






一.Wide & Deep
1.Wide
简介
即广义线性模型,主要负责记忆,能够学习到数据中的简单、直接的关联规则,捕捉特征之间的一阶关系。比如在推荐系统中,能直接根据用户过去的点击、购买等行为,快速找到与当前用户行为最相似的历史数据,从而进行精准推荐。
理解Wide增强记忆能力
wide部分是一个广义的线性模型,输入的特征主要有两部分组成,一部分是原始的部分特征,另一部分是原始特征的交叉特征(cross-product transformation),对于交互特征可以定义为:
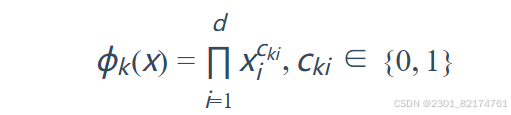
是一个布尔变量,当第i个特征属于第k个特征组合时,
的值为1,否则为0,
是第i个特征的值,大体意思就是两个特征都同时为1这个新的特征才能为1,否则就是0,说白了就是一个特征组合。
简单代码演示
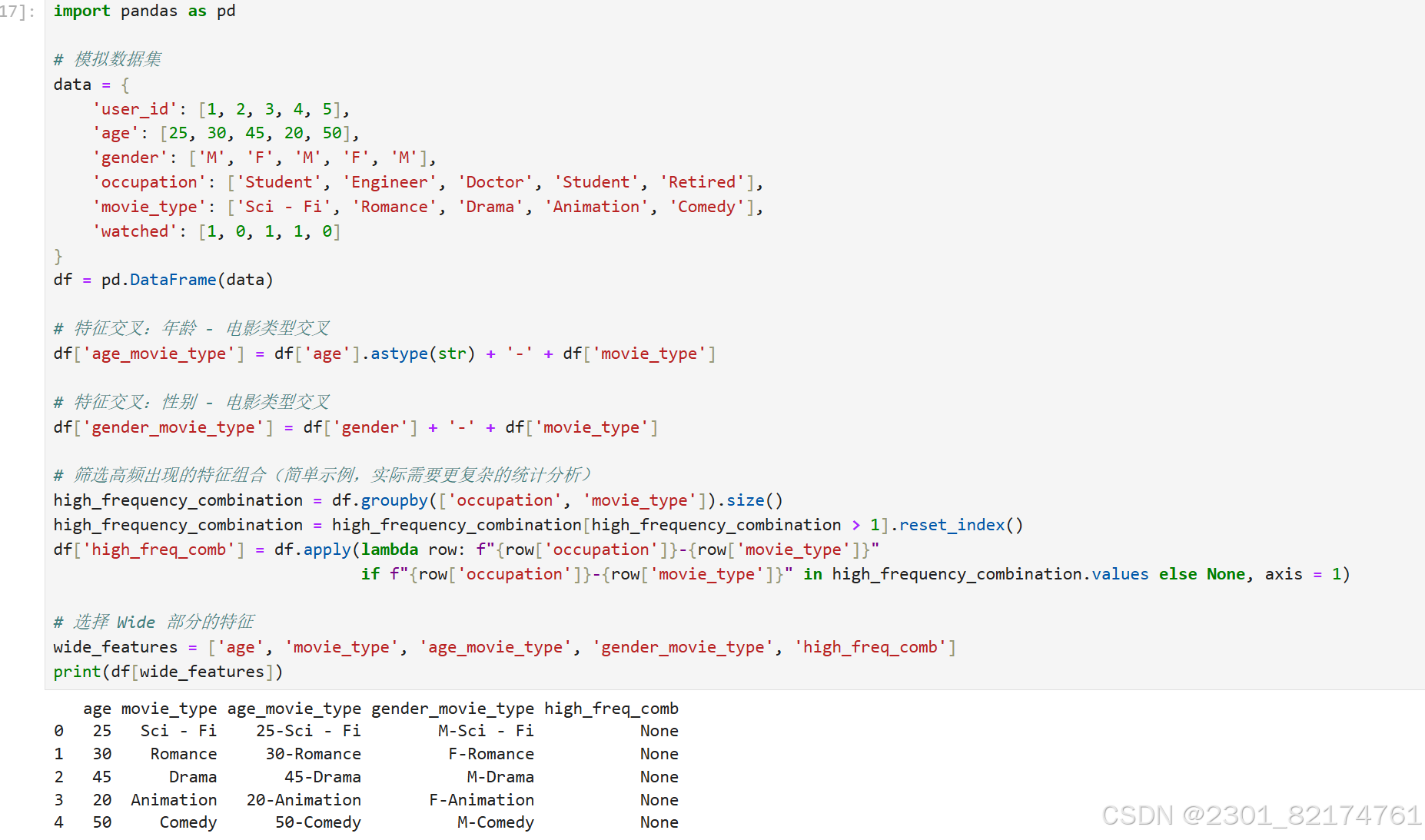
high_freq_comb 列:在这段数据中均为None,根据前面的代码逻辑,它应该是用于标记职业和电影类型的组合是否为高频组合。如果在数据集中某个职业和电影类型的组合出现次数大于 1,才会在该列显示对应的 “职业 - 电影类型” 组合,否则为None。这里全为None可能表示在这个数据片段中,这些记录的职业和电影类型组合都不是高频组合,即出现次数不大于 1。
2.Deep
简介
是前馈神经网络,擅长泛化,可自动学习数据中的复杂模式和特征之间的高阶交互关系。以推荐系统为例,能通过对用户和物品的特征进行深度挖掘,发现潜在的、不那么明显的关联,为用户推荐一些他们可能感兴趣但未曾直接接触过的物品。
理解Deep增强泛化能力
