






Ollama
Ollama 是一个基于 Go 语言开发的简单易用的本地大语言模型运行框架。专为在本地运行大型语言模型而设计。该框架将模型权重、配置和数据整合到一个包中,优化了设置和配置细节,包括 GPU 使用情况,从而简化了在本地运行大型模型的过程。
前排提示,文末有大模型AGI-优快云独家资料包哦!
可以将其类比为 docker(具有实现命令行交互中的 list,pull,push,run 等命令),事实上它也的确制定了类 docker 的一种模型应用标准。
官方提供了类似 GitHub,DockerHub 一般的,可类比理解为 ModelHub,用于存放大语言模型的仓库(有 llama 2,mistral,qwen 等模型,同时你也可以自定义模型上传到仓库里来给别人使用)。
在管理模型的同时,它还基于 Go 语言中的 Gin 框架提供了一些 Api 接口,让你能够像跟 OpenAI 提供的接口那样进行交互。
Ollama 安装
下载链接:https://ollama.com/download
- macOS:https://ollama.com/download/Ollama-darwin.zip
- Windows:https://ollama.com/download/OllamaSetup.exe
- Linux:
curl -fsSL https://ollama.com/install.sh | sh - Docker:https://hub.docker.com/r/ollama/ollama
模型管理
ollama 安装之后,与模型交互就是通过命令来进行的。
ollama list:显示模型列表ollama show:显示模型的信息ollama pull:拉取模型ollama push:推送模型ollama cp:拷贝一个模型ollama rm:删除一个模型ollama run:运行一个模型
运行大模型
ollama 安装之后,可以在本地一键启动大模型(模型仓库见: https://ollama.com/library):
ollama run qwen:1.8b //这里使用千问1.8b https://ollama.com/library/qwen
启动之后可以直接在终端交互:

也可以使用 API 调用:
curl http://localhost:11434/api/generate -d '{
"model": "qwen:1.8b",
"prompt": "你好",
"stream": false
}'
MaxKB
