






一、环境准备
- 硬件要求:
- GPU显卡(可选):NVIDIA RTX 3090/A100/H100(24GB显存更流畅)。
- 硬盘:至少50GB SSD(用于模型存储和缓存)。
- 内存:最少16GB,推荐32GB以上,以保证模型运行流畅。
- CPU处理器:建议Intel i7/AMD Ryzen 5以上。
- 操作系统:Ubuntu 22.04/CentOS 7+
-
软件安装:
Ubuntu/Debian系统:执行sudo apt update && sudo apt upgrade -y && sudo apt install -y git wget curl python3 python3-venv python3-pip
CentOS/RHEL系统:执行sudo yum update -y && sudo yum install -y git wget curl python3 python3-venv python3-pip。
二、安装Ollama
Ollama是一个专为本地环境运行和定制大型语言模型所设计的工具,它提供了创建、运行和管理此类模型的接口,以及丰富的预构建模型库。
-
下载Ollama:
访问Ollama官方下载页面(Download Ollama on Linux),复制安装命令并执行。curl -fsSL https://ollama.com/install.sh | sh或者下载Ollama软件包并手动解压到指定目录。wget https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz,然后执行tar -C /usr -xzf ollama-linux-amd64.tgz -
验证安装:执行
ollama --version来验证Ollama是否安装成功。
这里我是打开MobaXterm.exe,连接WMWare
关于Centos7首先输入ipaddr查找主机ip地址,然后在MobaXterm.exe新建会话连接主机ip,连接成功出现此图:
随后复制命令到linux操作系统执行
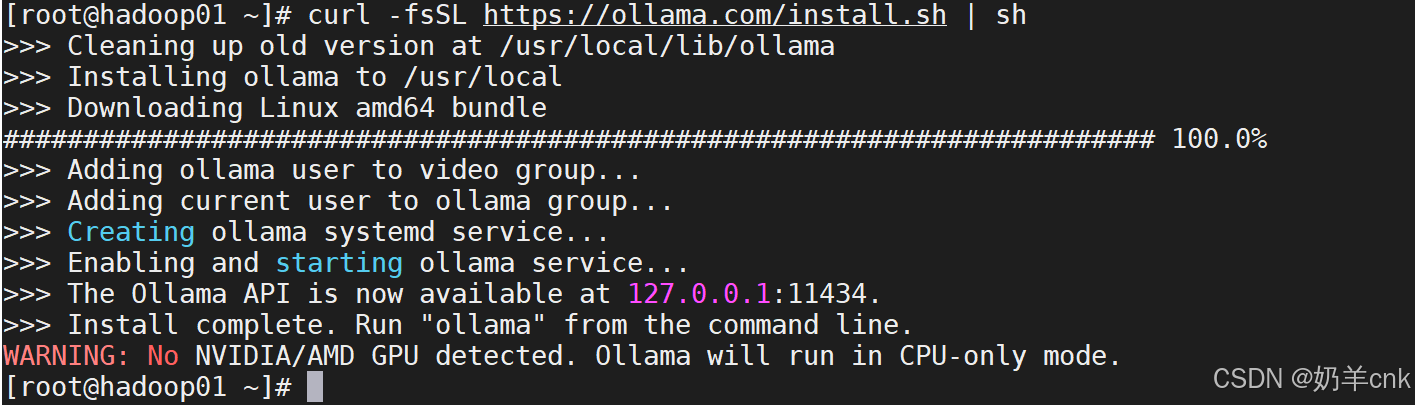
[root@hadoop01 ~]# curl -fsSL https://ollama.com/install.sh | sh

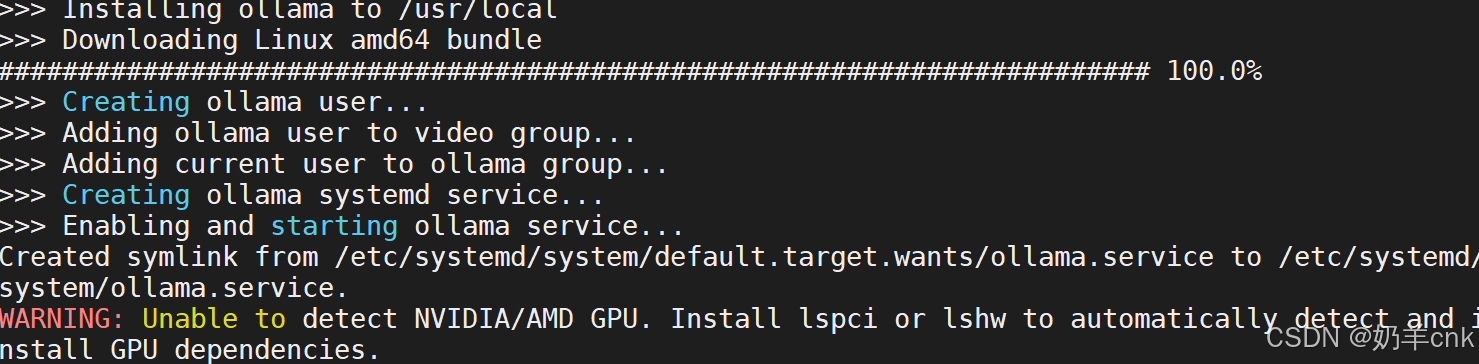
若文件报错WARNING: WARNING: Unable to detect NVIDIA/AMD GPU. Install lspci or lshw to automatically detect and install GPU dependencies