Deep部分是一个DNN模型,输入的特征主要分为两大类,一类是数值特征(可直接输入DNN),一类是类别特征(需要经过Embedding之后才能输入到DNN中),Deep部分的数学形式如下:
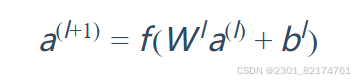
DNN模型随着层数的增加,中间的特征就越抽象,也就提高了模型的泛化能力。
代码演示
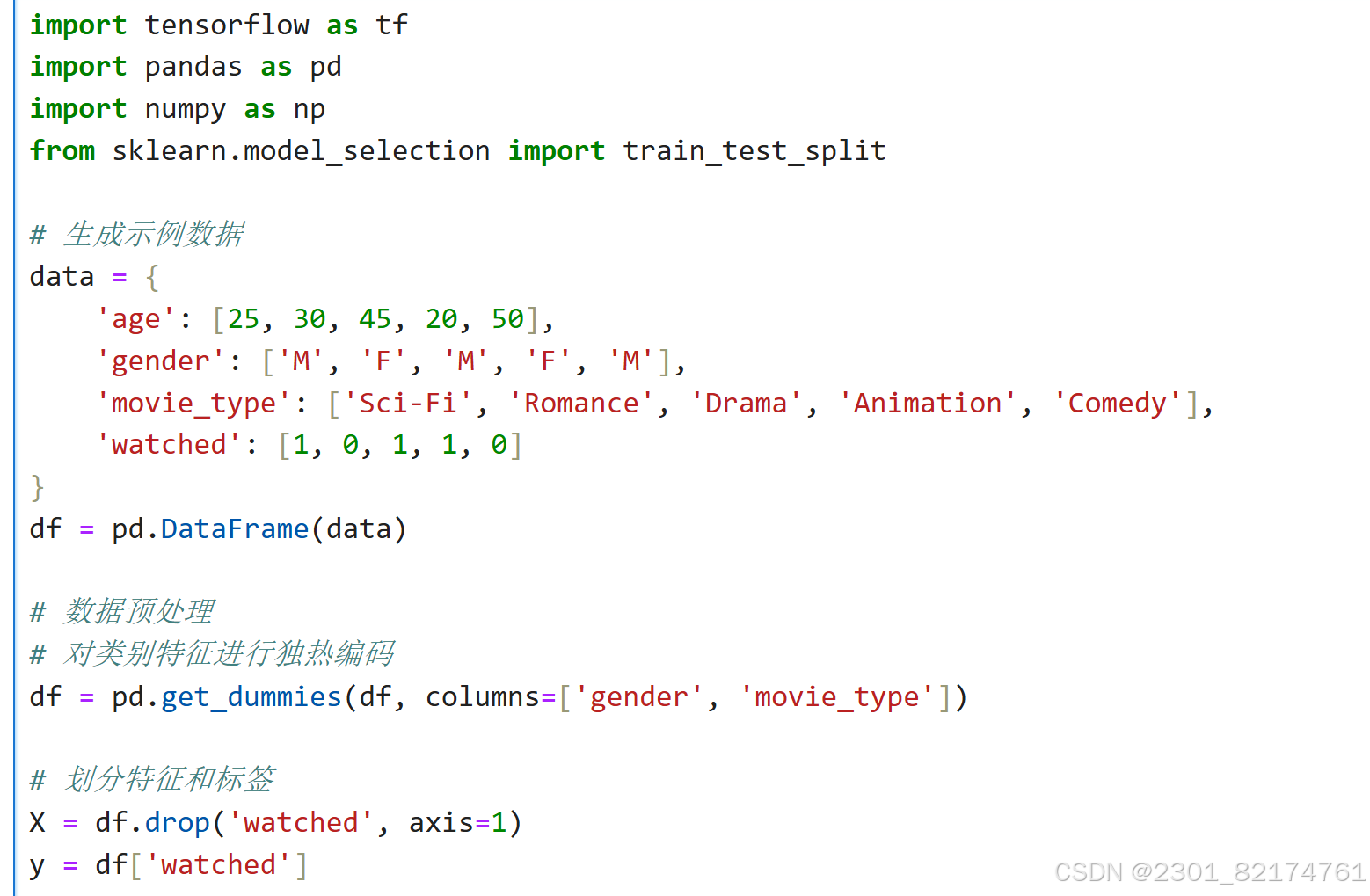

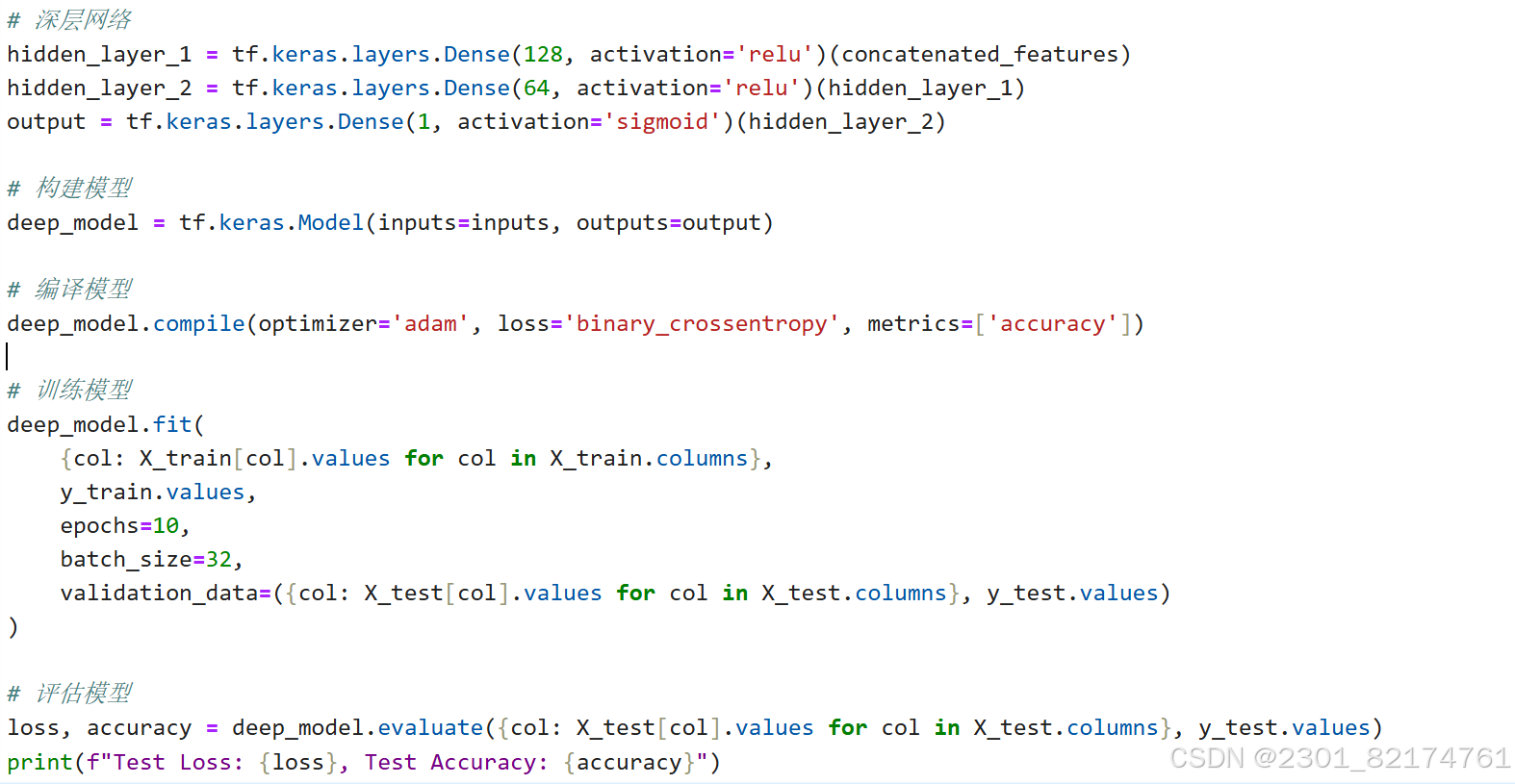

关于损失值
损失函数(在这里是二元交叉熵损失 binary_crossentropy)用于衡量模型预测值与真实标签之间的差异。0.8849431276321411 这个损失值相对较高。这个任务上,预测值和实际情况不太相符,模型的预测效果较差。
关于测试准确率(Test Accuracy)
