







本人亲自与队友完成的论文,最后获一等奖 + 创新奖;

文中依旧还有许多不足之处,分享给大家,有什么好的建议意见也可以留言提出哦;
如果需要代码或PDF本体可以关注私信!
比赛不是很难,新手可以参加,我们当时考虑到没有什么事情,随便报名的也没有想太多,新手极力推荐很好拿奖,我们的论文也不是很好,居然也能评创新奖!!!






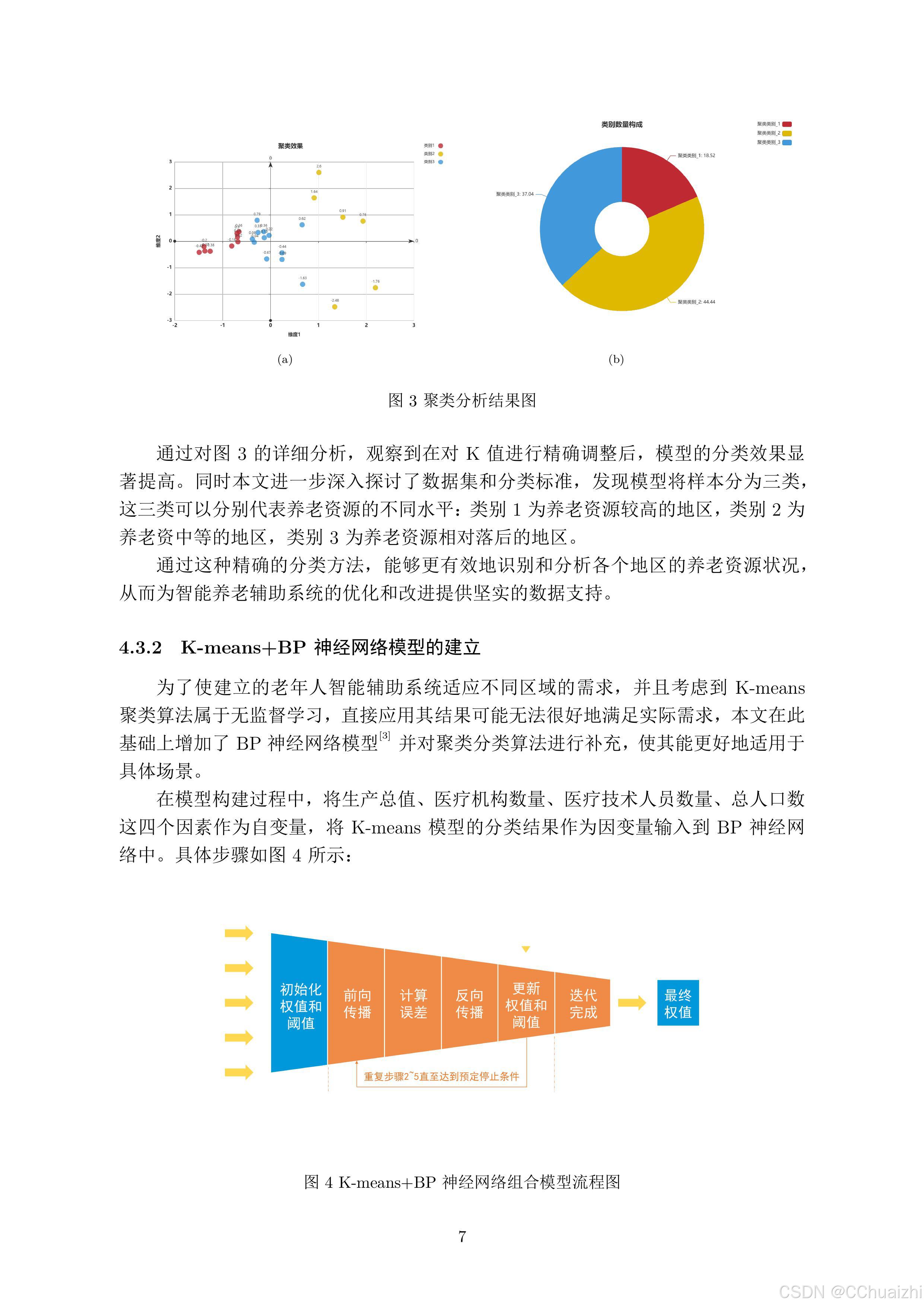
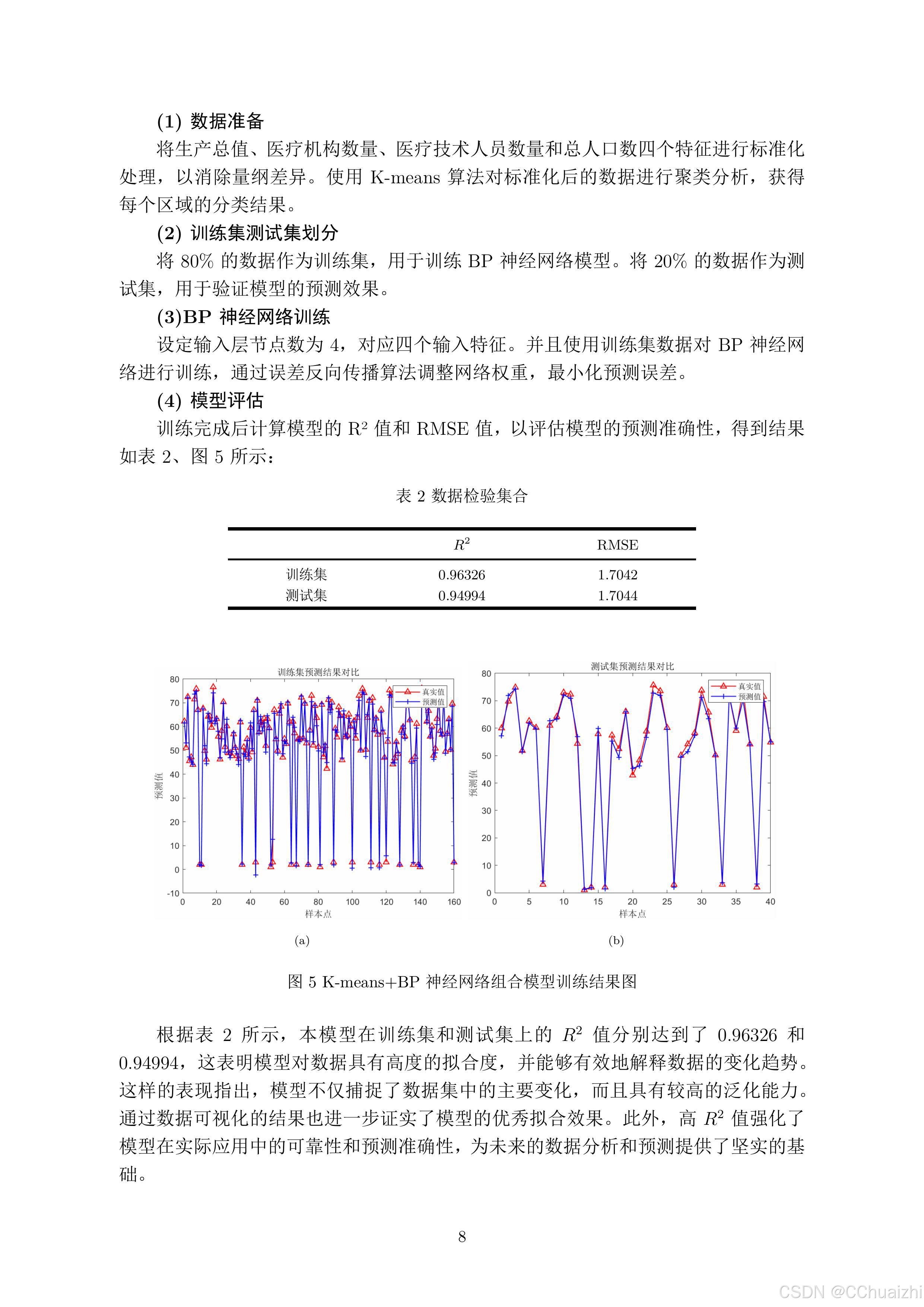


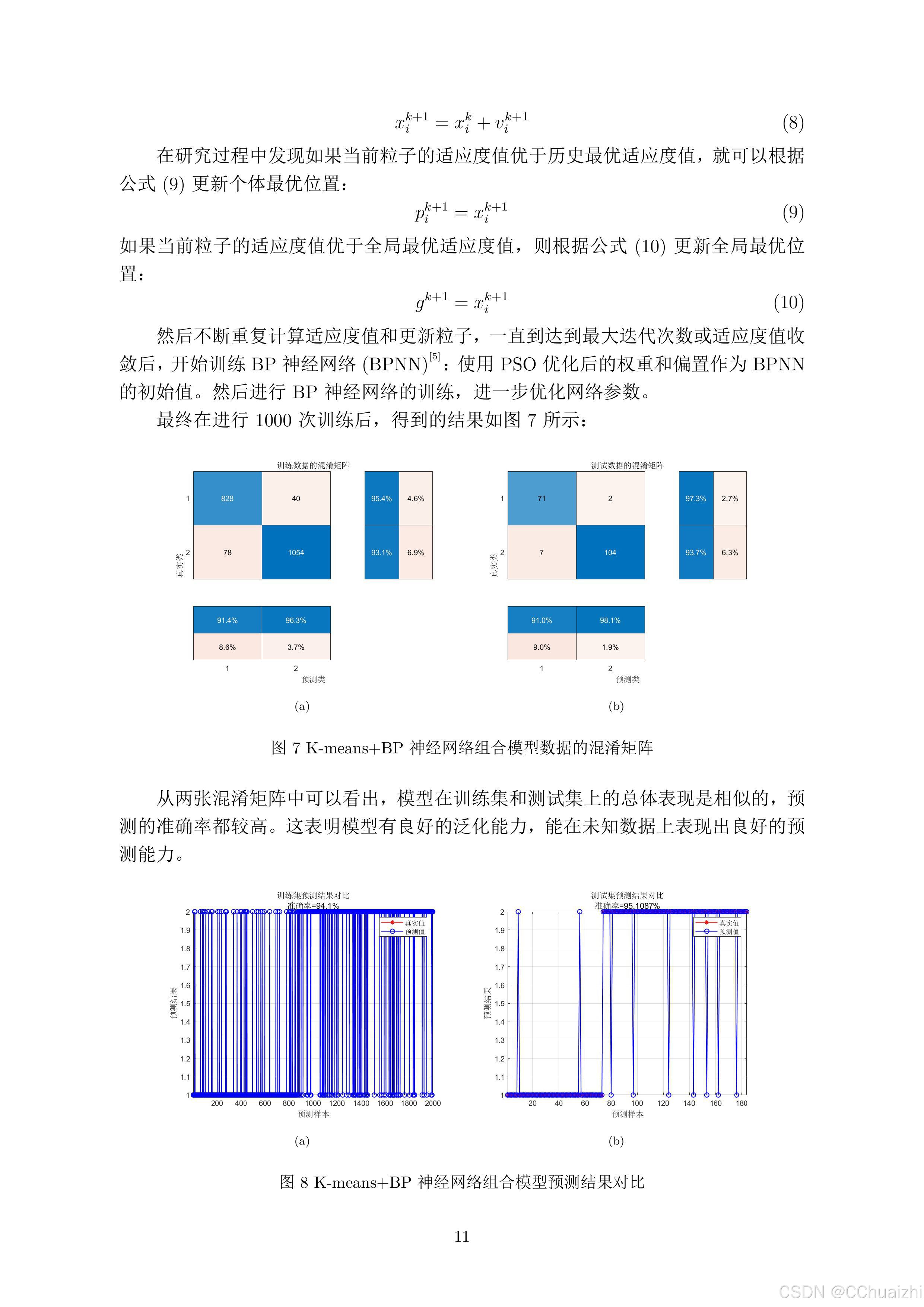