这个警告信息表明系统在尝试自动检测NVIDIA或AMD GPU时遇到了问题,因为没有找到lspci或lshw这样的硬件检测工具。这两个工具通常用于列出系统上的硬件信息,包括GPU
- 安装lspci和lshw:对于基于Debian的系统(如Ubuntu),可以使用
apt-get或apt命令安装这些工具
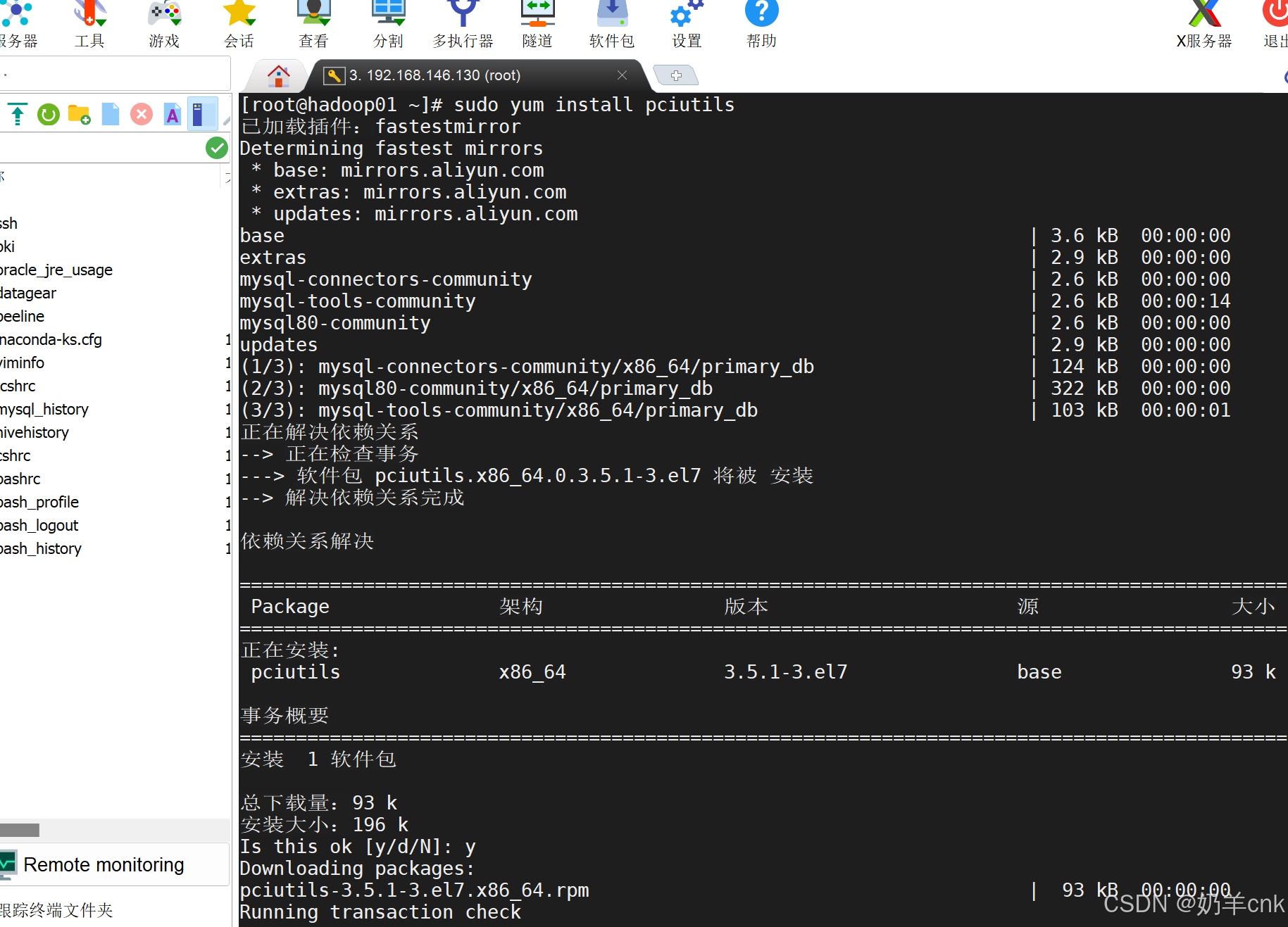
对于基于RPM的系统(如CentOS或Fedora),可以使用sudo apt install pciutilsyum或dnf命令:sudo yum install pciutils - 安装 lshw,在 CentOS 上:
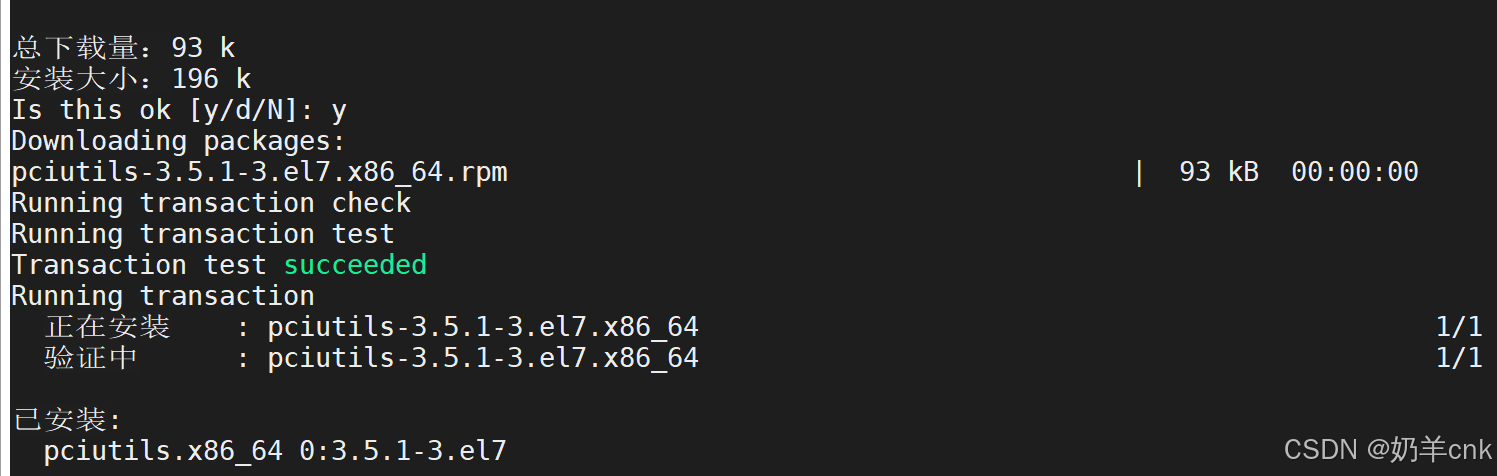
sudo yum install lshw - 重新运行安装或检测脚本:安装完
lspci和lshw后,重新运行之前导致警告的脚本或命令。这次它应该能够检测到GPU(如果存在的话)。 - 检查GPU驱动程序:即使
lspci或lshw能够检测到GPU,还需要确保已正确安装了相应的GPU驱动程序。对于NVIDIA GPU,这通常是NVIDIA驱动程序;对于AMD GPU,则是AMD驱动程序。 运行lspci -k | grep -EA3 'VGA|3D|Display'来查看GPU的详细信息以及它是否正在使用内核驱动程序。
