






 本文介绍了如何使用逻辑回归算法对乳腺癌数据集进行建模,通过梯度下降法训练模型,以区分恶性(1)和良性(0)细胞。通过80%的数据作为训练集,20%作为测试集,最终目标是实现95%以上的预测准确率。
本文介绍了如何使用逻辑回归算法对乳腺癌数据集进行建模,通过梯度下降法训练模型,以区分恶性(1)和良性(0)细胞。通过80%的数据作为训练集,20%作为测试集,最终目标是实现95%以上的预测准确率。
目录
注释1:theta=np.zeros(x.shape[1])
任务描述
本关任务:使用逻辑回归算法建立一个模型,并通过梯度下降算法进行训练,得到一个能够准确对癌细胞进行识别的模型。
相关知识
为了完成本关任务,你需要掌握:
- 逻辑回归算法流程;
- 逻辑回归中的梯度下降。
数据集介绍
乳腺癌数据集,其实例数量是 569 ,实例中包括诊断类和属性,帮助预测的属性一共 30 个,各属性包括为 radius 半径(从中心到边缘上点的距离的平均值), texture 纹理(灰度值的标准偏差)等等,类包括: WDBC-Malignant 恶性和 WDBC-Benign 良性。用数据集的 80% 作为训练集,数据集的 20% 作为测试集,训练集和测试集中都包括特征和类别。其中特征和类别均为数值类型,类别中 0 代表良性, 1 代表恶性。
构建逻辑回归模型
由数据集可以知道,每一个样本有 30 个特征和 1 个标签,而我们要做的事就是通过这 30 个特征来分析细胞是良性还是恶性(其中标签 y=0 表示是良性, y=1 表示是恶性)。逻辑回归算法正好是一个二分类模型,我们可以构建一个逻辑回归模型,来对癌细胞进行识别。模型如下:

我们将一个样本输入模型,如果预测值大于等于 0.5 则判定为 1 类别,如果小于 0.5 则判定为 0 类别。
训练逻辑回归模型
我们已经知道如何构建一个逻辑回归模型,但是如何得到一个能正确对癌细胞进行识别的模型呢?通常,我们先将数据输入到模型,从而得到一个预测值,再将预测值与真实值结合,得到一个损失函数,最后用梯度下降的方法来优化损失函数,从而不断的更新模型的参数 θ ,最后得到一个能够正确对良性细胞和癌细胞进行分类的模型。
在上一节中,我们知道要使用梯度下降算法首先要知道损失函数对参数的梯度,即损失函数对每个参数的偏导,求解步骤如下:

训练流程:
同梯度下降算法流程:请参见上一关卡。


编程要求
根据提示,在右侧编辑器Begin-End处补充 Python 代码,构建一个逻辑回归模型,并对其进行训练,最后将得到的逻辑回归模型对癌细胞进行识别。
测试说明
只需返回预测结果即可,程序内部会检测您的代码,预测正确率高于 95% 视为过关。
提示:构建模型时 x0 是添加在数据的左边,请根据提示构建模型,且返回theta形状为(n,),n为特征个数。
答案
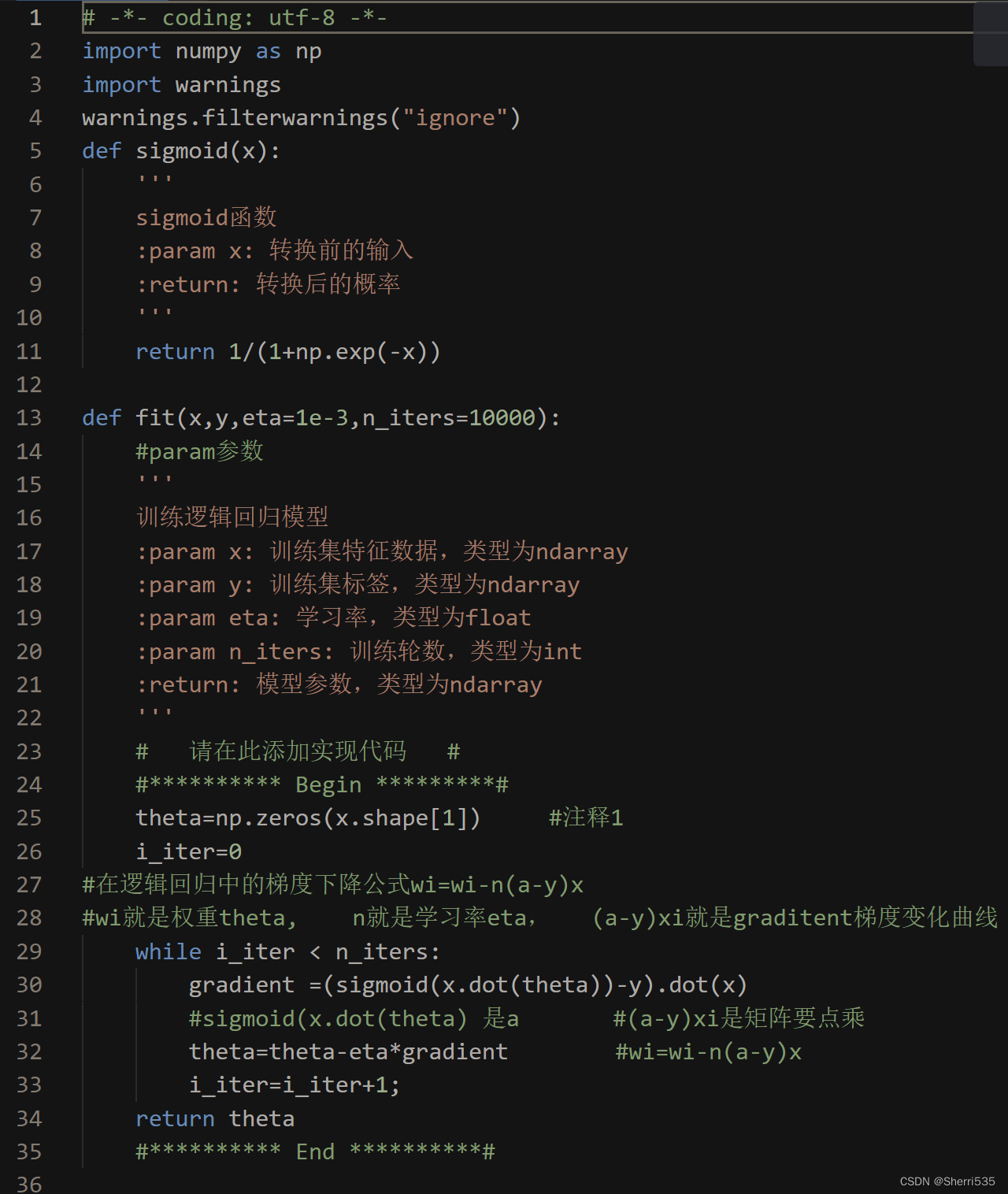
注释
注释1:theta=np.zeros(x.shape[1])
'np.zeros()'函数用于创建一个指定形状的新数组,并用0填充
`x.shape` 返回一个元组,表示`x`数组的维度。
`x.shape[0]`表示`x`数组的第一维度(通常是行数),
`x.shape[1]`表示第二维度(通常是列数)。
题目要求:且返回theta形状为(n,),n为特征个数。x是样本数*特征数的数组
因此,`np.zeros(x.shape[1])`将创建一个新的NumPy数组,其形状为`(x.shape[1],)`(即只有一个维度,长度为`x.shape[1]`),并用0填充。
这通常用于初始化一些与`x`特征数量相同的数组,例如用于存储权重、偏差或其他与特征数量相关的参数。
示例:
```python
import numpy as np# 假设 x 是一个形状为 (5, 3) 的数组
x = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
[10, 11, 12],
[13, 14, 15]])# 创建一个形状为 (3,) 的数组,并用0填充
zeros_array = np.zeros(x.shape[1])print(zeros_array) # 输出: [0. 0. 0.]
```
在上面的示例中,`x`是一个5x3的数组,所以`x.shape[1]`是3。因此,`np.zeros(x.shape[1])`创建了一个形状为(3,)的数组,并用0填充。
注释2 sigmoid(x.dot(theta))
a就是图中的p
x.dot(theta)是图中的z

















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