2024 年 4 月 12 日,1Panel 开源项目组正式对外介绍了其官方出品的开源子项目 ——MaxKB(github.com/1Panel-dev/MaxKB)。MaxKB 是一款基于 LLM(Large Language Model)大语言模型的知识库问答系统。MaxKB 的产品命名内涵为 “Max Knowledge Base”,为用户提供强大的学习能力和问答响应速度,致力于成为企业的最强大脑。
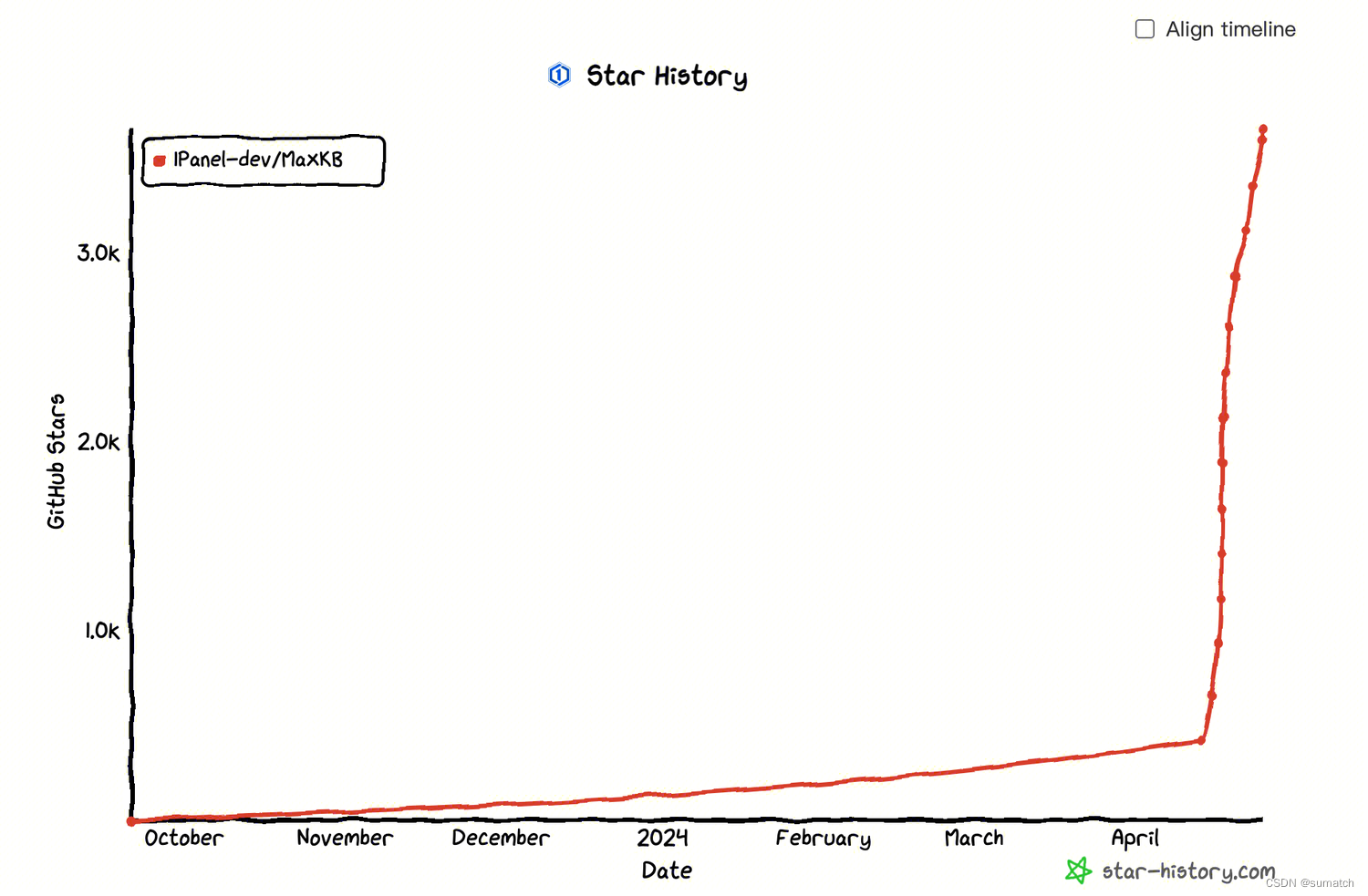
2024 年 4 月 16 日,MaxKB 成功登顶 GitHub Trending 主榜单,自项目发布后快速收获超过 1.8k Stars 和超过 5,000 次下载。
2024 年 4 月 25 日 已有 3.5k Stars 。
MaxKB 的优点:
- 多模型支持:支持对接主流的大模型,包括本地私有大模型(如 Llama 2)、OpenAI、通义千问、Kimi、Azure OpenAI 和百度千帆大模型等;
- 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化,智能问答交互体验好;
- 无缝嵌入:支持零编码快速嵌入到第三方业务系统。
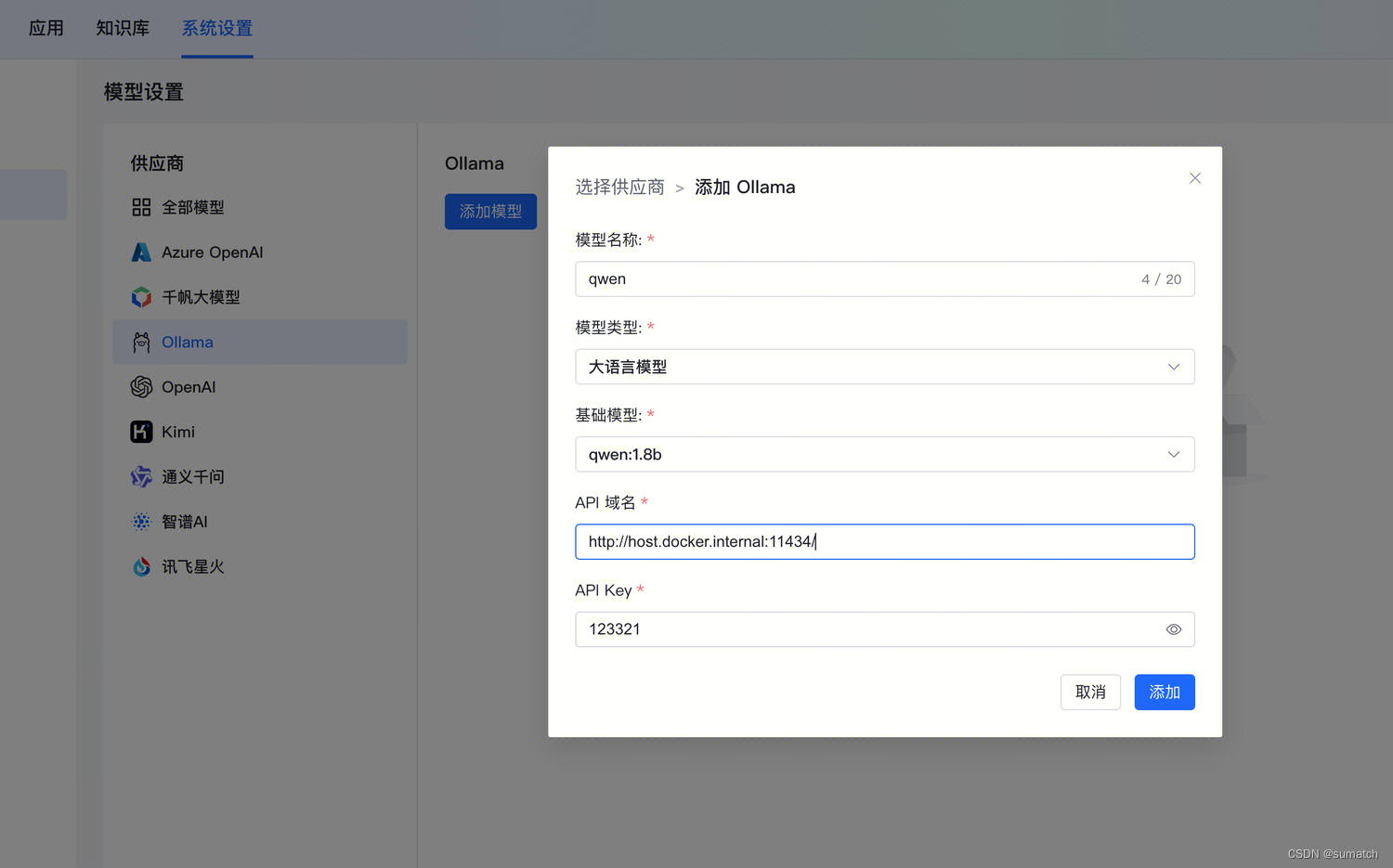
除了基于 OpenAI、百度千帆大模型等在线大模型快速搭建知识库问答系统外,MaxKB 还支持与以 Ollama 为代表的本地私有大模型相结合,快速部署本地的知识库问答系统。
