






25年Mamba+Transformer必将迎来大爆发!
这不,英文达前脚刚中稿CVPR25,提出的MambaVision模型,打破了精度/吞吐瓶颈;后脚又推出了基于该架构的大模型Nemotron-H,速度狂提300%;就在前几天,腾讯也推出了混元T1大模型;各大顶会也不乏其身影……
其热度可见一斑!主要在于:一方面,Mamba具有线性复杂度,Transformer能捕捉长期依赖关系,两者优势互补,显著提升模型在精度、吞吐量和长序列处理上的性能。而速度提升、成本降低,是AI大模型广泛应用的必经之路。这便给我们的论文创新提供了机会和空间。另一方面,这两者结合目前还处于早期发展阶段,还不算卷;同时也有不少优秀开源成果,改模型好操作!
为让大家能够紧跟领域前沿,早点发出自己的顶会,我给大家准备了12种创新思路和源码!
论文原文+开源代码需要的同学看文末
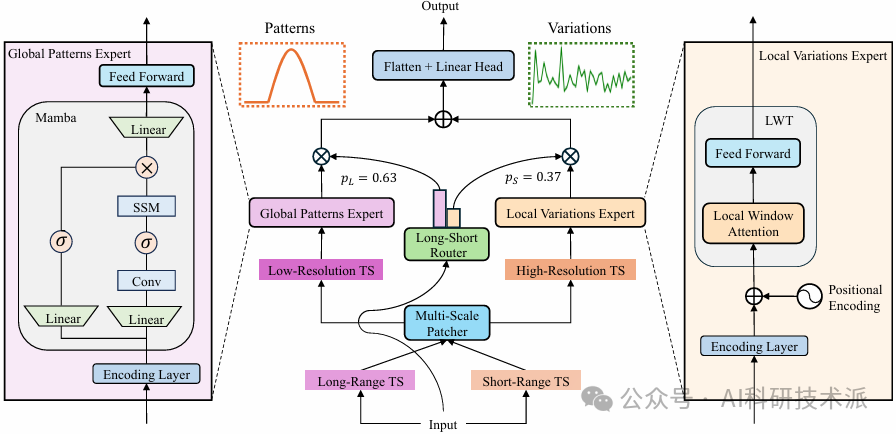
SST: Multi-Scale Hybrid Mamba-Transformer Experts for Long-Short RangeTime Series Forecasting
内容:本文提出了一种名SST的多尺度混合Mamba-Transformer专家模型,用于长短期时间序列预测。该模型通过将时间序列分解为长期的全局模式和短期的局部变化,并分别利用Mamba专家提取长期全局模式以及Local Window Transformer(LWT)专家捕捉短期局部变化,再通过长短期路由器动态整合两者的贡献,实现了在保持线性复杂度O(L)的同时,显著优于现有方法的预测性能,并在多个真实世界数据集上验证了其低内存占用和高效计算能力。
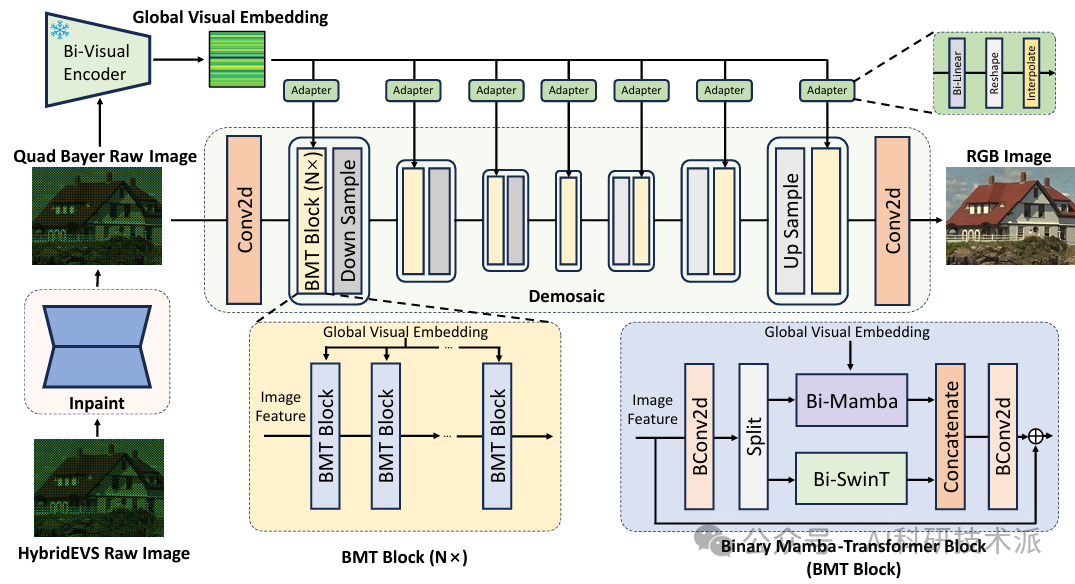
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
内容:本文提出了一种名为BMTNet的轻量化二值神经网络,专门用于Quad Bayer HybridEVS(混合事件视觉传感器)RAW图像的去马赛克任务。该网络结合了Mamba和Swin Transformer架构的优势,通过二值化投影层大幅降低了计算复杂度,同时引入全局视觉信息以增强全局上下文感知能力。实验表明,BMTNet在多个数据集上实现了与全精度方法相当的性能,同时显著减少了参数数量和计算量,适合在资源受限的移动设备上部署。
