






目录
第1关:支持向量机算法详解
相关知识
为了完成本关任务,你需要掌握:1.支持向量机的定义。2.支持向量机算法详解。
支持向量机的定义
“支持向量机”(SVM)是一种有监督的机器学习算法,可用于分类任务或回归任务。在该算法中,我们将每个数据绘制为n维空间中的一个点(其中n是特征的数量),每个特征的值是特定坐标的值。然后,我们通过找到很好地区分这两个类的一个超平面来执行分类的任务。
简单来说,我们将其理解为现在有很多点,一部分的标签是+1,一部分的标签是-1,而且这些点一定能被一条直线划分成两部分,我们的任务是“画一条线”把不同标签的数据分开。如下图所示:
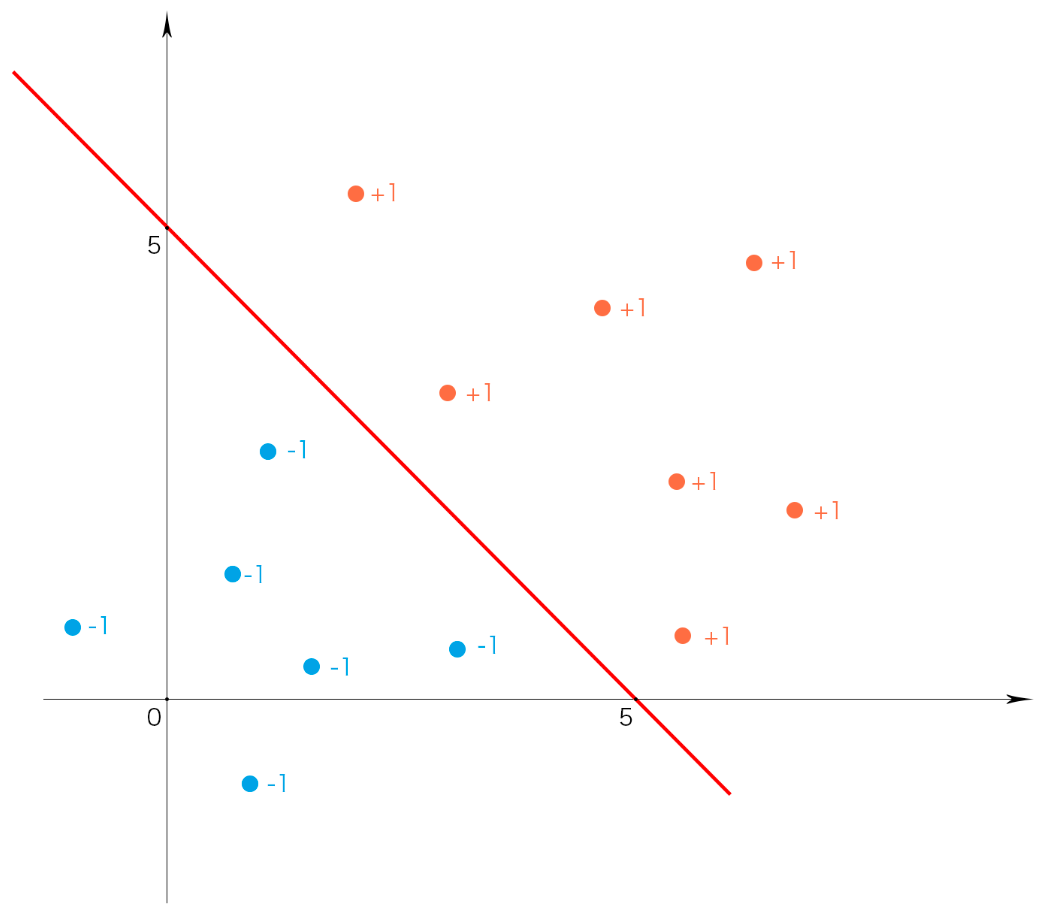
中间这条线我们叫做"超平面"。当处理二维平面数据时,超平面为一条直线。当处理三维空间数据时,超平面就是一个平面。
当然,我们可以画出许多这样的超平面,如:
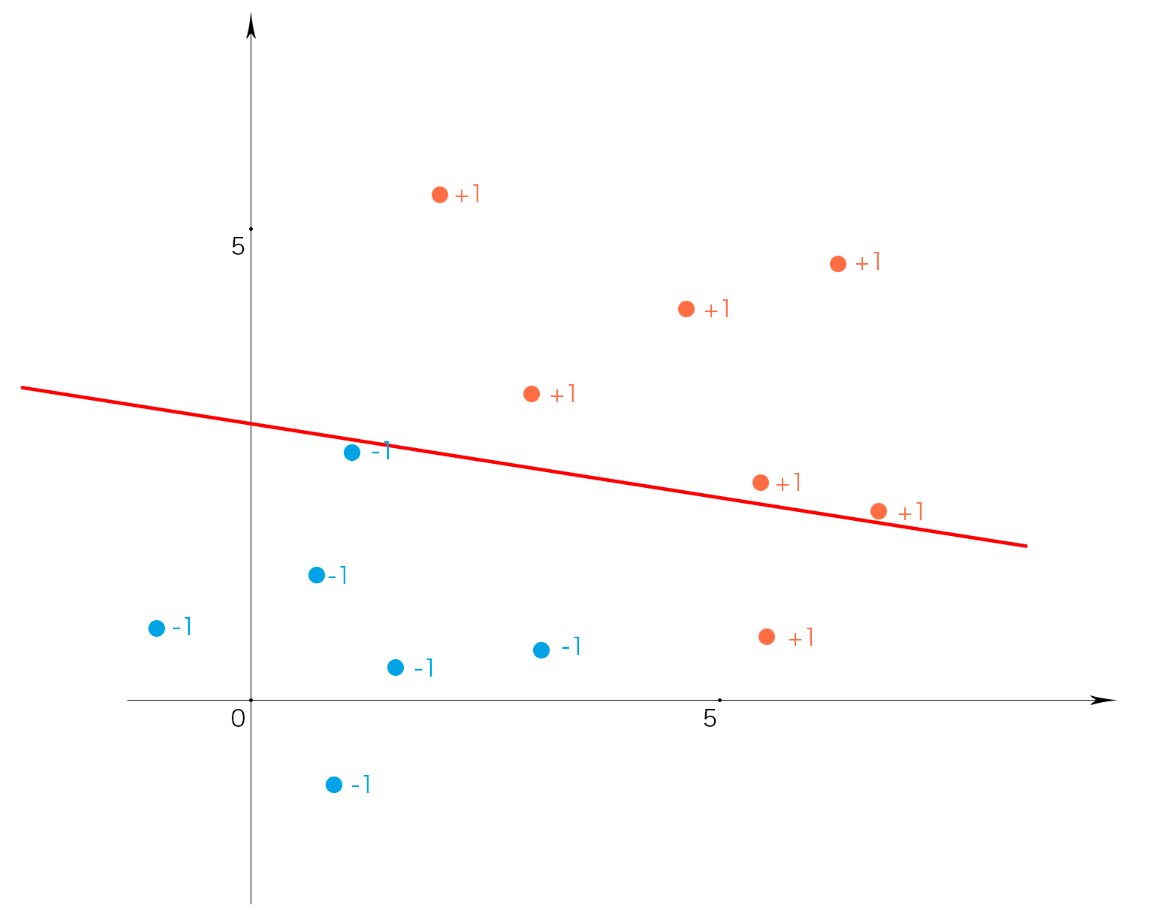
那么哪一个“超平面”更好呢?我们通过观察可以看出第一个最好,因为它的“最大间隔”是最大的。
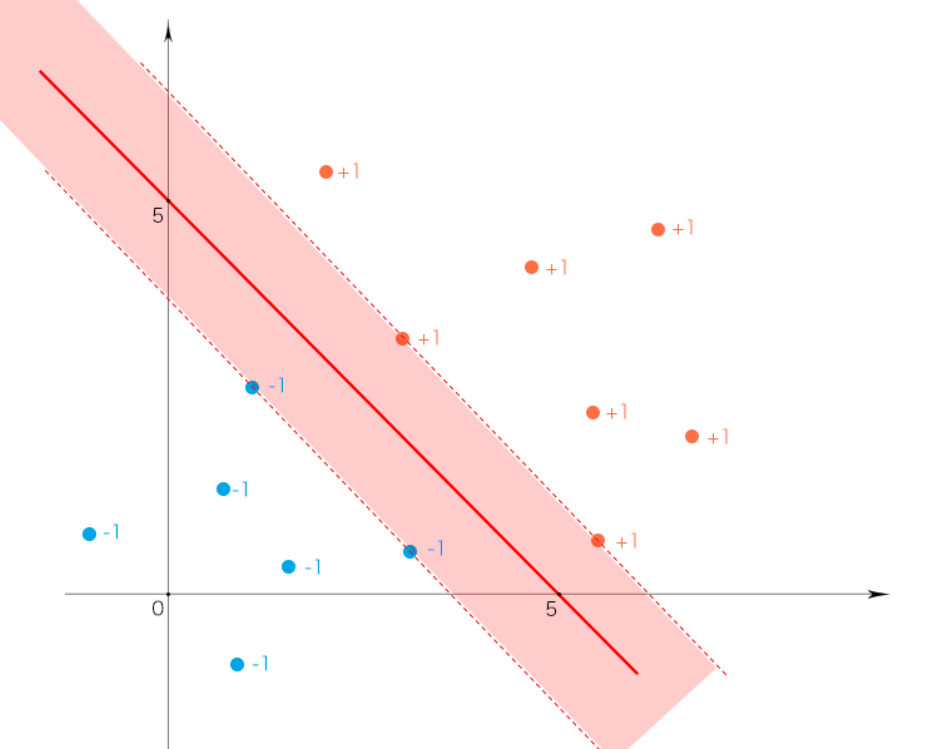
那我们该如何找出这个超平面呢?这就是支持向量机该要做的事情。
支持向量机算法详解