准确率(accuracy)是指模型正确预测的样本数占总样本数的比例。测试准确率为 0 意味着在整个测试集中,模型没有正确预测出任何一个样本的标签。预测几乎都是错误的。
3.Wide部分与Deep部分的结合
模型结构
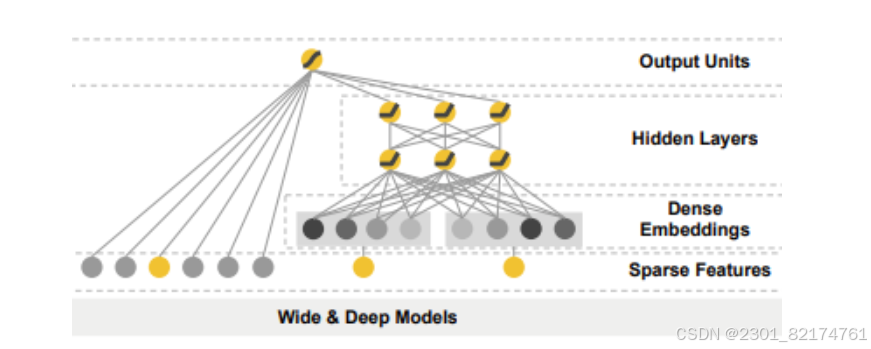
W&D模型是将两部分输出的结果结合起来联合训练,将deep和wide部分的输出重新使用一个逻辑回归模型做最终的预测,输出概率值。联合训练的数学形式如下:需要注意的是,因为Wide侧的数据是高维稀疏的,所以作者使用了FTRL算法优化,而Deep侧使用的是 Adagrad。
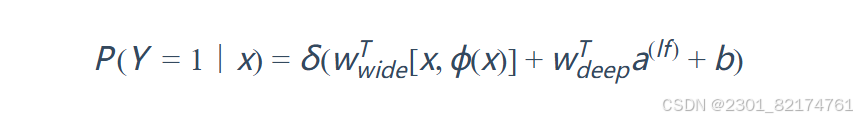
4.思考
- 在你的应用场景中,哪些特征适合放在Wide侧,哪些特征适合放在Deep侧,为什么呢?
- 为什么Wide部分要用L1 FTRL训练?
- 为什么Deep部分不特别考虑稀疏性的问题?