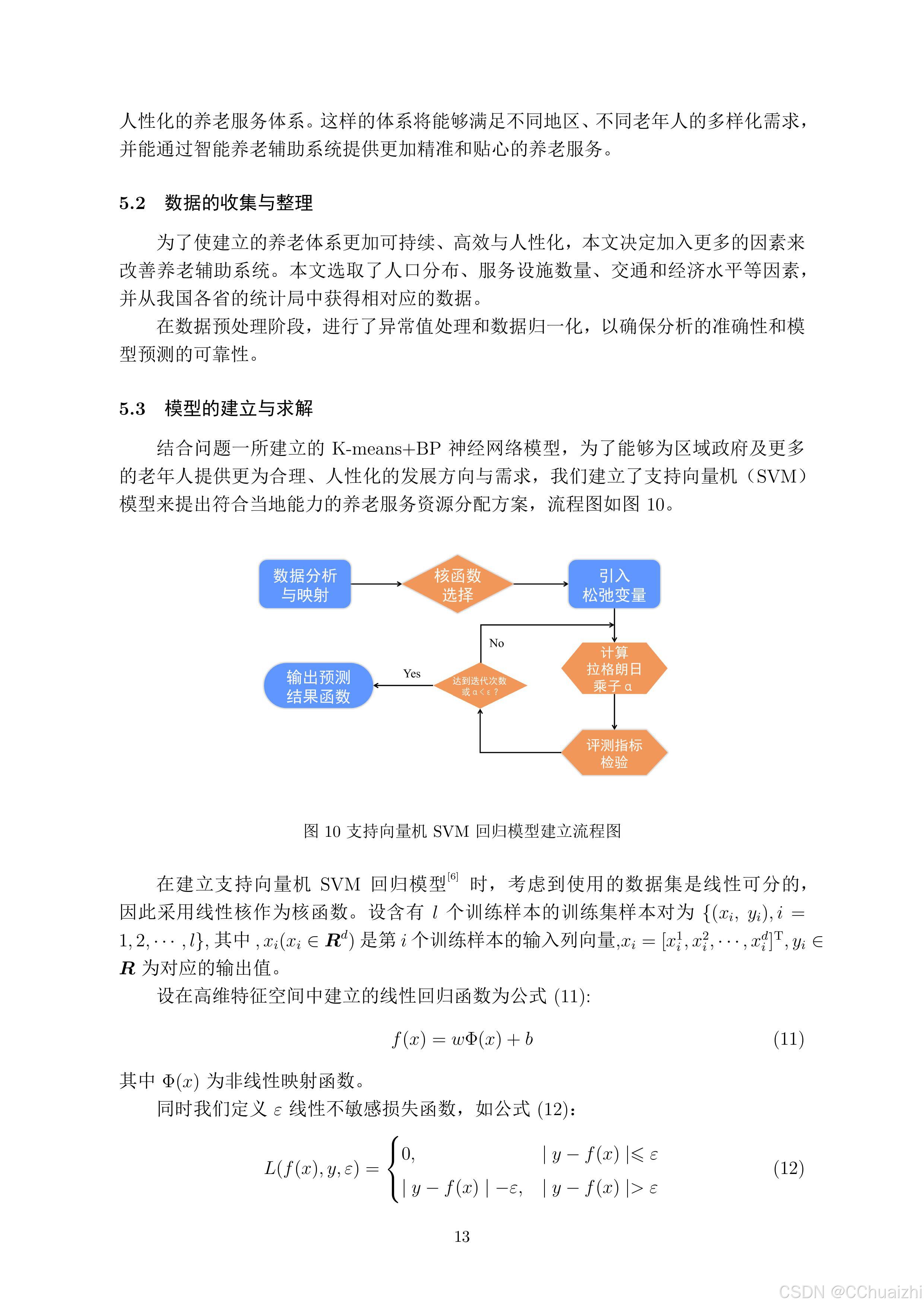






考虑到文章篇幅,后续代码就不在这里展示了,文章仅供参考!
本人亲自与队友完成的论文,最后获一等奖 + 创新奖;
文中依旧还有许多不足之处,分享给大家,有什么好的建议意见也可以留言提出哦;
如果需要代码或PDF本体可以关注私信!
比赛不是很难,新手可以参加,我们当时考虑到没有什么事情,随便报名的也没有想太多,新手极力推荐很好拿奖,我们的论文也不是很好,居然也能评创新奖!!!
考虑到文章篇幅,后续代码就不在这里展示了,文章仅供参考!
 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