下面介绍 快速部署 MaxKB 和 Ollama,并在 MaxKB 中接入 Ollama 的 LLM 模型,搭建基于大语言模型的本地知识库问答系统。
MaxKB 安装部署
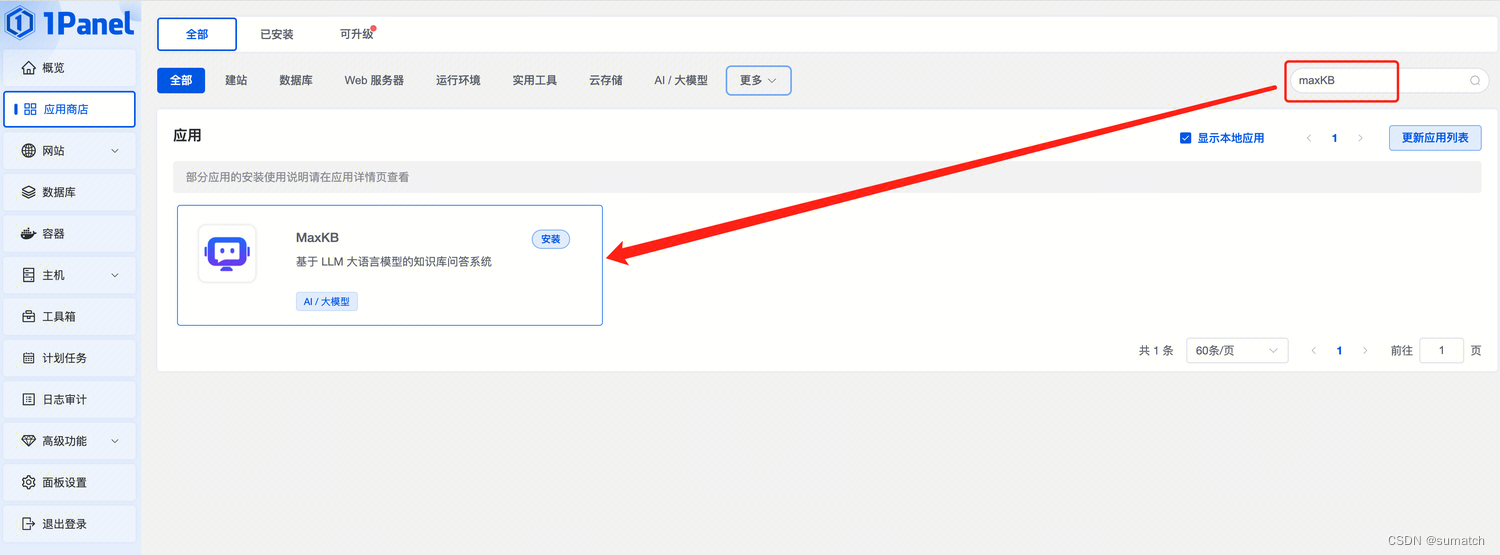
部署方式一:通过 1Panel 应用商店,快速安装 MaxKB 应用。
部署方式二:Docker 安装。(Docker 部署不再赘述。)
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data 1panel/maxkb
# 用户名: admin
# 密码: MaxKB@123..
选择使用 Docker 部署方式。注意设置挂载目录。
部署之后,界面如下:
使用教程:MaxKB 文档
MaxKB 支持嵌入到第三方系统中
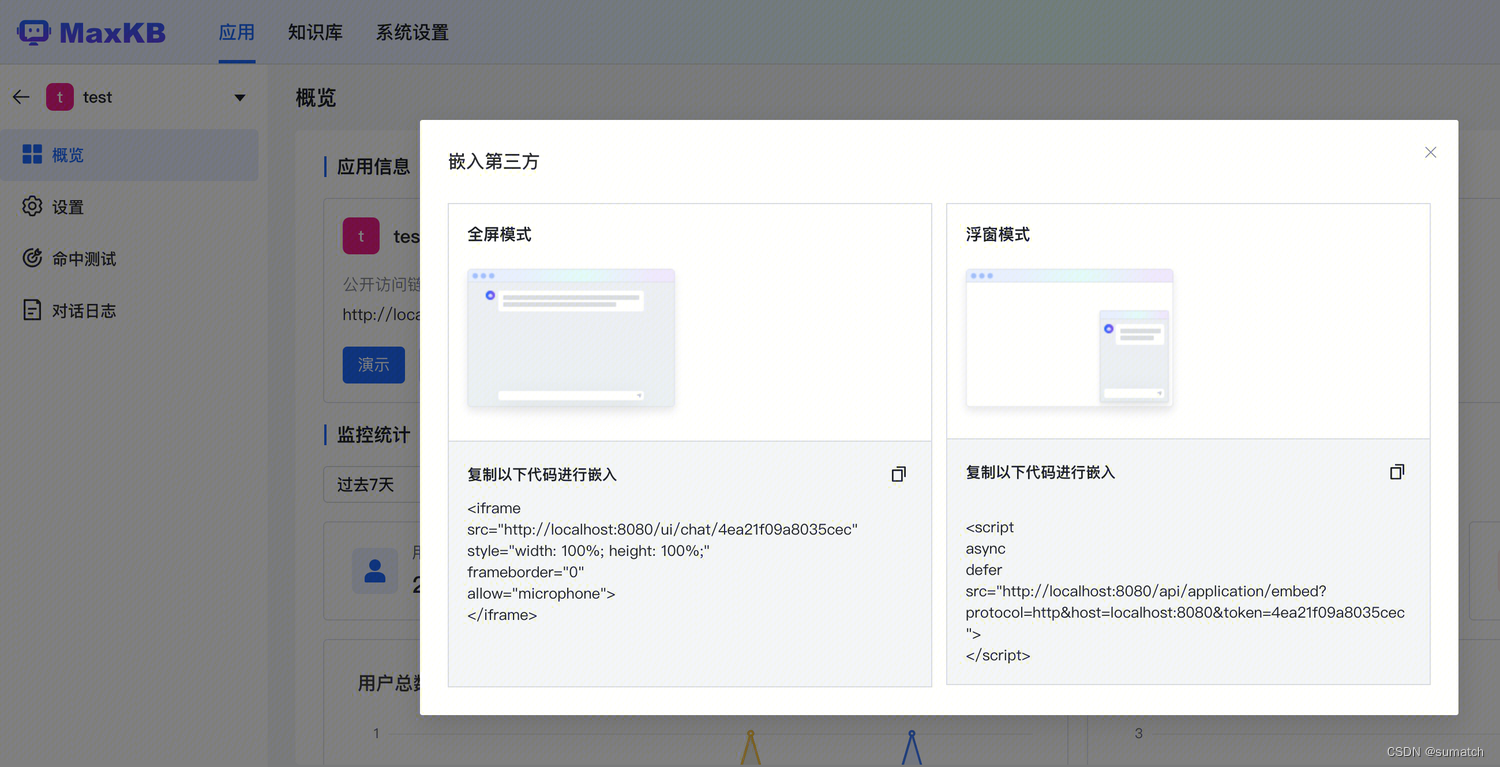
MaxKB + Ollama
http://host.docker.internal:11434/
AnythingLLM
AnythingLLM 是 Mintplex Labs Inc. 开发的一款开源 ChatGPT 等效工具,用于在安全的环境中与文档等进行聊天,专为想要使用现有文档进行智能聊天或构建知识库的任何人而构建。