如图所示:
随后可能出现:tar: Error is not recoverable: exiting now
这是由于最小安装时没有bzip2命令造成的简单错误,可以使用以下命令查看bzip2命令的软件包
yum whatprovides bzip2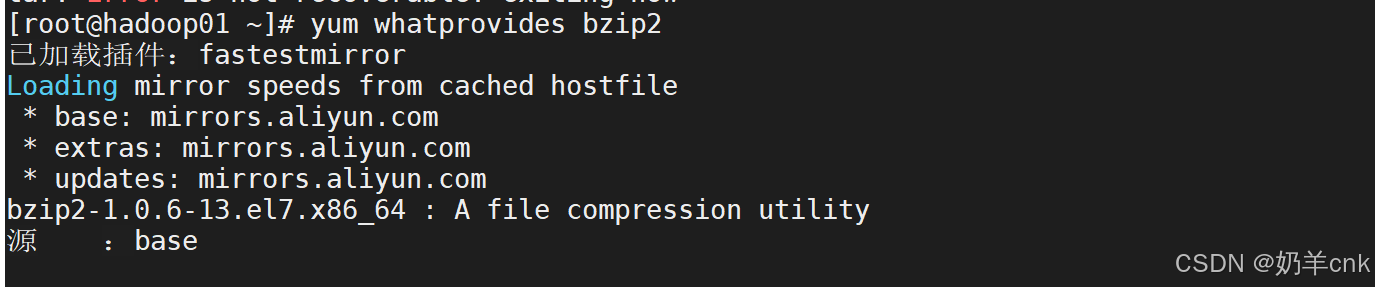 可以在倒数第二行看到bzip2的软件包名称。看到软件包名称之后,输入命令:
可以在倒数第二行看到bzip2的软件包名称。看到软件包名称之后,输入命令:
yum -y install bzip2 ,即可解决问题
接下来输入命令:
[root@hadoop01 ~]# vi /etc/systemd/system/ollama.service
进入ollama.service下编辑添加:
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"
输入wq保存退出
然后重启ollama服务
[root@hadoop01 ~]# systemctl daemon-reload
[root@hadoop01 ~]# systemctl restart ollama验证服务是否开启,11434是核心端口,必须开启。
[root@hadoop01 ~]# ss -anlp|grep 11434


