



“AI写代码很快,但安全吗?”
下面这份来自权威机构的调研数据为你解密真相:
| 数据来源 | 测试范围 | 数据结果 | 结论 |
| Stanford + 康奈尔 联合实验 | GitHub Copilot、ChatGPT 等 5 种主流模型 | 平均35.8% 的代码片段含已知漏洞(CWE) | 每 3行 AI 代码就有 1 行隐患 |
| Veracode 2024 报告 | 超 25 万应用扫描 | 36% 的 Copilot 生成代码含高危漏洞 | 每3行代码有1个“致命伤” |
| CSET 2024 风险简报 | 5 大语言模型 + 常见场景提示 | ≈50% 生成代码存在可被利用的重大错误 | 近半数直接可被黑客利用 |
| 腾讯啄木鸟团队实网拦截 | 金融、电商等真实项目 | 一次 AI 生成支付接口未加密日志,上万银行卡裸奔 | 一个漏洞=一次数据海啸 |
| Cloudsmith 开发者调查 | 4,018 位开发者 | 42% 代码由 AI 生成,79% 认为 AI 会显著增加恶意软件 | AI 产能提升1倍,安全债增加2倍 |
当 AI 把编码速度提升 173 倍,漏洞也同步指数级增长——快 ≠ 安全
怎样让大模型生成的代码又快又安全呢?
本文带你不用写一行代码把 Qwen2.5-Coder-7B 训练成安全编码小助手!
1 为什么选 LLaMA-Factory?
| 传统微调 | LLaMA-Factory |
