






Mamba再下一城,中稿CVPR25!通过与注意力机制结合,在性能刷爆语义分割SOTA的同时,推理速度更是狂飙了300%%!
实际上,Mamba+注意力机制,是近来顶会的新风向!它解决了传统算法在处理长序列数据时效率低下的难题,对提高模型的特征表达能力和预测精度也有奇效!有模型就实现了预测误差直降42.1%的效果!主要在于,Mamba的线性复杂度特性,能降低计算资源消耗;而注意力机制的引入,则能增强模型的全局感知能力。
尤其特别的是,该思路还不算卷,创新切入点很丰富!如何平衡效率与精度、跨模态应用、与多种注意力变体结合等都是热门。此外,其应用也非常广泛,目标检测、自动驾驶、医疗影像等都有它的身影。
为让大家能够紧跟领域前沿,找到更多idea,我给大家准备了9种创新思路和源码
论文原文+开源代码需要的同学看文末
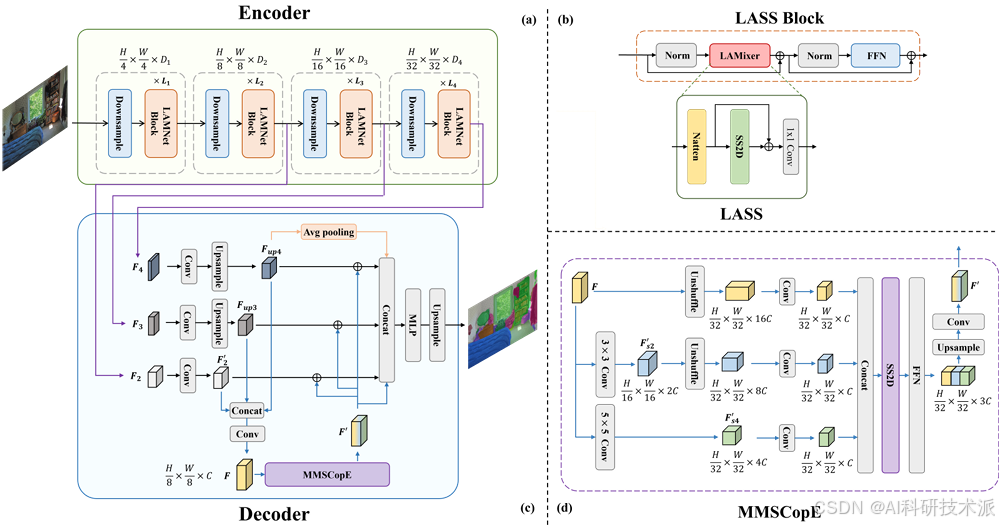
SegMAN: Omni-scale Context Modeling with State Space Models and Local Attention for Semantic Segmentation
内容:这篇文章介绍了一种名为SegMAN的新型语义分割模型,旨在同时实现高效的全局上下文建模、高质量的局部细节编码以及丰富的多尺度特征表示。SegMAN在ADE20K、Cityscapes和COCOStuff三个具有挑战性的数据集上进行了全面评估,均取得了优异的性能,同时保持了较低的计算复杂度。
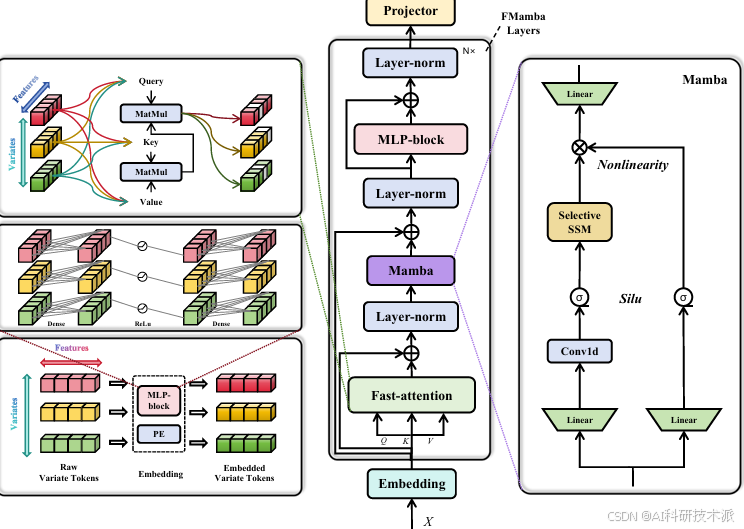
FMamba: Mambabased on Fast-attention for Multivariate Time-series Forecasting
内容:这篇文章提出了一种名为FMamba的新型多变量时间序列预测(MTSF)框架,旨在解决现有Transformer模型由于二次计算复杂度导致的效率低下问题。FMamba结合了快速注意力机制和基于状态空间模型(Mamba)的特性,通过线性计算复杂度实现了高效的全局变量相关性建模和选择性特征处理。实验结果表明,FMamba在多个公共数据集上达到了最先进的性能,同时显著降低了计算开销。