登录验证,访问的是虚拟机主机ip11434端口,浏览器直接访问192.168.146.130:11434
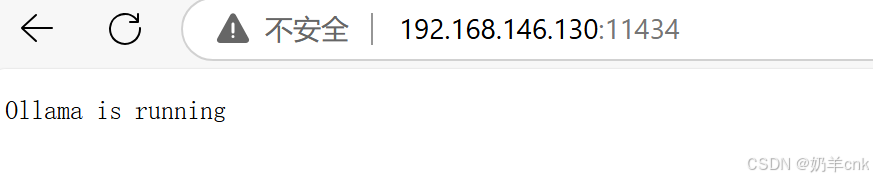
显示ollama is running 即正常运行
三、部署Deepseek R1模型
在ollama官网上,点击Models,选择deepseek-r1,不同版本对应的体积大小不同,体积越大模型越精细化,只需要复制命令即可,我这里选择7b。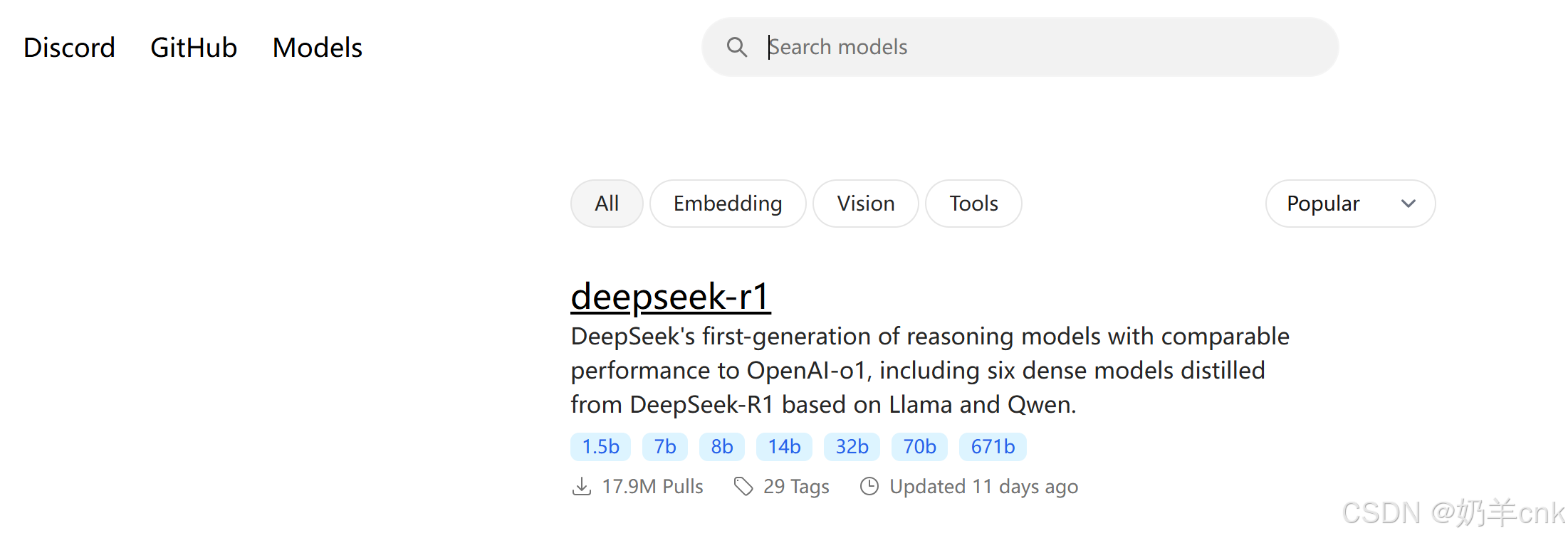
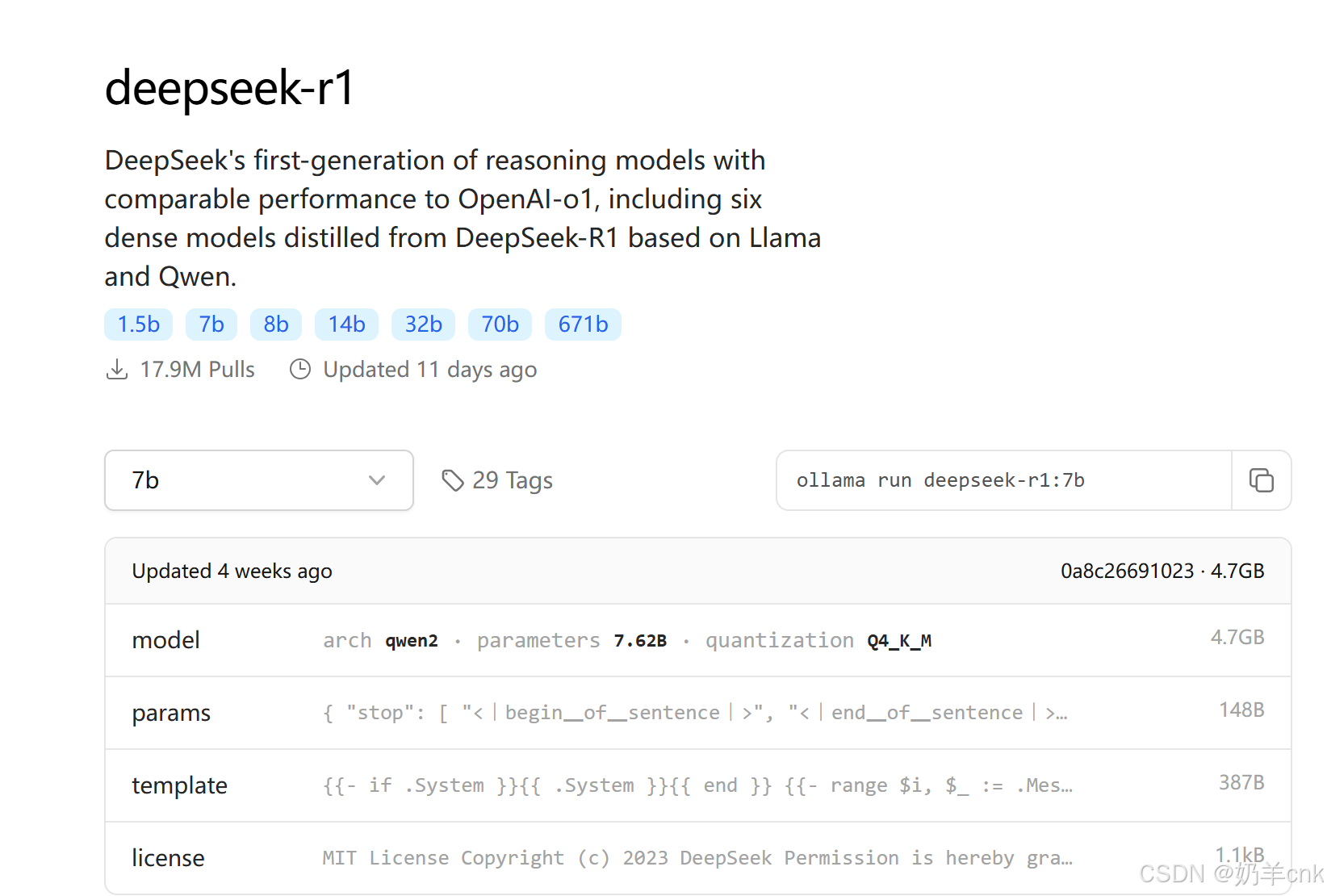
复制命令到MobaXterm.exe上
[root@hadoop01 ~]# ollama run deepseek-r1:7b
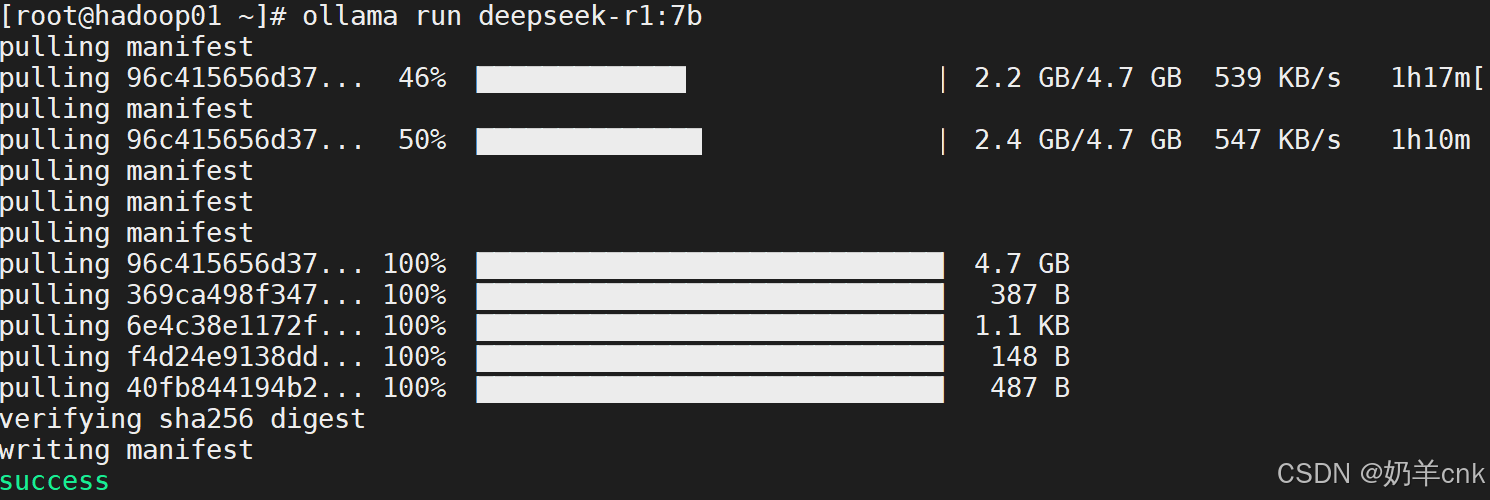
[root@hadoop01 ~]# ollama list

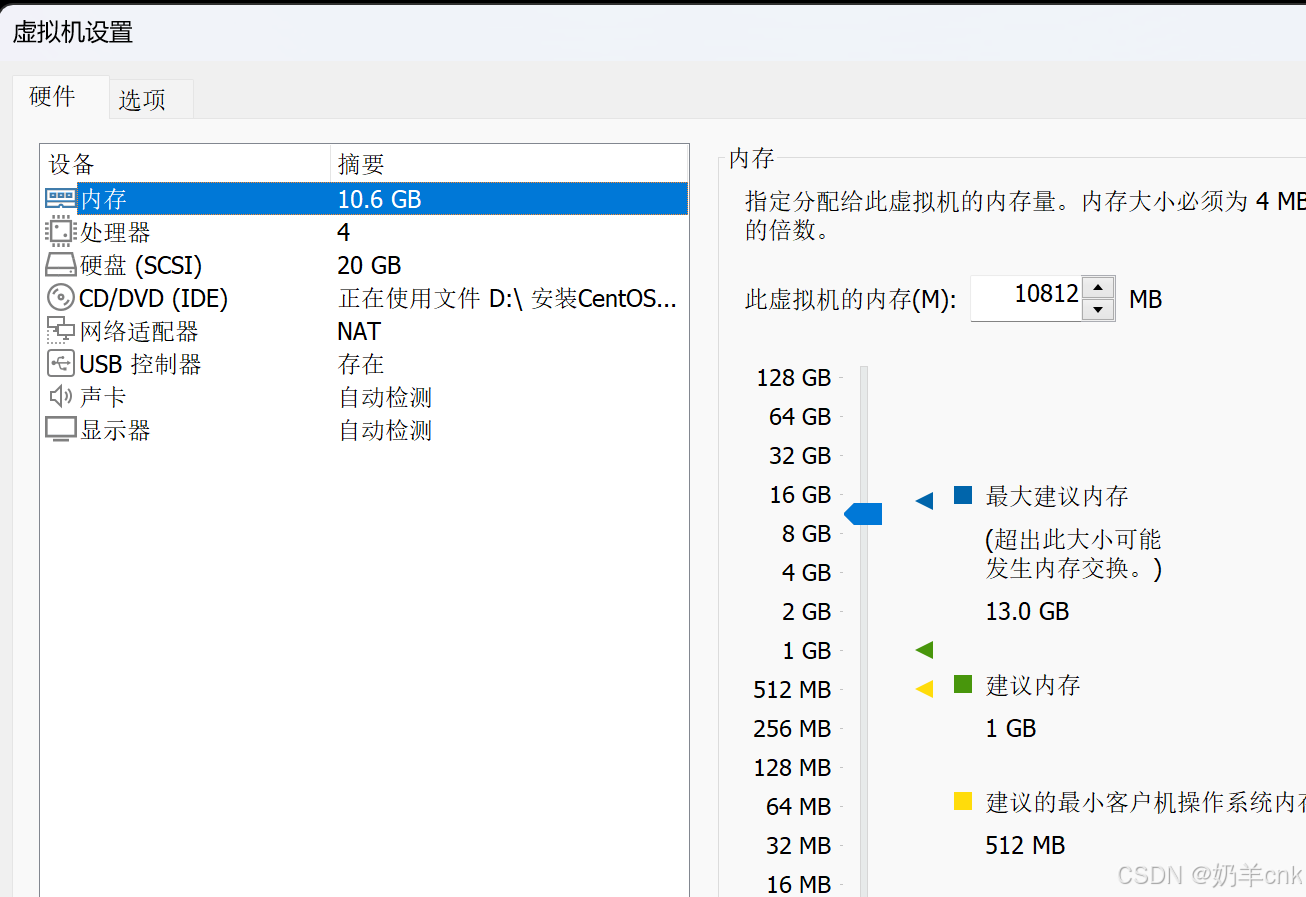
若遇到Error: model requires more system memory (5.6 GiB) than is available (3.2 GiB)报错,则表示内存不够。
解决方案:返回wmware虚拟机先关机,打开设置,把虚拟内存调大,再打开
