






在这篇文章中,我们将了解如何使用 Llama Index 微调 Llama3。更棒的是,你只需几个简单的步骤和几行代码就可以实现这一点。
在低成本云 GPU 上构建和扩展 AI 模型。
目录
-
- 什么是模型微调?
-
- 为什么使用 LLama-Factory?
-
- LLAMABOARD:LLAMAFACTORY 的统一界面
-
- 在 Paperspace 上微调 Llama 3
-
- 结论
-
- 参考文献
本文将探索于 2024 年 3 月 21 日发布的 Llama Factory,并了解如何微调 Llama 3。为了我们的任务,我们将使用 NVIDIA A4000 GPU,这被认为是最强大的单槽 GPU 之一,能够无缝集成到各种工作站设置中。
利用 NVIDIA Ampere 架构,RTX A4000 集成了 48 个第二代 RT 核心,192 个第三代 Tensor 核心和 6144 个 CUDA 核心及配备有 ECC 的 16GB 图形内存;确保创新项目的计算精度和可靠性。
直到最近,微调大语言模型还是一个复杂的任务,主要由机器学习和 AI 专家处理。然而,随着人工智能领域的不断发展,这一观念正在迅速改变。新工具如 Llama Factory 正在出现,使得微调过程更加便捷和高效。此外,现在还可以使用 DPO、ORPO、PPO 和 SFT 等技术进行微调和模型优化。此外,你现在可以高效地训练和微调 Llama、Mistral、Falcon 等模型。
什么是模型微调?
微调模型涉及调整预训练或基础模型的参数,使其能够用于特定任务或数据集,从而提升其性能和准确性。这个过程包括为模型提供新的数据,并修改其权重、偏差和某些参数以最小化损失和成本。通过这样做,这个新模型可以在任何新任务或数据集上表现良好,而无需从头开始,从而节省时间和资源。
通常,当一个新的大型语言模型(LLM)创建时,它会在一个大型文本数据语料库上进行训练,其中可能包含潜在有害或不良内容。在预训练或初始训练阶段之后,模型会被微调加入安全措施,确保其避免生成有害或不良的响应。然而,这种方法并非完美无缺。尽管如此,微调的概念解决了适应特定需求的要求。
为什么使用 LLama-Factory?
引入 Llama Factory,这是一款能够高效且经济地微调 100 多个模型的工具。Llama Factory 简化了模型微调的过程,使其变得易于访问和用户友好。它还提供了 Hiyouga 的 Hugging Face Space,可以用来微调模型。
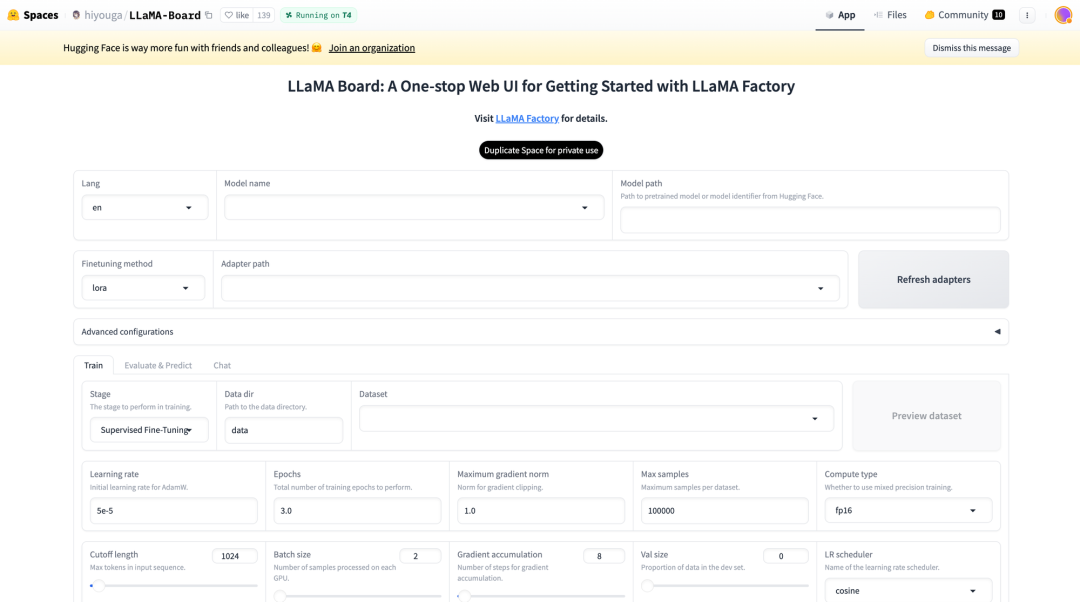
LLama Board(Huggingface Space)
