






以下是今天学习的知识点与代码测试:
面向对象
Scala 的面向对象思想和 Java 的面向对象思想和概念是一致的。
Scala 中语法和 Java 不同,补充了更多的功能。
一、Scala 包
基本语法
package 包名
Scala 包的三大作用(和 Java 一样)
-
- 区分相同名字的类
- 当类很多时,可以很好的管理类
- 控制访问范围
二、包的命名
- 命名规则
只能包含数字、字母、下划线、小圆点.,但不能用数字开头,也不要使用关键字。
- 案例实操
demo.class.exec1 //错误,因为 class 关键字
demo.12a //错误,数字开头
- 命名规范
一般是小写字母+小圆点
com.公司名.项目名.业务模块名
- 案例实操
com.zpark.oa.model com.zpark.oa.controller
com.sohu.bank.order
三、包说明(包语句)
- 说明
Scala 有两种包的管理风格,一种方式和 Java 的包管理风格相同,每个源文件一个包(包名和源文件所在路径不要求必须一致),包名用“.”进行分隔以表示包的层级关系,如com.zpark.scala。另一种风格,通过嵌套的风格表示层级关系,如下
package com{ package zpark{
package scala{
}
}
第二种风格有以下特点:
-
- 一个源文件中可以声明多个 package
- 子包中的类可以直接访问父包中的内容,而无需导包
- 案例实操
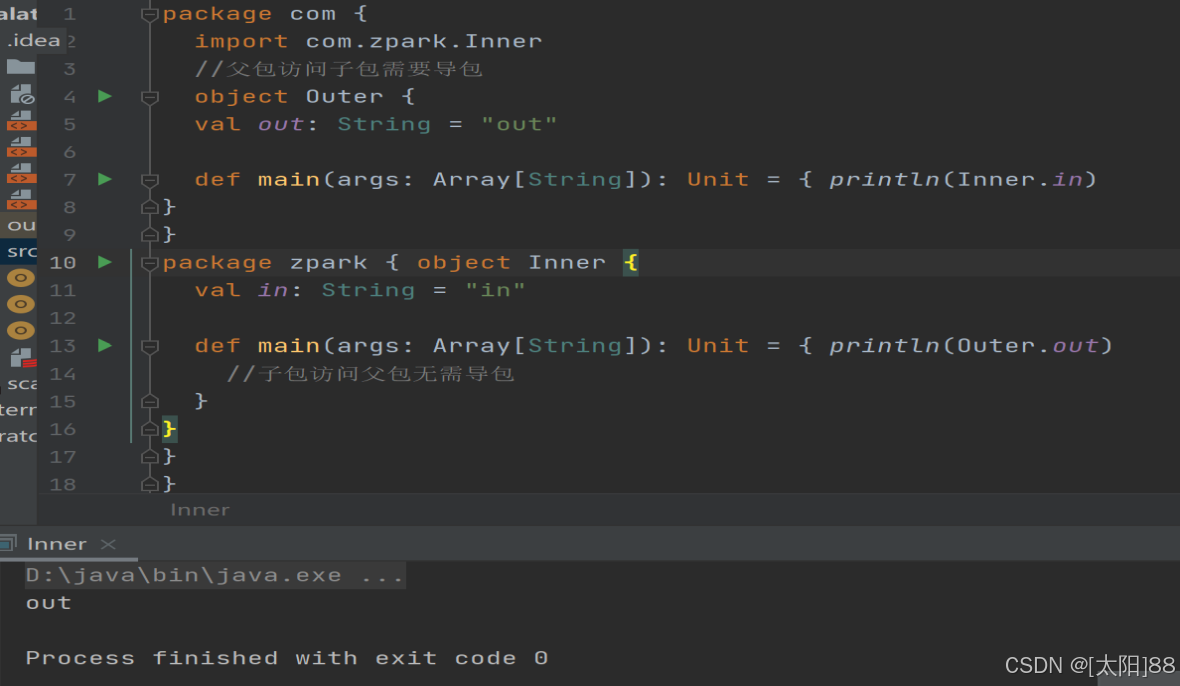
四、包对象
在 Scala 中可以为每个包定义一个同名的包对象,定义在包对象中的成员,作为其对应包下所有 class 和 object 的共享变量,可以被直接访问。
1)定义
package object com{
val shareValue="share" def shareMethod()={}
}
- 说明
若使用 Java 的包管理风格,则包对象一般定义在其对应包下的 package.scala文件中,包对象名与包名保持一致。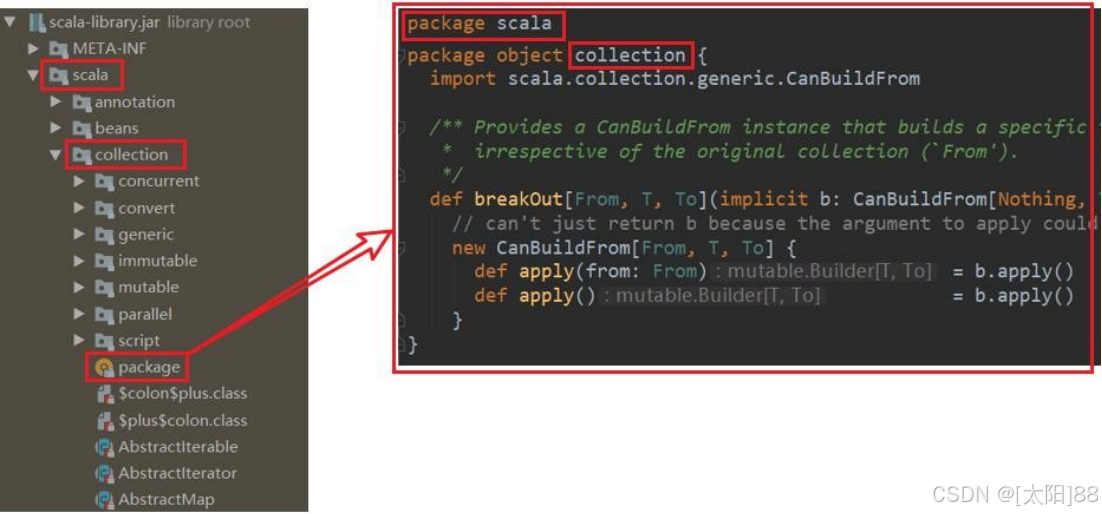
如采用嵌套方式管理包,则包对象可与包定义在同一文件中,但是要保证包对象与包声明在同一作用域中。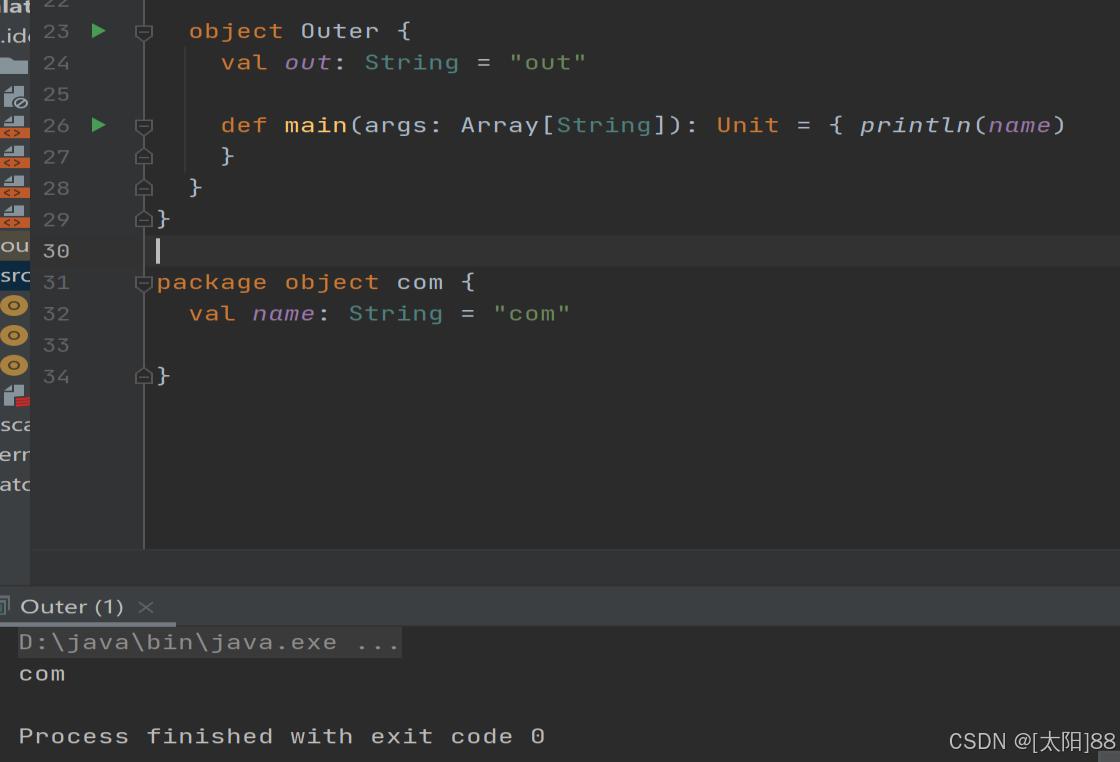
五、导包说明
- 和 Java 一样,可以在顶部使用 import 导入,在这个文件中的所有类都可以使用。
