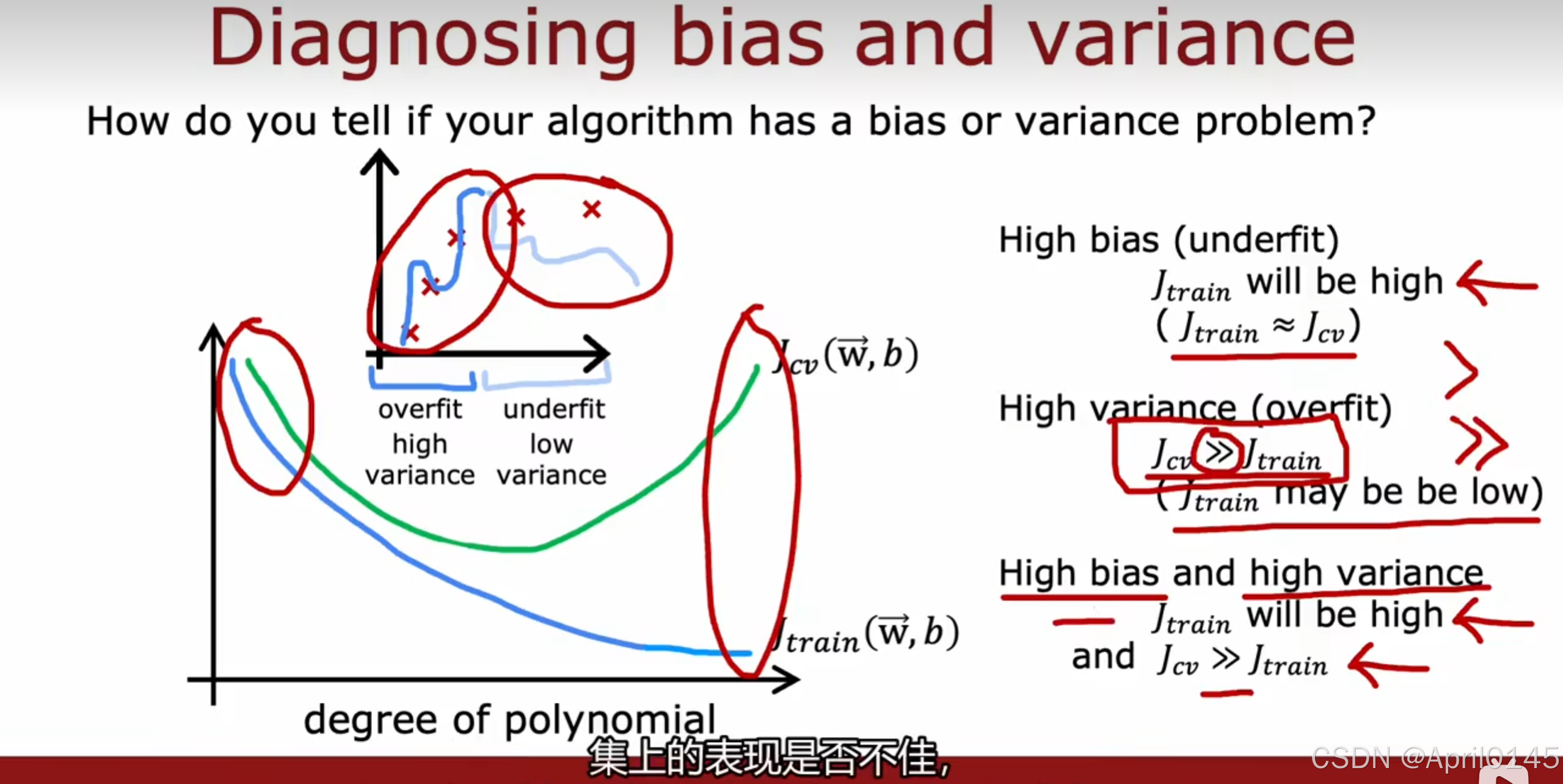
2.1,模型评估2(偏差和方差)
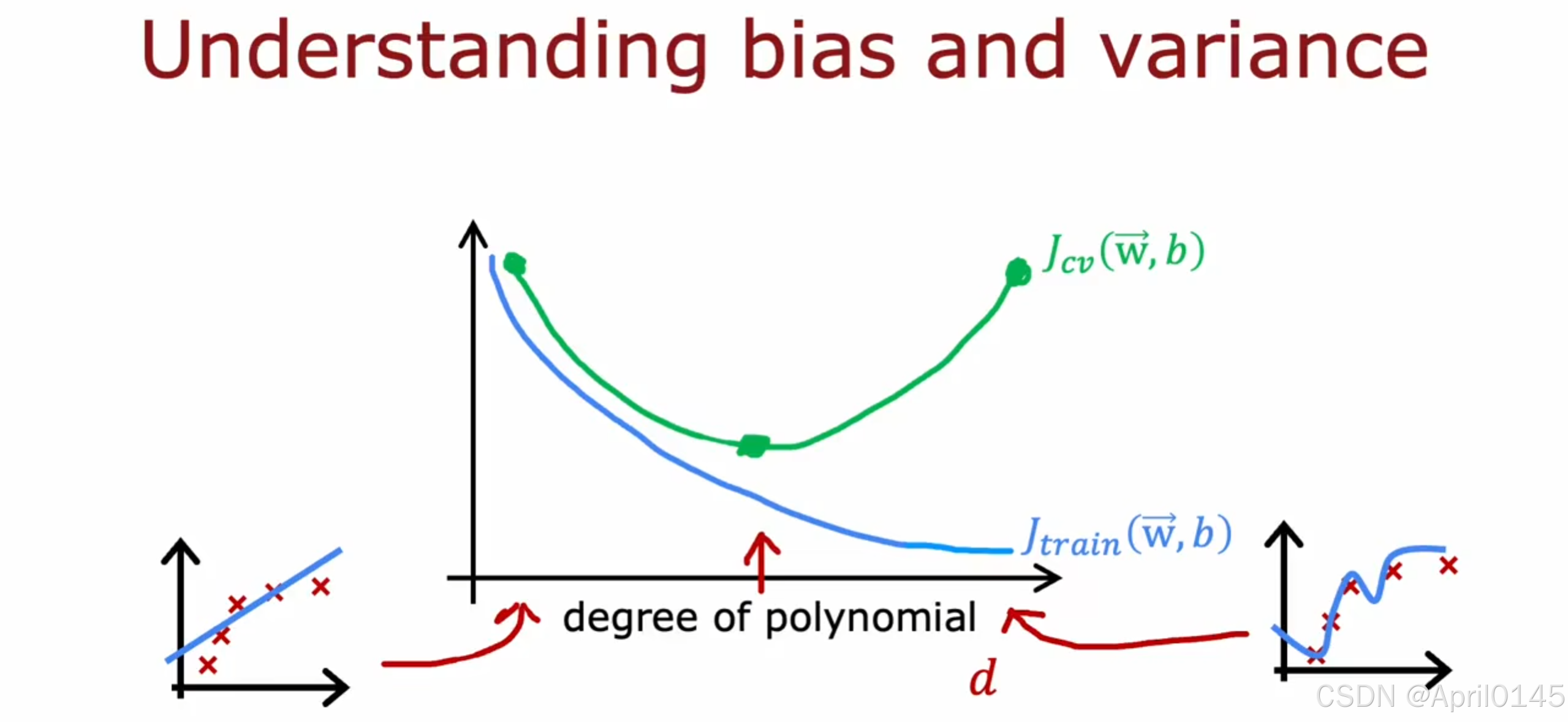
2.2,模型评估3(正则化)
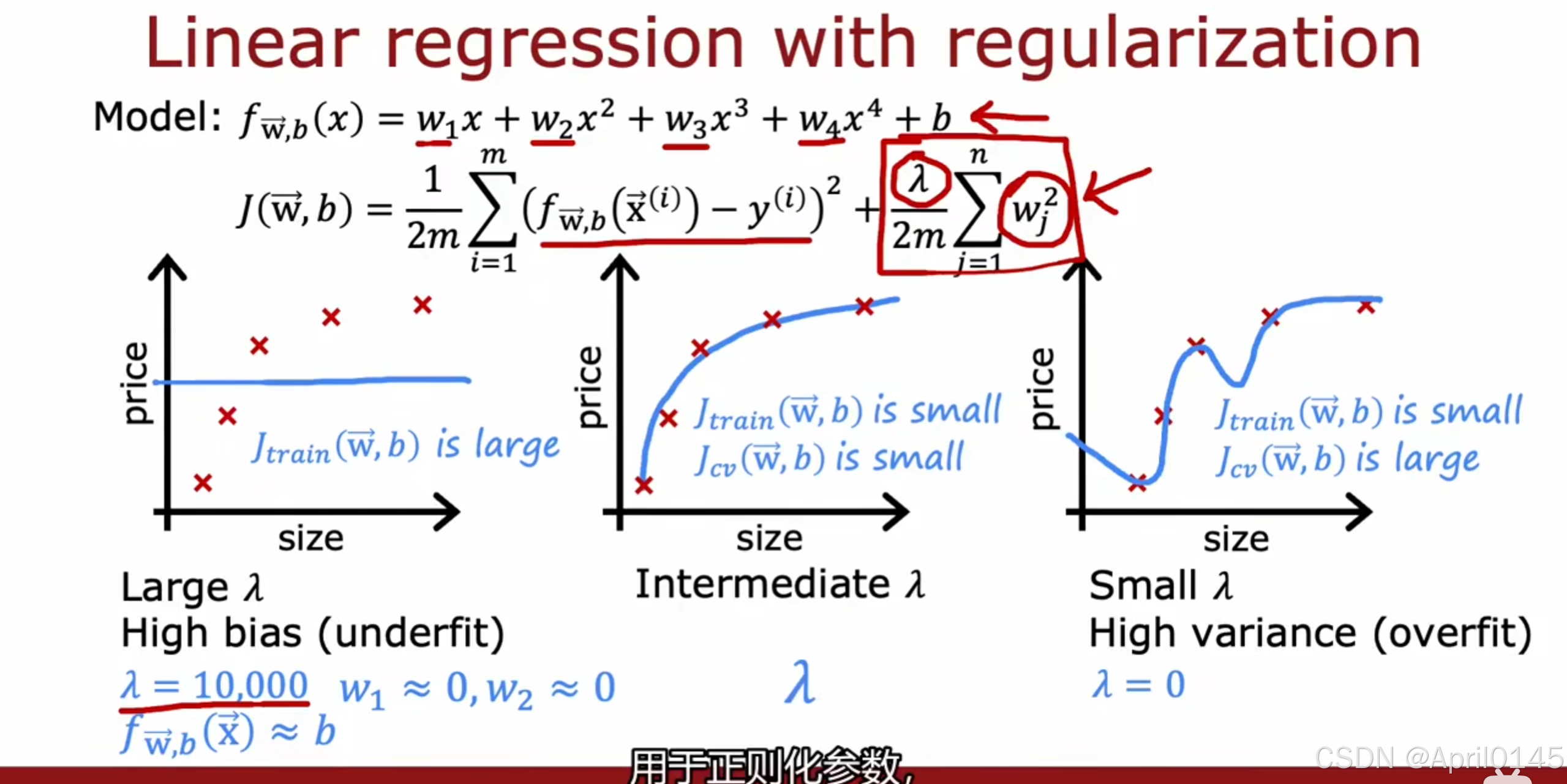
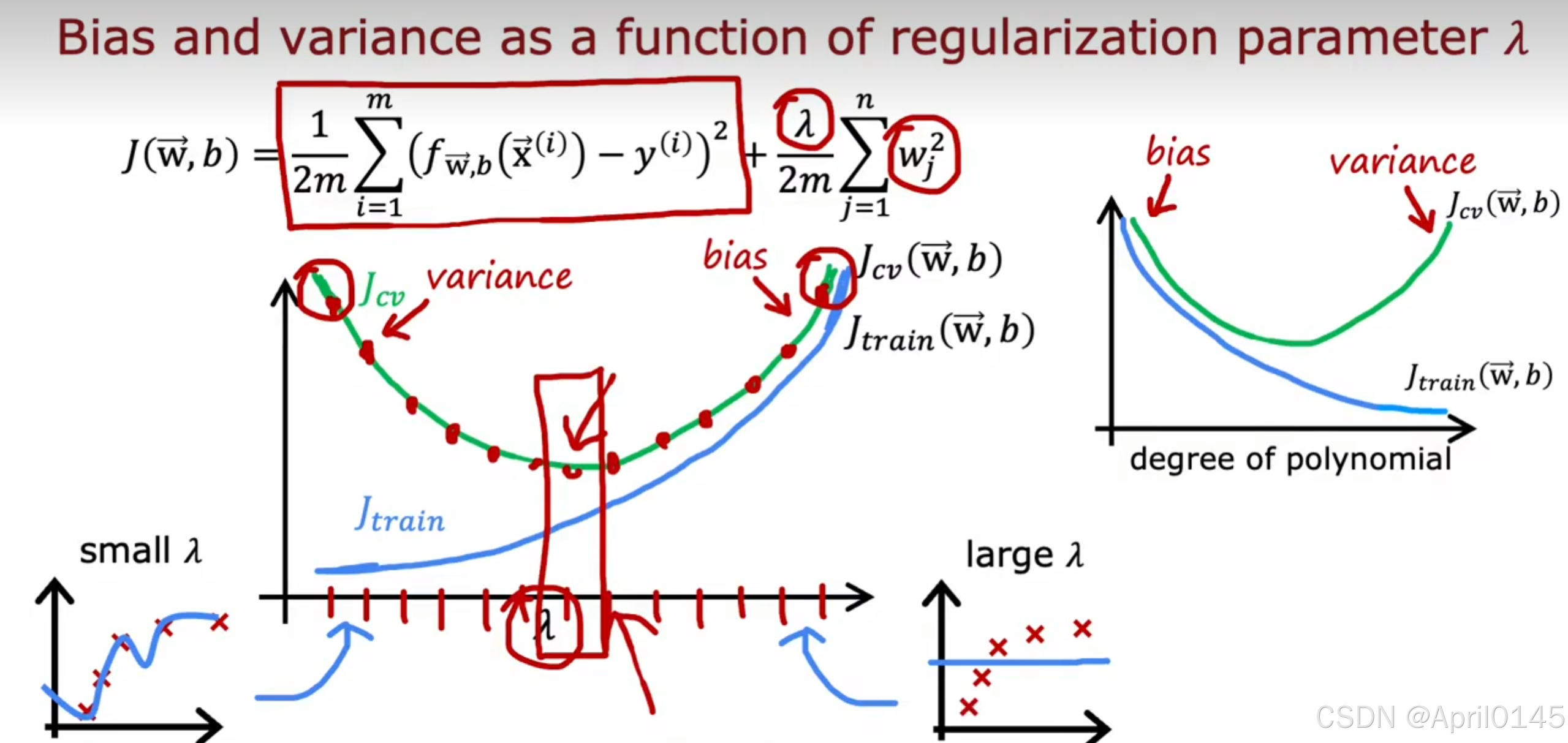