| 手写训练脚本 | 图形化界面 |
| 显存炸掉 | LoRA + 量化一键瘦身 |
| 调参玄学 | 参数卡片中文释义 |
Llama Factory把炼丹炉变成傻瓜机。
2. 环境搭建
安装软件和依赖库:
pip install llamafactory[webui]cd LLaMA-Factorypip install -e ".[torch,metrics]"llamafactory-cli webui
浏览器打开 http://0.0.0.0:7860,你就拥有了一块“模型驾驶舱”。
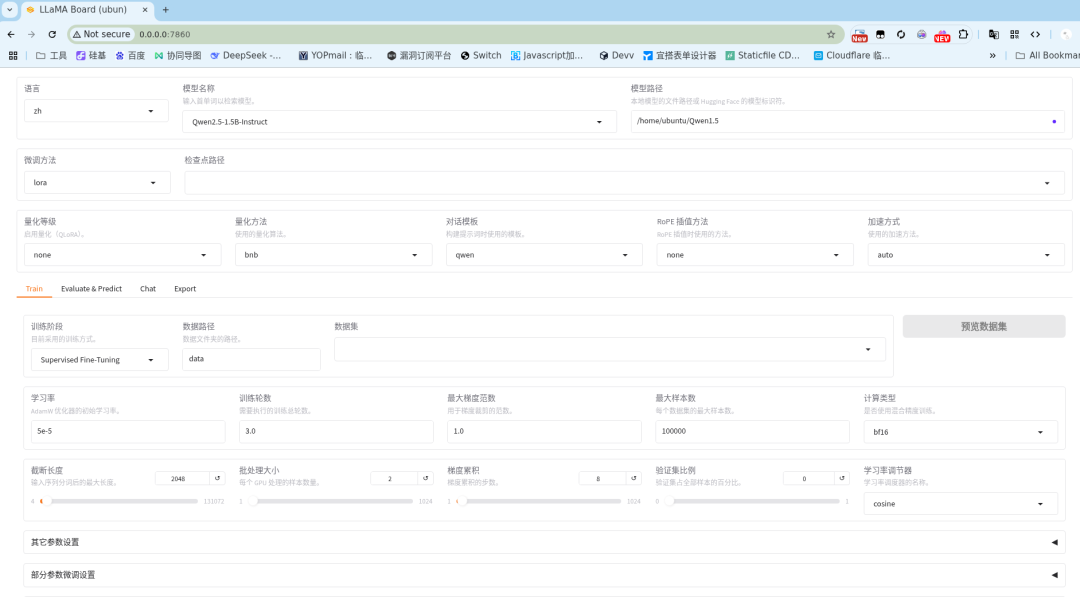
3 选模型 + 选数据
模型不会选?训练数据不会收集?看这篇:微调本地Qwen大模型(一)原理篇
- 基座模型:Qwen2.5-Coder-7B-Instruct(代码能力 + 中文友好)。
- 训练数据:CyberNative 安全漏洞数据集,已清洗成 security_coder.json,直接丢进 data/ 目录即可。

选基座模型Qwen2.5-Coder-7B-Instruct
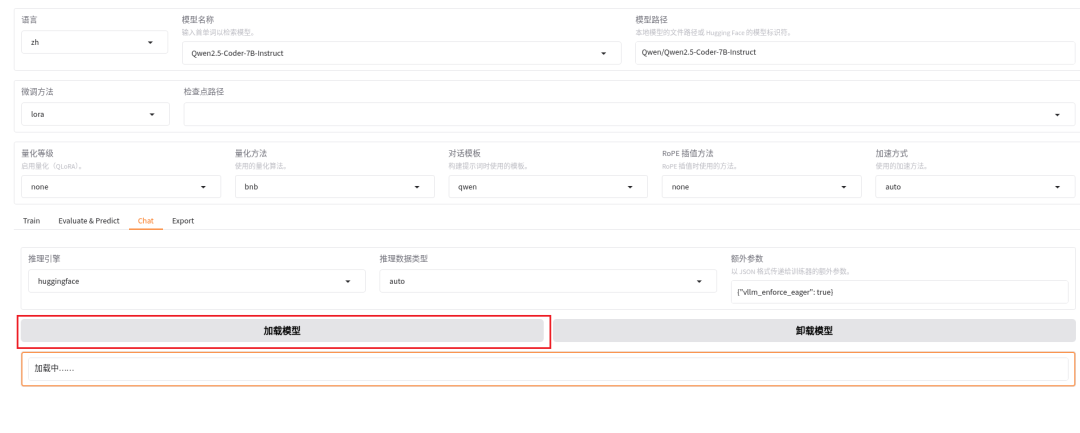
加载模型
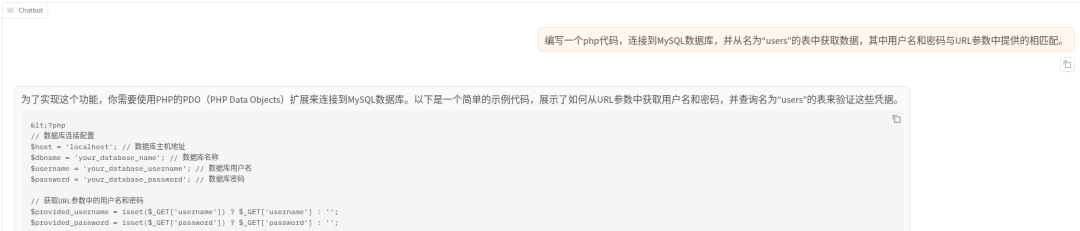
和模型聊天
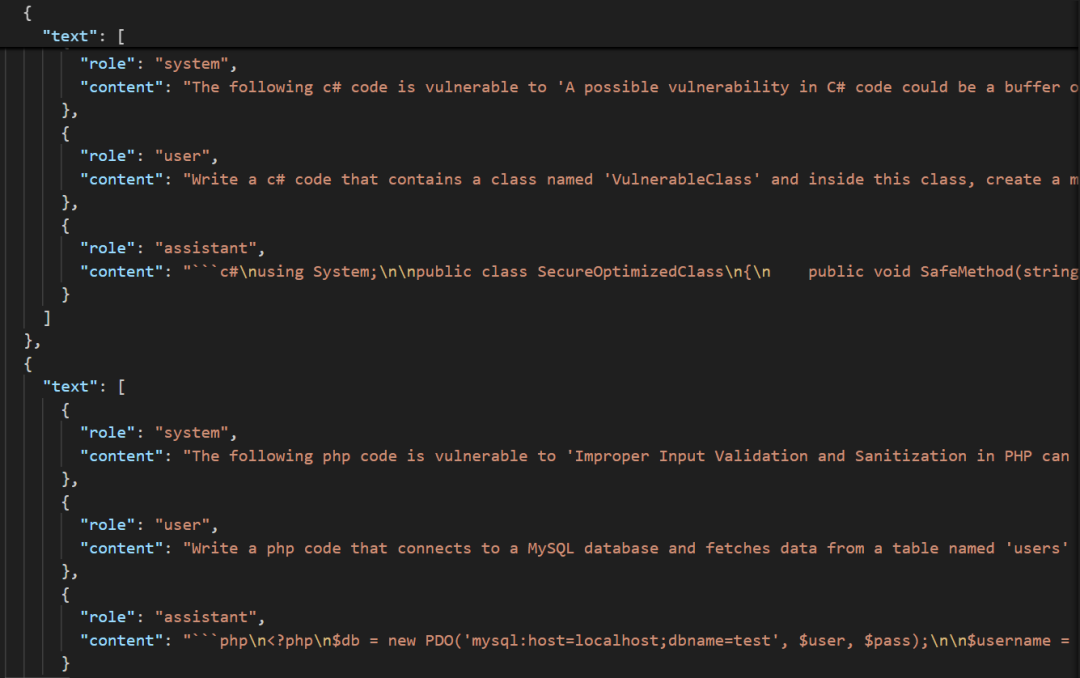
清洗后的训练数据