- 局部导入:什么时候使用,什么时候导入。在其作用范围内都可以使用3)通配符导入:import java.util._
- 给类起名:import java.util.{ArrayList=>JL}
- 导入相同包的多个类:import java.util.{HashSet, ArrayList} 6)屏蔽类:import java.util.{ArrayList =>_,_}
- 导入包的绝对路径:new _root_.java.util.HashMap
package java { package util {
class HashMap {
}
}
}
注意
Scala 中的三个默认导入分别是
import java.lang._ import scala._ import scala.Predef._
六、类和对象
类:可以看成一个模板对象:表示具体的事物
七、定义类
1)回顾:Java 中的类
如果类是 public 的,则必须和文件名一致。一般,一个.java 有一个 public 类
注意:Scala 中没有 public,一个.scala 中可以写多个类。
- 基本语法
[修饰符] class 类名 {
类体
}
说明
-
- Scala 语法中,类并不声明为public,所有这些类都具有公有可见性(即默认就是public)
- 一个Scala 源文件可以包含多个类
- 案例实操
package com.zpark.chapter06
//(1)Scala 语法中,类并不声明为 public,所有这些类都具有公有可见性(即默认就是 public)
class Person {
}
//(2)一个 Scala 源文件可以包含多个类
class Teacher{
}
八、属性
属性是类的一个组成部分
- 基本语法
[修饰符] var|val 属性名称 [:类型] = 属性值
注:Bean 属性(@BeanPropetry),可以自动生成规范的 setXxx/getXxx 方法
案例实操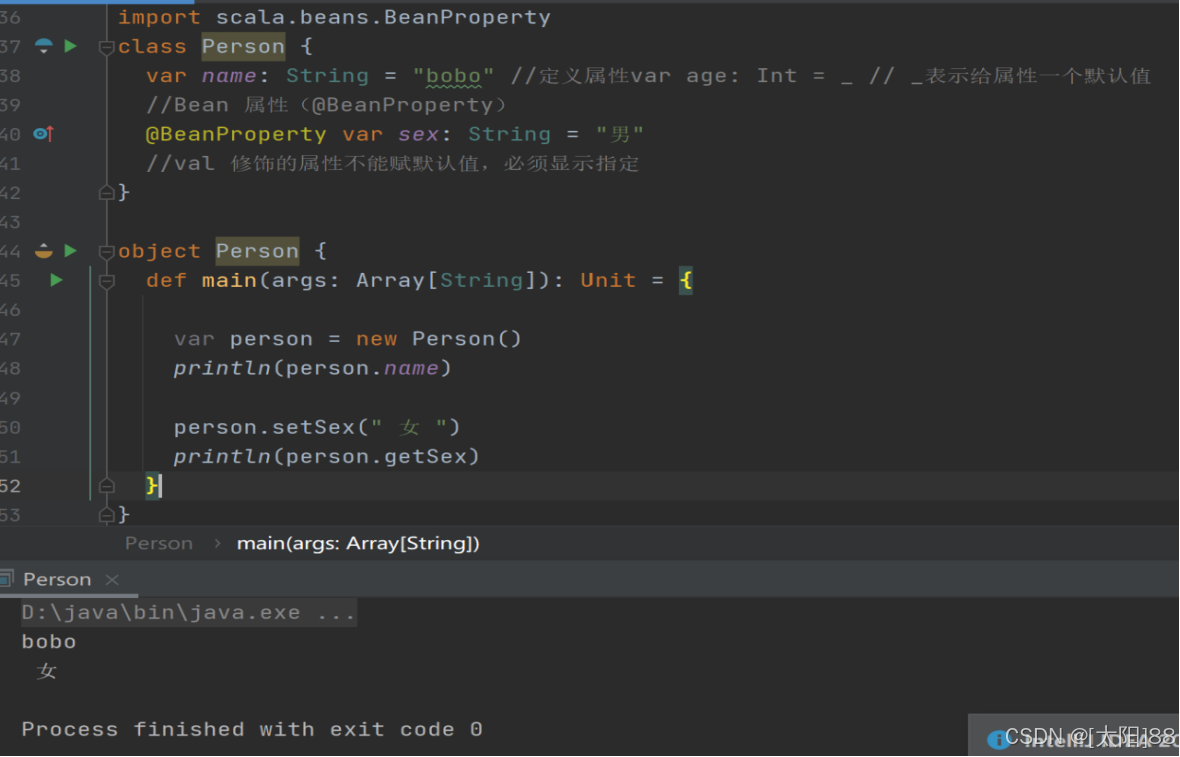
- 说明
在 Java 中,访问权限分为:public,private,protected 和默认。在 Scala 中,你可以通过类似的修饰符达到同样的效果。但是使用上有区别。
-
- Scala 中属性和方法的默认访问权限为 public,但 Scala 中无 public 关键字。
- private 为私有权限,只在类的内部和伴生对象中可用。
- protected 为受保护权限,Scala 中受保护权限比 Java 中更严格,同类、子类可以访问,同包无法访问。
- private[包名]增加包访问权限,包名下的其他类也可以使用
