







HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树
-
当我们往HashMap中put元素时,利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
-
存储时,如果出现hash值相同的key,此时有两种情况。
a. 如果key相同,则覆盖原始值;
b. 如果key不同(出现冲突),则将当前的key-value放入链表或红黑树中
-
获取时,直接找到hash值对应的下标,在进一步判断key是否相同,从而找到对应值。
-
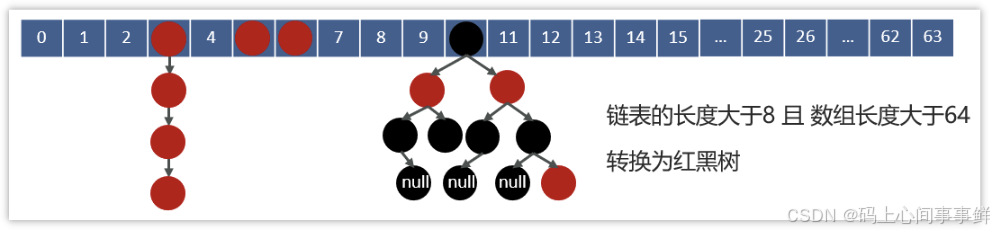
一、底层数据结构演进
| 版本 | 数据结构 | 优化目标 |
|---|---|---|
| JDK 1.7 | 数组 + 单向链表 | 解决哈希冲突 |
| JDK 1.8 | 数组 + 链表/红黑树 | 防止链表过长导致查询性能退化O(n)→O(log n) |
示例场景:
当多个键的哈希值映射到同一数组下标(桶)时:
- 链表:哈希冲突时用链表存储(时间复杂度O(n))
- 红黑树:链表长度≥8且桶总数≥64时,转为红黑树(时间复杂度O(log n))
二、哈希算法深度优化
1. 哈希扰动函数
java
// JDK 1.8的哈希计算:高位参与运算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}作用:
- 将哈希码的高16位与低16位异或,增加低位随机性
- 避免因哈希码分布不均导致大量冲突(如连续数作为键)
2. 下标计算
java
// n为数组长度(2的幂)
index = (n - 1) & hash等效操作:hash % n,但位运算效率更高。
为何用2的幂:保证(n-1)的二进制全为1(如16→15=0b1111),使哈希值均匀分布。
三、插入流程(Put)全解析
java
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}步骤分解:
- 计算哈希值:调用
hash(key)扰动 - 定位桶位置:
(n-1) & hash - 处理哈希冲突:
- 空桶:直接插入新节点
Node<K,V> - 链表:遍历链表,存在相同key则更新value,否则尾插新节点
- 红黑树:调用
TreeNode.putTreeVal()插入
- 空桶:直接插入新节点
- 树化检查:链表长度≥8时,尝试转为红黑树(需数组长度≥64)
- 扩容检查:元素总数 > 容量×负载因子(默认0.75)则扩容
链表转红黑树阈值:
- 选择8的统计学依据:哈希冲突符合泊松分布,链表长度≥8的概率极低(约千万分之一)
四、扩容机制(Resize)核心技术
1. 触发条件
- 元素数量 > 当前容量 × 负载因子(默认16×0.75=12)
2. 扩容过程
- 创建新数组:容量翻倍(如16→32)
- 数据迁移:
- 链表拆分:根据哈希值高位判断位置(原位置或原位置+旧容量)
java
// 旧容量为16(二进制0b10000) if ((e.hash & oldCap) == 0) { // 留在原位置(如index=3) } else { // 迁移到新位置(如index=3+16=19) } - 红黑树拆分:节点数≤6时退化为链表
- 链表拆分:根据哈希值高位判断位置(原位置或原位置+旧容量)
3. 扩容优化
- 无需重新计算哈希:利用高位快速定位新下标
- 均摊时间复杂度:O(1)(分摊到每次插入操作)
五、查找流程(Get)原理
java
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}步骤分解:
- 计算哈希值:同Put流程
- 定位桶位置
- 遍历结构:
- 链表:顺序查找,调用
equals()比较key - 红黑树:树查找,时间复杂度O(log n)
- 链表:顺序查找,调用
关键点:
- 重写equals()必须重写hashCode():确保相同对象返回相同哈希值
六、并发安全问题深度分析
1. 典型问题
- JDK 1.7头插法死循环:多线程扩容导致链表成环
- JDK 1.8数据覆盖:多线程put可能丢失数据
2. 解决方案
- 替代方案:使用
ConcurrentHashMap(分段锁/CAS+synchronized) - 加锁:
Collections.synchronizedMap(new HashMap<>())
七、设计哲学与性能调优
1. 关键参数选择
| 参数 | 默认值 | 作用 | 调优建议 |
|---|---|---|---|
| 初始容量 | 16 | 减少扩容次数 | 预估元素数量/0.75并取2的幂 |
| 负载因子 | 0.75 | 平衡空间与时间效率 | 高查询频率可降低(如0.5) |
| 树化阈值 | 8 | 防止链表查询性能退化 | 非必要不修改 |
2. 最佳实践
- 键对象设计:
- 使用不可变对象(如String、Integer)作为键
- 正确实现
hashCode()和equals()
- 预分配容量:
java
// 预期存储100个元素,初始容量=100/0.75≈133 → 取256(2^8) Map<String, Object> map = new HashMap<>(256);
八、与其他结构的对比
| 结构 | 线程安全 | 有序性 | 时间复杂度(平均) | 适用场景 |
|---|---|---|---|---|
| HashMap | 否 | 无 | O(1) | 高频读写,无需同步 |
| LinkedHashMap | 否 | 插入序 | O(1) | 需要保留插入/访问顺序 |
| TreeMap | 否 | 键排序 | O(log n) | 需要自然或自定义排序 |
| ConcurrentHashMap | 是 | 无 | O(1) | 高并发环境 |
总结
- 核心思想:空间换时间,哈希算法决定性能下限,数据结构设计决定上限
- 适用场景:单线程环境下的高效键值存储,如缓存、临时数据存储
- 避坑指南:避免在多线程环境直接使用,注意键对象的哈希分布


















 43万+
43万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