这个空间还支持 Lora 和 GaLore 配置以减少 GPU 使用。通过一个简单的滑动条,用户可以轻松更改诸如 drop-out、epoch、批量大小等参数。有多种数据集选项可供选择来微调你的模型。如本文所述,Llama Factory 支持众多模型,包括不同版本的 Llama、Mistral 和 Falcon。它还支持先进的算法如 galore、badm 和 Lora,提供了各种功能如闪存注意力、位置编码和缩放。
此外,你可以集成监控工具如 TensorBoard、VanDB 和 MLflow。为了更快的推理,你可以利用 Gradio 和 CLI。总之,Llama Factory 提供了一套多样化的选项来提升模型性能并简化微调过程。
LLAMABOARD:LLAMAFACTORY 的统一界面
LLAMABOARD 是一个用户友好的工具,帮助人们无需编程知识就能调整和改进语言模型(LLM)的性能。它像一个仪表板一样,可以轻松自定义语言模型的学习和信息处理方式。
以下是一些关键特性:
-
- 简单定制:你可以在网页上调整设置来改变模型的学习方式。默认设置适用于大多数情况。而且,你还可以在开始之前查看数据在模型中的表现。
-
- 进度监控:在模型学习过程中,你可以看到更新和图表,这些图表显示了模型的表现。这将帮助你了解模型是否在改进。
-
- 灵活测试:你可以通过与已知答案对比或直接与模型交互来检查模型对文本的理解能力。这可以帮助你看清模型在语言理解方面的提升。
-
- 多语言支持:LLAMABOARD 支持英文、俄文和中文,这使得它对不同语言的用户都很有用。未来还可以增加更多语言的支持。
使用 Paperspace 微调 LLama 3
让我们登录平台,选择你喜欢的 GPU,并启动笔记本。你也可以点击文章中的链接来帮助你启动笔记本。
-
- 我们将先克隆代码库并安装所需库,
!git clone https://github.com/hiyouga/LLaMA-Factory.git %cd LLaMA-Factory %ls
-
- 接下来,我们将安装 unsloth,它可以帮助我们有效地微调模型。另外,我们还将安装 xformers 和 bitsandbytes。
# 安装所需软件包 !pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" !pip install --no-deps xformers==0.0.25 !pip install .[bitsandbytes] !pip install 'urllib3<2'
-
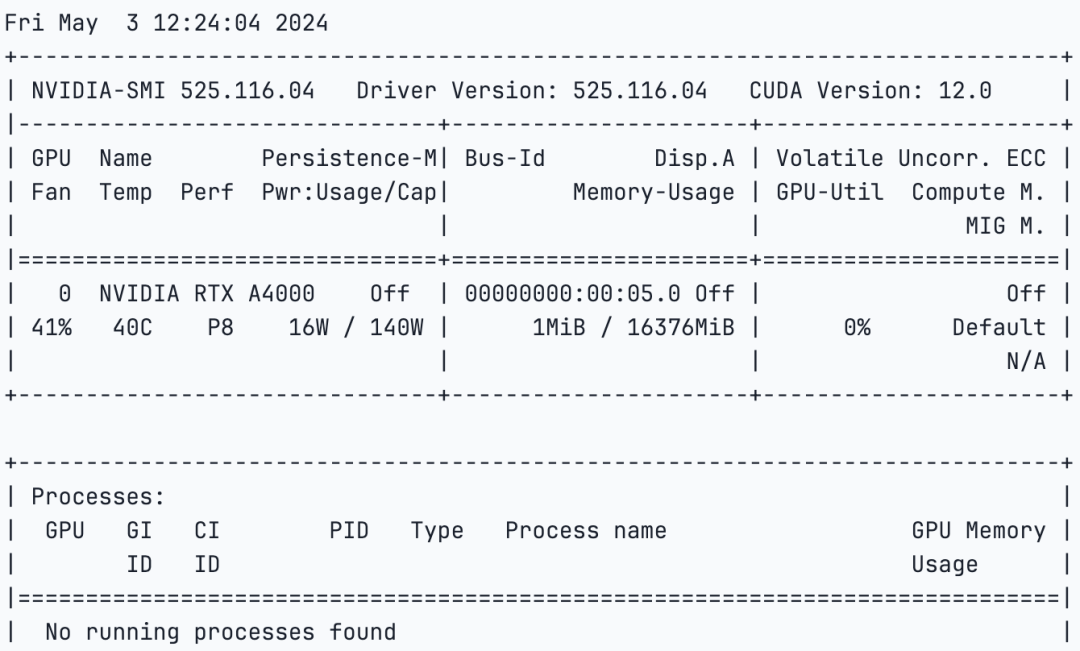
- 安装完成后,我们将检查 GPU 规格,
!nvidia-smi
-
- 接下来,我们将导入 torch 并检查 CUDA,因为我们使用的是 GPU,
import torch try: assert torch.cuda.is_available() is True except AssertionError: print("Your GPU is not setup!")
