






1.实现折半查找
分析:折半查找也称折半搜索、二分搜索、对数搜索,是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。
算法步骤描述:
①首先确定整个查找区间的中间位置 mid = (left + right)/2 。
② 用待查关键字值与中间位置的关键字值进行比较;若相等,则查找成功;若大于,则在后(右)半个区域继续进行折半查找;若小于,则在前(左)半个区域继续进行折半查找。
③ 对确定的缩小区域再按折半公式,重复上述步骤。最后,得到结果:要么查找成功, 要么查找失败。折半查找的存储结构采用一维数组存放。
程序:
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int k;
int left = 0;
int right =9;
printf("输入要查找的数");
scanf("%d",&k);
while (left <= right)
{
int mid = (left + right) / 2;
if (arr[mid] > k)
{
right = mid - 1;// 如果目标值小于数组中间元素,则将右边界设为中间位置前一个位置
}
else if (arr[mid] < k)
{
left = mid + 1;// 如果目标值大于数组中间元素,则将左边界设为中间位置后一个位置
}
else
{
printf("找到了:%d\n", mid);// 如果目标值等于数组中间元素,则返回该位置索引
break;
}
}
if (left > right)
{
printf("找不到了\n"); // 若未找到目标值,则输出不存在
}
return 0;
}2.排序两个一维数组;合并到一个一维数组中,仍然保持有序。
分析:你需要将两个已排序的一维数组合并成一个有序的一维数组,可以通过交换元素的方式实现。
下面的程序首先输入两个数组的长度,然后分别输入数组a和b的元素。接下来,对数组a和b进行冒泡排序,最后将两个排序后的数组按照元素大小进行合并,存储在数组c中。
注意:本题要求在合并时先对两个已排序的一维数组中的元素进行排序,再把排好的元素放入新的一维数组中。
程序:(程序写的有些太长了,可以把一些没啥用处的步骤删除,可以通过调用函数来简化)
简化(排序函数):
#include<stdio.h>
void sort(int a[],int n)
{
int i,k,temp;
for(i=0;i<n-1;i++)
for(k=0;k<n-i-1;k++)
if (a[k]>a[k+1])
{
temp = a[k];
a[k] = a[k+1];
a[k+1] = temp;
}
}
#include<stdio.h>
int main()
{
int i,j,m,n,t,temp;
scanf("%d%d",&m,&n);
int a[m],b[n],c[m+n];
printf("输入一维数组a[m]:\n");
for(i=0;i<m;i++)
{
scanf("%d",&a[i]);
}
printf("a[m]排序前:");
for(i = 0;i <m;i++)
{
printf("%d ",a[i]);
}
printf("\n");
for(i = 0;i<m;i++)
{
for(j = i + 1;j <m;j++)
{
if(a[i] > a[j])
{
temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
}
printf("a[m]排序后:");
for(i = 0;i<m;i++)
{
printf("%d ",a[i]);
}
printf("\n");
printf("输入一维数组b[n]:\n");
for(i=0;i<n;i++)
{
scanf("%d",&b[i]);
}
printf("b[n]排序前:");
for(i = 0;i <n;i++)
{
printf("%d ",b[i]);
}
printf("\n");
for(i = 0;i <n;i++)
{
for(j = i + 1;j <n;j++)
{
if(b[i] > b[j])
{
temp = b[i];
b[i] = b[j];
b[j] = temp;
}
}
}
printf("b[n]排序后:");
for(i = 0;i < n;i++)
{
printf("%d ",b[i]);
}
printf("\n");
for(i=0,j=0,t=0;i<m&&j<n;)
{
if(a[i] < b[j])
{
c[t++] = a[i++];
}
else
{
c[t++] = b[j++];
}
}
while(i < m)
{
c[t++] = a[i++];
}
while(j < n)
{
c[t++] = b[j++];
}
for(i=0;i<t;i++)
{
printf("%d ",c[i]);
}
return 0;
}输出:
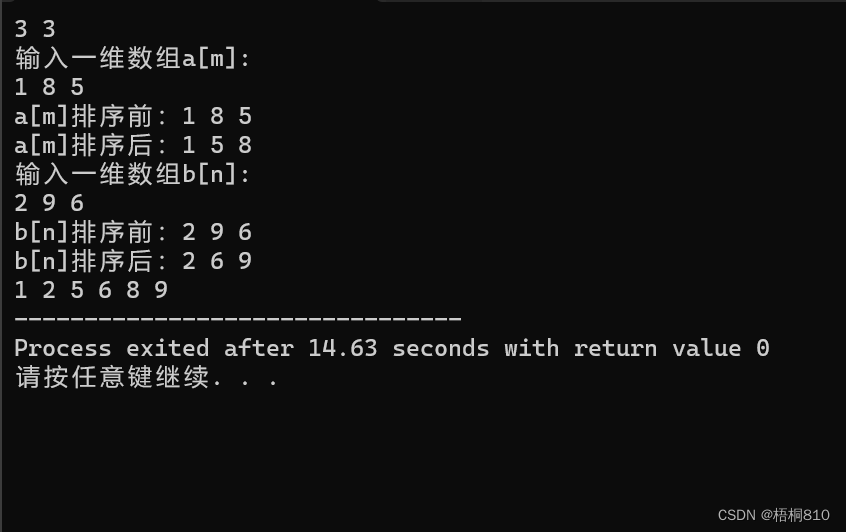
3.把一维数组中的数值按照奇偶性拆分成两个一维数组
分析:
该代码首先创建了一个包含10个元素的一维数组,然后使用for循环遍历数组。根据元素奇偶性,将它们分别存储到b数组和c数组中。最后使用printf语句输出两个数组中的元素。
程序:
#include<stdio.h>
int main()
{
int a[10];
int b[10],c[10];
int i,j,k;
printf("请输入10个数赋给数组a[10]\n");
for(i=0;i<10;i++)
{
scanf("%d",&a[i]);
}
printf("\n");
for(i=0,j=0,k=0;i<10;i++)
{
if(a[i]%2==0)
{
b[j]=a[i];
j++;
}
else
{
c[k]=a[i];
k++;
}
}
printf("其中偶数数组b[]为:");
for(i=0;i<j;i++)
{
printf("%d ",b[i]);
}
printf("\n");
printf("其中奇数数组c[]为:");
for(i=0;i<k;i++)
{
printf("%d ",c[i]);
}
return 0;
}

















 2445
2445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