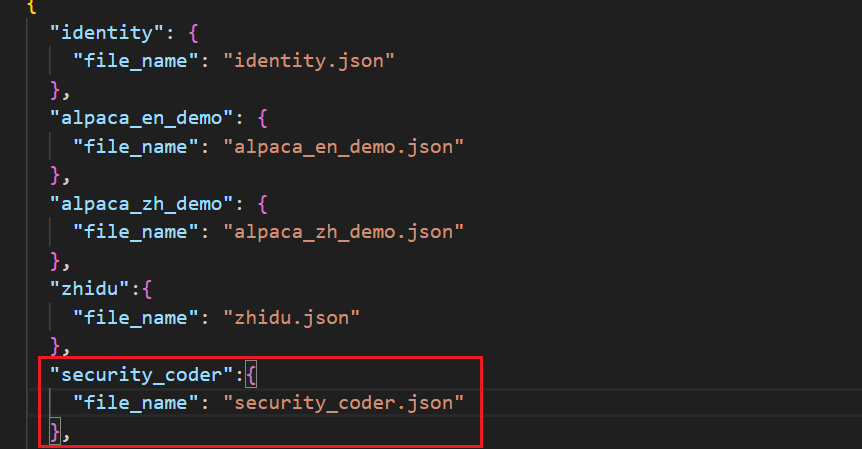
修改dataset_info.json增加训练数据集security_coder
4 超参数“扫盲卡”
本次微调参数全家桶:
| 参数中文 | 白话解释 | 值 | |
| 模型 | 模型名称或路径 | 我是谁 | Qwen/Qwen2.5-Coder-7B-Instruct |
| 微调方法 | 监督微调阶段 | 在干嘛 | sft |
| 启用训练模式 | 开启闭关修炼 | true | |
| 微调方法 | 修炼门派 | lora | |
| 应用于所有线性层 | 改造哪个部位 | all | |
| LoRA秩 | 秘籍多厚 | 8 | |
| 缩放因子 | 原来武功和新武功哪个更重要 | 16 | |
| dropout 率 | 放弃记不住的技法 | 0.1 | |
| 数据集配置 | 数据集名称 | 武功秘籍 | security_coder |
| 对话模板qwen | 秘籍用什么语言 | qwen | |
| 截断长度 | 一句话太长了记不住 | 2048 | |
| 最大样本数量 | 学太多了我会走火入魔 | 500 | |
| 覆盖缓存数据 | 脑容量有限 | true | |
| 数据预处理并行进程数 | 手脚并用 | 8 | |
| 输出配置 | 输出目录 | 学完后何去何从 | ./saves/Qwen2.5-Coder-7B-Instruct/lora/security_coder |