-
- 现在我们将导入克隆到 GitHub 代码库中的数据集。我们也可以创建自定义数据集并使用它。
import json %cd /notebooks/LLaMA-Factory MODEL_NAME = "Llama-3" with open("/notebooks/LLaMA-Factory/data/identity.json", "r", encoding="utf-8") as f: dataset = json.load(f) for sample in dataset: sample["output"] = sample["output"].replace("MODEL_NAME", MODEL_NAME).replace("AUTHOR", "LLaMA Factory") with open("/notebooks/LLaMA-Factory/data/identity.json", "w", encoding="utf-8") as f: json.dump(dataset, f, indent=2, ensure_ascii=False)
-
- 完成上述步骤后,执行以下代码生成 Llama Factory 的 Gradio web 应用链接。
# 生成 web 应用链接 %cd /notebooks/LLaMA-Factory !GRADIO_SHARE=1 llamafactory-cli webui
你可以点击生成的链接并按照提示操作,或者使用你自己的参数规格。
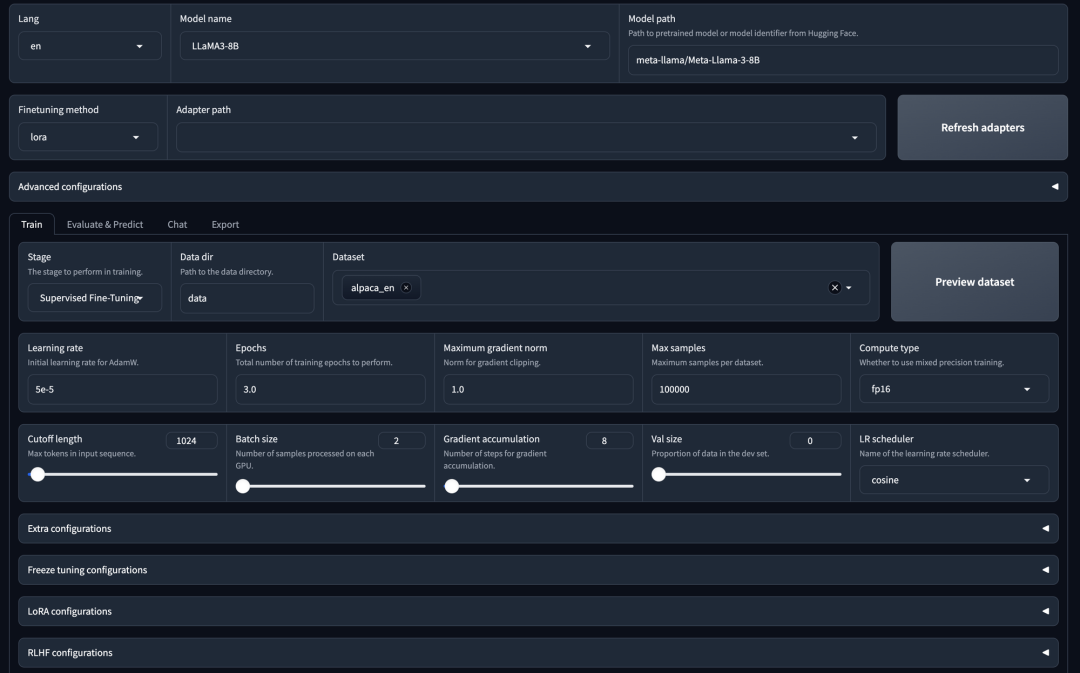
-
- 模型选择:
- • 你可以选择任何模型;此处我们选择 8 亿参数的 Llama 3。
-
- 适配器配置:
-
• 你可以指定适配器路径。
-
• 可用的适配器包括 LoRa、QLoRa、freeze 或 full。
-
• 如果需要,你可以刷新适配器列表。
-
- 训练选项:
-
• 你可以通过监督微调进行模型训练。
-
• 或者,你可以选择使用 DPU(数据处理单元)或 PPU(并行处理单元)(如果适用)。
-
- 数据集选择:
-
• 已选择的数据集用于监督微调(SFT)。
-
• 你也可以选择自己的数据集。
-
- 超参数配置:
- • 你可以调整超参数,比如训练轮数、最大梯度范数和最大样本大小。
-
- Laura 配置:
- • 可用的详细配置选项可用于 LoRa 模型。
-
- 开始训练:
- • 设置完所有配置后,你可以点击“开始”按钮启动训练过程。
这将开始训练。
我们也将使用 CLI 命令开始训练和微调。你可以使用下面的代码来指定参数。
args = dict( stage="sft", # 指定训练阶段。这里设置为“sft”以进行监督微调 do_train=True, model_name_or_path="unsloth/llama-3-8b-Instruct-bnb-4bit", # 使用 bnb-4bit-quantized Llama-3-8B-Instruct 模型 dataset="identity,alpaca_gpt4_en", # 使用 alpaca 和 identity 数据集 template="llama3", # 使用 llama3 模板 finetuning_type="lora", # 使用 LoRA 适配器,以节省内存 lora_target="all", # 将 LoRA 适配器附加到所有线性层 output_dir="llama3_lora", # 保存 LoRA 适配器的路径 per_device_train_batch_size=2, # 指定批量大小 gradient_accumulation_steps=4, # 梯度累积步数 lr_scheduler_type="cosine", # 使用余弦学习率调度器 logging_steps=10, # 每 10 步记录一次 warmup_ratio=0.1, # 使用预热调度器 save_steps=1000, # 每 1000 步保存一次检查点 learning_rate=5e-5, # 学习率 