- 案例实操
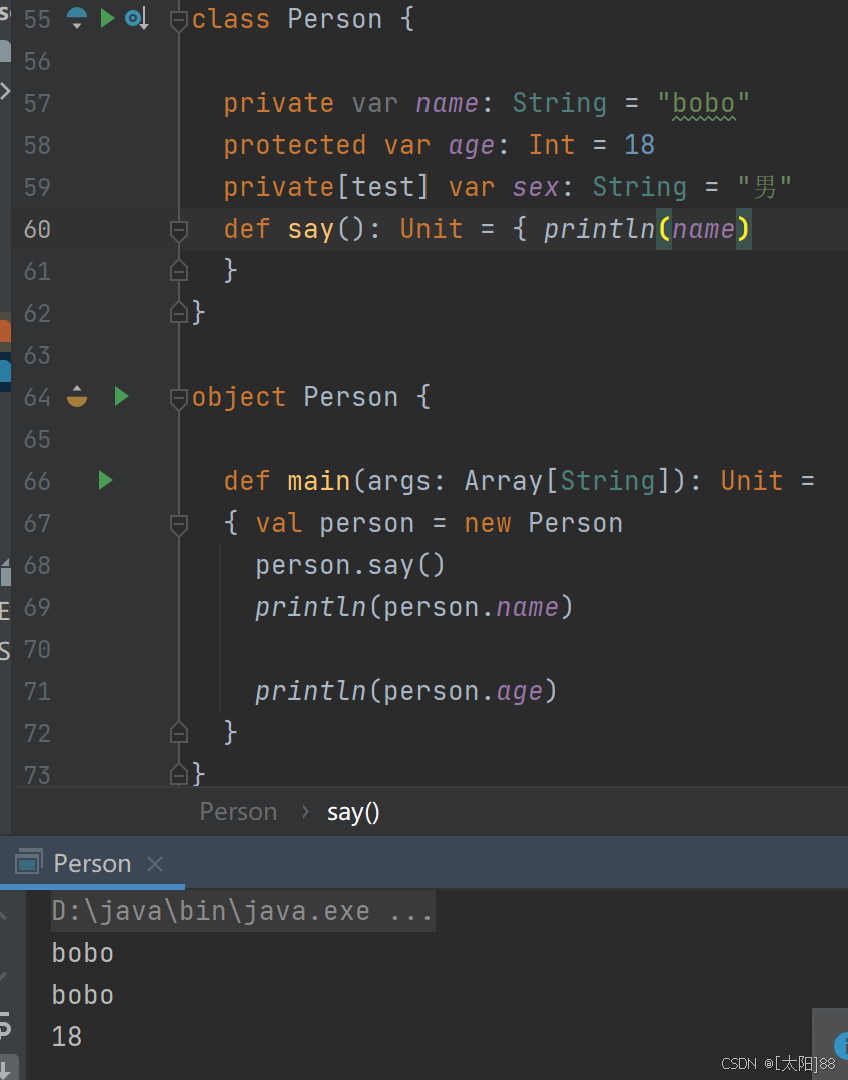
九、方法
- 基本语法
def 方法名(参数列表) [:返回值类型] = {
方法体
}
- 案例实操
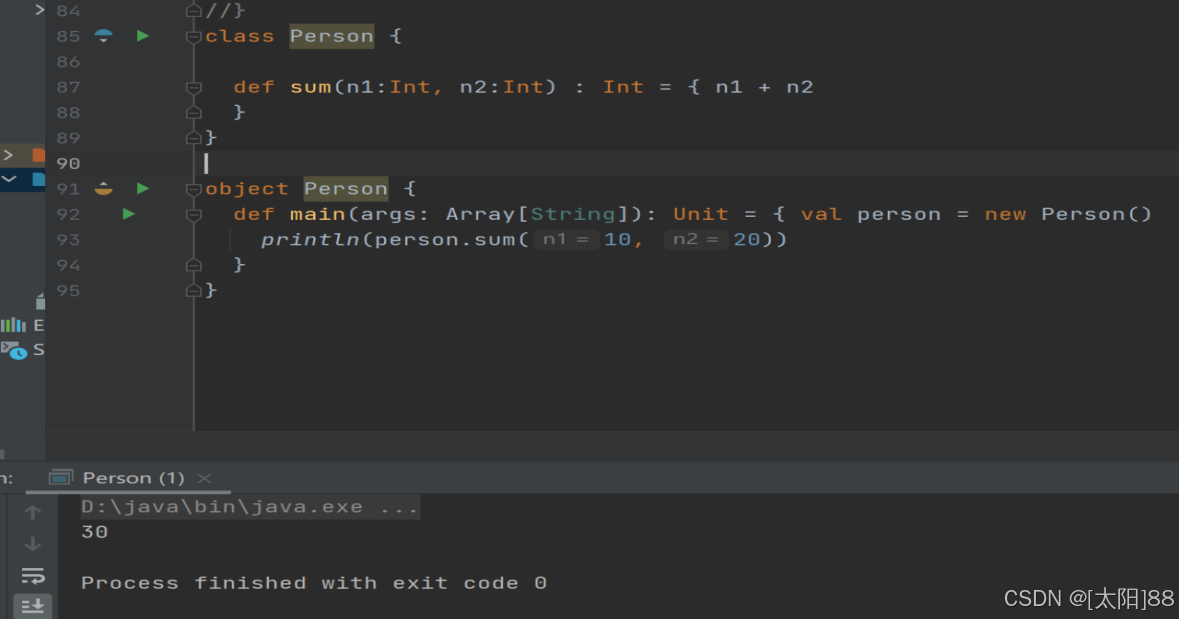
十、创建对象
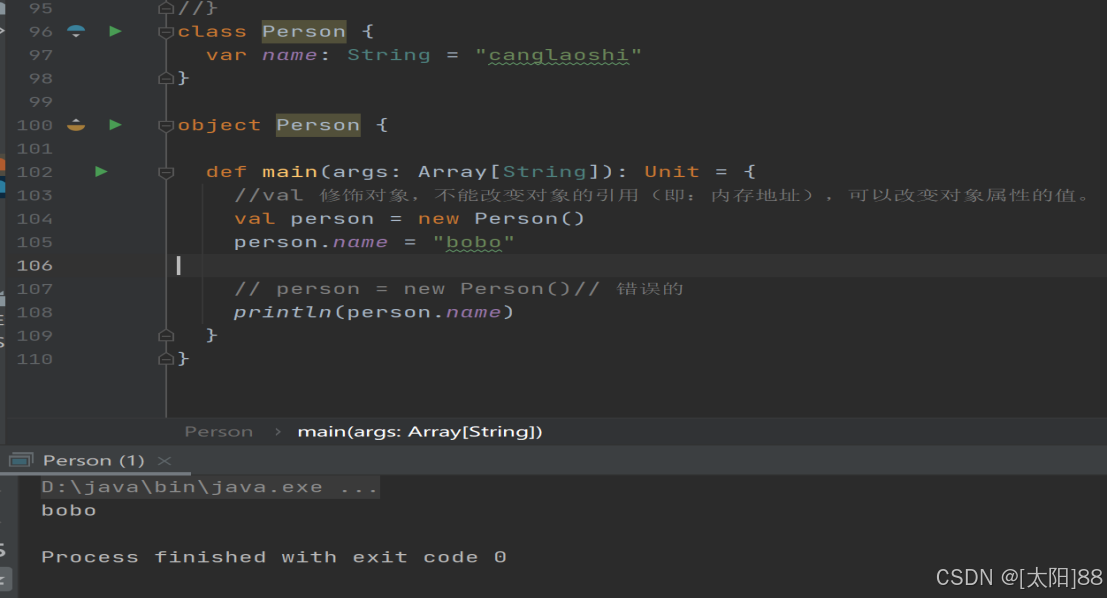
- 基本语法
val | var 对象名 [:类型] = new 类型()
- 案例实操
- val 修饰对象,不能改变对象的引用(即:内存地址),可以改变对象属性的值。
- var 修饰对象,可以修改对象的引用和修改对象的属性值
- 自动推导变量类型不能多态,所以多态需要显示声明
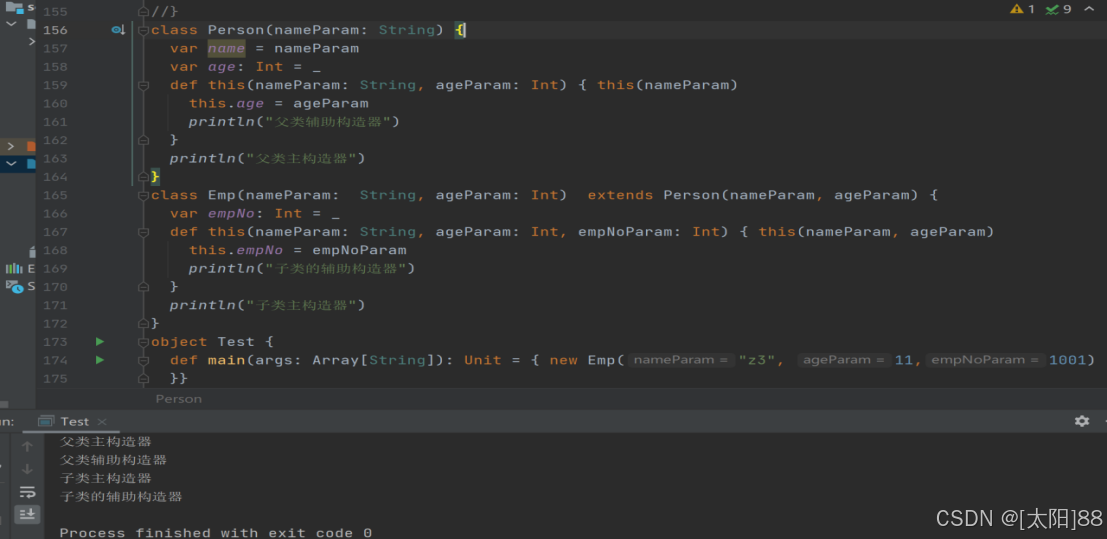
十一、构造器
和 Java 一样,Scala 构造对象也需要调用构造方法,并且可以有任意多个构造方法。
Scala 类的构造器包括:主构造器和辅助构造器
- 基本语法
class 类名(形参列表) { // 主构造器
// 类 体
def this(形参列表) { // 辅助构造器
}
def this(形参列表) { //辅助构造器可以有多个...
