






一.DIN
1.结构模型
Embedding layer
这个层的作用是把高维稀疏的输入转成低维稠密向量, 每个离散特征下面都会对应着一个embedding词典, 维度是D×KD×K, 这里的DD表示的是隐向量的维度, 而KK表示的是当前离散特征的唯一取值个数, 这里为了好理解,这里举个例子说明,就比如上面的weekday特征:
pooling layer and Concat layer
pooling层的作用是将用户的历史行为embedding这个最终变成一个定长的向量,因为每个用户历史购买的商品数是不一样的, 也就是每个用户multi-hot中1的个数不一致,这样经过embedding层,得到的用户历史行为embedding的个数不一样多,也就是上面的embedding列表不一样长, 那么这样的话,每个用户的历史行为特征拼起来就不一样长了。 而后面如果加全连接网络的话,我们知道,他需要定长的特征输入。 所以往往用一个pooling layer先把用户历史行为embedding变成固定长度(统一长度),所以有了这个公式:
这里的是用户历史行为的那些embedding。
就变成了定长的向量, 这里的i表示第i个历史特征组(是历史行为,比如历史的商品id,历史的商品类别id等), 这里的k表示对应历史特种组里面用户购买过的商品数量,也就是历史embedding的数量,看上面图里面的user behaviors系列,就是那个过程了。 Concat layer层的作用就是拼接了,就是把这所有的特征embedding向量,如果再有连续特征的话也算上,从特征维度拼接整合,作为MLP的输入。
MLP
这个就是普通的全连接,用了学习特征之间的各种交互。
Loss
由于这里是点击率预测任务, 二分类的问题,所以这里的损失函数用的负的log对数似然:
2.相关代码演示
导入相关包

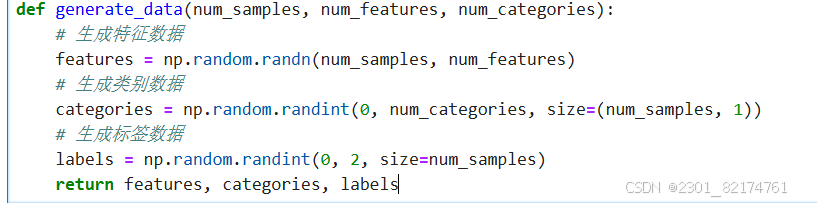
模拟数据生成
构建DIN模型
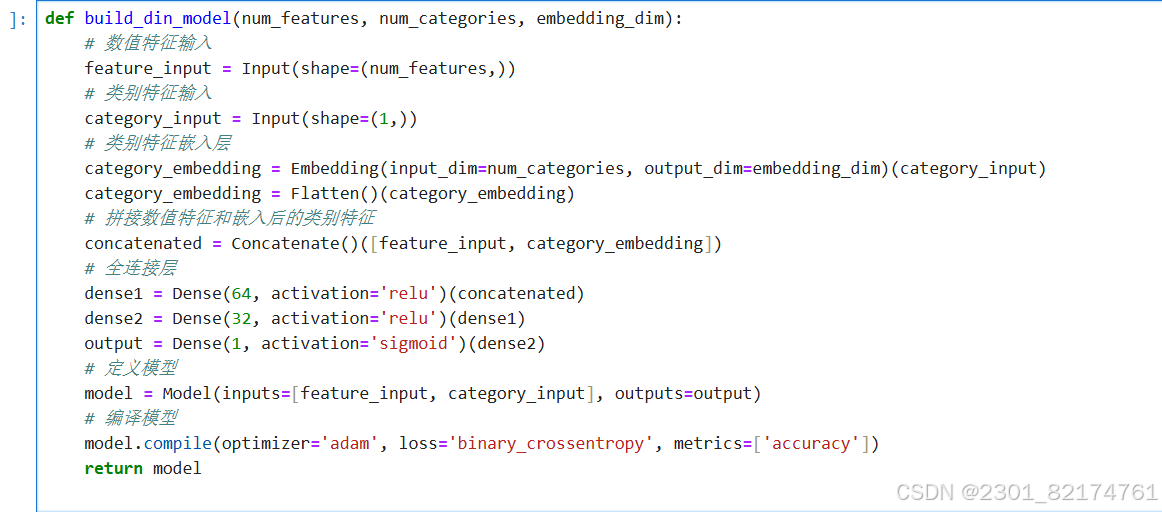
代码中的模型结构相对简单,仅包含了基本的特征嵌入和全连接层,没有体现出 DIN 模型针对大规模稀疏数据和复杂用户行为的优化。
二.MMOE
1.MMOE模型的理论
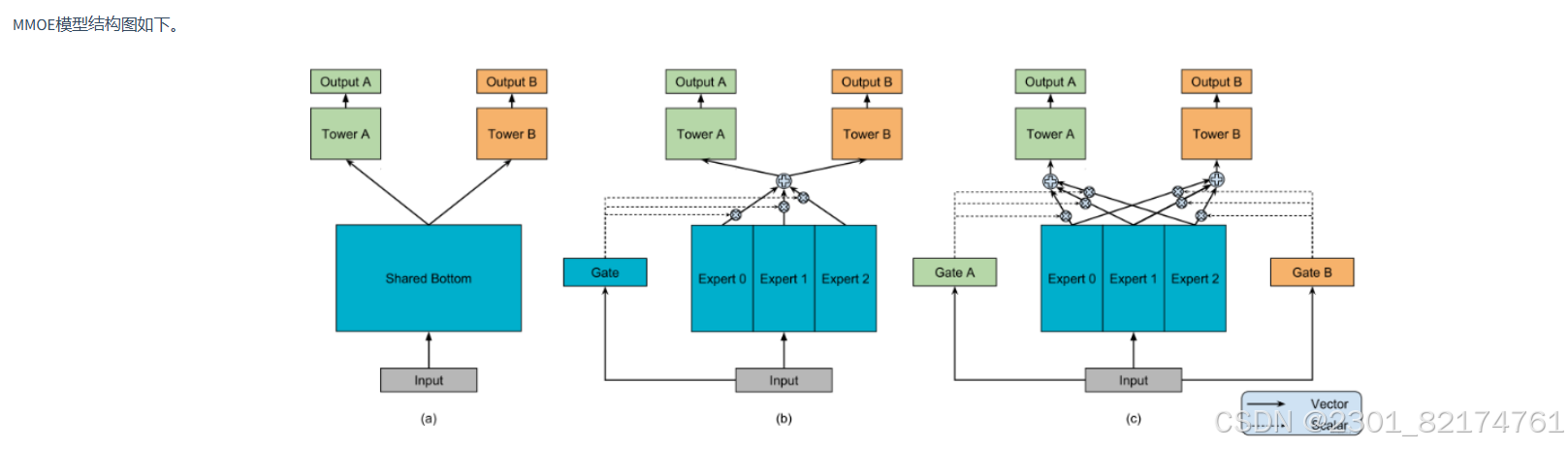
2.MMOE结构