degree of polynomial:多项式的数量
2.3,制定一个性能评估的标准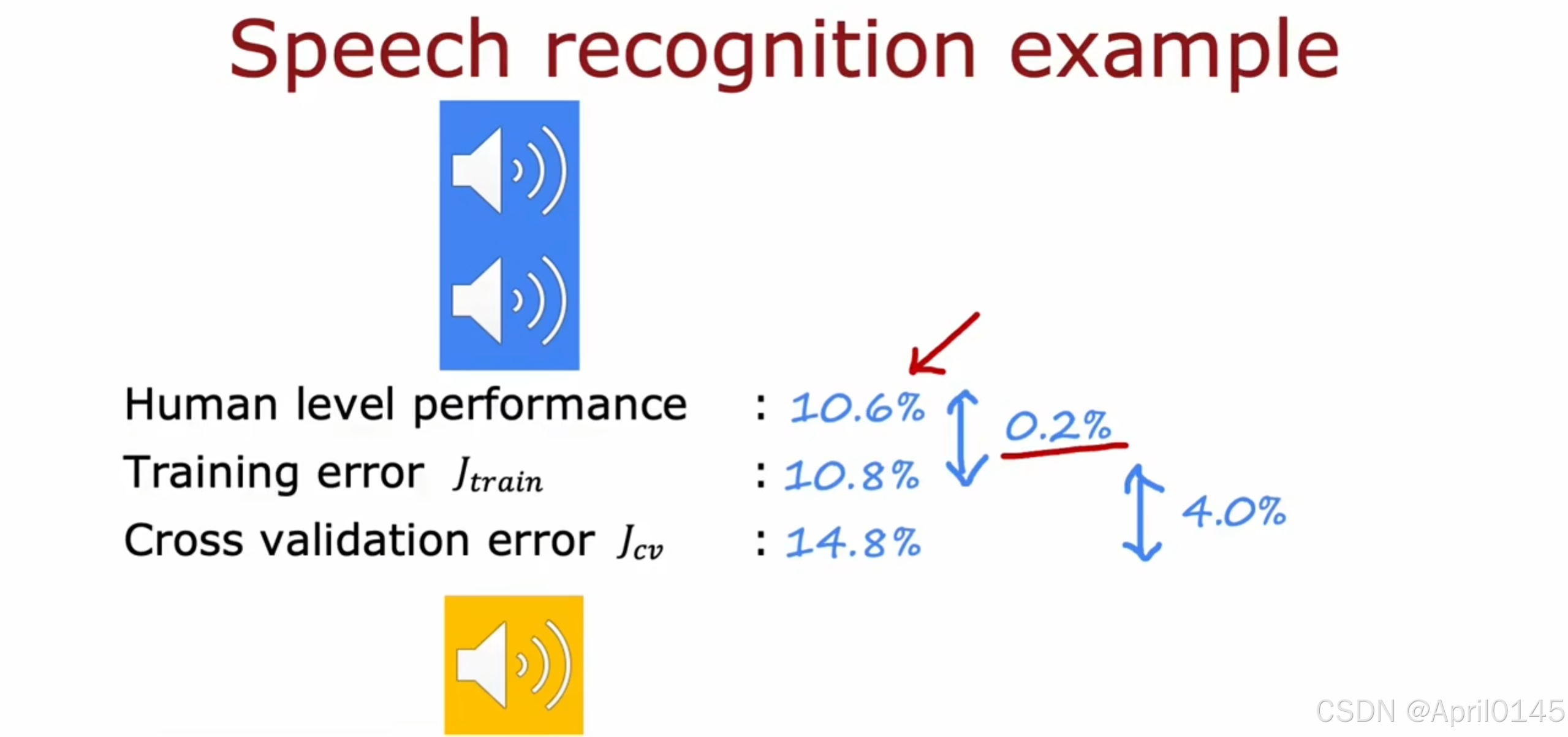
语音识别例子
人类水平的表现
训练误差
交叉验证误差

建立一个性能评估标准
你能合理的希望达到什么程度的错误
1,人类水平的表现
2,竞争算法的表现
3,根据以往经验的猜测

high variance:高方差,过拟合
high bias:高偏差,欠拟合
2.4,学习曲线
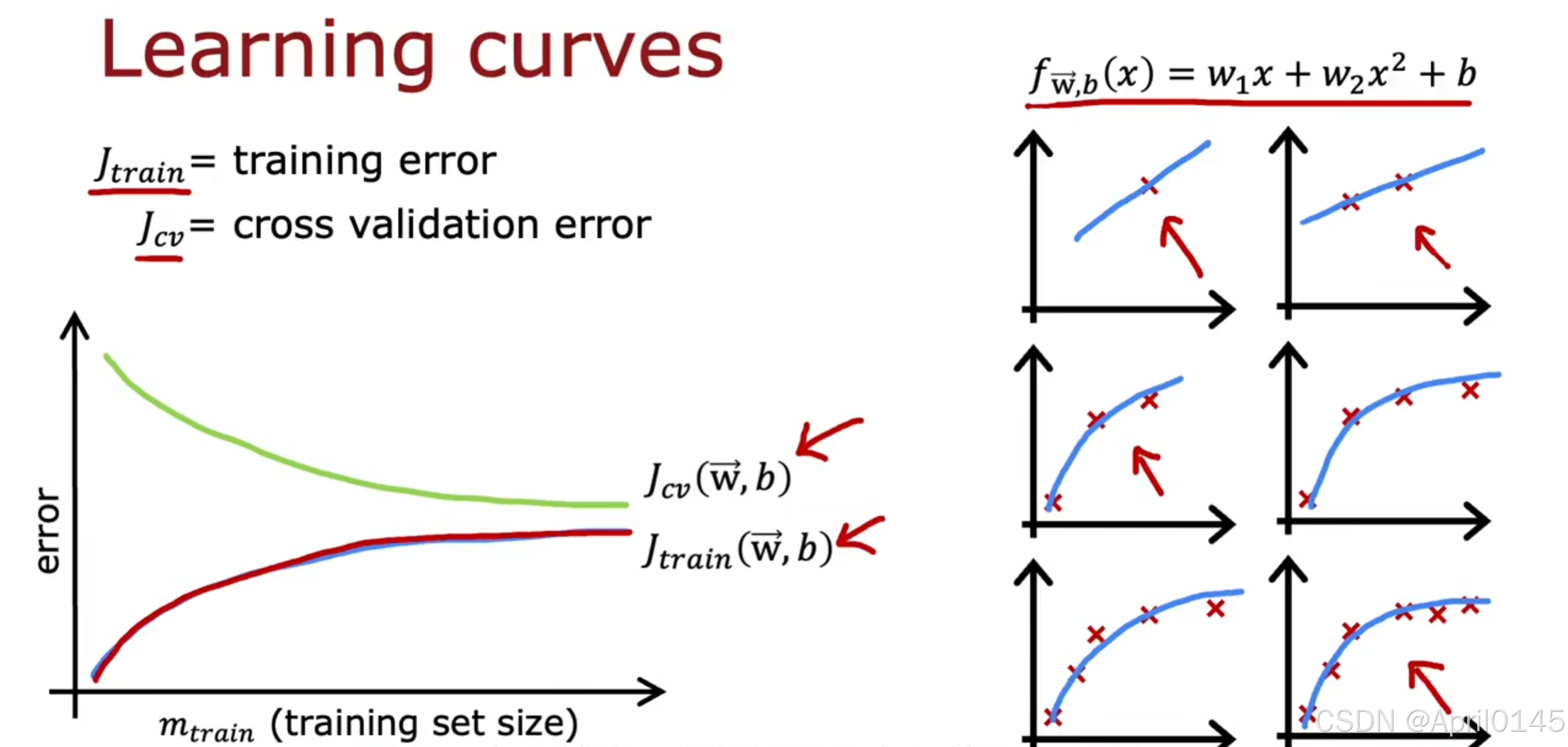
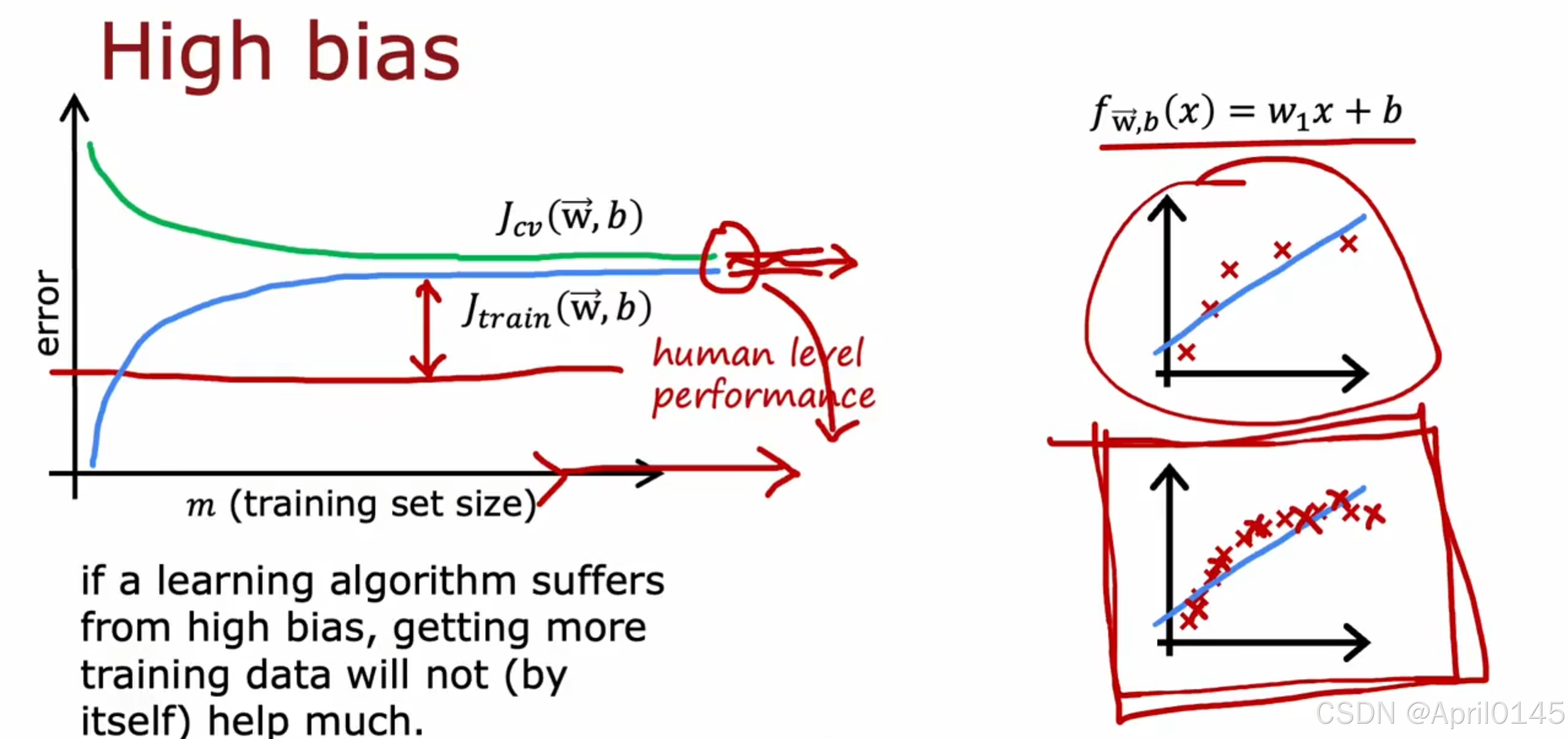 在算法具有高偏差时,无论增加多少数据集,误差也不会降低
在算法具有高偏差时,无论增加多少数据集,误差也不会降低
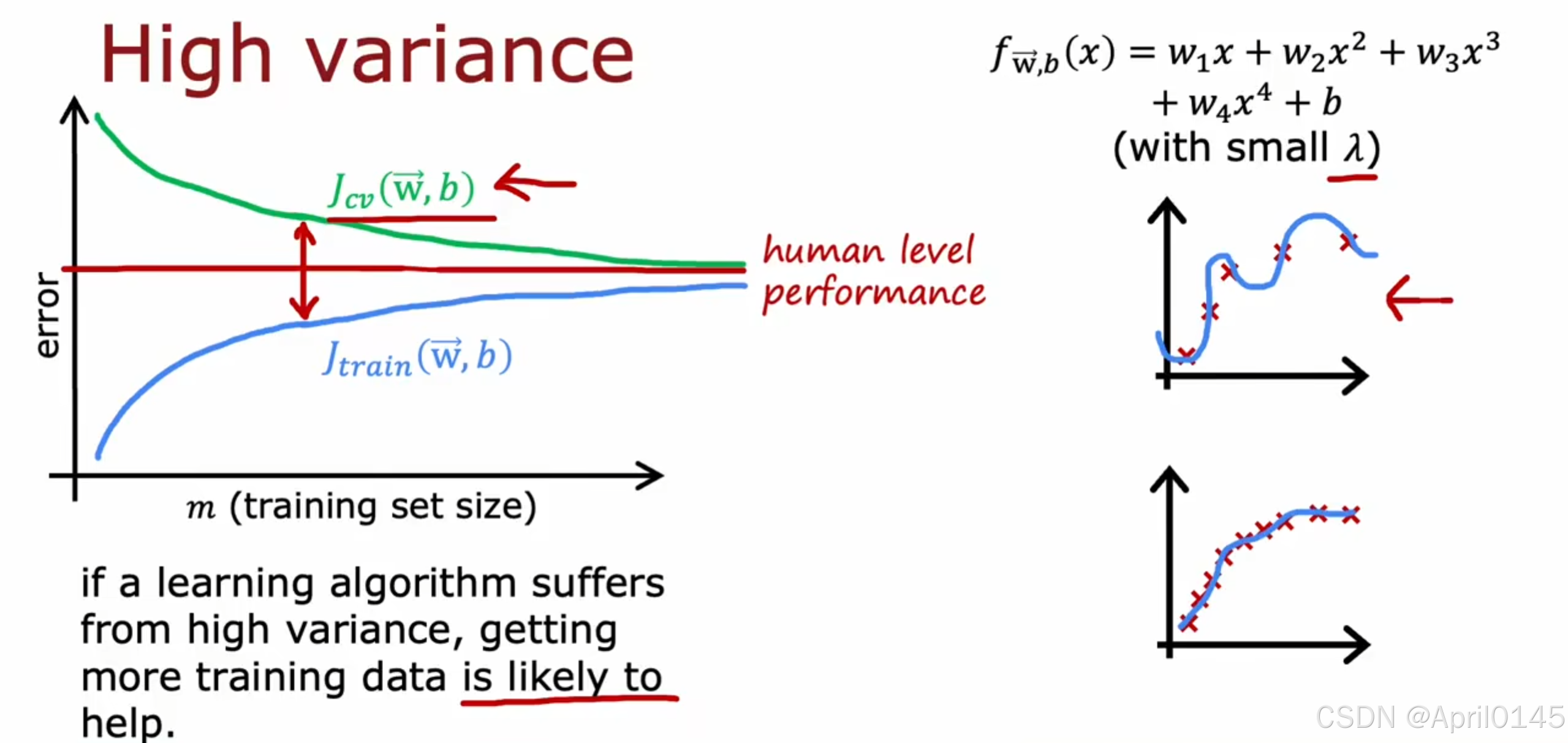
在算法具有高方差时,增加数据集会对你有帮助
运用学习曲线的缺点:训练的计算成本非常高
2.6,神经网络与方差和偏差
tradeoff:权衡