AnythingLLM 能够把各种文档、资料或者内容转换成一种格式,让LLM(如ChatGPT)在聊天时可以引用这些内容。然后你就可以用它来和各种文档、内容、资料聊天,支持多个用户同时使用,还可以设置谁能看或改哪些内容。 支持多种LLM、嵌入器和向量数据库。
AnythingLLM 特点
- 多用户支持和权限管理:允许多个用户同时使用,并可设置不同的权限。
- 支持多种文档类型:包括 PDF、TXT、DOCX 等。
- 简易的文档管理界面:通过用户界面管理向量数据库中的文档。
- 两种聊天模式:对话模式保留之前的问题和回答,查询模式则是简单的针对文档的问答
- 聊天中的引用标注:链接到原始文档源和文本。
- 简单的技术栈,便于快速迭代。
- 100% 云部署就绪。
- “自带LLM”模式:可以选择使用商业或开源的 LLM。
- 高效的成本节约措施:对于大型文档,只需嵌入一次,比其他文档聊天机器人解决方案节省 90% 的成本。
- 完整的开发者 API:支持自定义集成。
支持的 LLM、嵌入模型和向量数据库
- LLM:包括任何开源的 llama.cpp 兼容模型、OpenAI、Azure OpenAI、Anthropic ClaudeV2、LM Studio 和 LocalAi。
- 嵌入模型:AnythingLLM 原生嵌入器、OpenAI、Azure OpenAI、LM Studio 和 LocalAi。