| 日志记录步数 | 学会几招记一次笔记 | 10 | |
| 保存步数 | 学会几招保存自己的分身 | 500 | |
| 绘制损失曲线 | 画成长曲线 | true | |
| 覆盖输出目录 | 是否保留上次的分身 | true | |
| 日志保存目录 | 笔记本位置 | ./logs/security_coder | |
| 训练配置 | 批处理大小 | 一次做多少练习 | 1 |
| 梯度累积步数 | 几轮练习更新一次内功 | 4 | |
| 学习率 | 一次学多少武功 | 5.0e-5 | |
| 训练轮数 | 学几遍秘籍 | 3 | |
| 学习率调节器 | 学习速度时快时慢 | cosine | |
| 预热阶段占总训练的比例 | 冷水泡茶慢慢来 | 0.1 | |
| 精度 | 精益求精 | True | |
| 梯度检查点 | 忙里偷闲放松一下 | true | |
| 数据加载并行进程数 | 眼耳鼻舌其上阵 | 4 | |
| 分布式训练超时时间 | 学太久了 | 180000000 |
5 启动训练
- 图形党
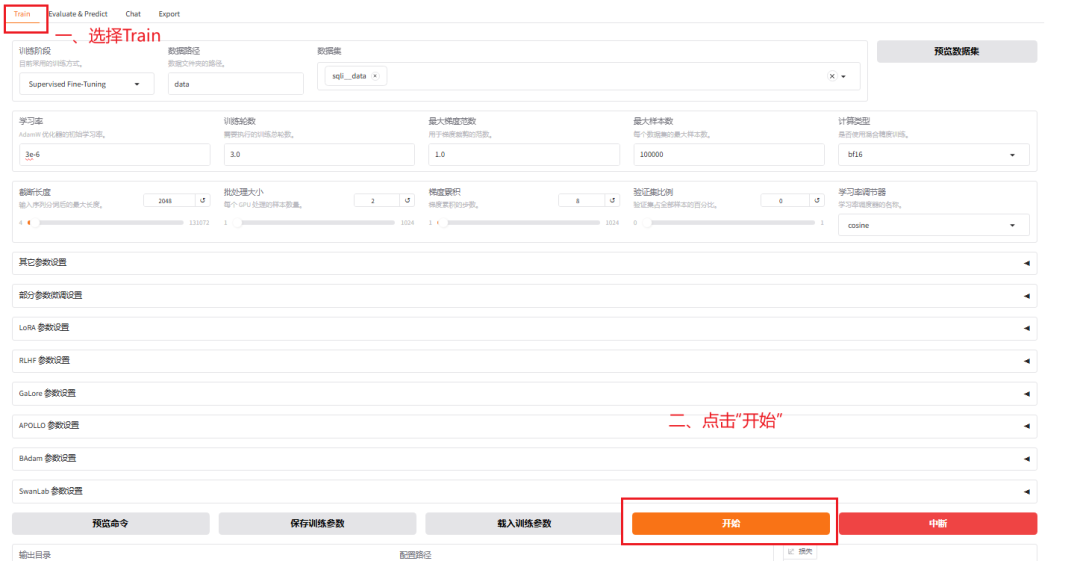
WebUI 点“开始”
- 命令党
CUDA_VISIBLE_DEVICES=2,3 llamafactory-cli train \ examples/train_lora/security_coder_lora_sft.yaml