大规模神经网络能更好地拟合复杂数据,因此在训练集上表现出较低的偏差
Jt和性能指标差距过大—>高偏差—>使用更大的神经网络—>再次检测—>Jcv和Jt差距过大—>高方差—>获取更多的数据
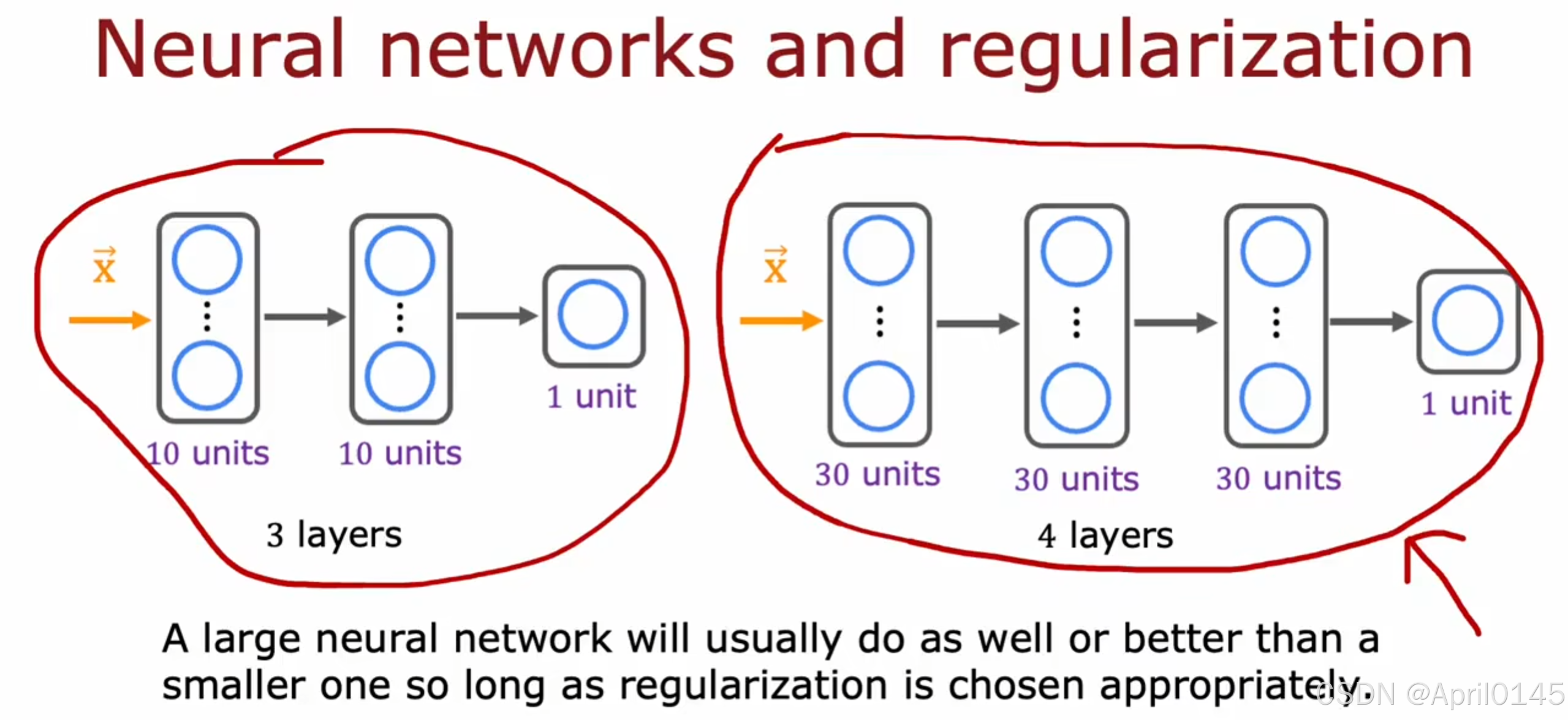
神经网络和正则化
只要适当选择正则化,大的神经网络往往比较小的神经网络更好
缺点:一个大的神经网络会降低你的算法的运行速度
3.1,机器学习开发的迭代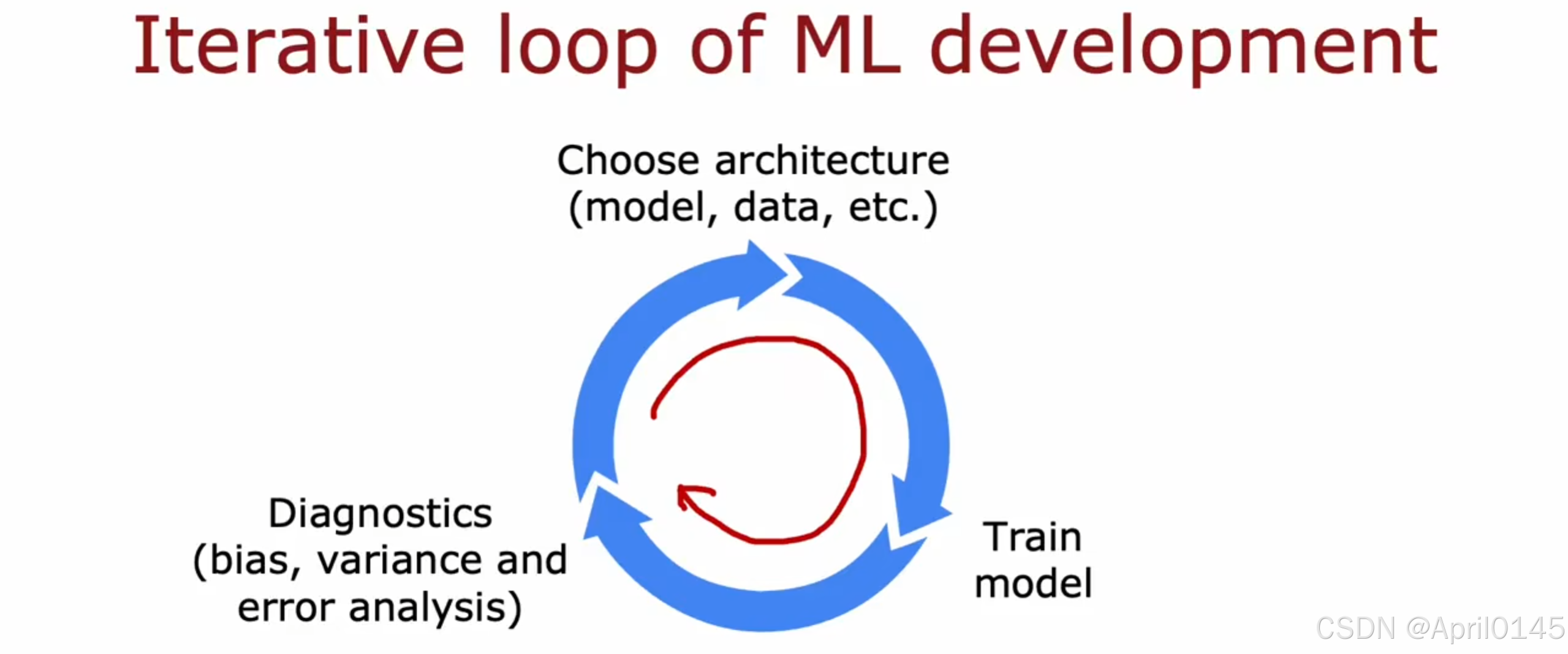
机器学习开发的迭代循环
1,选择架构(模型,数据,超参数)
2,训练数据
3,诊断(偏差,方差和错误分析)
然后重新选择或调整架构,不断迭代直到满足你所需要的性能
3.2,错误分析
误差分析
Mcv = 交叉验证集中的500个示例
算法错误地分类了其中的100个
手动检查100个示例,并根据共同特征对它们进行分类
例子:垃圾邮件分类
卖药(广告):21个
故意拼写错误:3个
不寻常的电子邮件来源:7个
窃取密码(网络钓鱼):18个
嵌入式图像中的垃圾邮件:5个
对于占比较大的比如卖药和网络钓鱼:
1,收集更多的相关数据用于训练
2,选取更合适的特征
对于占比较少的,在时间紧张的情况下可以先搁置
3.3,添加更多的数据
在数据收集中,尝试获取更多所有类型的数据可能即慢又昂贵,
可以专注于添加更多分析表明可能有帮助的类型的数据(比如错误分析)
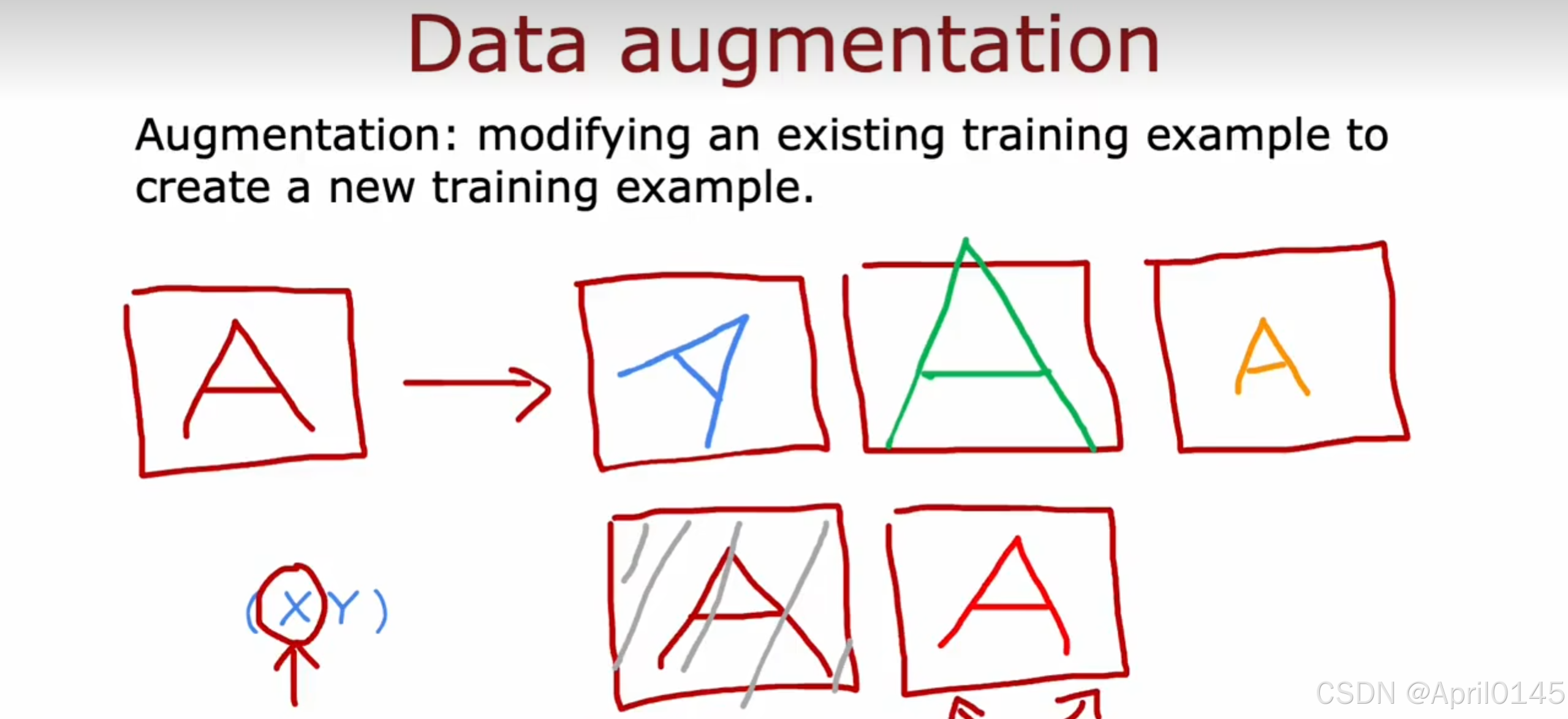 数据增强
数据增强
增强:修改现有的训练示例以创建新的训练示例
例子:对字母A的识别
可以把A放大,缩小,倒过去......
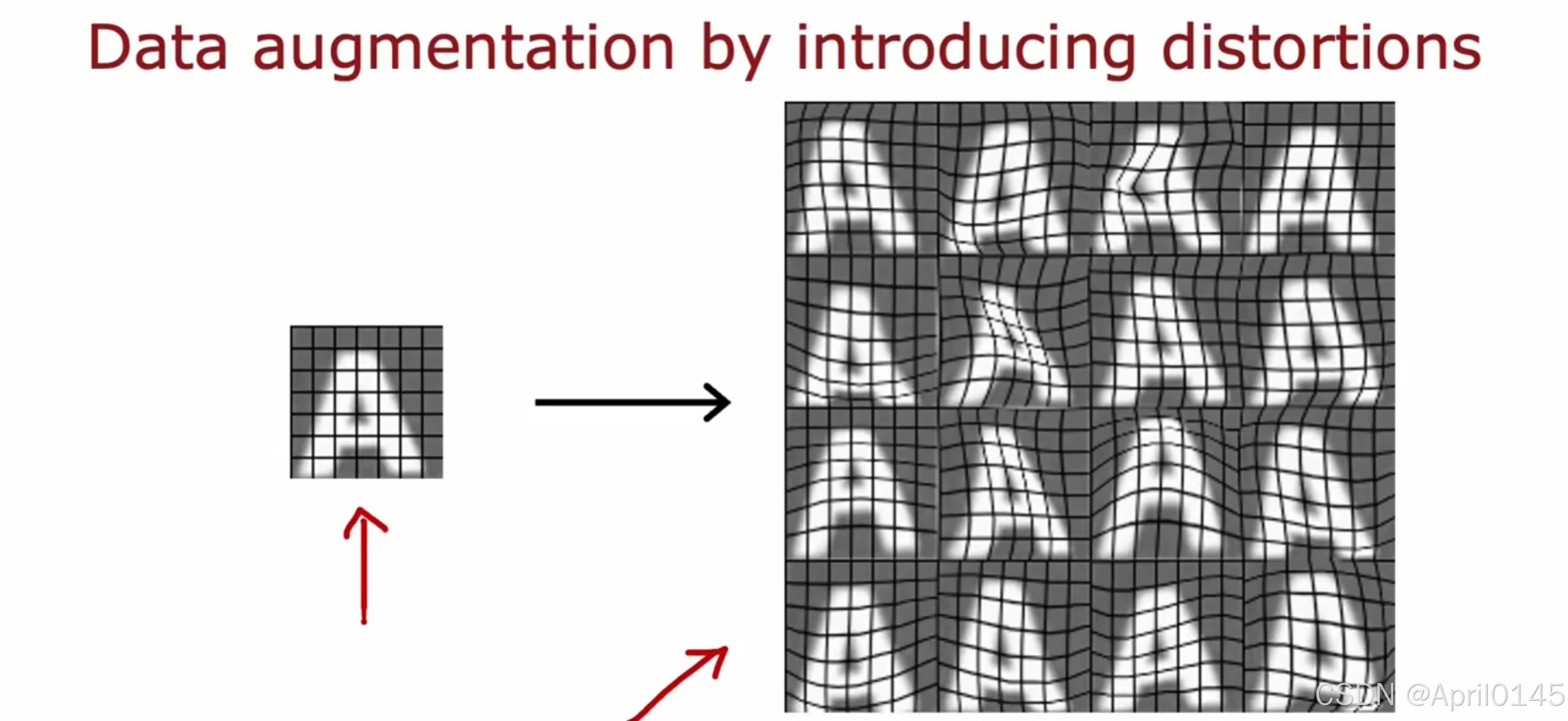
通过引入失真来增强数据
更高级别的数据增强示例
取字母A并将其放在一个网格上,通过对这个网格的随机扭曲,你可以取字母A新的训练示例