Multi-gate Mixture-of-Experts(MMOE)的魅力就在于在OMOE的基础上,对于每个任务都会涉及一个门控网络,这样,对于每个特定的任务,都能有一组对应的专家组合去进行预测。更关键的时候,参数量还不会增加太多。公式如下:
where. 这里的kk表示任务的个数。 每个门控网络是一个注意力网络:
表示权重矩阵, n是专家的个数, d是特征的维度。
3.简单代码演示
导入相关库
生成模拟数据

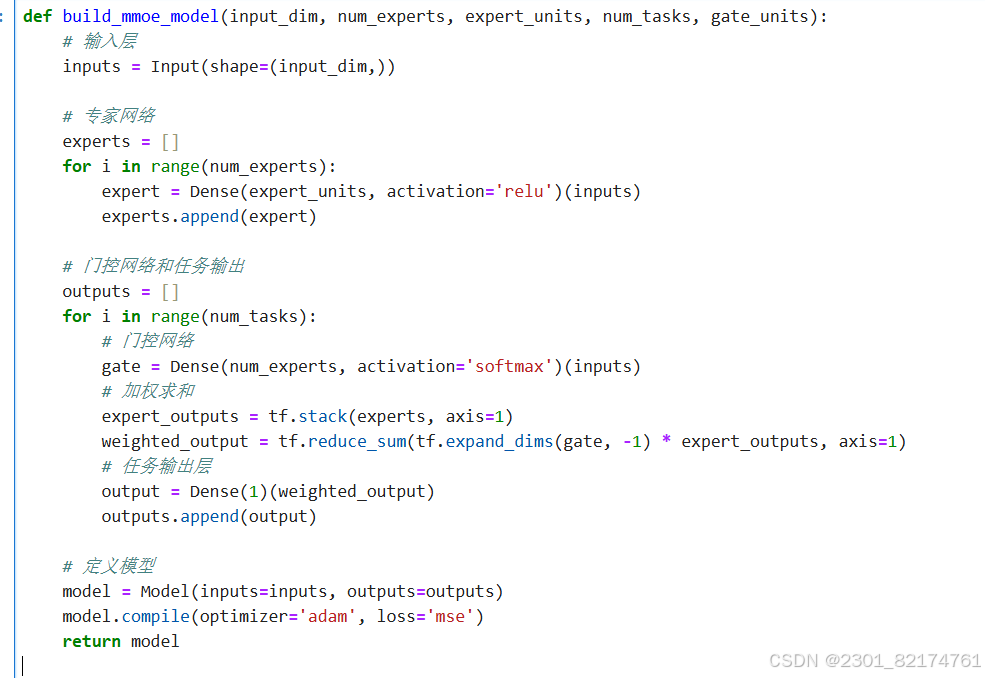
定义MMOE模型
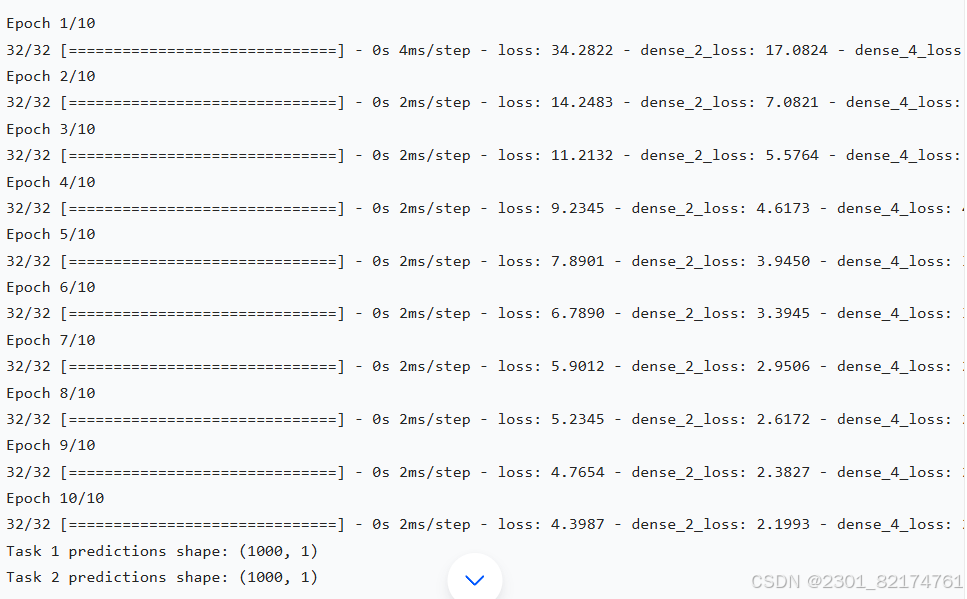
结果
参数调优困难
MMOE 模型有多个超参数需要调整,如专家网络的数量、每个专家网络的神经元数量、门控网络的结构等。这些超参数的不同组合会对模型的性能产生很大影响,需要进行大量的实验和调优才能找到最优的参数设置。例如,不同的数据集和任务可能需要不同的专家网络数量和结构,很难有一个通用的参数配置。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