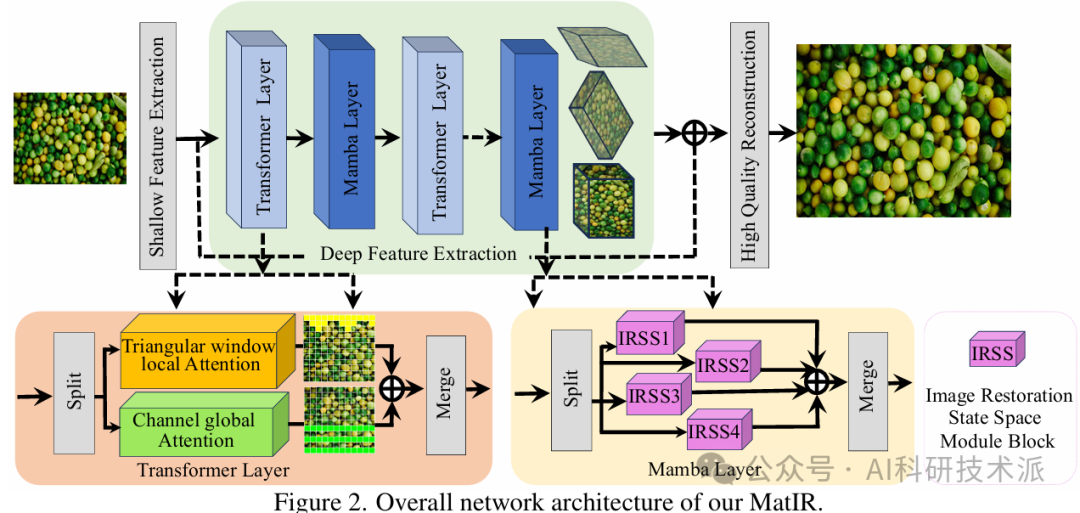
MatIR: A Hybrid Mamba-Transformer Image Restoration Model
内容:本文提出了一种名为 MatIR 的混合 Mamba-Transformer 图像恢复模型,旨在结合 Mamba 的高效处理长序列数据能力和 Transformer 的强大上下文学习能力,以解决图像恢复任务(如超分辨率、去噪和去模糊)中的挑战。MatIR 通过交叉循环 Transformer 层和 Mamba 层的块来提取特征,并引入了图像修复状态空间(IRSS)模块、三角窗局部注意力(TWLA)块和通道全局注意力(CGA)块,以实现高效的长序列数据处理和高质量的图像恢复。实验结果表明,MatIR 在多个基准数据集上优于其他最新方法,同时在计算效率和内存管理方面表现出色。
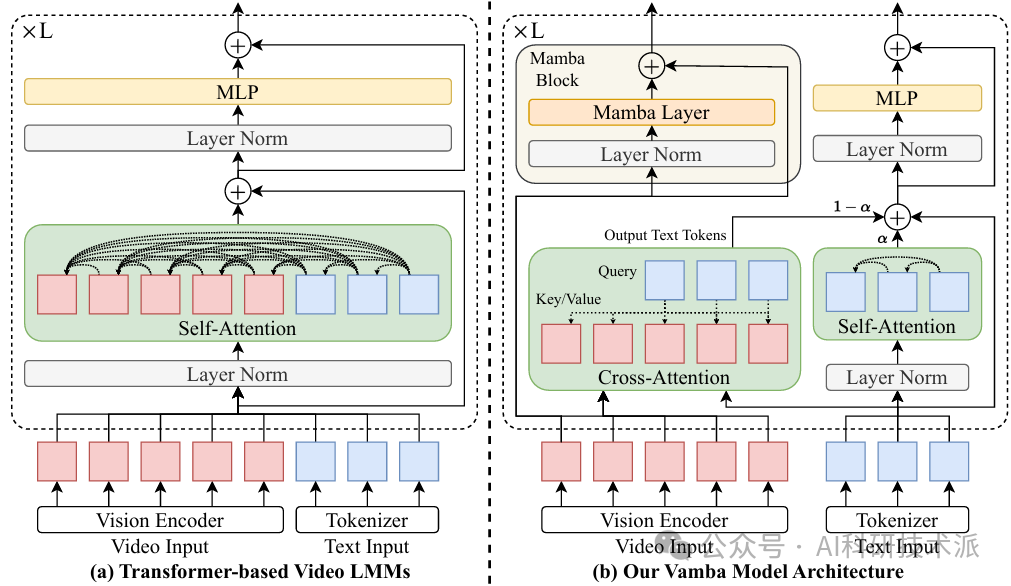
VAMBA: Understanding Hour-Long Videos with Hybrid Mamba-Transformers
内容:本文提出了一种名为 VAMBA的混合 Mamba-Transformer 模型,用于高效处理长达数小时的视频输入。该模型通过结合 Mamba 的线性复杂度和 Transformer 的强大上下文学习能力,显著降低了计算成本和内存占用,同时在长视频理解任务上取得了优异的性能。具体而言,VAMBA 使用 Mamba-2 块处理视频帧,利用交叉注意力层更新文本信息,从而在保持性能的同时,将训练和推理阶段的 GPU 内存使用量减少超过 50%,并将每步训练速度提高近一倍。实验结果表明,VAMBA 在小时级视频理解基准测试 LVBench 上比之前的高效视频多模态模型准确率提高了 4.3%,并且在长、中、短视频理解任务上均表现出色。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【曼巴变形】获取完整论文
👇

















 2011
2011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