数据增强对于语言识别同样适用
语音识别例子:
原始音频(语言搜索:“今天天气怎么样”)
加吵闹的背景:人群
加吵闹的背景:汽车
加手机连接不良的音频

通过引入失真来增强数据
引入的失真应该是测试集中噪音/失真类型的表示
音频:背景噪音,手机连接不良
通常对为您的数据添加纯随机/无意义的噪音通常没有帮助
例如:在图像识别中对每个像素添加噪音

数据合成:
使用人工数据输入来创建一个新的训练示例

 使用计算机文本编辑器合成的数据
使用计算机文本编辑器合成的数据
合成数据的方法多用于计算机视觉当中,较少应用于其它计算机程序当中

对你的系统设计数据的使用
传统的以模型为中心的方法
以数据为中心的方法
3.4,迁移学习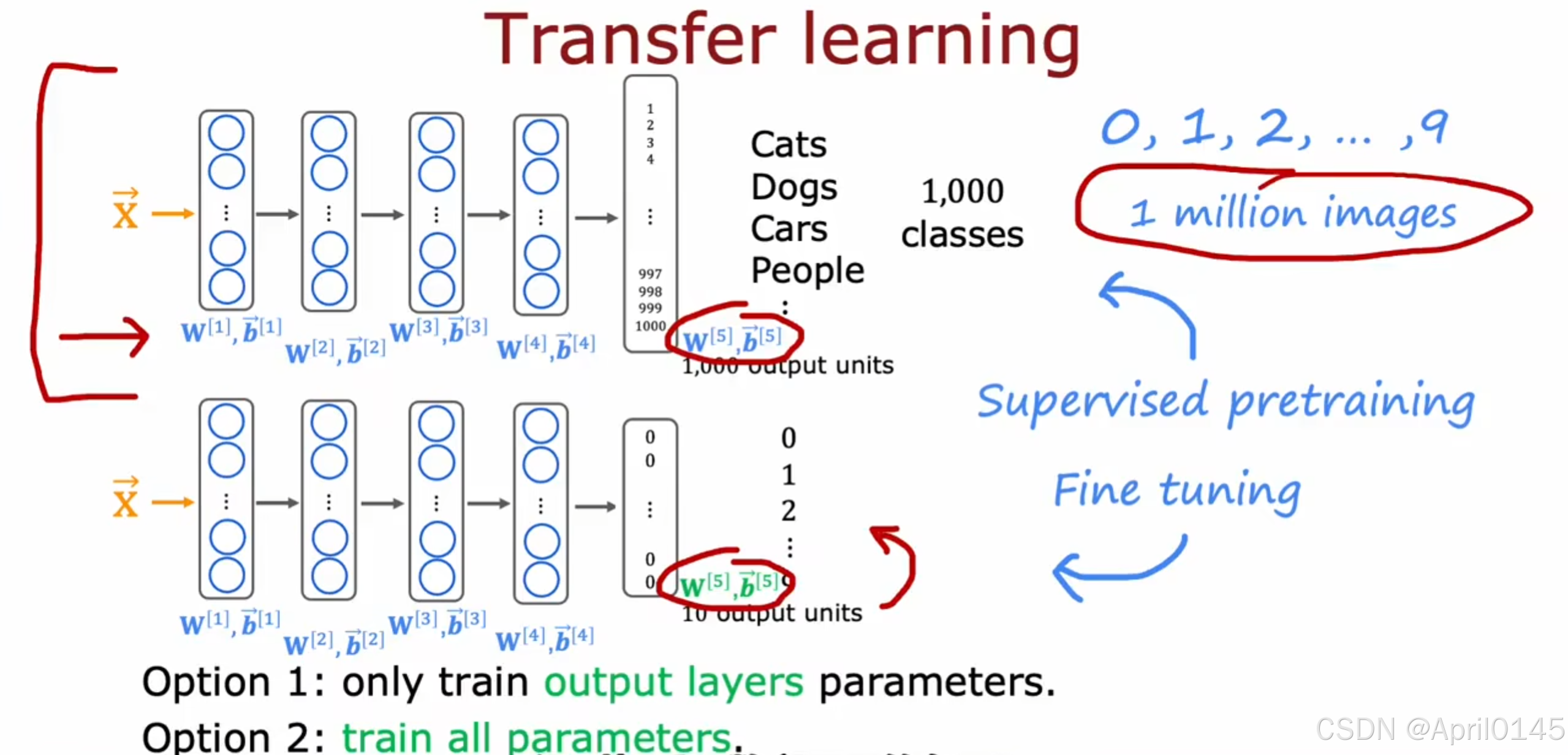
transfer learning:迁移学习
假设你要训练0到9手写数字的识别,但你已有的数据集不足
但你之前训练过从1百万张图片中识别出,狗,猫,人等不同的1000个类别的神经网络模型
supervised pretraining:监督预训练
fine tuning:调优
迁移学习步奏:
第一步:监督预训练(预训练):在大型数据集上进行训练,比如1百万张不完全相关任务的图像
第二步:调优:根据从监督预训练中获取的参数和模型,然后使用你较小的数据集比如1万张手写数据集
进一步运行梯度下降以微调权重来适应你手写数字识别的特定应用
选项一:只训练输出层的参数
选项二:训练全部的参数
如果你的数据很小,推荐选项一,如果你的数据稍多,推荐选项二
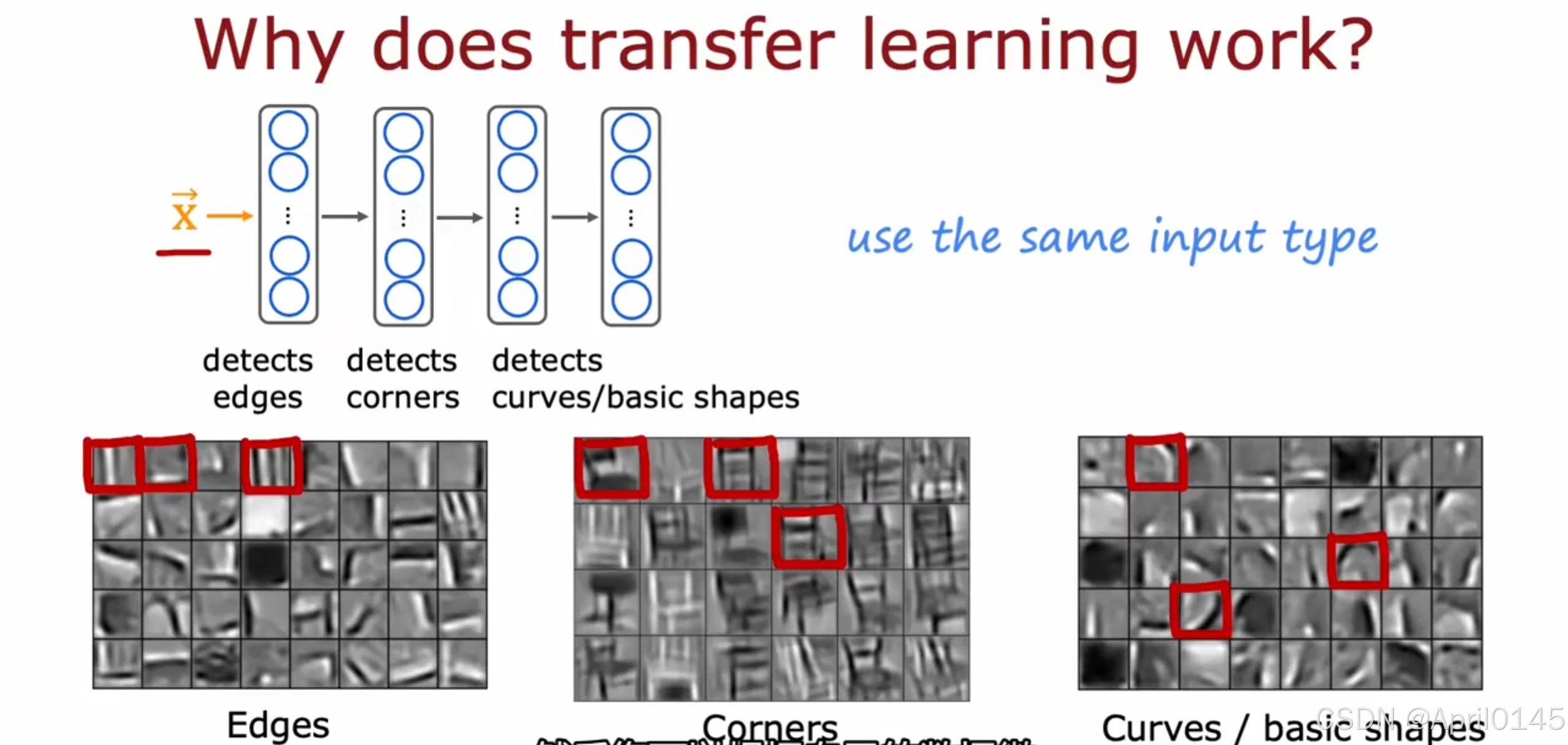
迁移学习如何工作
detects edges:检测边缘
detects corners:检测角落
detects curves/basic shapes:检测曲线/基本形状
在使用相同的输入类型,比如图像检测中,神经网络一般都会先检测物体的边缘,到角落再到基本形状

迁移学习总结
1,下载与你应用程序相同的输入类型(例如图像,音频,文本)的大型数据集中预先训练的神经网络参数,或训练自己的
数据集
2,进一步用你的数据训练(微调)神经网络
3.5,机器学习项目的完整周期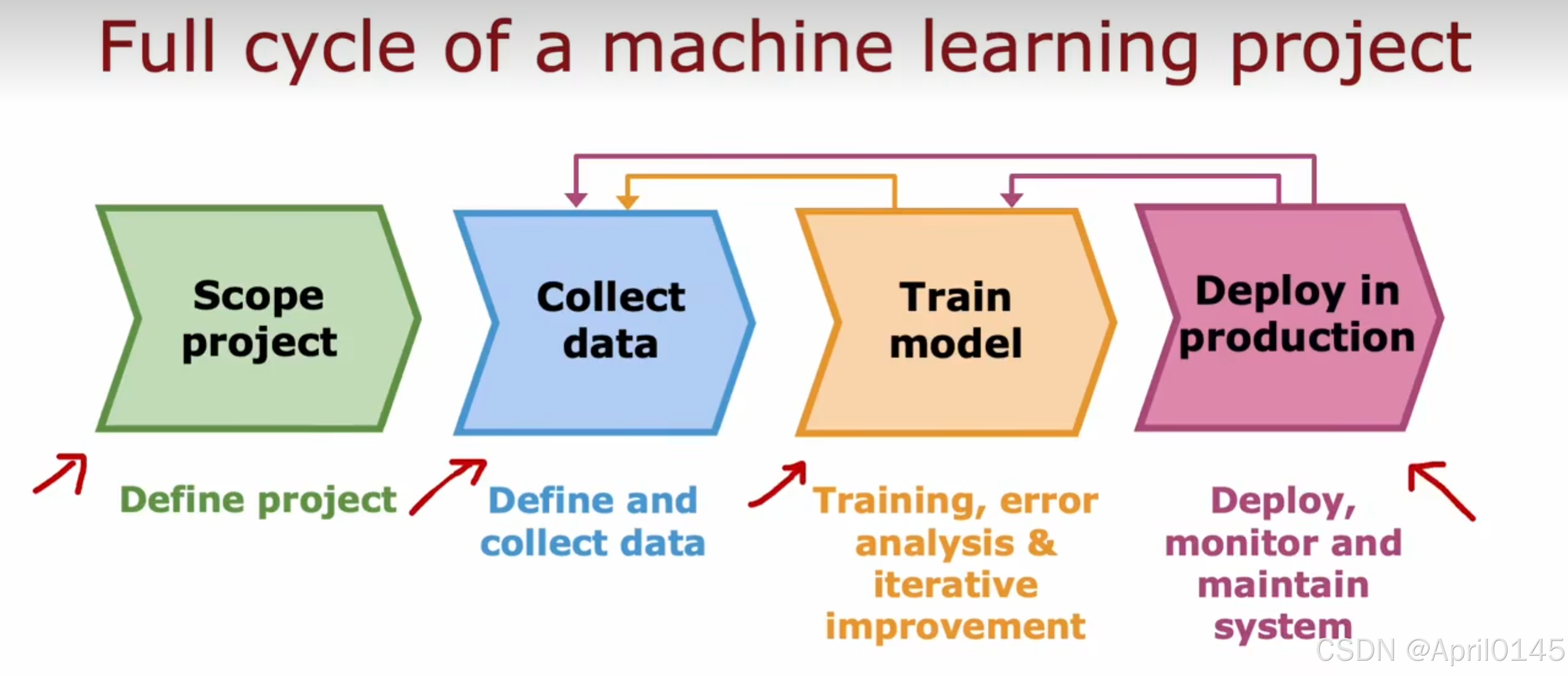
机器学习项目的整个周期 define:定义
第一步:确定项目的范围
定义目标
第二步:收集数据
定义并收集数据
第三步:训练模型
训练,错误分析和迭代改进
第四步:部署在生产中
部署,监控和维护系统
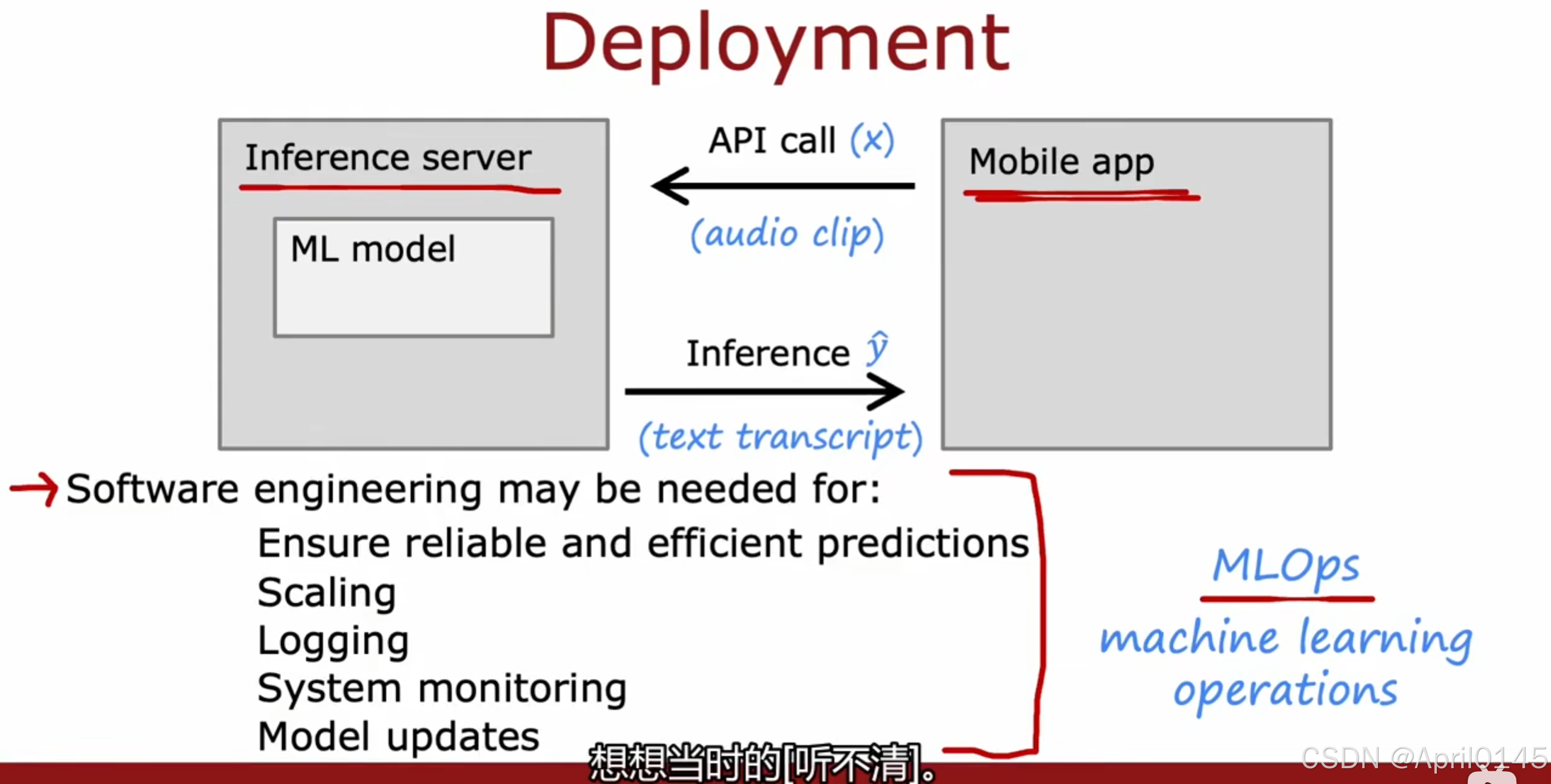
deployment:部署
inference server:推断服务器
API调用(x)
audio clip:音频剪辑
text transcript:文本记录
软件工程可能用于:
确保可靠和高效的预测
用户拓展
日志
系统监控
模型更新
MLOPS:机器学习的操作
4.1,倾斜数据集的误差指标
罕见疾病分类示例
训练分类器Fw,b
如果存在疾病,y = 1,否则y = 0
发现在测试集上只有百分之1的误差(99%的正确率)
只有0.5的患者患这种病
accuracy:准确率 error:误差
对于倾斜数据集,假设这里有三个算法,误差分别为0.5,1,1.2很难区分哪个更好
因为误差最低的可能不是特别有用的预测,因为y预测总是为0,很难诊断出有患者患这种病
使用不同的错误度量来确定学习算法的表现如何
precision/recall:精确率和召回率 actual:实际的 predicted:预测的
我们想要检测的稀有类中y = 1存在
精确率:精确率关注的是模型的准确性,表示在所有预测为正的样本中,真正有多少是对的。
召回率:召回率则关注的是模型的完整性,表示在所有实际正样本中,有多少被正确识别出来。
在某些应用中,如医疗诊断或垃圾邮件过滤,可能更关注召回率,因为漏掉一个正例可能带来严重后果。
在其他场合,如金融欺诈检测,可能更关注精确率,以避免误报。
4.2,精确率和召回率的权衡
权衡精确率和召回率 threshold:阈值
通过提高阈值可以获得更高的精确率但召回率随之降低
通过降低阈值可以获得更低的精确率但召回率随之提高