1.如果他们的英语单词一样,先从wide说起。wide所谓的记忆能力,直白地说就是直接的”、“暴力的”、“显然的”关联规则的能力。比如上面的代码和结果可以知道学生职业看了浪漫电影,但无法看出医生职业是否看了,因为职业和电影类型组合都不是高频组合。然后是deep,如同词一样深度,例如,在电影推荐系统中,用户对电影的评论可以反映出他们对电影的喜好和态度,通过深度学习模型可以从这些评论中提取出有用的信息,用于推荐更符合用户口味的电影。
2.L1 FTRL会让Wide部分的大部分权重都为0,我们准备特征的时候就不用准备那么多0权重的特征了,这大大压缩了模型权重,也压缩了特征向量的维度。
3.在处理类别特征时,Deep 部分通常会使用Embedding,可以将高维稀疏的类别特征转换为低维连续的向量表示,从而有效地解决了稀疏性问题。
二.deepFM
1.简介
DeepFM 主要由两部分组成:因子分解机(FM)部分和深度神经网络(DNN)部分,二者共享相同的输入。
因子分解机(FM)部分:负责学习特征之间的二阶交互信息,能够有效地处理稀疏数据,捕捉特征之间的线性和低阶非线性关系。它通过对特征的隐向量进行内积运算,自动发现特征之间的组合模式。