}
}
说明:
-
- 辅助构造器,函数的名称 this,可以有多个,编译器通过参数的个数及类型来区分。
- 辅助构造方法不能直接构建对象,必须直接或者间接调用主构造方法。
- 构造器调用其他另外的构造器,要求被调用构造器必须提前声明。
- 案例实操
- 如果主构造器无参数,小括号可省略,构建对象时调用的构造方法的小括号也可以省略。
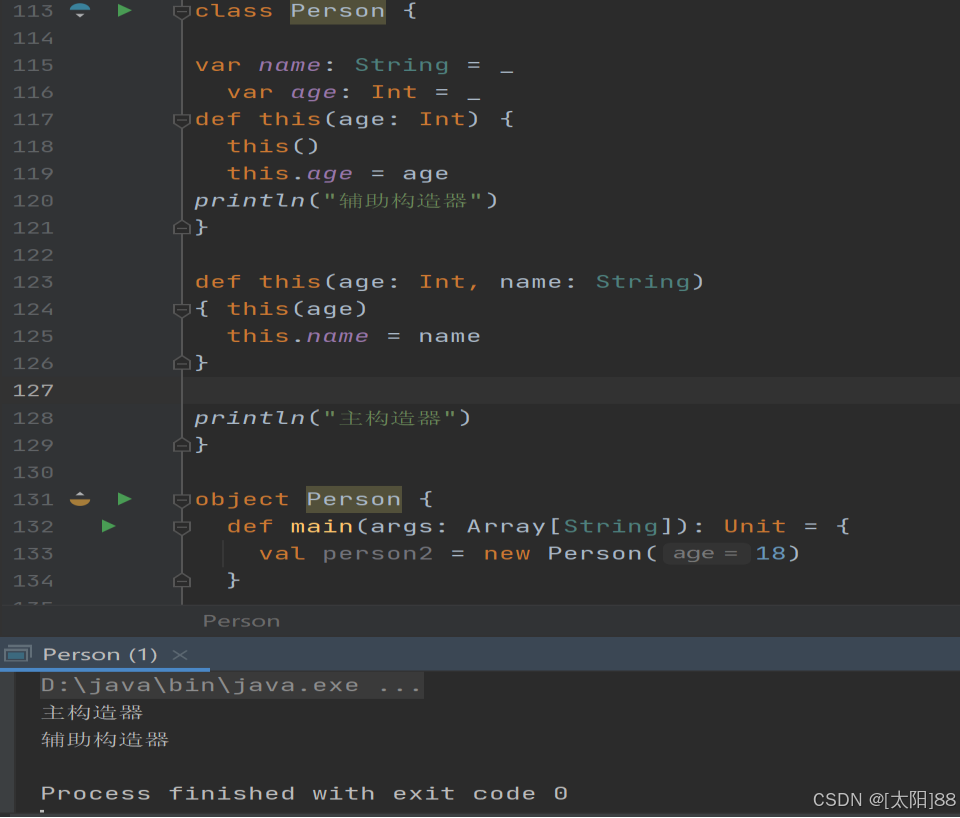
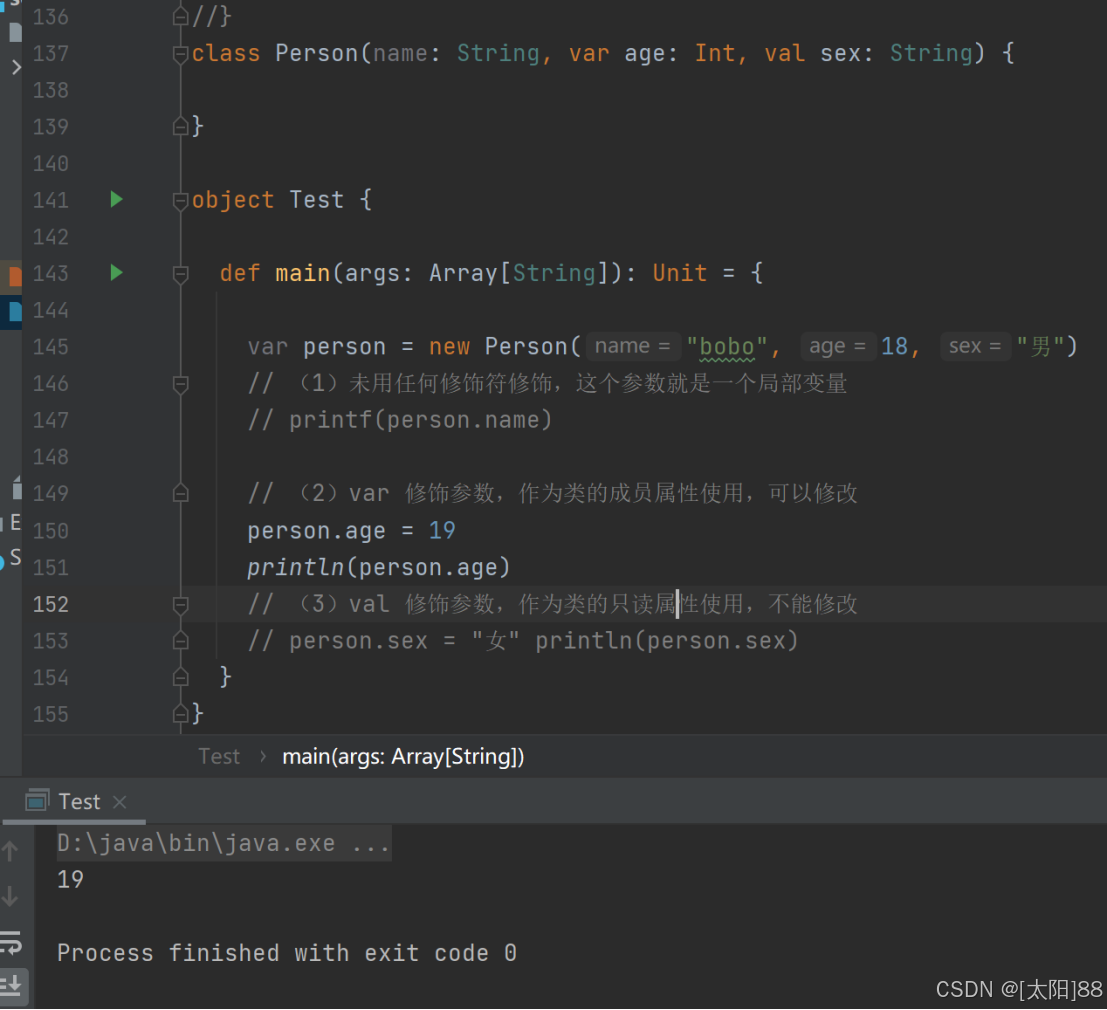
十二、构造器参数
- 说明
Scala 类的主构造器函数的形参包括三种类型:未用任何修饰、var 修饰、val 修饰
-
- 未用任何修饰符修饰,这个参数就是一个局部变量
- var 修饰参数,作为类的成员属性使用,可以修改
- val 修饰参数,作为类只读属性使用,不能修改
- 案例实操
十三、封装