执行命令:ollama run deepseek-1 进入聊天交互模式,就可以进入ai模式

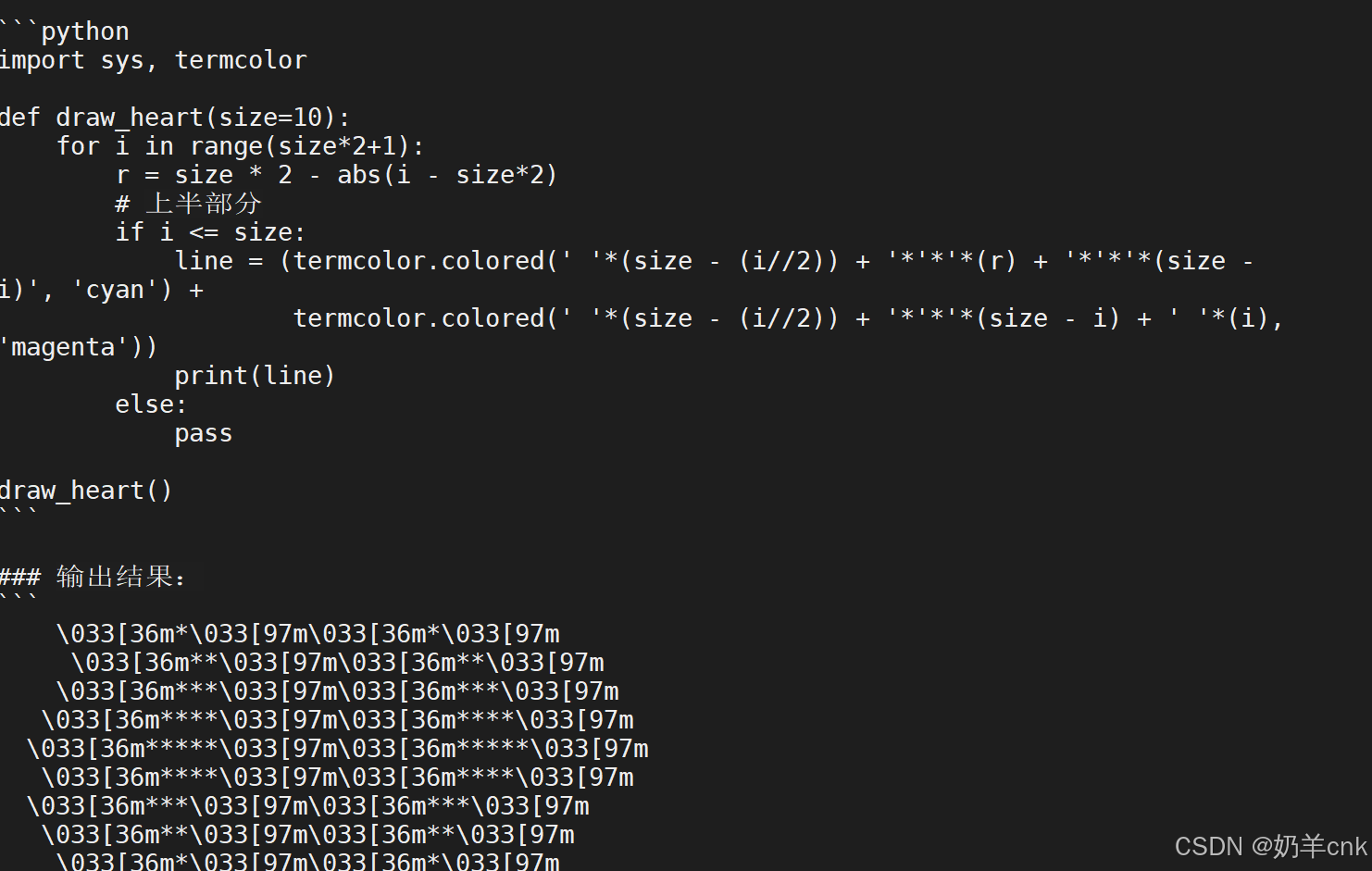 可以看到,它的话比我还啰嗦。。。
可以看到,它的话比我还啰嗦。。。
四、配置可视化界面
为了更方便地与DeepSeek模型进行交互,可以配置一个可视化界面,如Open WebUI。
- 安装Docker:根据Linux发行版执行相应的Docker安装命令。确保Docker已正确安装并正在运行。
执行以下命令
[root@localhost yum.repos.d]#wget http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
[root@localhostyum.repos.d]#yum install docker-ce-20.10.9-3.el7 docker-ce-cli-20.10.9-3.el7 containerd.io
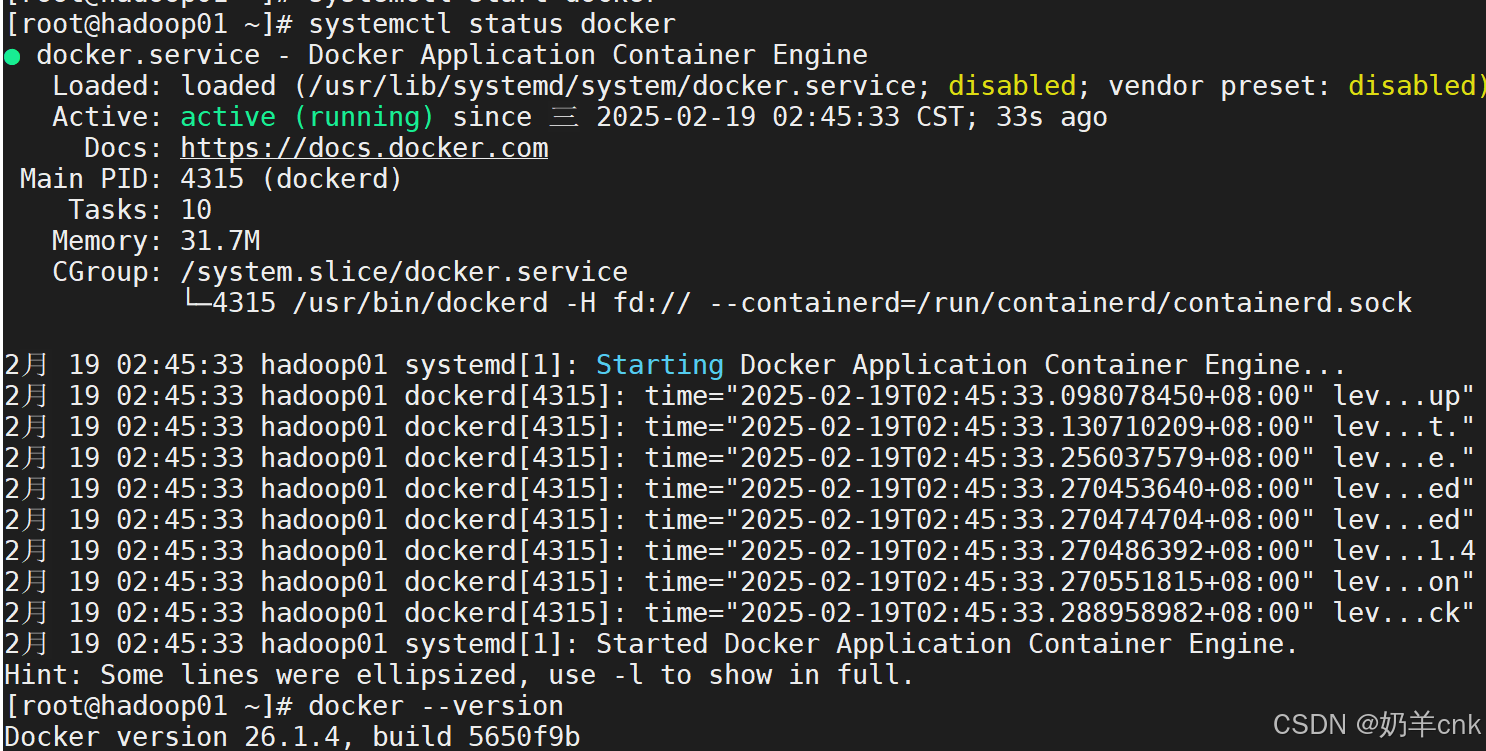
[root@localhost yum.repos.d]#systemctl start docker
[root@localhost yum.repos.d]#systemctl status docker
