



背景介绍
vLLM 是一个开源的大语言模型(LLM)推理与服务引擎,由 加州大学伯克利分校 Sky Computing Lab 发起开发,现已成为社区驱动项目,并被正式纳入 PyTorch 生态系统项目。
- 项目主页:https://github.com/vllm-project/vllm
- 官方文档:https://docs.vllm.ai
它的目标是让 大模型推理更快、更省显存、更易部署,并且可以直接提供 OpenAI API 兼容接口,让用户可以像调用 OpenAI 的接口那样使用自己的模型。
为什么 vLLM 很重要?
运行大语言模型时,主要难点包括:
- 显存占用(特别是 Attention 的 KV 缓存)
- 并发请求的吞吐量与延迟
- 多硬件适配(GPU/TPU/CPU)
- 动态批处理与任务调度
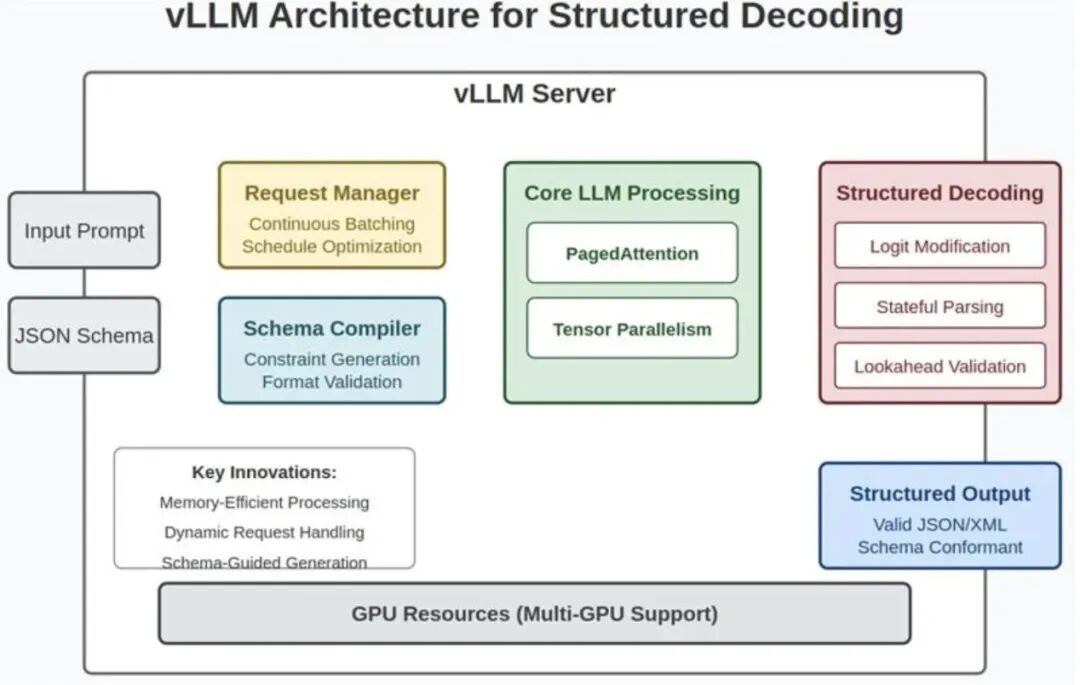
vLLM 针对这些问题提出了一系列创新,例如 PagedAttention 算法、动态连续批处理(Continuous Batching)等,从而极大提升了推理效率。
核心特性
vLLM 推理速度快
-
高效的注意力机制:PagedAttention 是 vLLM 的核心创新之一。它像“虚拟内存”一样管理 Attention 的 Key/Value 缓存(KV cache),只在需要时加载,从而显著减少显存浪费。
-
对 CUDA Kernel 进行优化,包括FlashAttention、FlashInfer 等优化内核,进一步提升速度。
-
动态连续批处理(Continuous Batching)
:vLLM 可以动态合并不同请求到同一个批次中推理,即使请求在不同时间到达,也不会浪费 GPU 时间。这让它在高并发 API 服务场景中非常高效。
-
使用CUDA/HIP graph进行加速
-
推测性解码(Speculative decoding)
-
块状预填充(Chunked prefill)
-
量化:内置支持多种量化方案:GPTQ、AWQ、INT8、INT4、FP8 等
接口易用性
- OpenAI API 兼容接口: vLLM 自带一个 OpenAI 风格的接口服务。
- 多硬件支持:支持 NVIDIA GPU、AMD GPU(AMD ROCm)、Intel GPU(Intel XPU)、TPU、CPU 等多种硬件。同时支持张量并行(Tensor Parallel)、流水线并行(Pipeline Parallel)等分布式推理。
- 与流行的 HuggingFace 模型无缝集成
- 采用多种解码算法,包括并行采样(parallel sampling)、波束搜索(beam search)等,实现高吞吐量服务
- 支持分布式推理的张量、管道、数据和专家并行性
- 支持前缀缓存(Prefix Caching),复用相同提示词前缀的计算结果
- 多LoRa支持
实践
vLLM 是一个快速易用的 LLM 推理和服务库。只需几行代码,您就可以在本地以 OpenAI 兼容格式运行 LLM(例如 DeepSeek):
安装 vllm
参考官方文档:https://docs.vllm.ai/en/latest/getting_started/quickstart/#installation 进行安装
uv venv --python 3.12 --seedsource .venv/bin/activateuv pip install vllm --torch-backend=auto
服务化部署(Bash)
export CUDA_VISIBLE_DEVICES=0,1nohup vllm serve Qwen/Qwen3-4B-Instruct-2507 > server.log 2>&1 &disowncurl http://localhost:8000/v1/models
``````plaintext