深度神经网络(DNN)部分:能够学习到特征之间的高阶非线性关系,通过多层全连接层对输入特征进行非线性变换,挖掘数据中的复杂模式。
输出层:将 FM 部分和 DNN 部分的输出进行拼接,然后通过一个全连接层得到最终的预测结果。
2.DNN局限
当我们使用DNN网络解决推荐问题的时候存在网络参数过于庞大的问题,这是因为在进行特征处理的时候我们需要使用one-hot编码来处理离散特征,这会导致输入的维度猛增。这里借用AI大会的一张图片: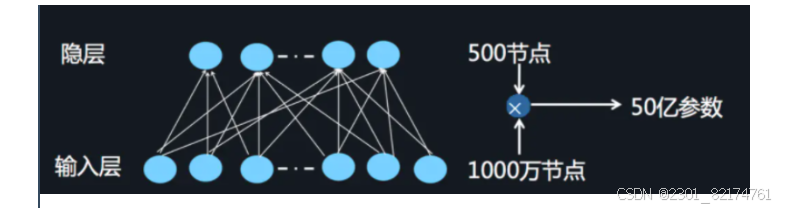
这样庞大的参数量也是不实际的。为了解决DNN参数量过大的局限性,可以采用非常经典的Field思想,将OneHot特征转换为Dense Vector
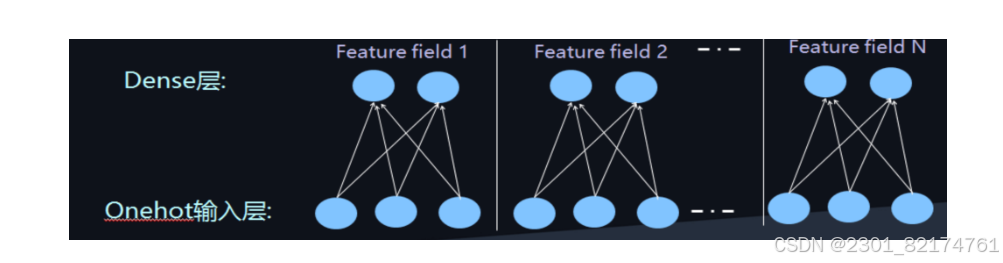
此时通过增加全连接层就可以实现高阶的特征组合,如下图所示:
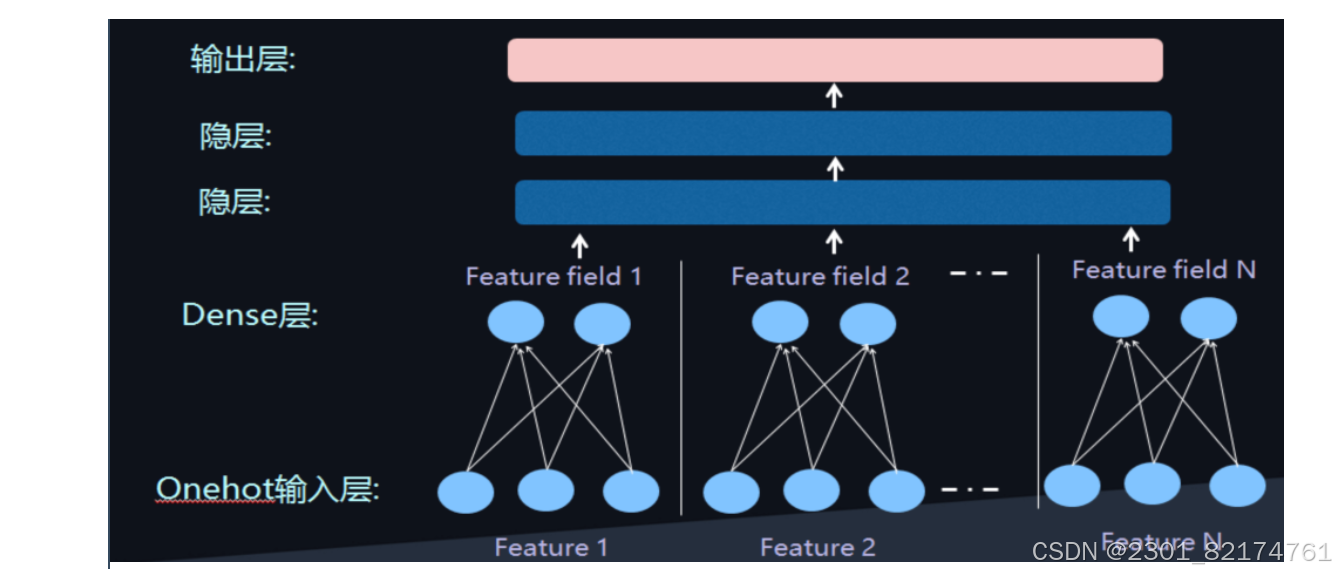
但是仍然缺少低阶的特征组合,于是增加FM来表示低阶的特征组合
3.FM
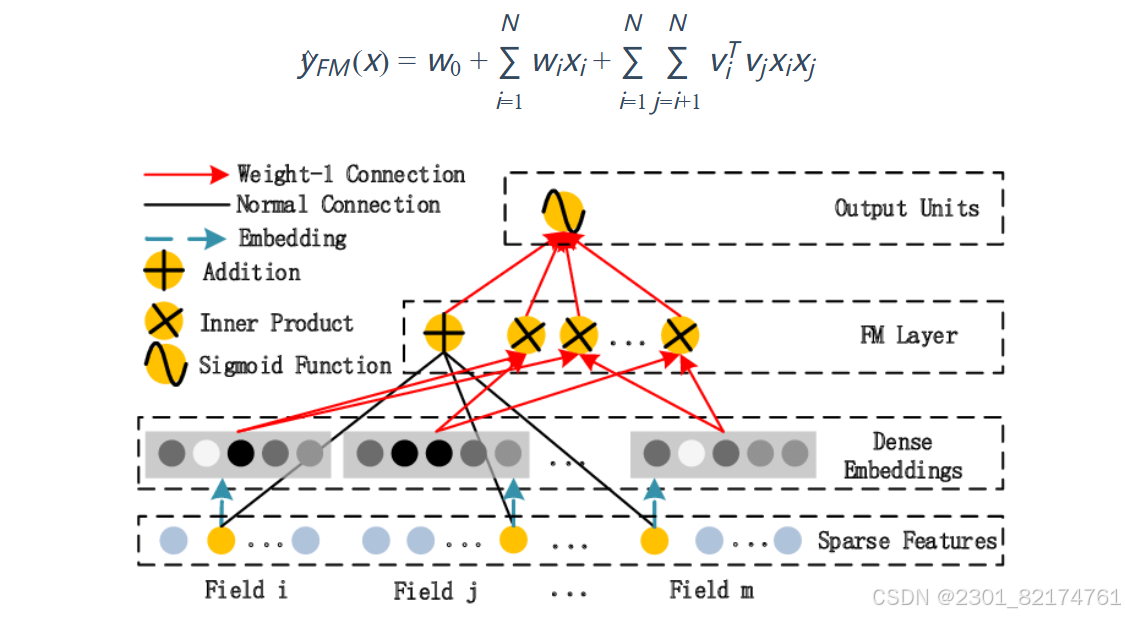