通过F1 score算法自动选择精确率和召回率
F1 score是一种计算平均分数的算法,它更关注较低的分数
第四周:机器学习中的决策树算法‘
1.1,决策树模型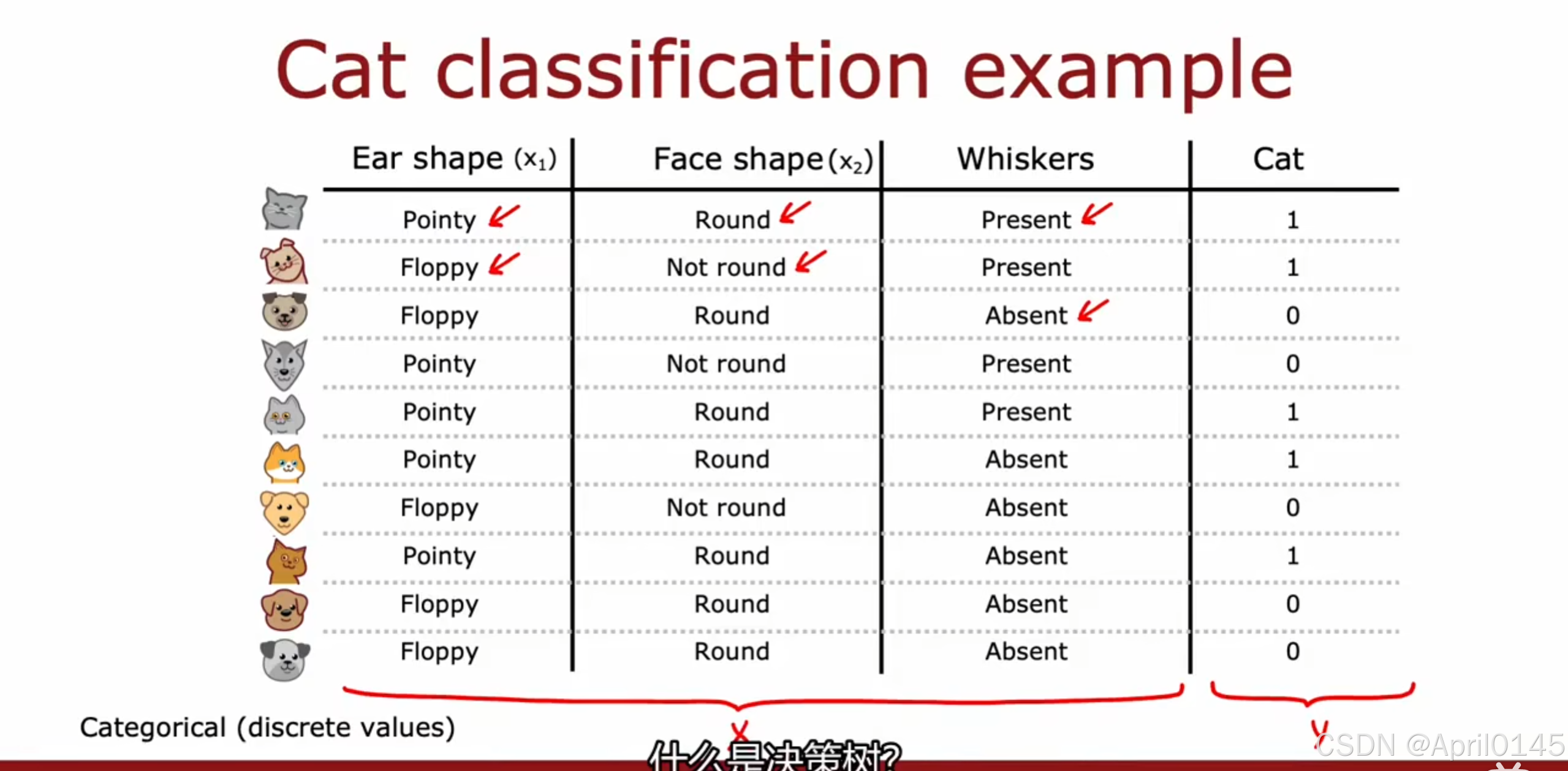
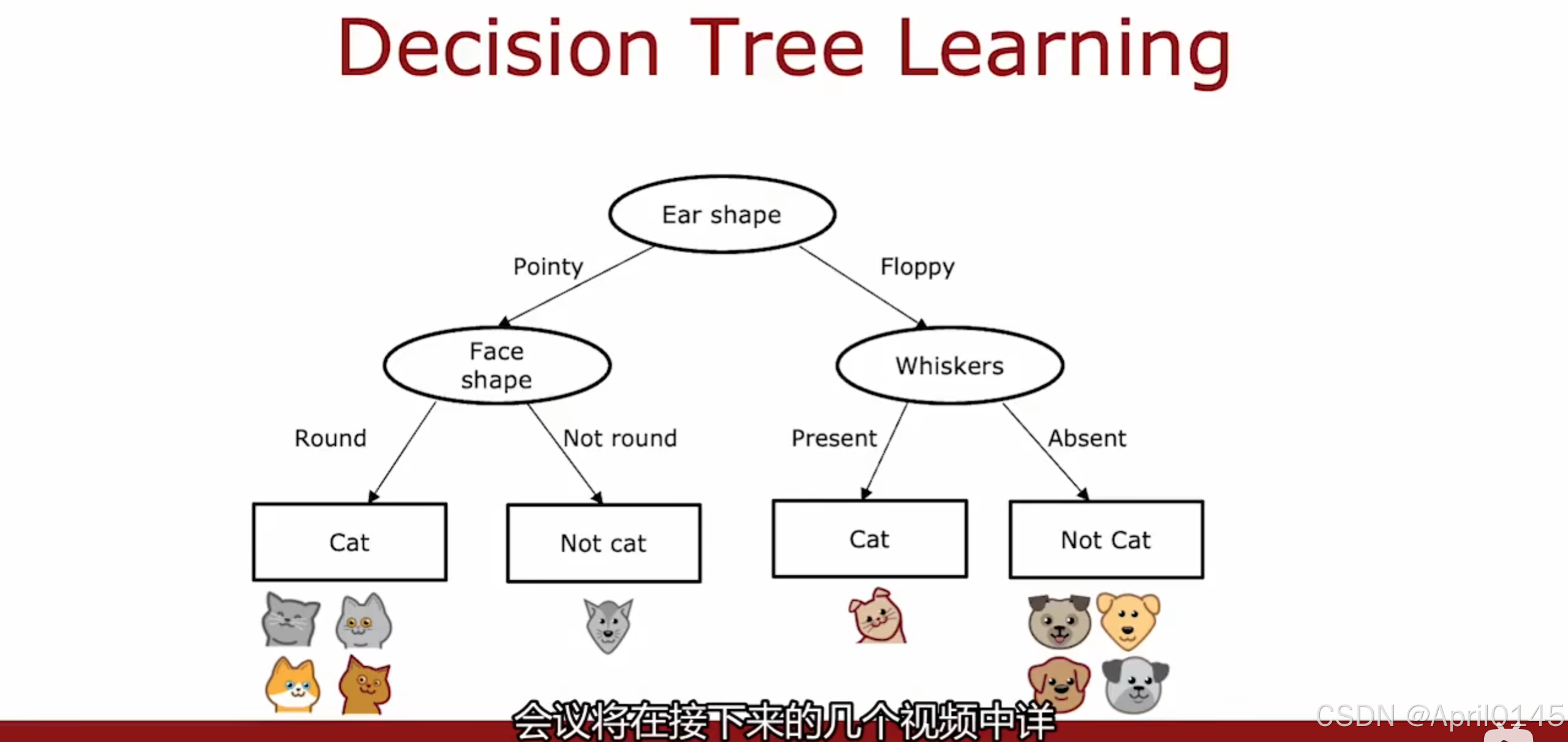
猫分类的例子
whiskers:胡须 pointy:尖的 floppy:松软的
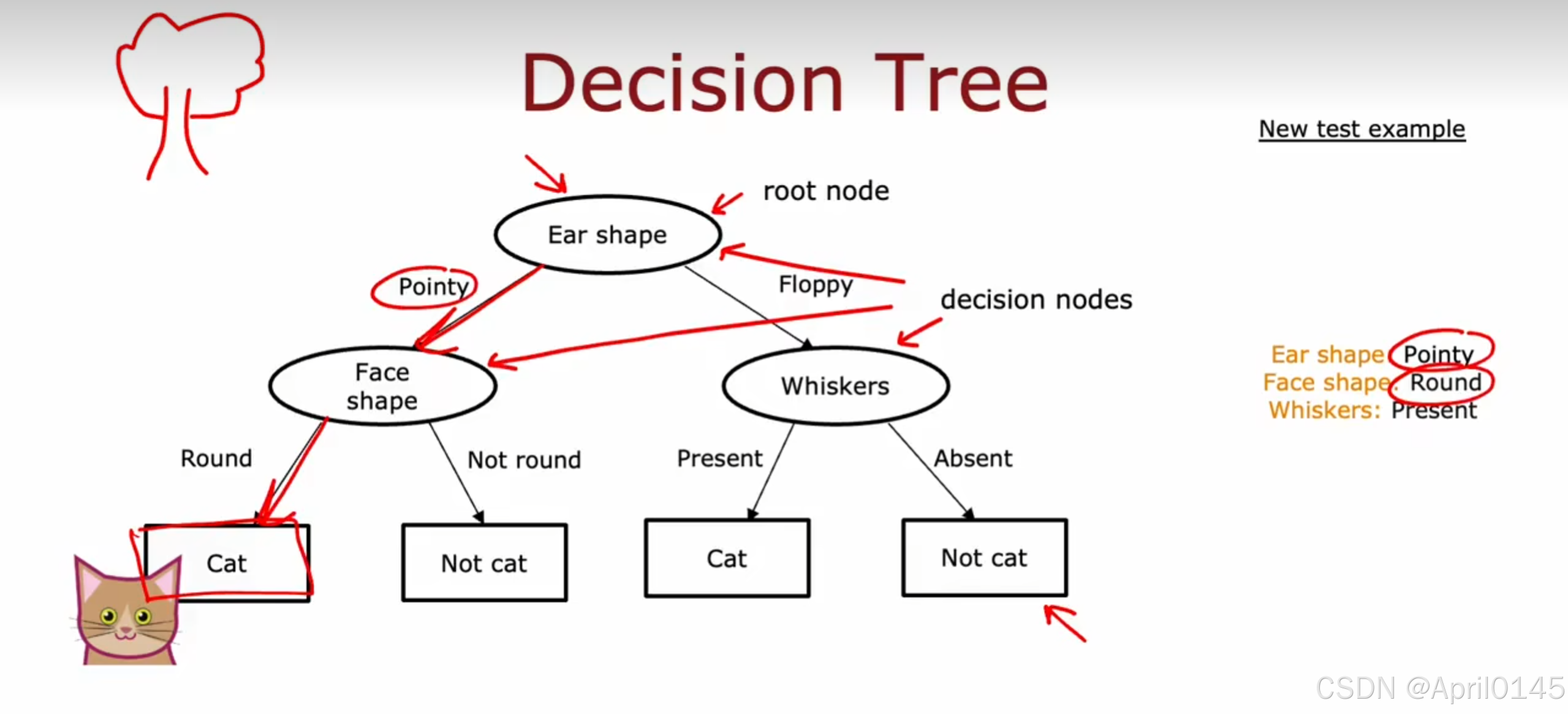
root node:根节点 decision nodes:决策节点
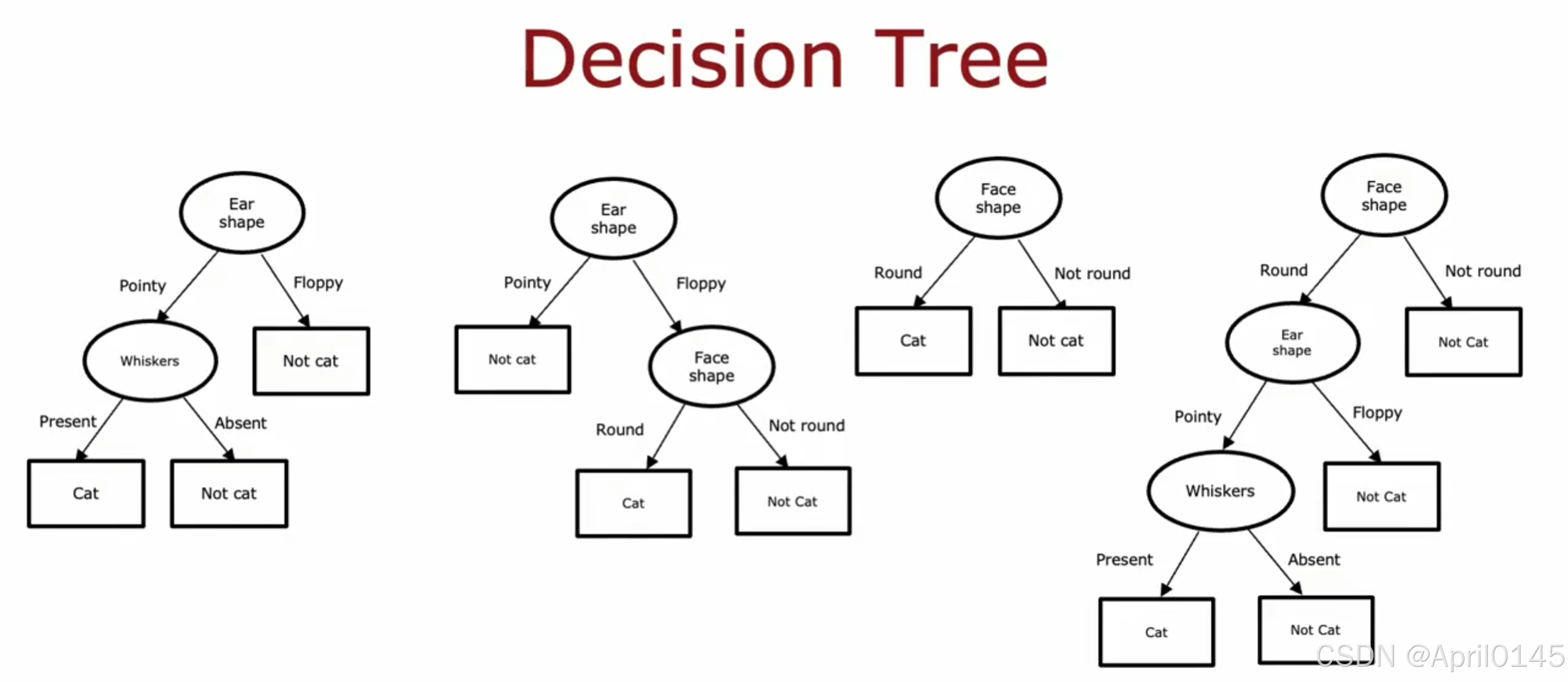
1.2,学习过程
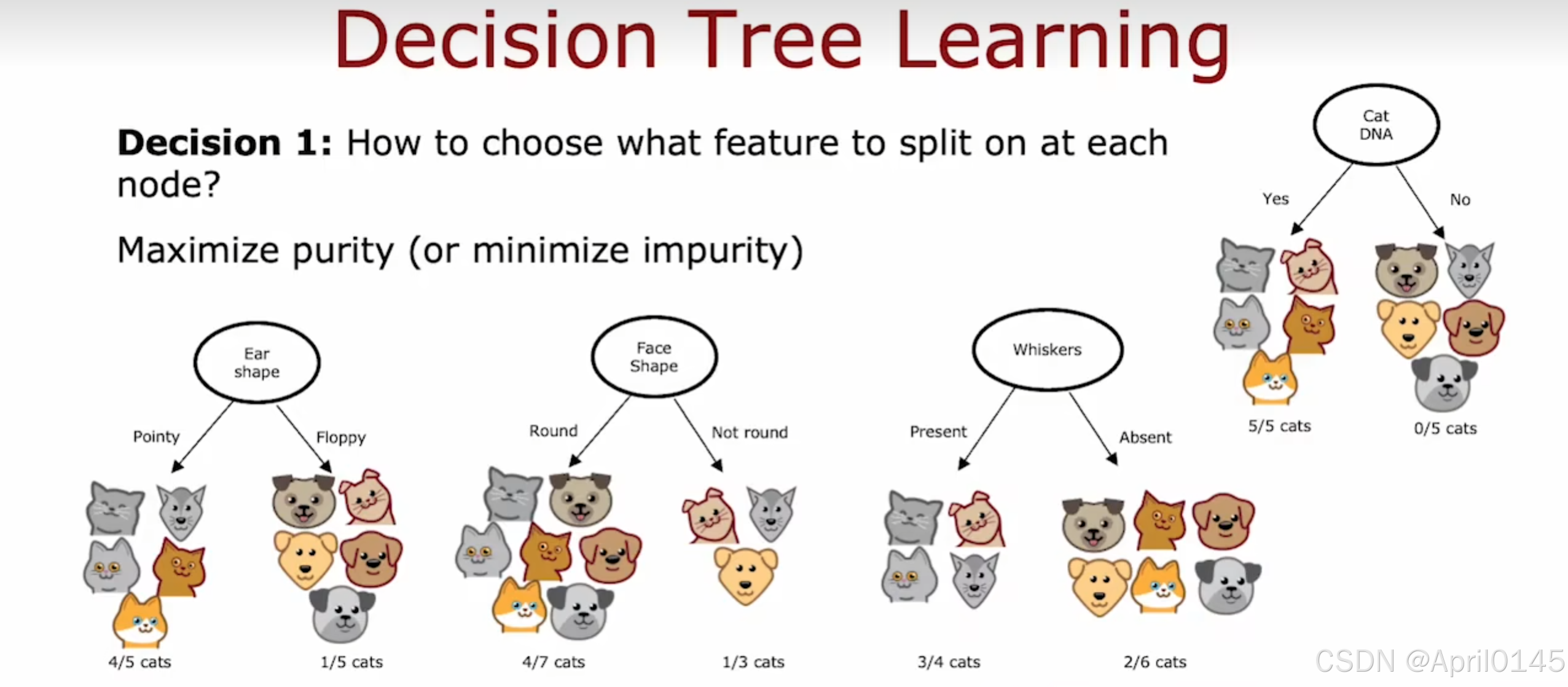 决定一:如何选择每个节点根据什么功能拆分
决定一:如何选择每个节点根据什么功能拆分
最大化纯度(或最小化杂质)