- 向量数据库:LanceDB(默认)、Pinecone、Chroma、Weaviate 和 QDrant。
安装
桌面安装: https://useanything.com/download
Docker安装: https://github.com/Mintplex-Labs/anything-llm/blob/master/docker/HOW_TO_USE_DOCKER.md
Docker :
docker pull mintplexlabs/anythingllm
export STORAGE_LOCATION=$HOME/anythingllm && \
mkdir -p $STORAGE_LOCATION && \
touch "$STORAGE_LOCATION/.env" && \
docker run -d -p 3001:3001 \
--cap-add SYS_ADMIN \
-v ${STORAGE_LOCATION}:/app/server/storage \
-v ${STORAGE_LOCATION}/.env:/app/server/.env \
-e STORAGE_DIR="/app/server/storage" \
mintplexlabs/anythingllm
安装好之后,访问 http://localhost:3001 :

创建命名空间,比如 “Test”
配置大模型
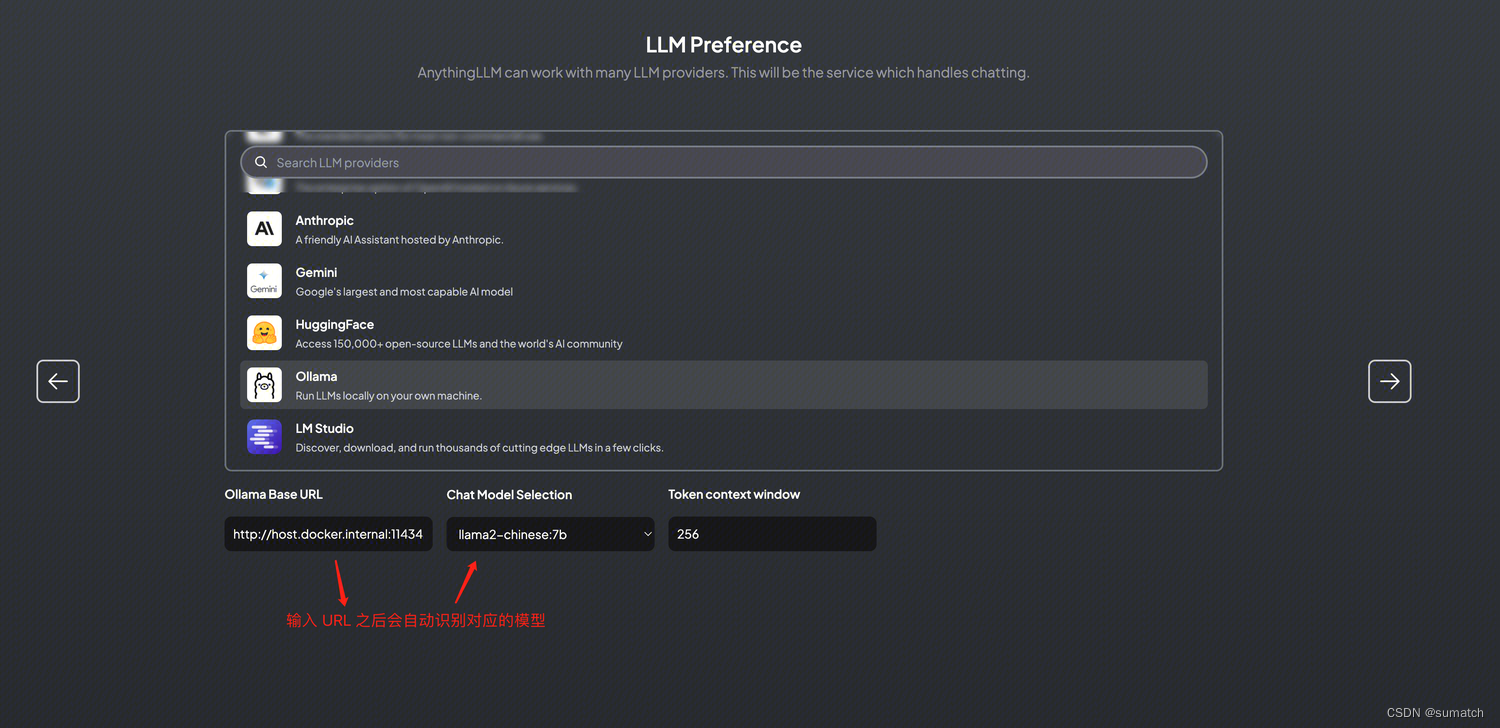
“Token context window” 是指在大模型中处理文本时,模型在每个标记(token)周围考虑的上下文范围。
AnythingLLM 中默认是 4096
配置文本向量模型
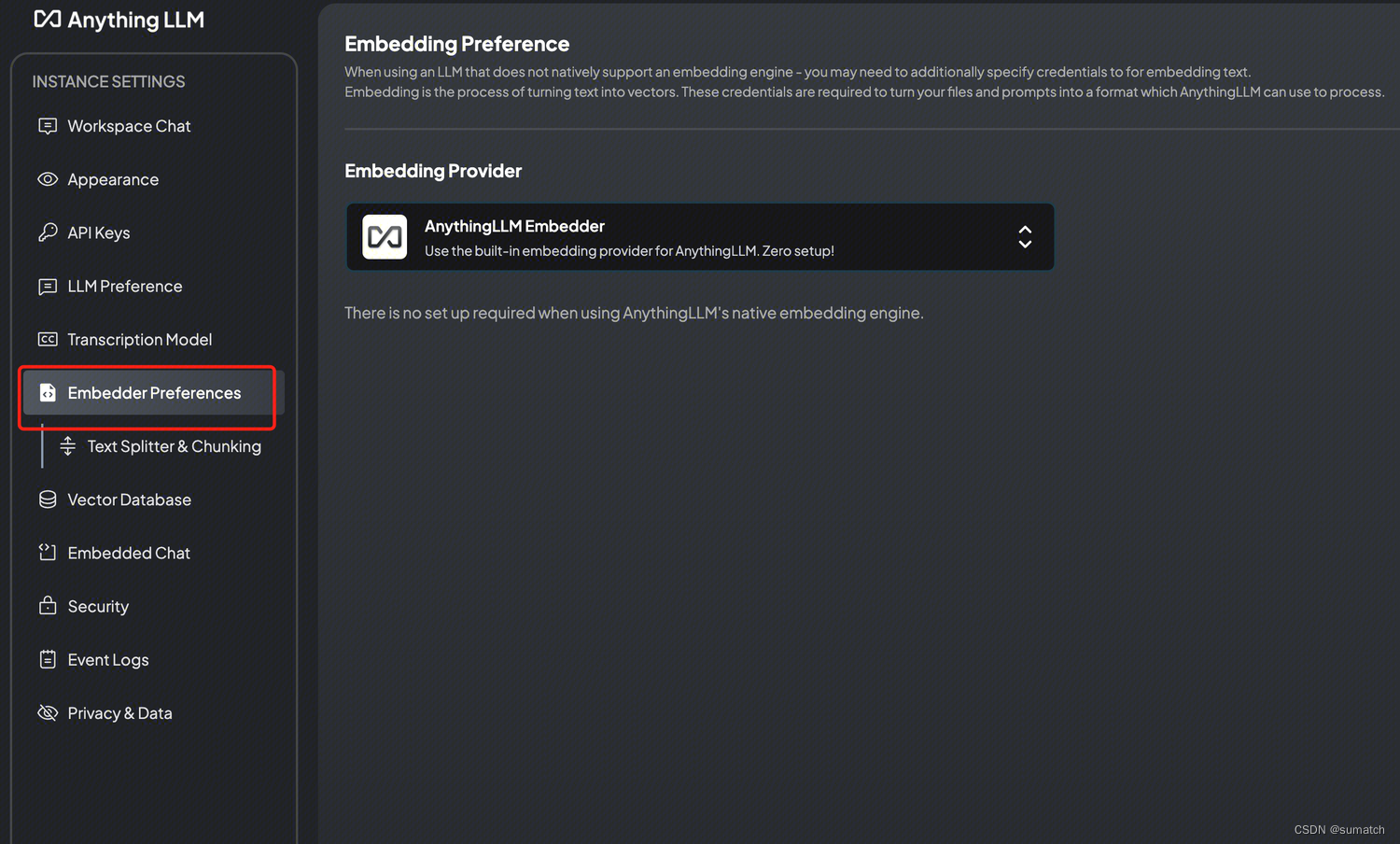
安装文本向量模型:https://ollama.com/library/nomic-embed-text
选择 nomic-embed-text
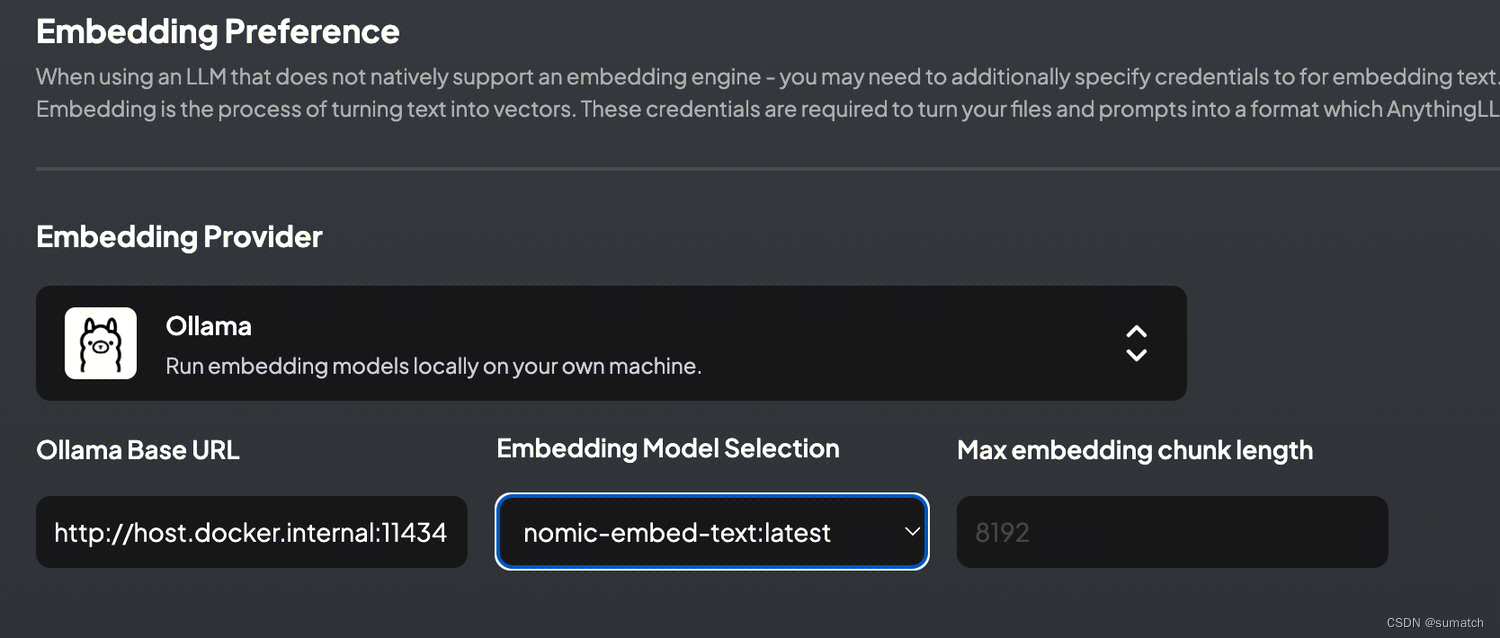
“Max embedding chunk length” 在大模型领域通常表示嵌入块的最大长度。嵌入块是指将输入文本分割成较小的片段或块,以便在大型模型中进行处理。
由于大型模型的计算和内存资源限制,处理长文本序列可能会面临挑战。为了克服这个问题,可以将长文本序列分割成较短的嵌入块,然后分别对每个块进行处理。
“Max embedding chunk length” 是指在分割文本序列时所使用的最大块长度。如果文本序列的长度超过了最大块长度,它将被分割成多个块,每个块的长度不超过最大块长度。