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-4B-Instruct-2507", "prompt": ["San Francisco is a", "The capital of Germany is"], "max_tokens": 7, "temperature": 0 }'
``````plaintext
{"id":"cmpl-274ae6a8ef17464fa11452e33b3c25cb","object":"text_completion","created":1762616312,"model":"Qwen/Qwen3-4B-Instruct-2507","choices":[{"index":0,"text":" city in California, United States,","logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null,"prompt_logprobs":null,"prompt_token_ids":null},{"index":1,"text":" Berlin. Is this statement true?\n\n","logprobs":null,"finish_reason":"length","stop_reason":null,"token_ids":null,"prompt_logprobs":null,"prompt_token_ids":null}],"service_tier":null,"system_fingerprint":null,"usage":{"prompt_tokens":9,"total_tokens":23,"completion_tokens":14,"prompt_tokens_details":null},"kv_transfer_params":null}
服务化部署(Python)
vllm 支持与 OpenAI 兼容的接口进行服务请求
from openai import OpenAImodel_name = "Qwen/Qwen3-4B-Instruct-2507"# Modify OpenAI's API key and API base to use vLLM's API server.openai_api_key = "EMPTY"openai_api_base = "http://localhost:8000/v1"client = OpenAI( api_key=openai_api_key, base_url=openai_api_base,)# Single prompt completioncompletion = client.completions.create( model=model_name, prompt="San Francisco is a", max_tokens=7, temperature=0,)print("Completion result:", completion)# support multiple promptscompletion = client.completions.create( model=model_name, prompt=["San Francisco is a", "The capital of Germany is"], max_tokens=7, temperature=0,)print("Completion result for multiple prompts:", completion)
性能与优势
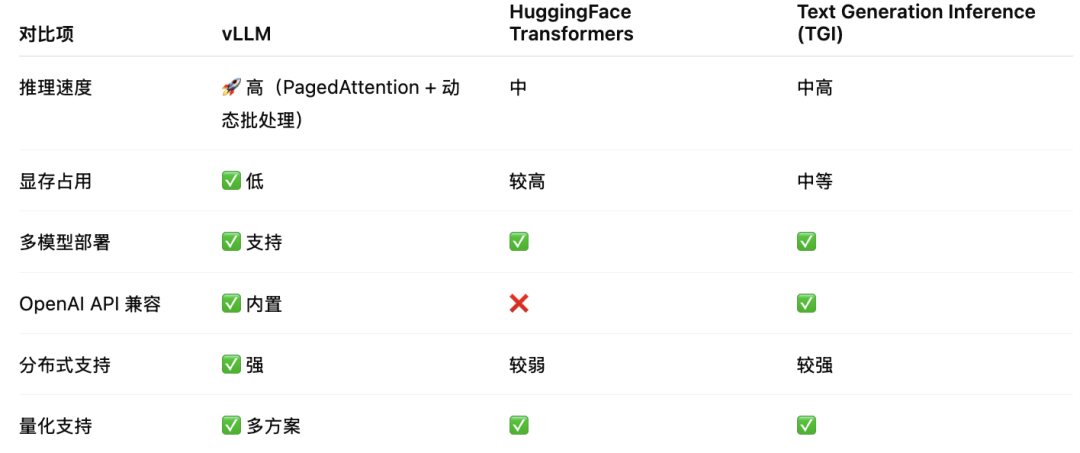
vLLM 在同等硬件条件下常常能比 HuggingFace 推理快 2~5 倍
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:

- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