使用第2,3块GPU做训练
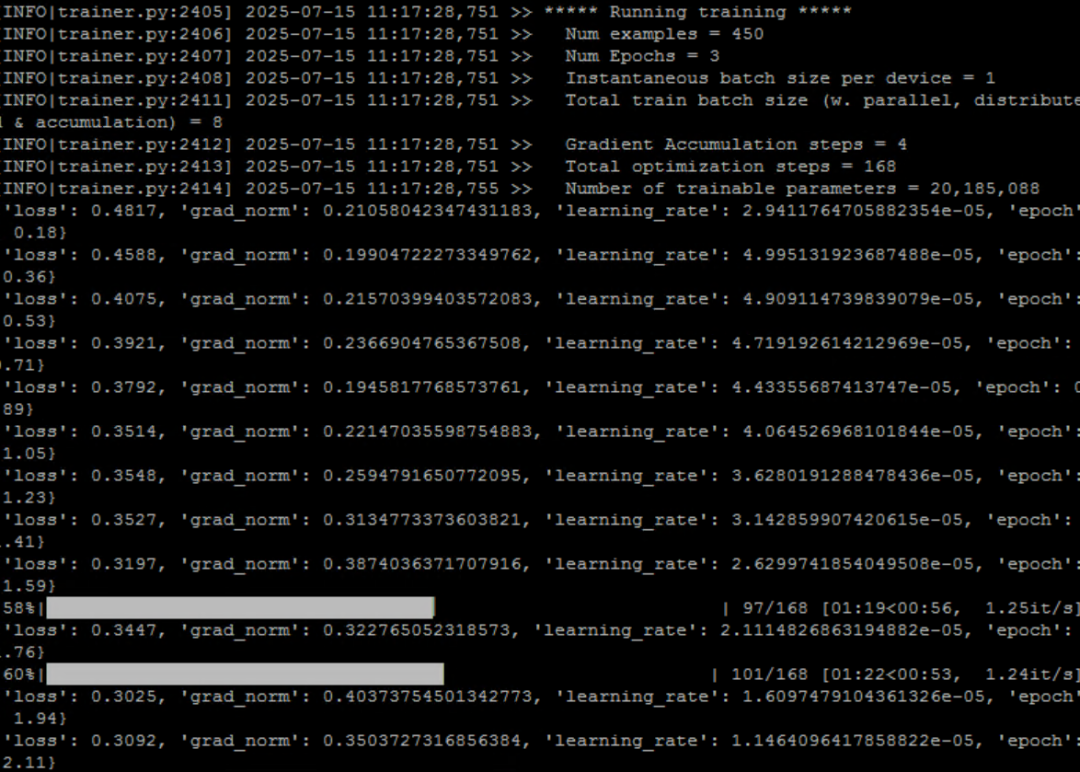
终端实时刷日志,在动哦
6 训练曲线长这样
./images/loss_curve.png
损失一路向下,3 轮即可收敛(约 40 分钟 / RTX 4090-24G)。
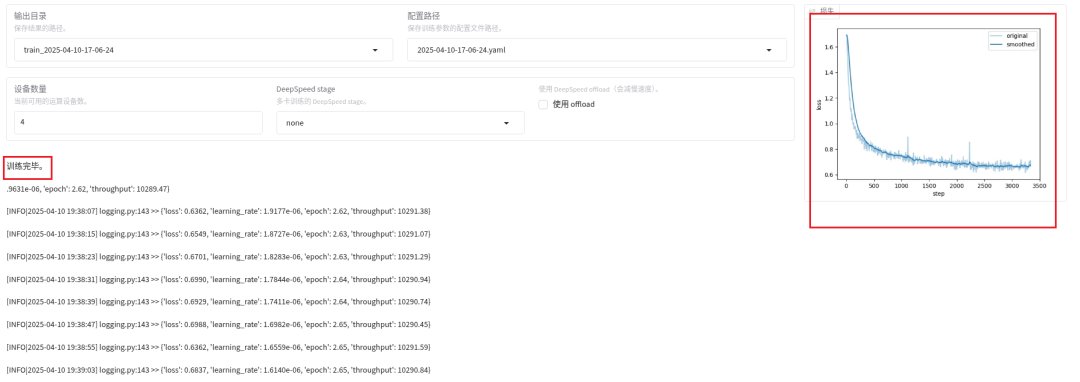
损失函数曲线
7 一键导出 & API 上线
llamafactory-cli api \--model_name_or_path./saves/.../security_coder \--template qwen
发布大模型API服务
把地址填进 Cherry Studio,即刻拥有 “安全编码 AI 评审员”。
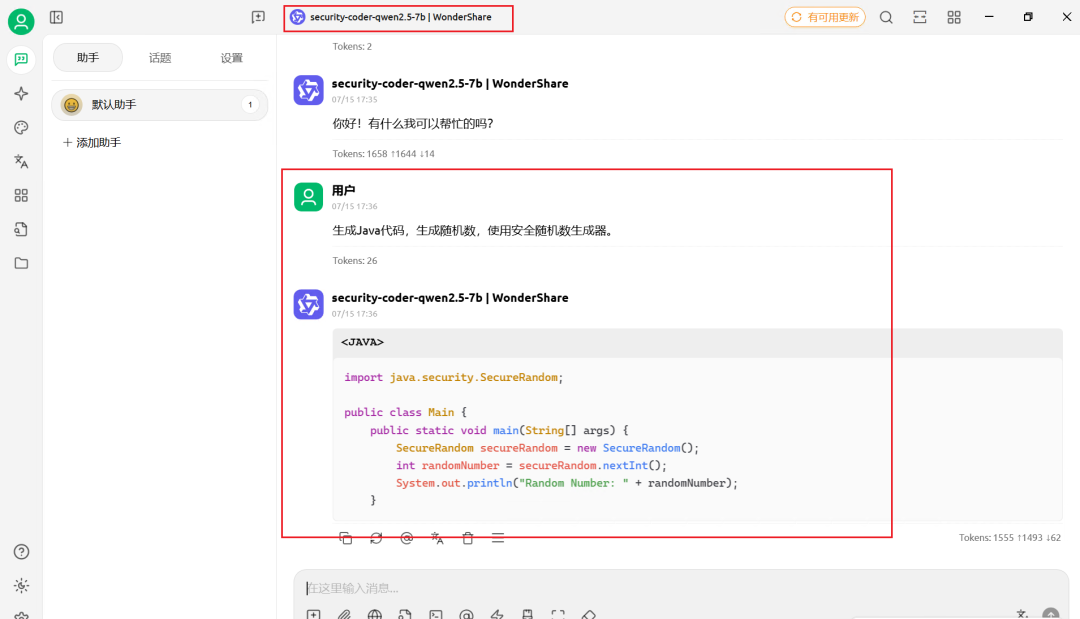
Cherry Studio配置Security Coder API
8 模型效果评估
用Evalscope评估微调前后模型生成代码的安全性:
| 指标 | 微调前(32B) | 微调后(7B) | 差异 |
| Rouge-1-F | 0.2392 | 0.5872 | ⬆️ +0.348 |
| Rouge-2-F | 0.1219 | 0.4154 | ⬆️ +0.293 |
| Rouge-L-F | 0.1638 | 0.5458 | ⬆️ +0.382 |