通过限制嵌入块的最大长度,可以确保模型能够处理较长的文本序列,并且可以在每个块上进行并行计算,以提高效率和减少内存需求。然而,较小的最大块长度可能会导致信息丢失或上下文不完整,因此需要在模型设计中进行权衡和选择。
AnythingLLM 中默认是 8192
配置向量数据库
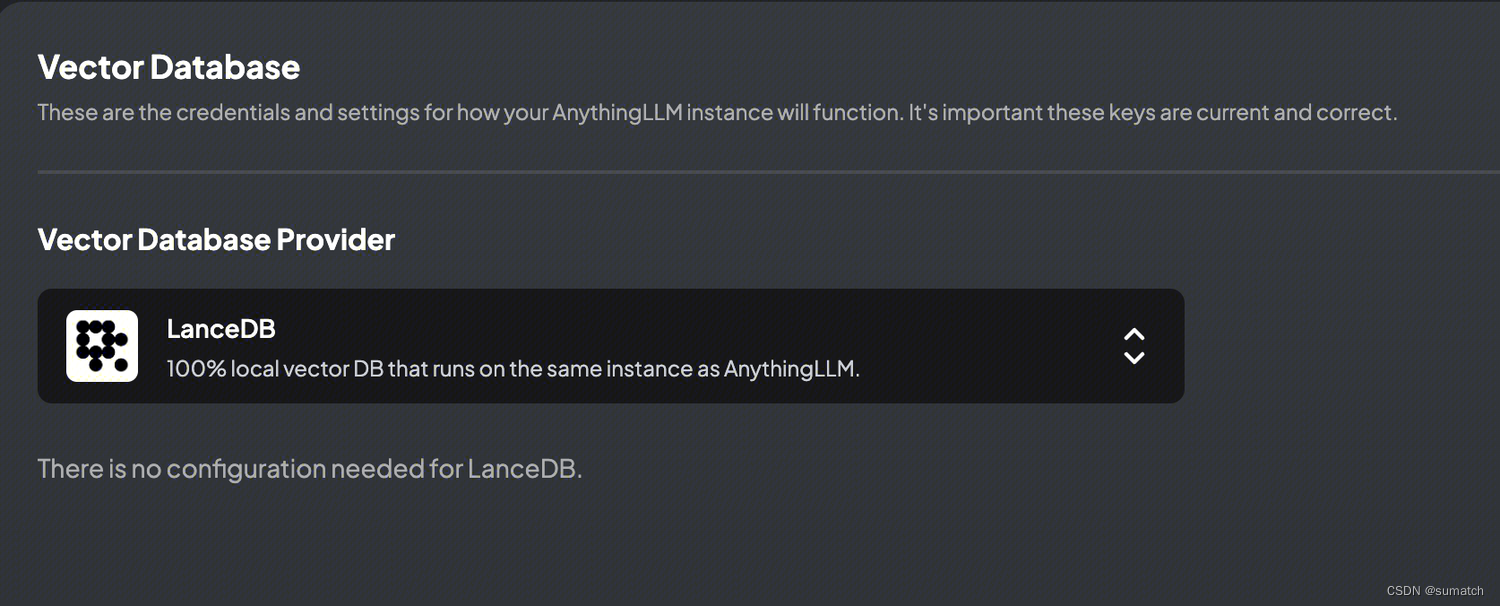
这里选择默认的 LanceDB。
LanceDB 是一款针对AI应用的新型开发者友好型无服务器向量数据库。
- 它可嵌入应用程序中,无需管理服务器,其扩展性依赖于磁盘而非内存,具有低延迟性
- LanceDB 支持向量搜索、全文搜索和SQL,并针对多模态数据进行了优化
- LanceDB 2.0,已在 Github 上开源 https://github.com/lancedb/lancedb
上传本地知识库
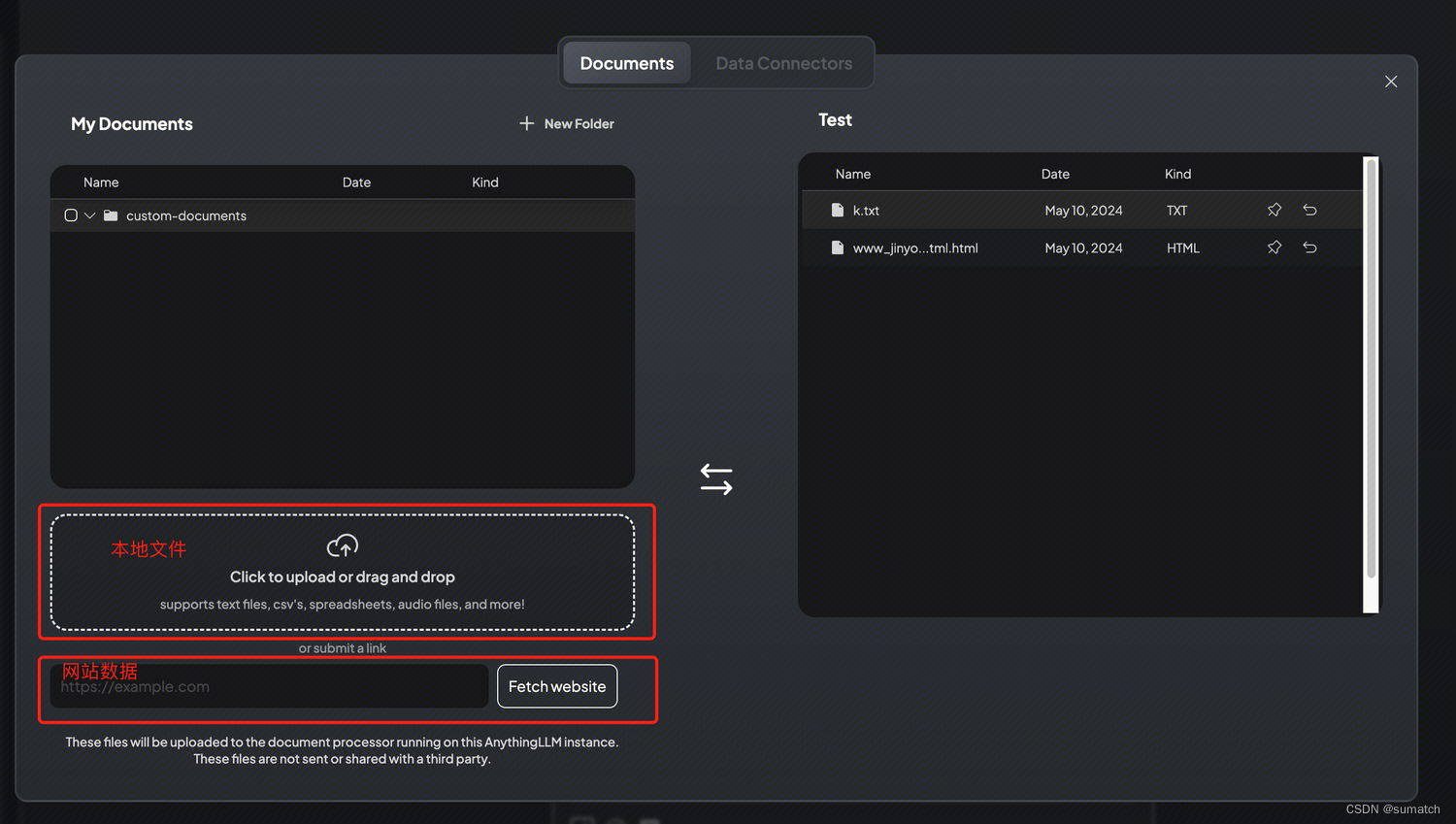
配置聊天模式
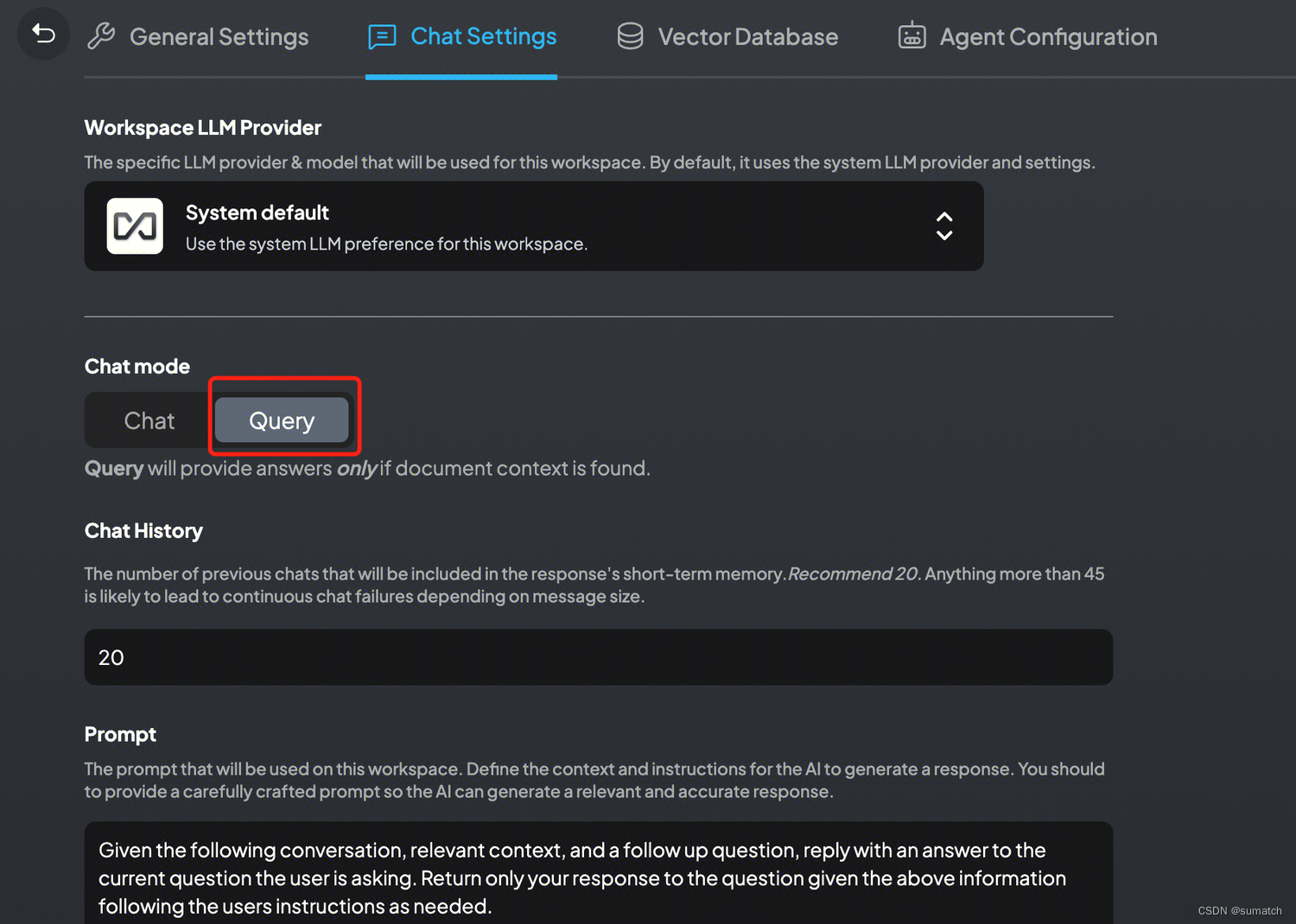
-
Chat 模式:模型将根据常识和本地知识库作答
-
Query 模型:模型仅根据本地知识库作答
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