封装就是把抽象出的数据和对数据的操作封装在一起,数据被保护在内部,程序的其它部分只有通过被授权的操作(成员方法),才能对数据进行操作。Java 封装操作如下,
- 将属性进行私有化
- 提供一个公共的 set 方法,用于对属性赋值
- 提供一个公共的 get 方法,用于获取属性的值
Scala 中的 public 属性,底层实际为 private,并通过 get 方法(obj.field())和 set 方法
(obj.field_=(value))对其进行操作。所以 Scala 并不推荐将属性设为 private,再为其设置public 的 get 和 set 方法的做法。但由于很多 Java 框架都利用反射调用 getXXX 和 setXXX 方法,有时候为了和这些框架兼容,也会为 Scala 的属性设置 getXXX 和 setXXX 方法(通过@BeanProperty 注解实现)。
十四、继承和多态
- 基本语法
class 子类名 extends 父类名 { 类 体 }
-
- 子类继承父类的属性和方法
- scala 是单继承
- 案例实操
- 子类继承父类的属性和方法
- 继承的调用顺序:父类构造器->子类构造器
- 动态绑定
Scala 中属性和方法都是动态绑定,而Java 中只有方法为动态绑定。
案例实操(对比 Java 与 Scala 的重写) Scala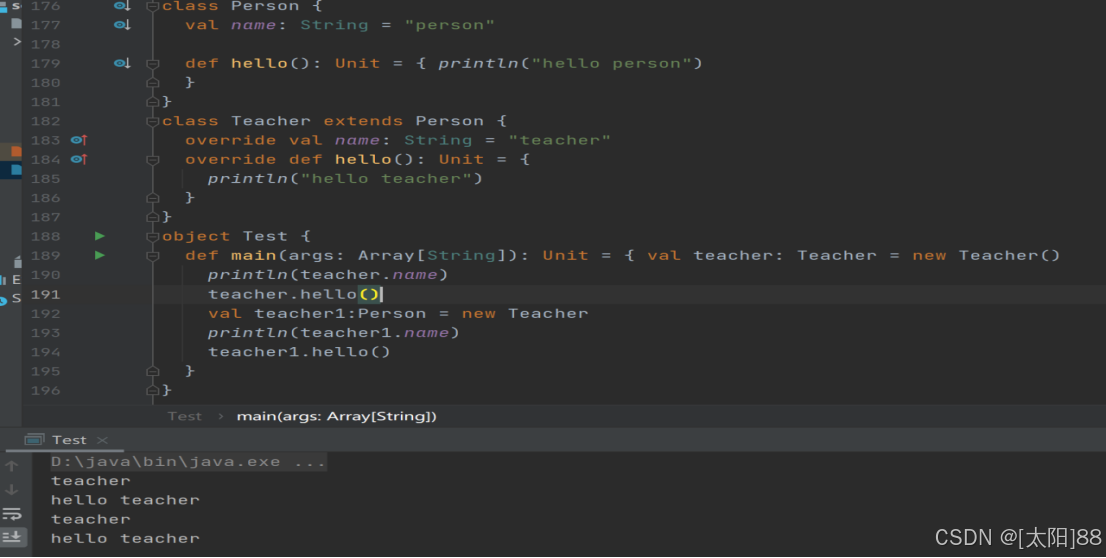
Java
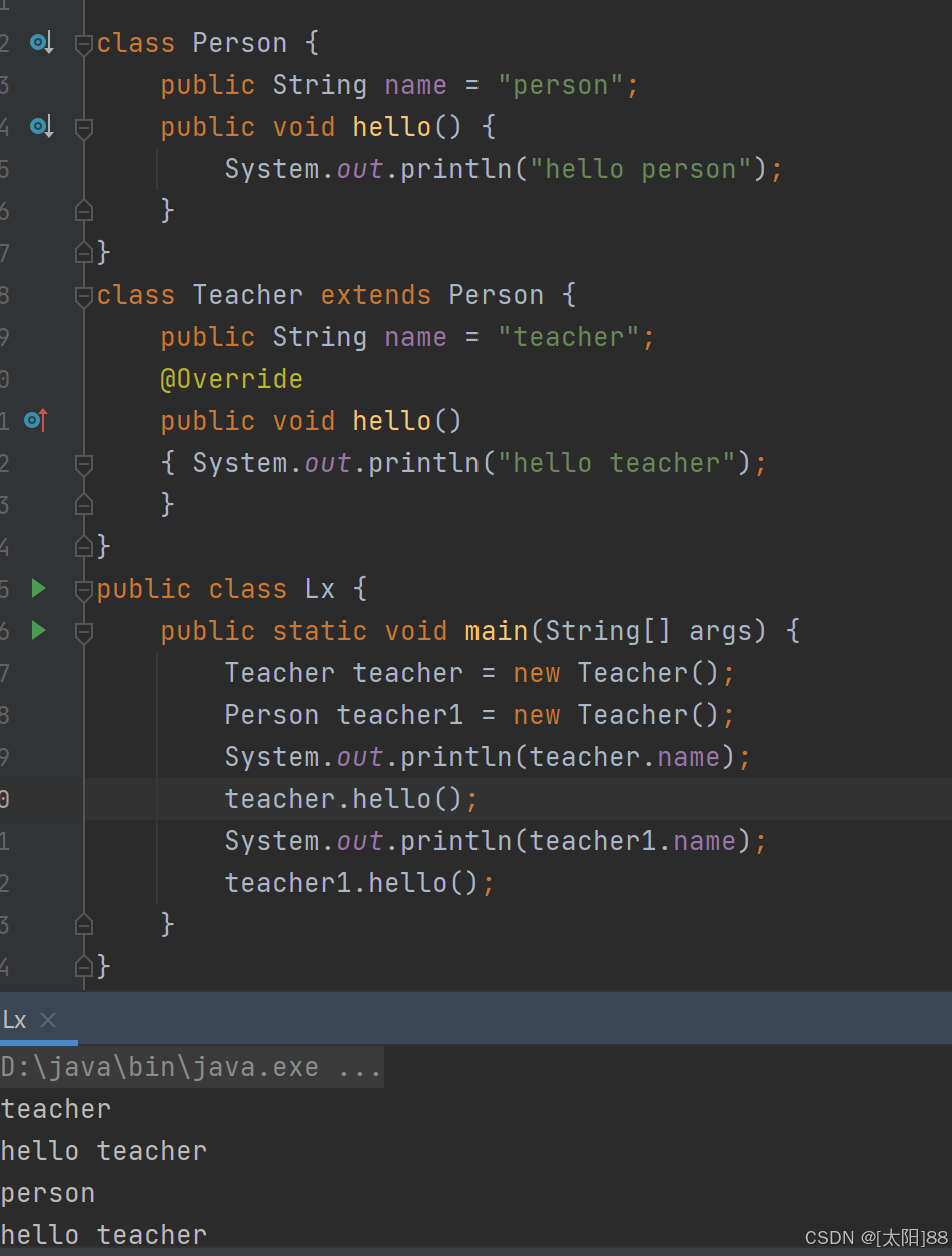
结果对比
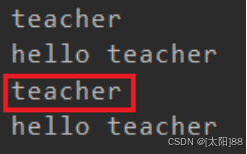
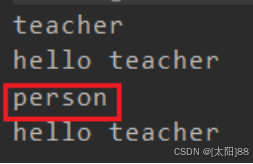

















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