num_train_epochs=3.0, # 训练轮数 max_samples=500, # 每个数据集使用 500 个示例 max_grad_norm=1.0, # 最大梯度范数剪裁值 quantization_bit=4, # 使用 4 位 QLoRA 量化 loraplus_lr_ratio=16.0, # 使用 lambda=16.0 的 LoRA+ use_unsloth=True, # 使用 UnslothAI 的 LoRA 优化以加速 2 倍训练速度 fp16=True, # 使用 float16 混合精度训练 ) json.dump(args, open("train_llama3.json", "w", encoding="utf-8"), indent=2)
接下来,打开终端并运行以下命令
!llamafactory-cli train train_llama3.json
这将启动训练过程。
-
- 模型训练完成后,我们可以使用该模型进行推理。让我们尝试这样做,并检查模型的工作情况。
args = dict( model_name_or_path="unsloth/llama-3-8b-Instruct-bnb-4bit", # 指定用于推理的预训练模型的名称或路径。在本例中,设置为 "unsloth/llama-3-8b-Instruct-bnb-4bit"。 #adapter_name_or_path="llama3_lora", # 加载保存的 LoRA 适配器 finetuning_type="lora", # 指定微调类型。这里设置为 "lora" 以使用 LoRA 适配器。 template="llama3", # 指定用于推理的对话模板。这次设置为 "llama3"。 quantization_bit=4, # 指定量化位数。这次设置为 4。 use_unsloth=True, # 使用 UnslothAI 的 LoRA 优化,实现 2 倍生成速度 ) json.dump(args, open("infer_llama3.json", "w", encoding="utf-8"), indent=2)
在这里,我们定义了带有已保存适配器的模型,选择了聊天模板,并指定了用户-助手的交互过程。 接下来,在终端中运行以下代码,
!llamafactory-cli chat infer_llama3.json
我们建议用户尝试 Llama-Factory,进行各种模型实验和参数调整。
结论
有效的微调已经成为大语言模型(LLMs)适应特定任务的必要条件之一。然而,这需要一定的努力,有时还相当具有挑战性。LLama-Factory 的引入提供了一个综合框架,该框架整合了先进的高效训练技术,用户无需编码即可轻松自定义超过 100 种 LLMs 的微调。 许多人现在对大语言模型(LLMs)变得更好奇,他们会倾向于使用 LLama-Factory 来调整自己的模型。这有助于开源社区的成长和活跃。LLama-Factory 正逐渐出名,甚至在 Awesome Transformers3 中被强调为高效微调 LLMs 的领先工具。 我们希望这篇文章能鼓励更多开发者使用此框架构建对社会有益的 LLMs。请记住,在使用 LLama-Factory 微调 LLMs 时,遵守模型许可证的规定非常重要,以防止潜在的滥用。 到这里,我们结束了这篇文章,我们看到了现在微调任何模型是多么容易,可以在几分钟内完成。我们还可以使用 hugging face CLI 将此模型推送到 hugging face hub。 为您的机器学习工作流程增添速度和简便性,今天就开始吧
参考资料
-
• LLAMAFACTORY: Unified Efficient Fine-Tuning of 100+ Language Models
-
• Github LLaMA-Factory
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 4247
4247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