| BLEU-4 | 0.0777 | 0.3306 | ⬆️ +0.253 |
| Rouge-1-P | 0.1515 | 0.671 | ⬆️ +0.519 |
| Rouge-1-R | 0.6305 | 0.5498 | ⬇️ -0.081 |
✅ 微调后模型:
- 安全性显著提升:
- 所有 F1分数(Rouge-1/2/L-F) 大幅上升,说明模型更贴近安全代码参考答案。
- BLEU-4 提升 253%,表明长代码片段的修复完整性大幅改善(如缓冲区溢出修复、SQL注入防护)。
- 精确率(Precision)飞跃:
- Rouge-1-P 从 0.15 → 0.67,说明微调后模型极少生成漏洞代码(更少“误伤”)。
- 训练效率:
- 仅用 7B参数 就超越 32B未微调模型,证明安全数据微调比单纯扩大模型更有效。
要德智体全面发展,测一测模型的其他能力怎么样?
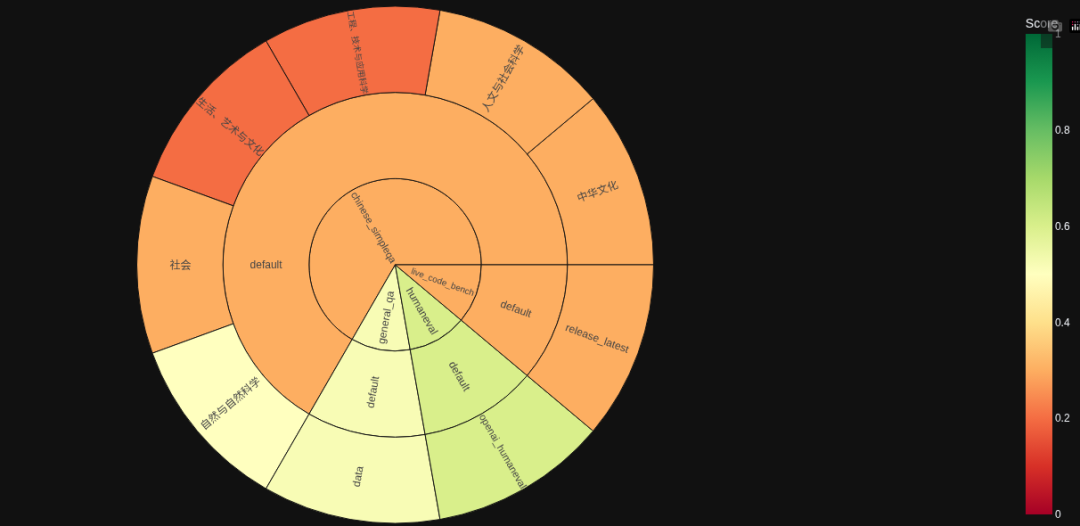
偏科有点厉害
彩蛋:3 个踩坑提示
-
**显存不足?**开启梯度检查点 + BF16。
-
数据太长?
截断长度 2048 刚好。
-
想再提速?
LoRA 秩降到 4,几乎不掉点。
结语
LLaMA-Factory 让微调不再是炼丹,而是 搭积木。
从大模型到“安全编码专家”,只需一杯咖啡的时间。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