决定2:什么时候停止分裂
当一个节点100%是一个类时
拆分节点会导致超过你设置的最大深度时
当纯度分数提高低于阀值时(对纯度的改善太小)
当节点中的示例数量低于阀值时
如果树太大,树会变得很复杂且容易过度拟合
所以要在保证收益和保持树不至于太大之间权衡
2.1,纯度
熵作为杂质的衡量标准
熵函数H(p1)越大,纯度越低
p1 = 例子中是猫的一部分

熵函数H(p1)的定义
2.2,选择拆分和信息增益
选择拆分

信息增益
信息增益是用来衡量一个特征对分类任务的有效性。它通过比较使用特征前后的信息熵变化,来评估特征对数据集的“纯度”提升程度。在决策树中,信息增益越大,意味着该特征越能帮助做出准确分类。
2.3,整合
决策树学习
从根节点的所有示例开始
计算所有可能特征的信息增益,并选择信息增益最高的特征
根据所选特征拆分数据集,并创建树的左右分支
继续重复拆分过程,直到满足停止标准:
当一个节点100%是一个类时
拆分节点会导致超过你设置的最大深度时
当纯度分数提高低于阀值时(对纯度的改善太小)
当节点中的示例数量低于阀值时
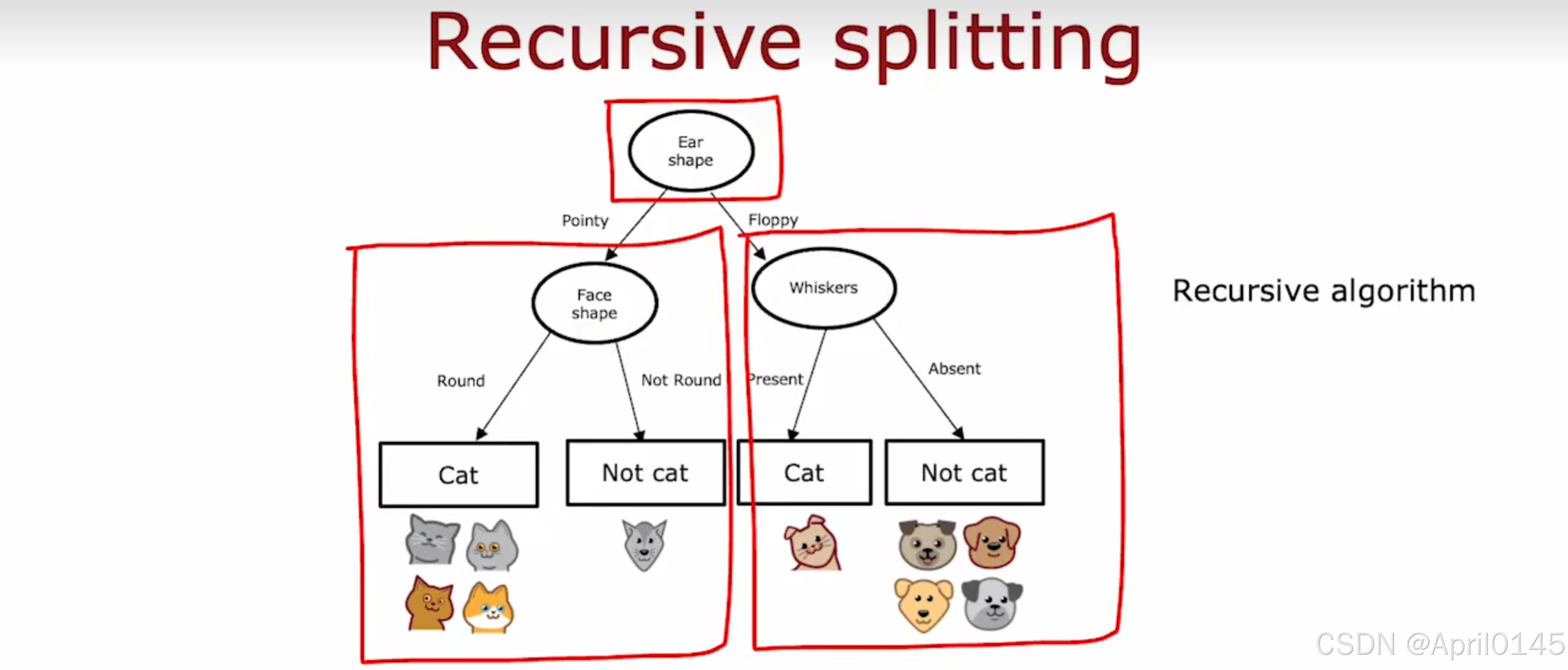