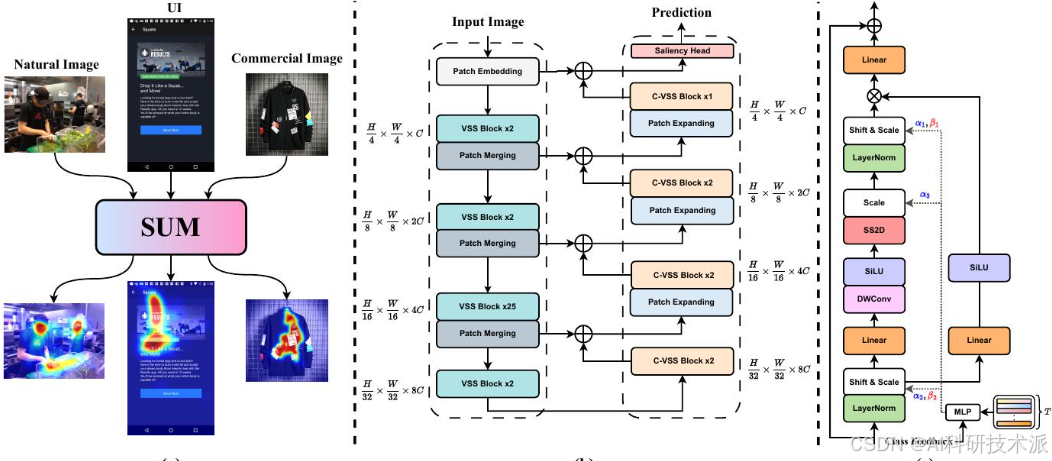
SUM:Saliency Unification through Mamba for Visual Attention Modeling
内容:这篇文章提出了一种名为SUM的新型视觉注意力建模方法,旨在通过整合高效的Mamba状态空间模型和U-Net架构来实现对多种图像类型的统一视觉显著性预测。SUM引入了一种新颖的条件视觉状态空间(C-VSS)模块,能够动态适应不同图像类型(如自然场景、网页和商业图像)的视觉特征,从而在多种基准数据集上实现卓越的性能,为视觉注意力建模领域提供了一个强大且通用的解决方案。
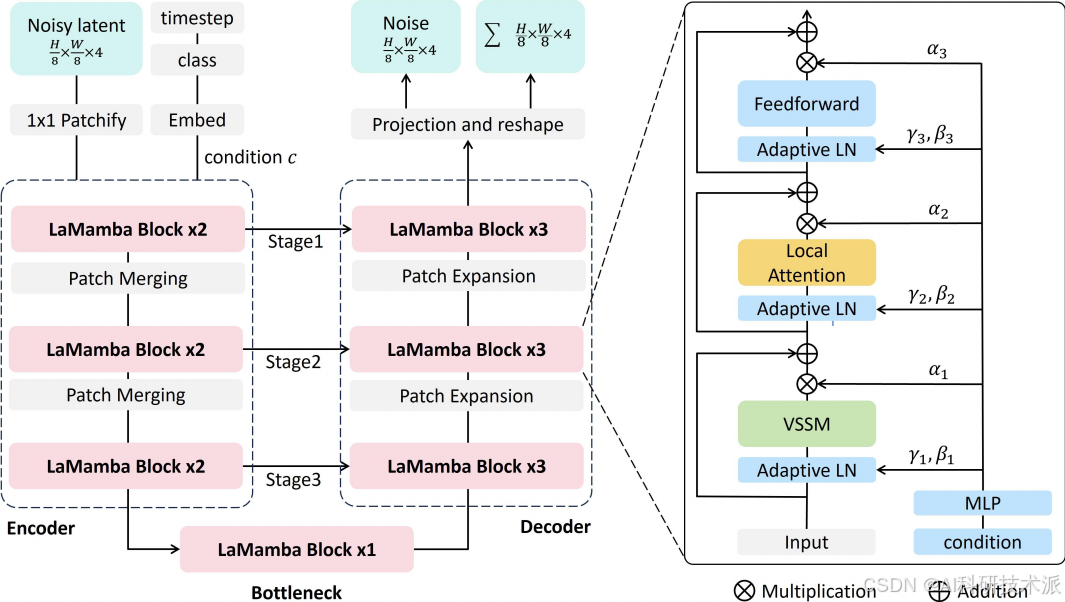
LaMamba-Diff: Linear-Time High-Fidelity Diffusion Models Based on Local Attention and Mamba
内容:这篇文章介绍了一种名为LaMamba-Diff的新型扩散模型,旨在通过结合局部注意力和Mamba状态空间模型来实现高效的高保真图像生成。LaMamba-Diff通过线性复杂度的Local Attentional Mamba(LaMamba)块,同时捕捉全局上下文和局部细节,显著降低了计算复杂度,同时在ImageNet数据集上实现了与现有最先进模型相媲美或更好的性能。该模型在256×256和512×512分辨率的图像生成任务中表现出色,使用更少的GFLOPs(浮点运算次数)达到了更低的Fréchet Inception Distance(FID)分数,展示了其在高分辨率图像生成任务中的高效性和可扩展性。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【曼巴注意】获取完整论文
👇

















 3274
3274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