[root@localhost yum.repos.d]# docker --version
[root@localhost yum.repos.d]#docker info
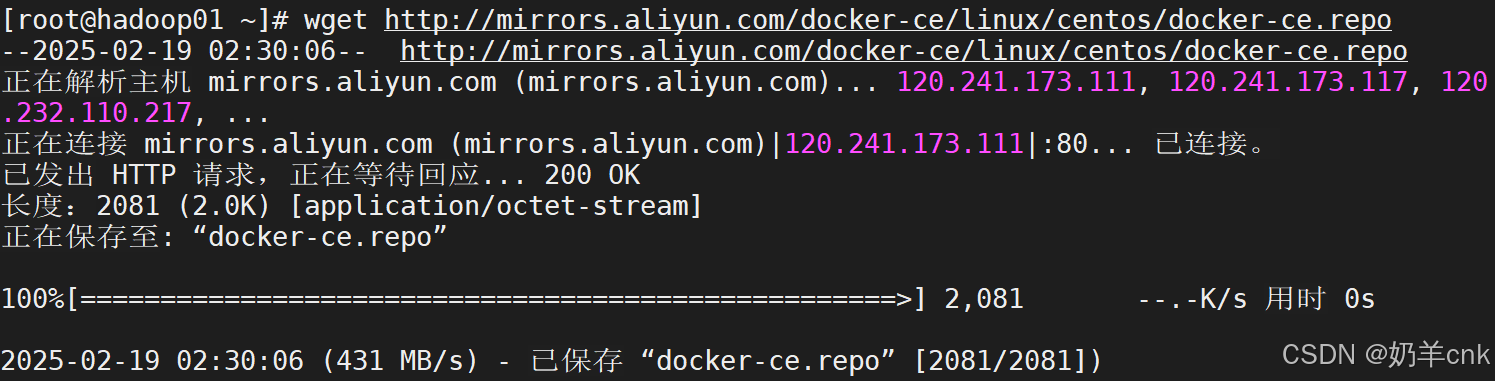
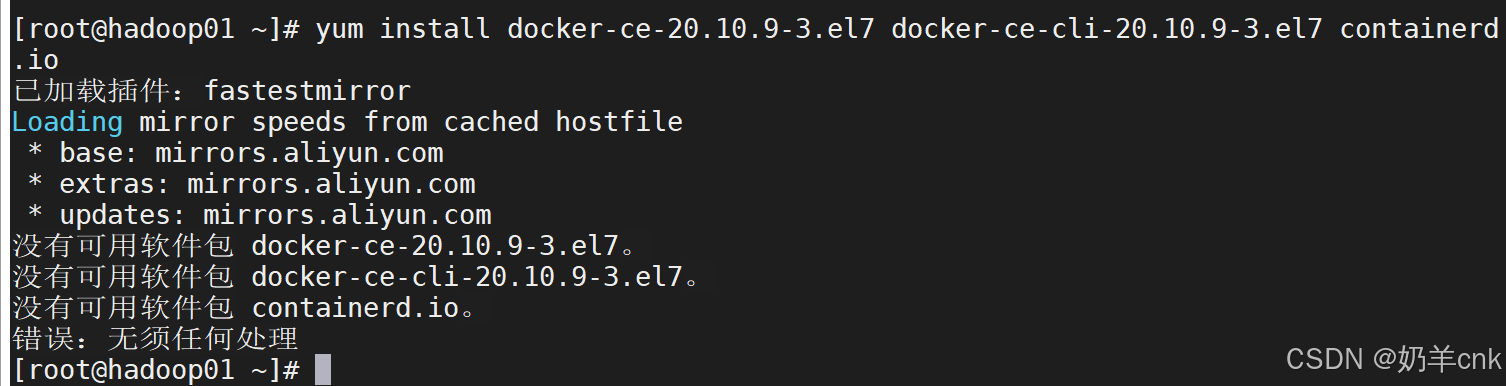

出现这个问题原因是:CentOS默认使用podman代替docker,所以需要将podman卸载
输入yum erase podman buildah,卸载podaman,输入y,等待知道卸载完毕。
安装依赖环境: yum install -y yum-utils
安装配置镜像:
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo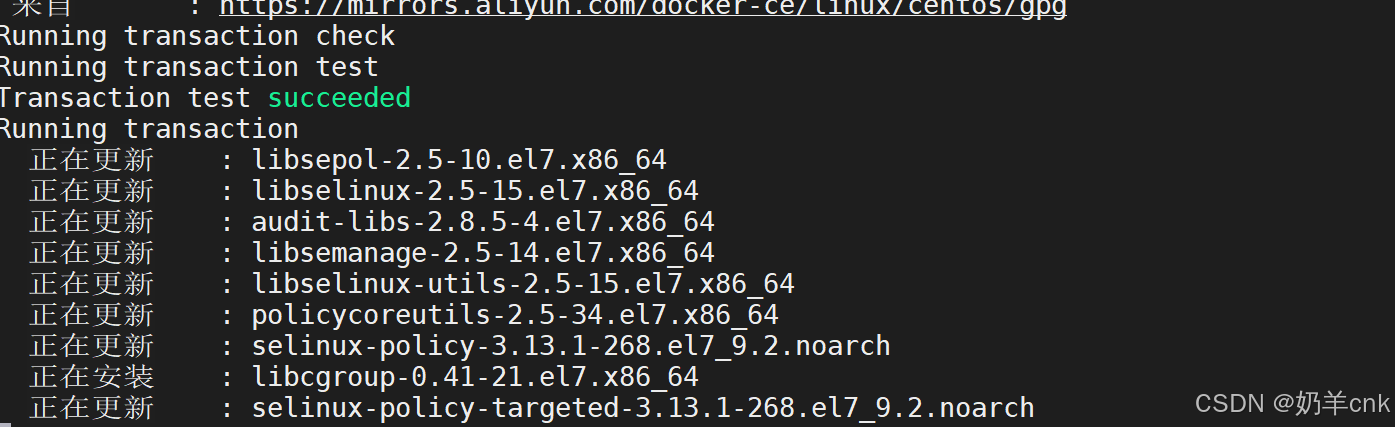
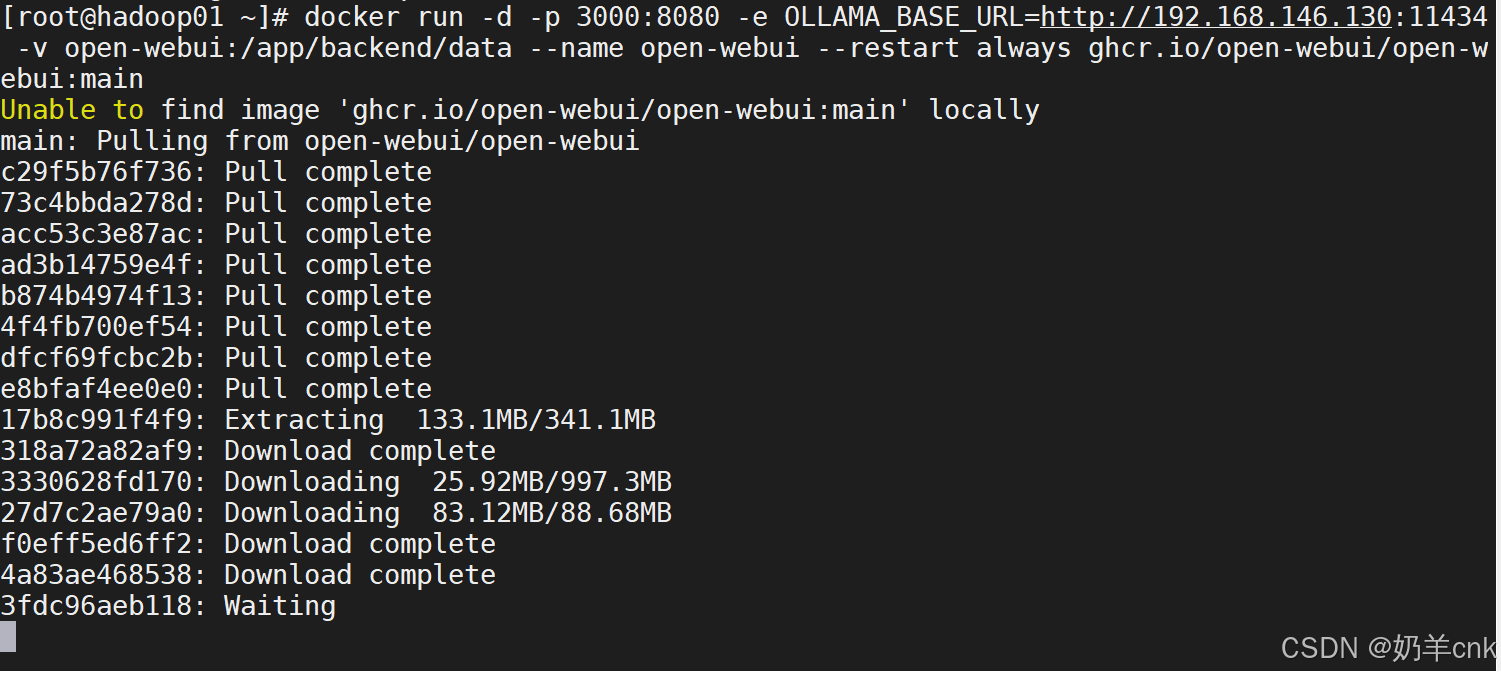
运行Open WebUI容器:使用Docker命令运行Open WebUI容器,并将其端口映射到主机的某个端口上。同时,设置必要的环境变量以指定Ollama服务的URL。启动Docker服务,输入:systemctl start docker
访问可视化界面:在浏览器中访问Open WebUI的URL(通常是http://localhost:[Open WebUI端口号]),即可使用可视化界面与DeepSeek模型进行交互。