recursive:递归
递归拆分,递归算法
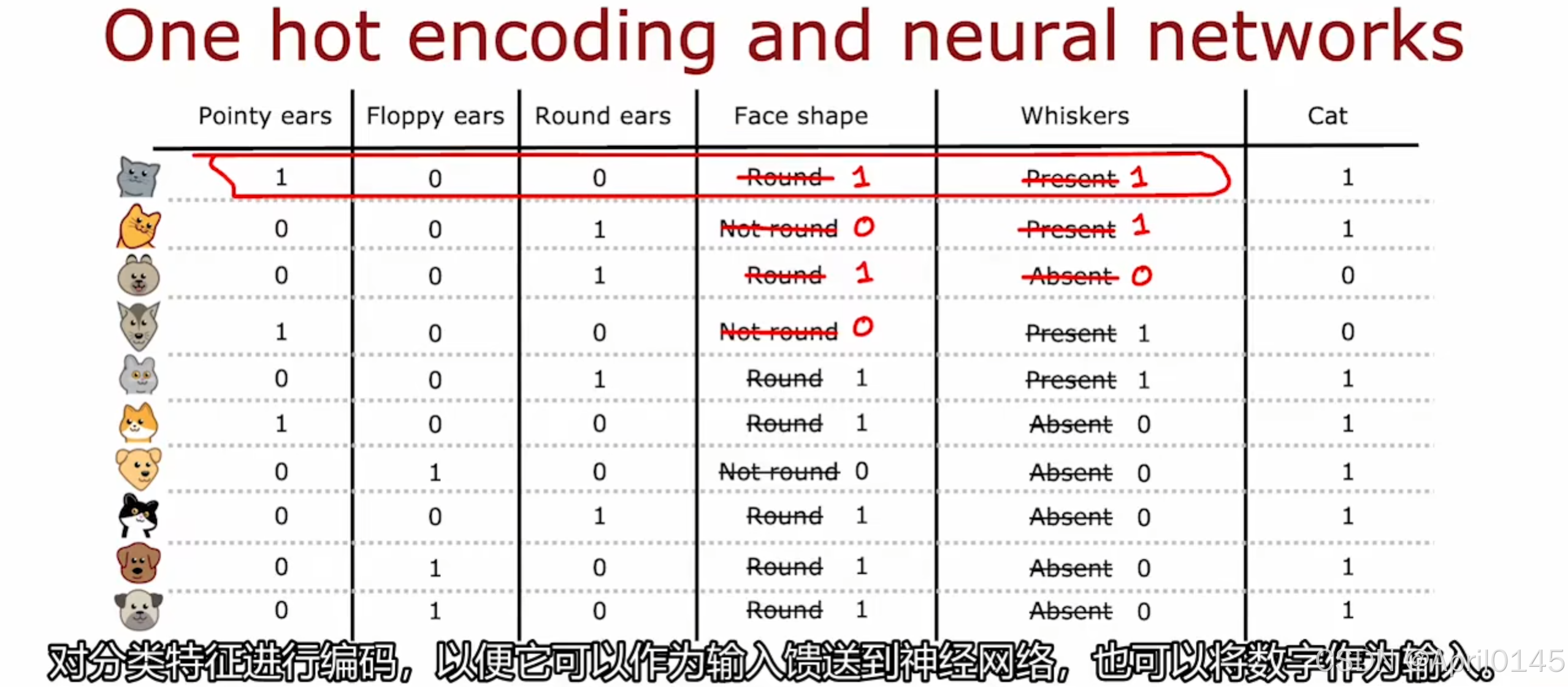
2.4,独热编码one-hot
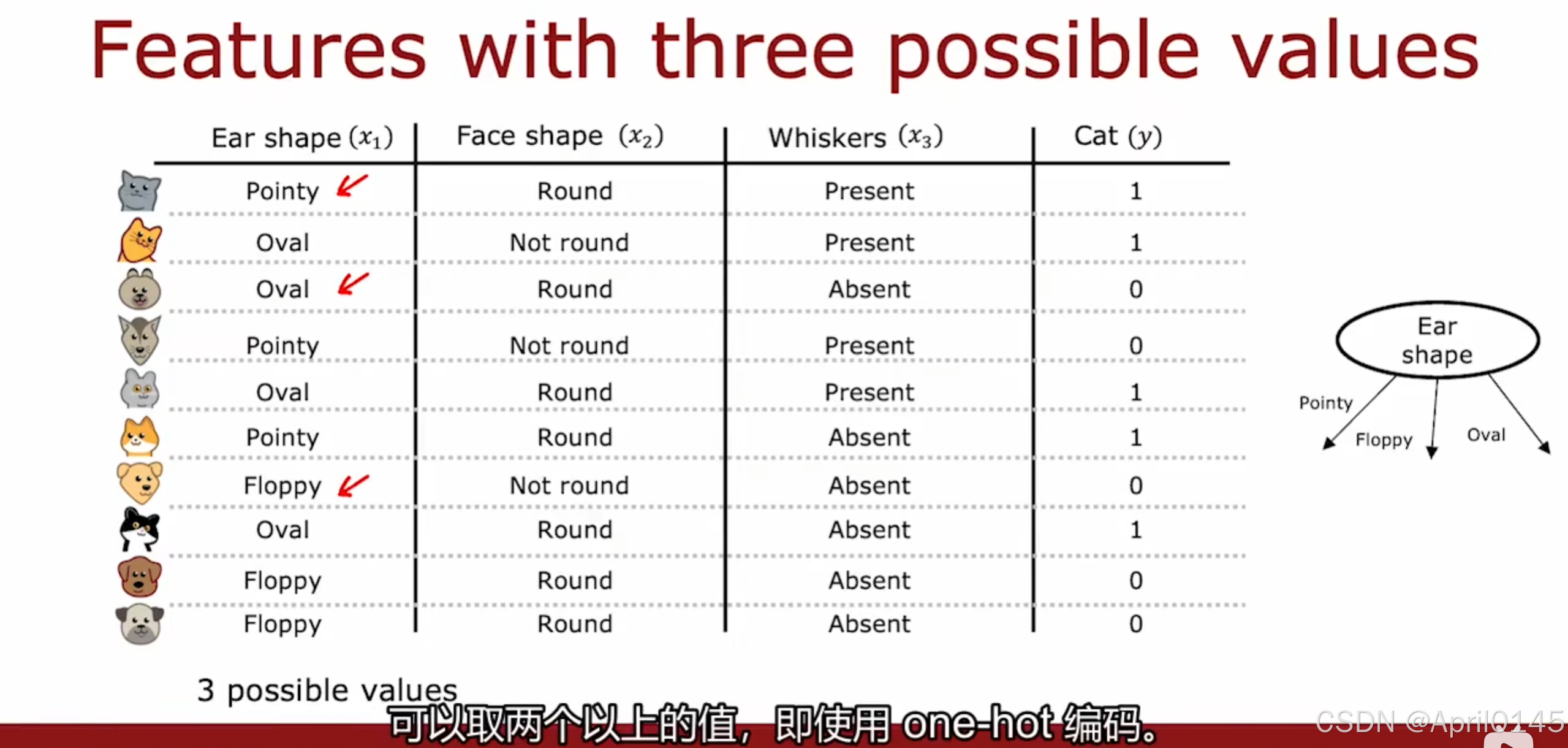
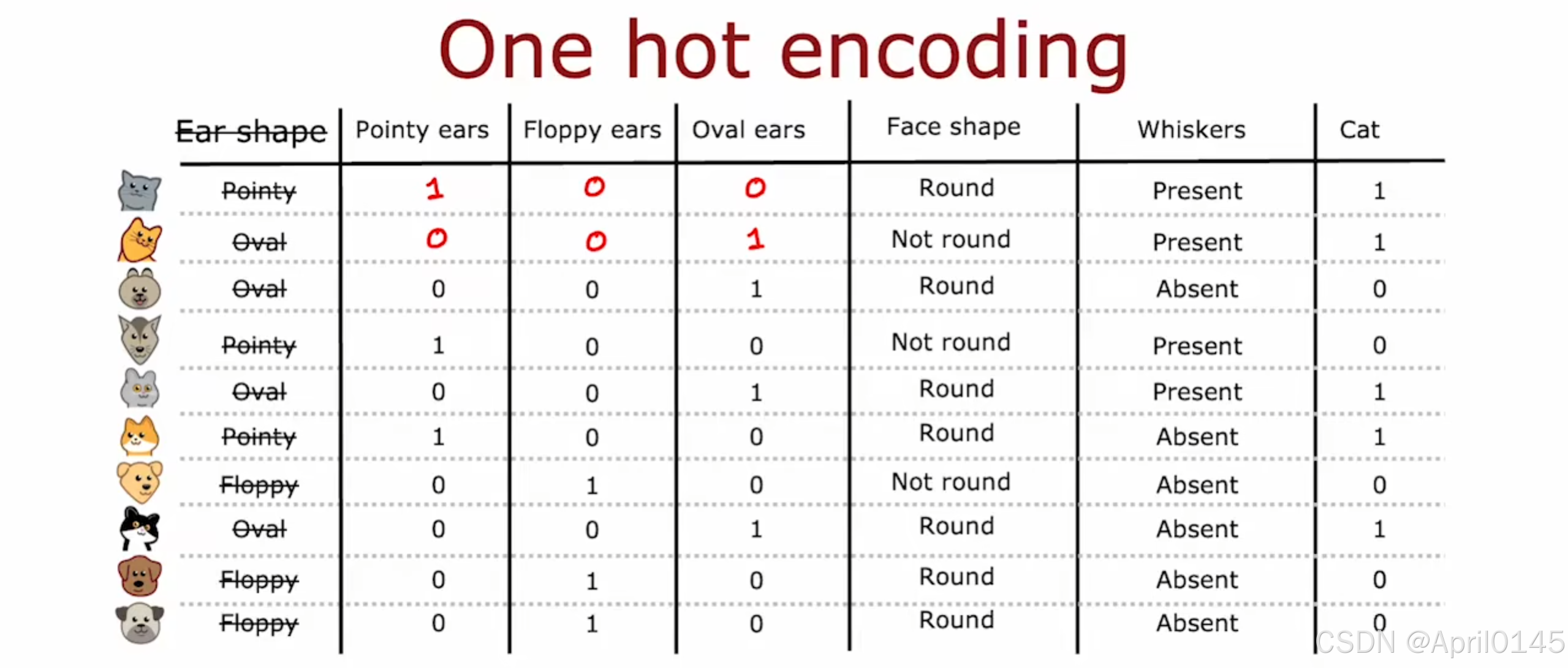
 独热编码
独热编码
如果分类特征可以采用K个值,请创建k个二进制特征(值为0或1)
2.5,连续值特征的拆分
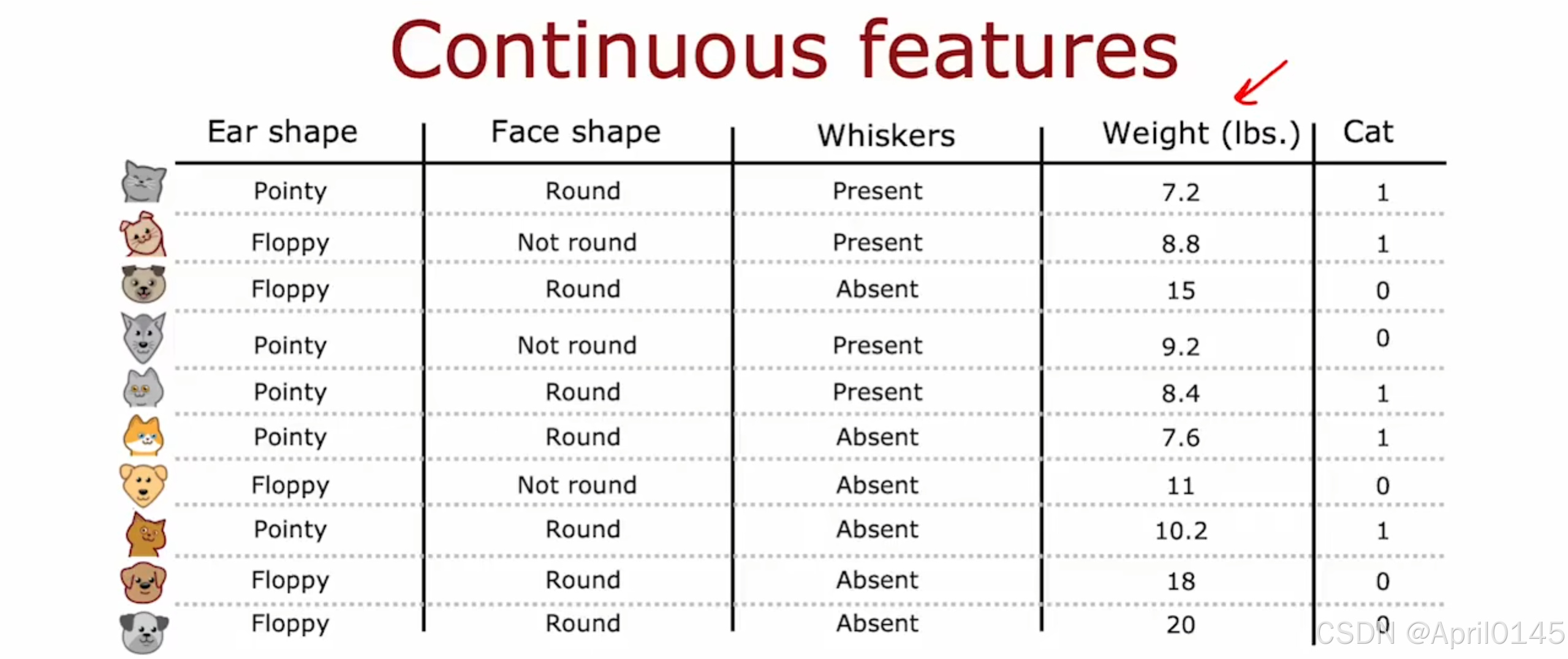
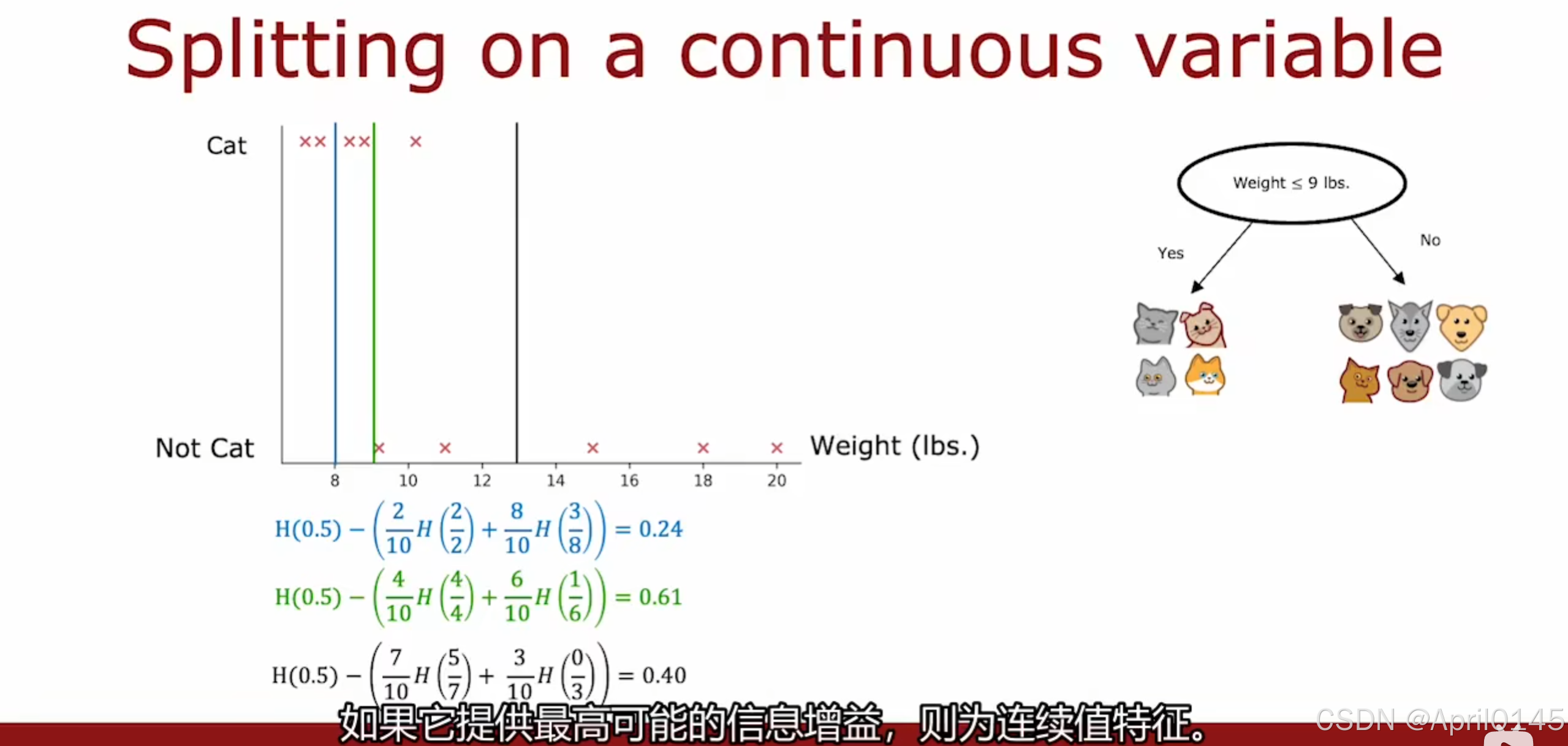 如何对连续变量进行拆分
如何对连续变量进行拆分
如果你有10个示例,你将针对此阈值测试9个不同的值,然后选择为你提供信息增益最高的那一个
2.6,回归树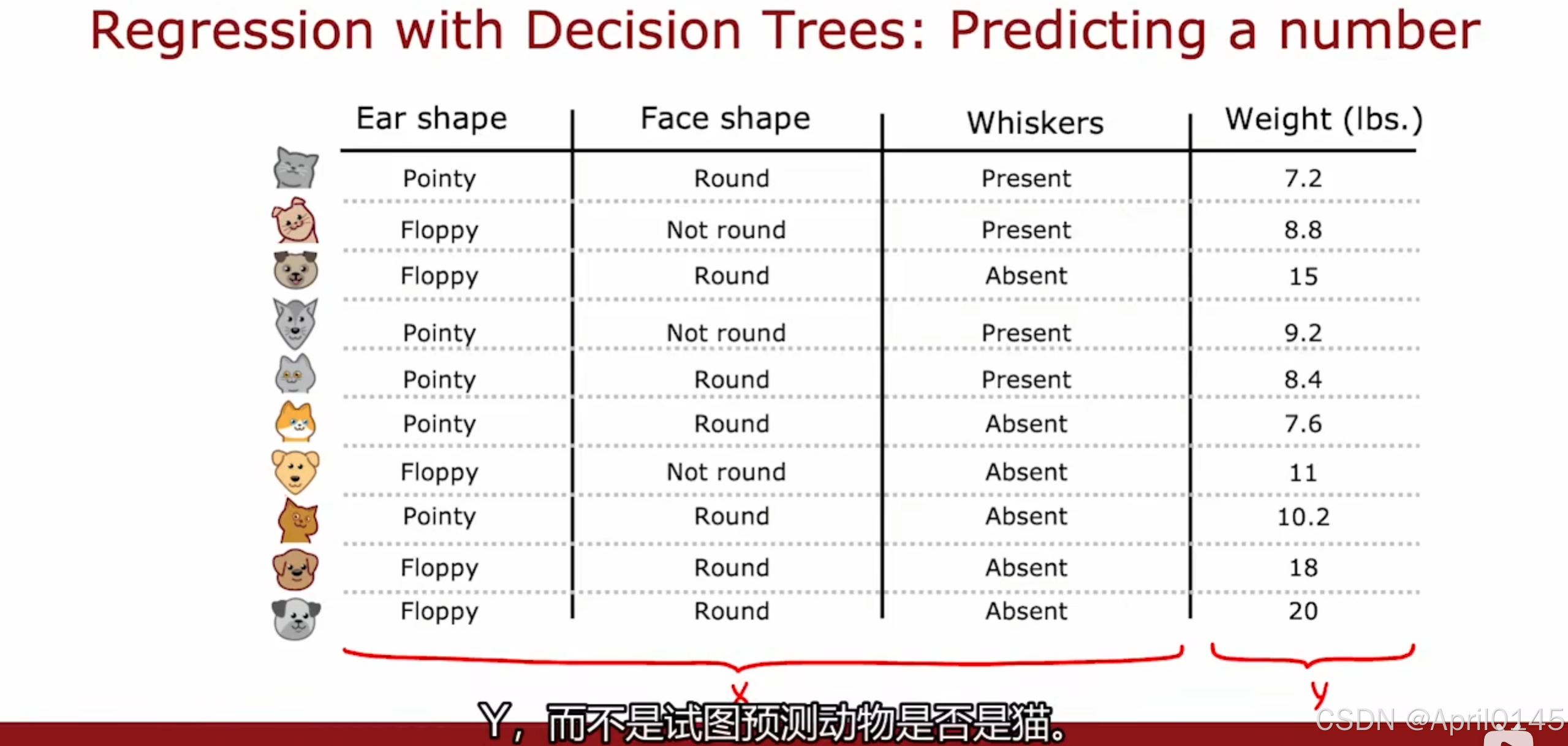
回归决策树:预测一个数字
根据特征x来预测体重y而不是试图预测动物是否是猫
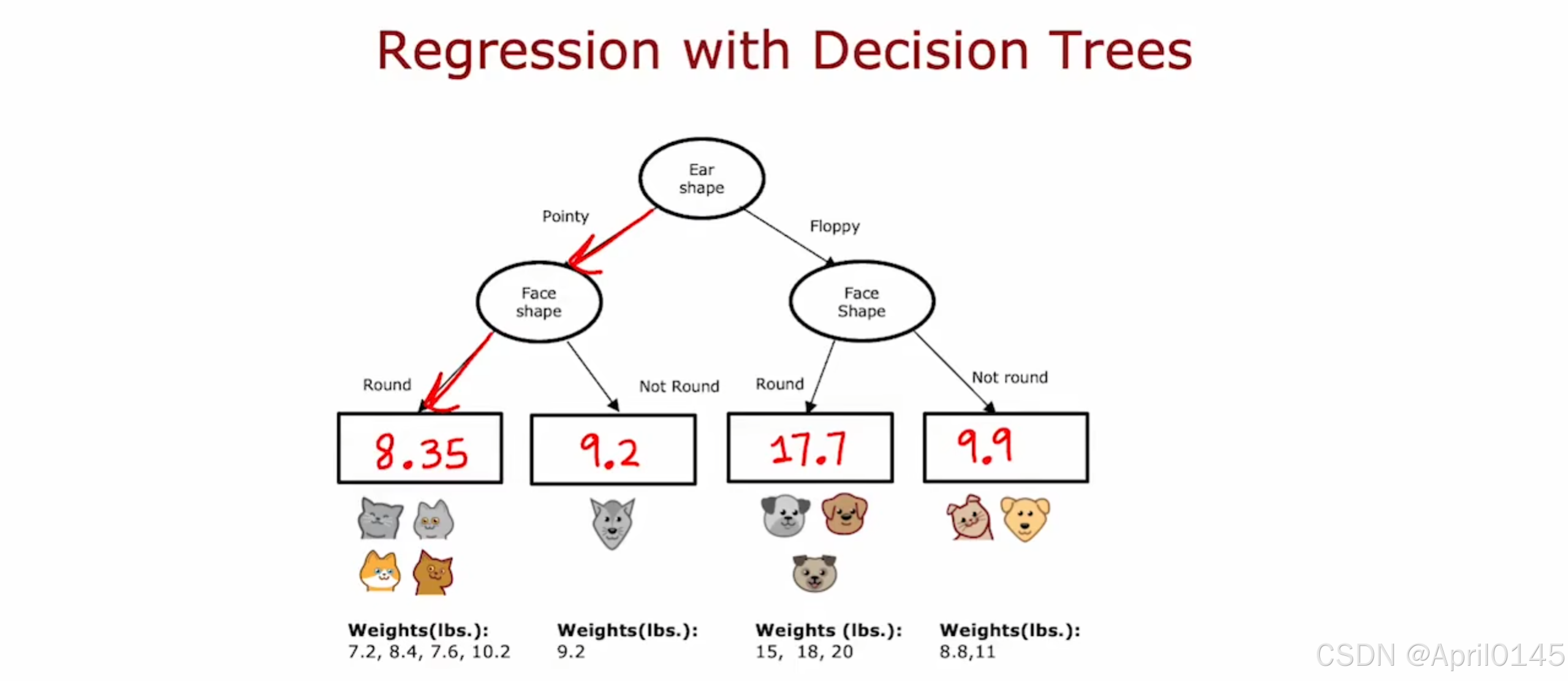
计算平均值