详细内容参考FM模型部分的内容,下图是FM的一个结构图,从图中大致可以看出FM Layer是由一阶特征和二阶特征Concatenate到一起在经过一个Sigmoid得到logits(结合FM的公式一起看),所以在实现的时候需要单独考虑linear部分和FM交叉特征部分。
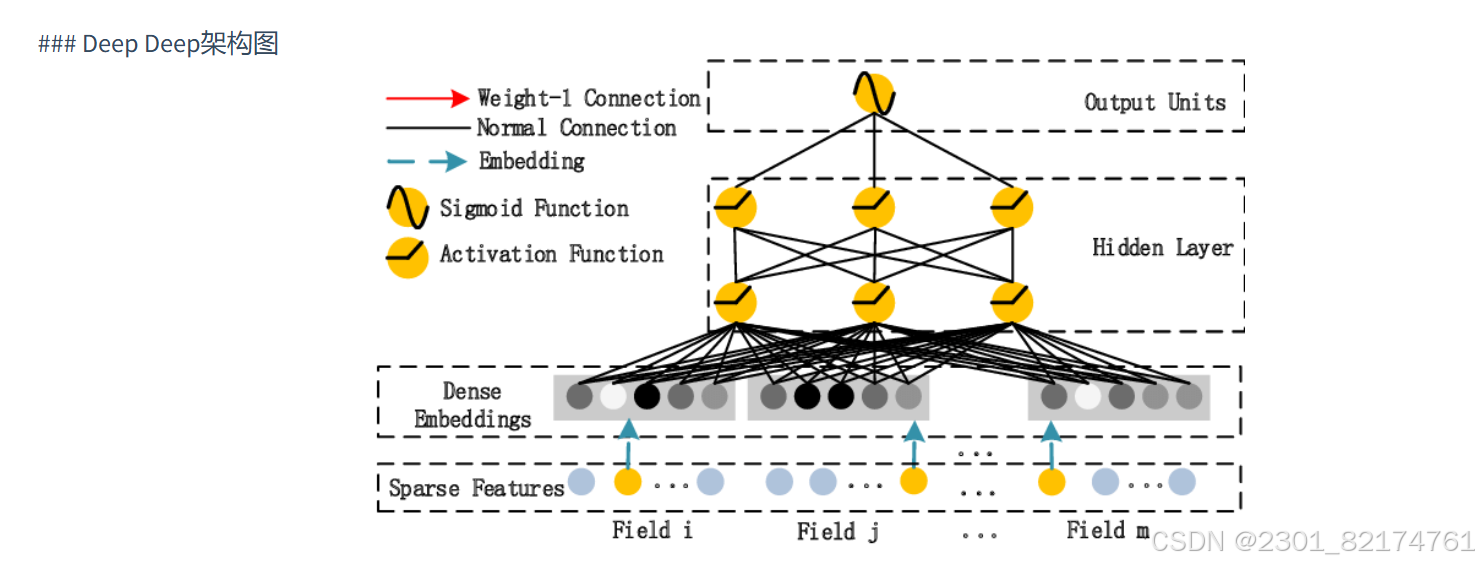
Deep Module是为了学习高阶的特征组合,在上图中使用用全连接的方式将Dense Embedding输入到Hidden Layer,这里面Dense Embeddings就是为了解决DNN中的参数爆炸问题,这也是推荐模型中常用的处理方法。
Embedding层的输出是将所有id类特征对应的embedding向量concat到到一起输入到DNN中。其中表示第i个field的embedding,m是field的数量。z1=[v1,v2,...,vm]
上一层的输出作为下一层的输入,我们得到:
其中σ表示激活函数,Z,W,b分别表示该层的输入、权重和偏置。
最后进入DNN部分输出使用sigmod激活函数进行激活:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