输入: docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=http://192.168.47.136:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
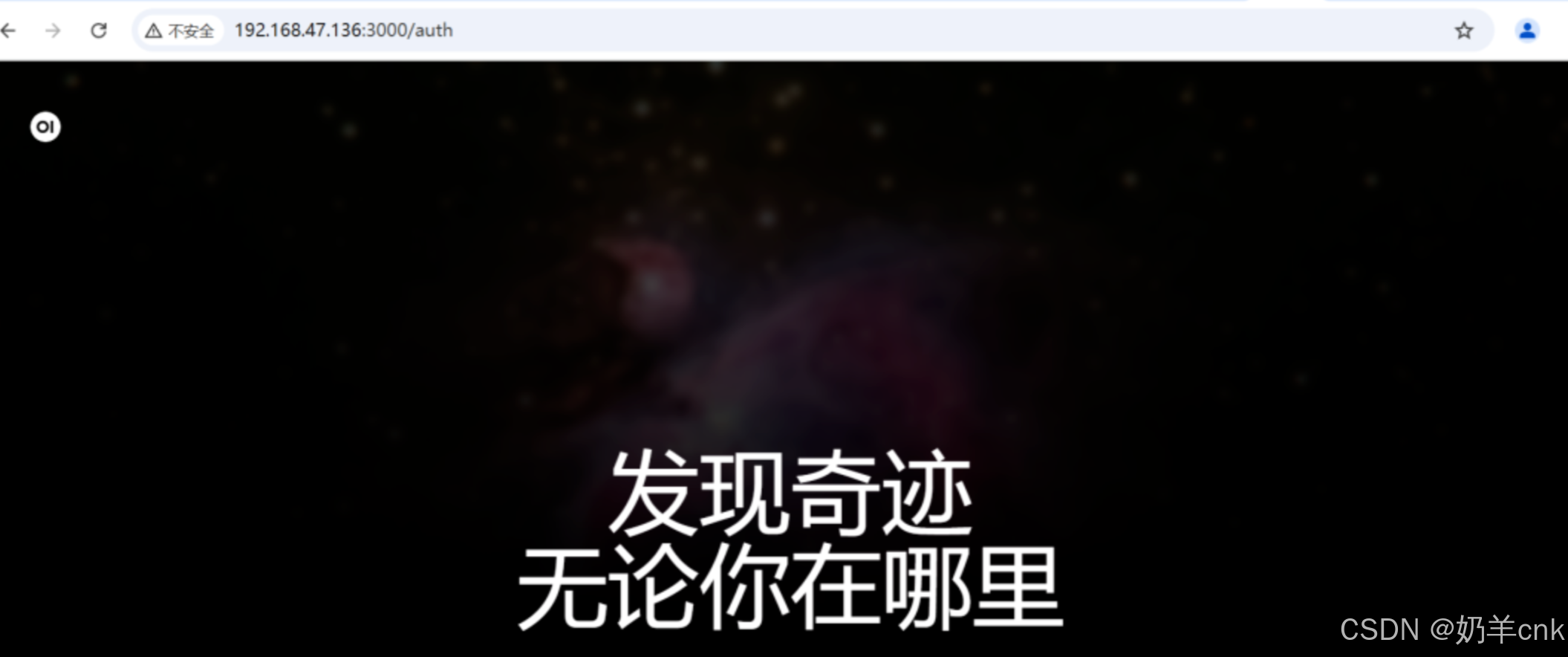
在浏览器访问网址:
http://192.168.47.136:3000
五、注意事项
- 防火墙和安全组设置:确保Linux服务器的防火墙和安全组规则允许访问Ollama和Open WebUI所使用的端口。
- 资源分配:根据服务器的硬件配置合理分配CPU、内存和GPU资源给Ollama和DeepSeek模型。确保系统有足够的资源来运行这些服务。
- 备份和恢复:定期备份DeepSeek模型和Ollama的配置文件。在出现问题时,可以使用备份进行恢复。
- 监控和日志记录:设置监控和日志记录机制,以便及时发现并解决潜在的问题。这有助于确保DeepSeek和Ollama的稳定运行。

















 3949
3949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