选择拆分
variance:方差
选择最大程度上能够减少方差的特征
3.1,使用多个决策树
决策树对数据的微小变化非常敏感
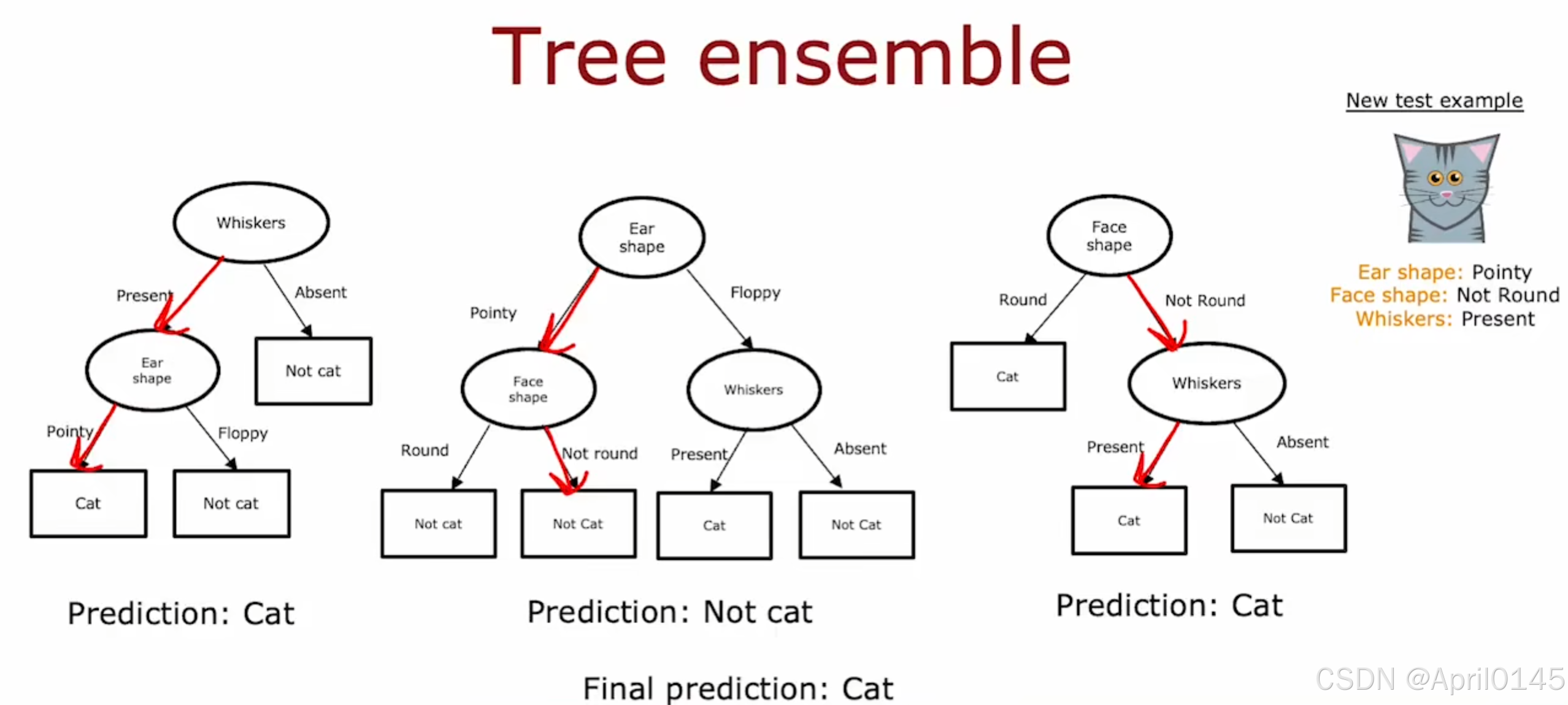
决策树组合
3.2,有放回抽样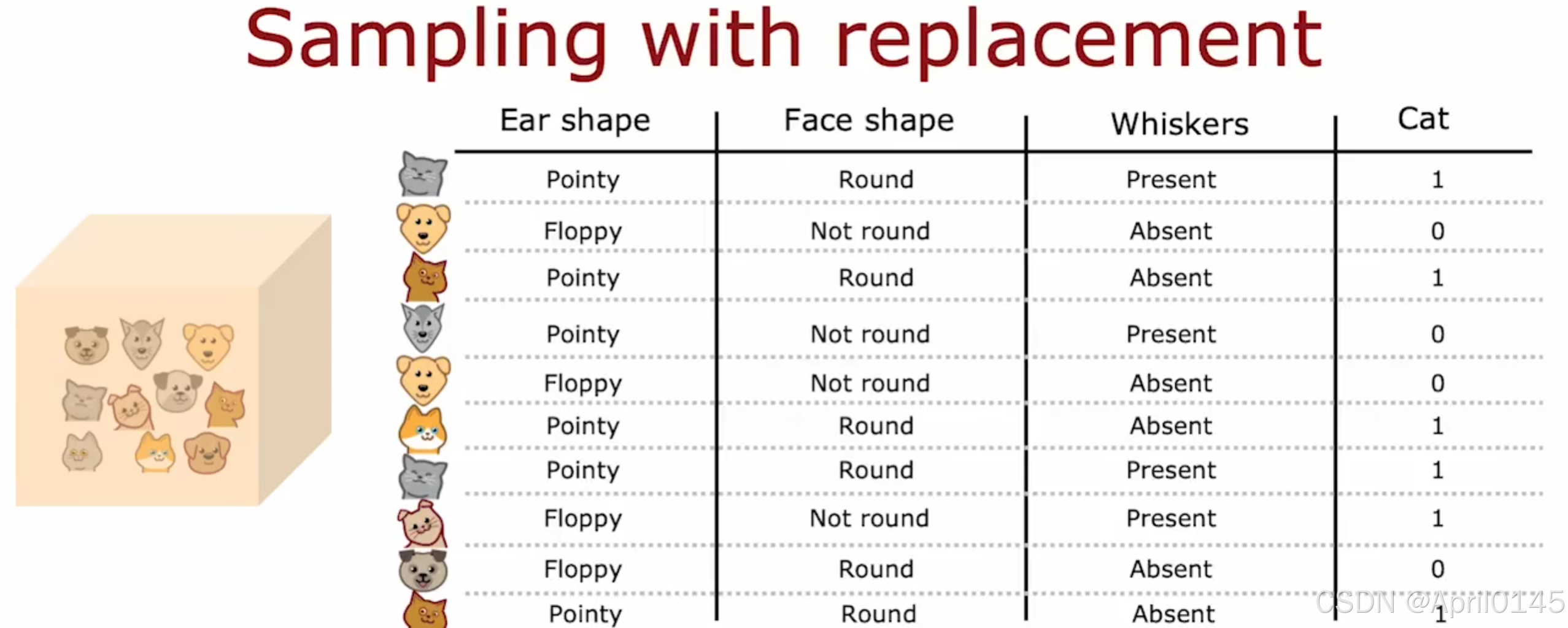
sampling with replacement:有放回抽样
对原始数据集进行有放回抽样建立新的数据集
3.3,随机森林
generating a tree sample:生成树样本
给定m尺寸的训练集
对于b=1到B:
使用采样和替换来创建一个m大小的新训练集
在新数据集上训练决策树

随机特征选取
在每个节点上,在选择用于拆分的特征时,如果有n个特征可用,请选择k<n个特征的随机子集,
并允许算法仅从该特征的子集中进行
随机森林算法
3.4,XGBoost
boost树 算法
给定m尺寸的训练集
对于b=1到B:
使用采样和替换来创建一个m大小的新训练集
但与其从所有概率相等(1/m)的例子中挑选,不如选择以前训练过的树木分类错误的例子
在新数据集上训练决策树
对错误的数据进行刻意练习

boost树的开源实现
快速高效的实施
良好的默认拆分和停止分裂的标准选择
内置正则化,以防止过度拟合
常用语机器学习竞赛中(比如:kaggle竞赛)

3.5,何时使用决策树
决策树和神经网络算法都是非常强大的算法
决策树和树组合:
1,在表格(结构化)数据上表现更好
2,不建议在非结构化数据(图像,音频,文本)上使用决策树
3,运行更快
4,小的决策树是人类可以解释的
神经网络:
1,适用于所有类型的数据,包括表格(结构化)和非结构化数据
2,运行必决策树更慢
3,可以在工作中使用迁移学习
4,在构建一个由多个模型共同运行的系统时,将多个神经网络串起来
可能更容易


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









