







引言
在大语言模型中,我们期望模型能够理解人类语言的一般规律,从而做出和人类相似的表达方式,通过使用大量的数据进行训练从而获得使模型学习到数据背后的一般规律。在训练预训练模型时,通常有两个可以提高大语言模型性能的选项:增加数据集大小和增加模型中的参数量。在此基础上,训练过程中还存在一个限制条件,即训练成本,比如GPU的数量和可用于训练的时间等。因此,大语言模型的预训练,通常伴随着模型容量、数据量、训练成本的三方权衡博弈。
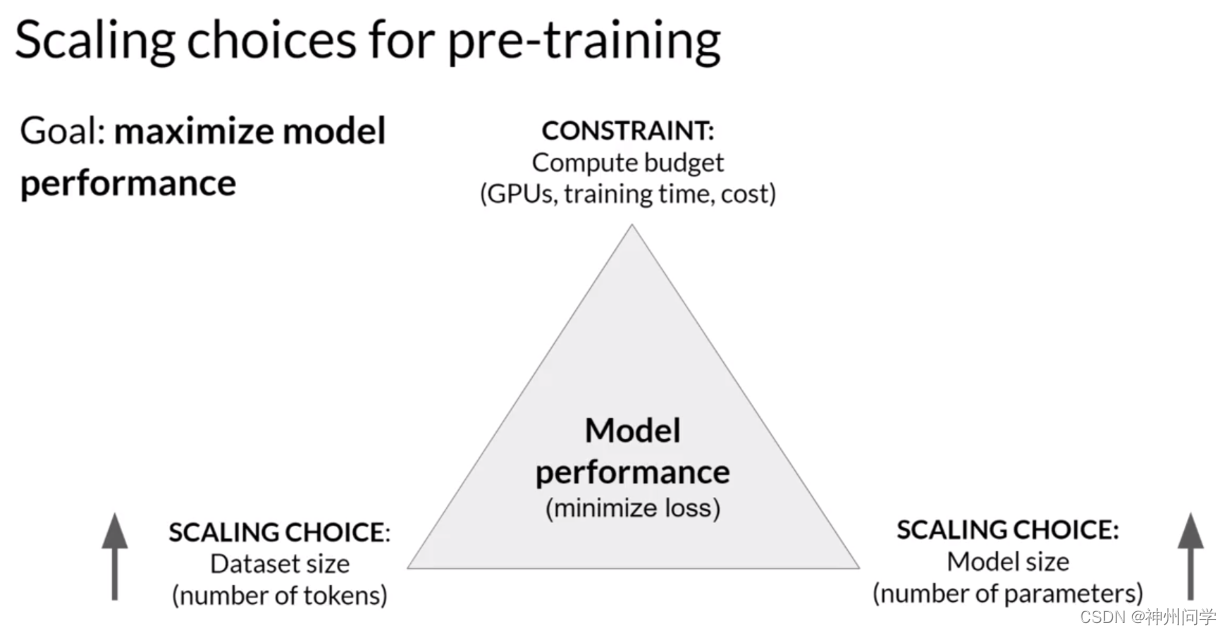
Figure 1. 模型规模扩展的选项概览
什么是Scaling Laws
对于这种三角形式的拔河关系,往往存在一些三元悖论,比如分布式计算领域中的公认定理:CAP理论。分布式系统不可能同时满足一致性、可用性和分区容错性,最多只能同时满足其中2个条件。大语言模型训练中同样存在类似这种三元关系的探索,这就是缩放定律(Scaling Laws)。
在大语言模型预训练过程中,交叉熵损失(cross-entropy loss)是一种常用的性能衡量标准,用于评估模型预测输出与真实情况之间的差异。较低的交叉熵损失意味着模型的预测更准确。训练的过程也是追求损失值的最小化的过程。
Scaling Laws的意义在于,AI专业人士可以通过Scaling Laws预测大模型在参数量、数据量以及训练计算量这三个因素变动时,损失值的变化。这种预测能帮助一些关键的设计决策,比如在固定资源预算下,匹配模型的最佳大小和数据大小,而无需进行及其昂贵的试错。
OpenAI V.S DeepMind
DeepMind
We’re a team of scientists, engineers, ethicists and more, committed to solving intelligence, to advance science and benefit humanity.
—— DeepMind
DeepMind,成立于2010年并于2015年被谷歌收购,是Alphabet Inc.的子公司。该公司专注于开发能模仿人类学习和解决复杂问题能力的AI系统。作为Alphabet Inc.的一部分,DeepMind在保持高度独立的同时,也在利用谷歌的强大能力推动AI研究的发展。
DeepMind在技术上取得了显著成就,包括开发AlphaGo,击败世界围棋冠军李世石的AI系统,展示了深度强化学习和神经网络的潜力,开启了一个AI时代。另一项重要成就是AlphaFold,这是一个革命性的用于准确预测蛋白质折叠的工具,对生物信息学界产生了深远影响。DeepMind用AI进行蛋白质折叠预测的突破,将帮助我们更好地理解生命最根本的根基,并帮助研究人员应对新的和更难的难题,包括应对疾病和环境可持续发展。
OpenAI
“Our mission is to ensure that artificial general intelligence—AI systems that are generally smarter than humans—benefits all of humanity.”
——2023年2月14日《Planning for AGI and beyond》
在谷歌收购DeepMind后,为避免谷歌在AI领域形成垄断,埃隆·马斯克和其他科技行业人物于2015年决定创建OpenAI。它作为一个有声望的非营利组织,致力于开发能够推动社会进步的AI技术。不同于DeepMind 像一个精于解决棋盘上复杂战术的大师,专注于解决那些有明确规则和目标的难题,OpenAI更像是一个擅长语言艺术的诗人,致力于让机器理解和生成自然的人类语言。
从坚持初期被外界难以理解的GPT路线<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3774
3774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