我们定义间隔r为整个数据集D中所有样本到分割超平面的最短距离,如果间隔r越大,则分割超平面对两个数据集的划分越稳定,不容易受到噪声等因素影响,支持向量机的目标就是要寻找一个超平面(w,b)使得r最大。 我们将上述思想用数学公式表达为:
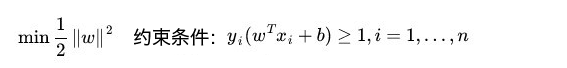
接下来就变成了一个不等式约束条件下的凸二次规划问题求解。
KKT条件
对于不等式约束的优化问题,我们一般通过KKT条件将其转换为等式约束的优化问题,再利用拉格朗日乘子法求解最优解。 对于含有不等式约束的优化问题,将其转化为对偶问题:
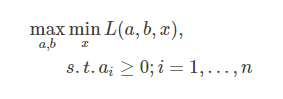
其中 L(a,b,x) 为由所有的不等式约束、等式约束和目标函数全部写成的一个式子 L(a,b,x)=f(x)+a⋅g(x)+b⋅h(x)L(a,b,x)=f(x)+a⋅g(x)+b⋅h(x) KKT条件是说原始问题最优值 x∗x∗ 和对偶问题最优值 a∗,b∗a∗,b∗ 必须满足以下条件:
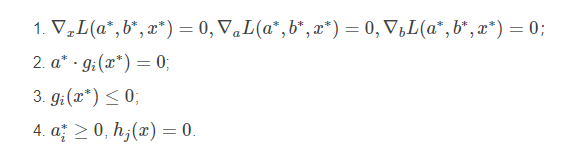
当原始问题的解和对偶问题的解满足KKT条件,并且 f(x),g(x)是凸函数时,原始问题的解与对偶问题的解相等。
求取这几个等式之后就能得到候选最优值。
核函数
支持向量机还有一个重要的优点,可以使用核函数(Kernel Function)隐式地将样本从原始特征空间映射到更高维的空间,并解决原始特征空间中的线性不可分问题。
常用的核函数有:
1.多项式核函数 :通过多项式来作为特征映射函数 。
k(x,z)=(x⋅z+1)p,p∈Z+
优点:可以拟合出复杂的分隔超平面 缺点:参数太多。有 γ , c , n 三个参数要选择,选择起来比较困难;另外多项式的阶数不宜太高否则会给模型求解带来困难。
2.高斯(BRF)核函数 :
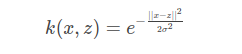
优点:可以把特征映射到无限多维,并且没有多项式计算那么困难,参数也比较好选择。 缺点:不容易解释,计算速度比较慢,容易过拟合。
3.线性核函数 :这是最简单的核函数,它直接计算两个输入特征向量的内积。
k(x,z)=<x,z>
优点:简单高效,结果易解释,总能生成一个最简洁的线性分割超平面。 缺点:只适用线性可分的数据集。
在实际计算中,通常会选用高斯核函数。
测试说明
请完成接下来的选择题。


















 4169
4169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









