






声明:以下工具仅用于学习交流使用,请勿用作商业用途!
在当今多元化的社交媒体格局中,weibo占据着举足轻重的地位,是中国备受欢迎的社交媒体平台之一。其以文字与图片为主要内容承载形式,构建起一个庞大且活跃的社交与信息交互网络。
在weibo强大的信息传播能力与活跃的社交氛围下,其蕴含的数据价值愈发凸显。无论是企业希望通过分析数据洞察市场趋势、了解消费者需求,从而制定精准的营销策略;还是研究人员渴望借助这些数据深入剖析社会舆论走向、探究用户行为模式,为学术研究提供有力支撑;亦或是自媒体从业者想要获取热门话题和用户关注焦点,以创作更具吸引力的内容,都对weibo数据采集提出了迫切需求。
然而,手动采集weibo数据不仅效率低下,且难以满足大规模、多样化的数据需求。面对海量的信息,人工筛选和收集犹如大海捞针,耗费大量的时间和精力,却可能无法获取全面、准确的数据。为了填补这一空白,解决用户在数据采集中面临的困境,我开发了这个【爬微博搜索软件】。
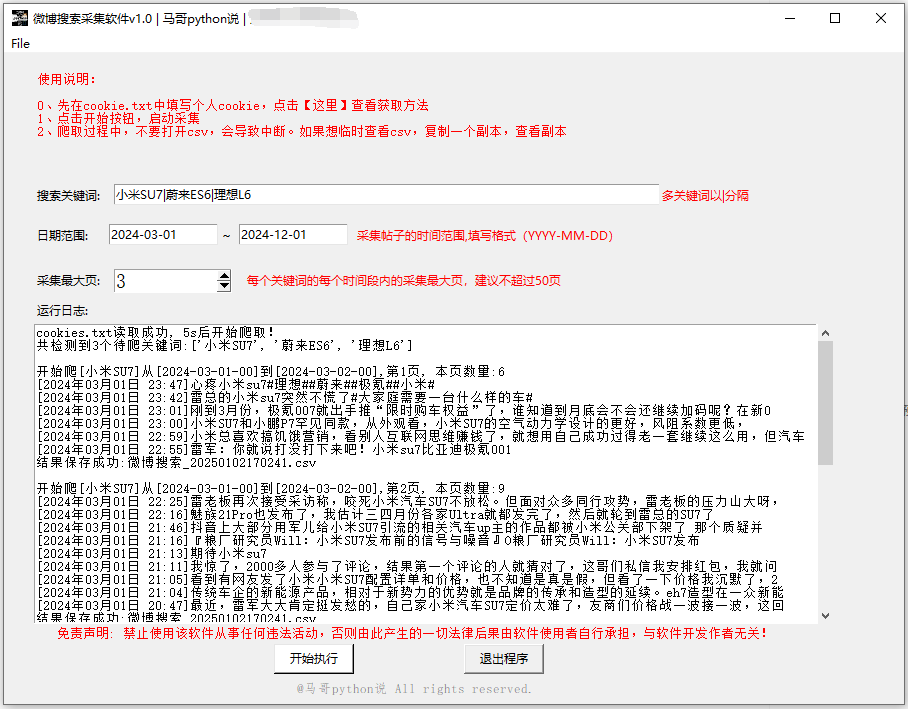
·
采集到的结果数据,长这样: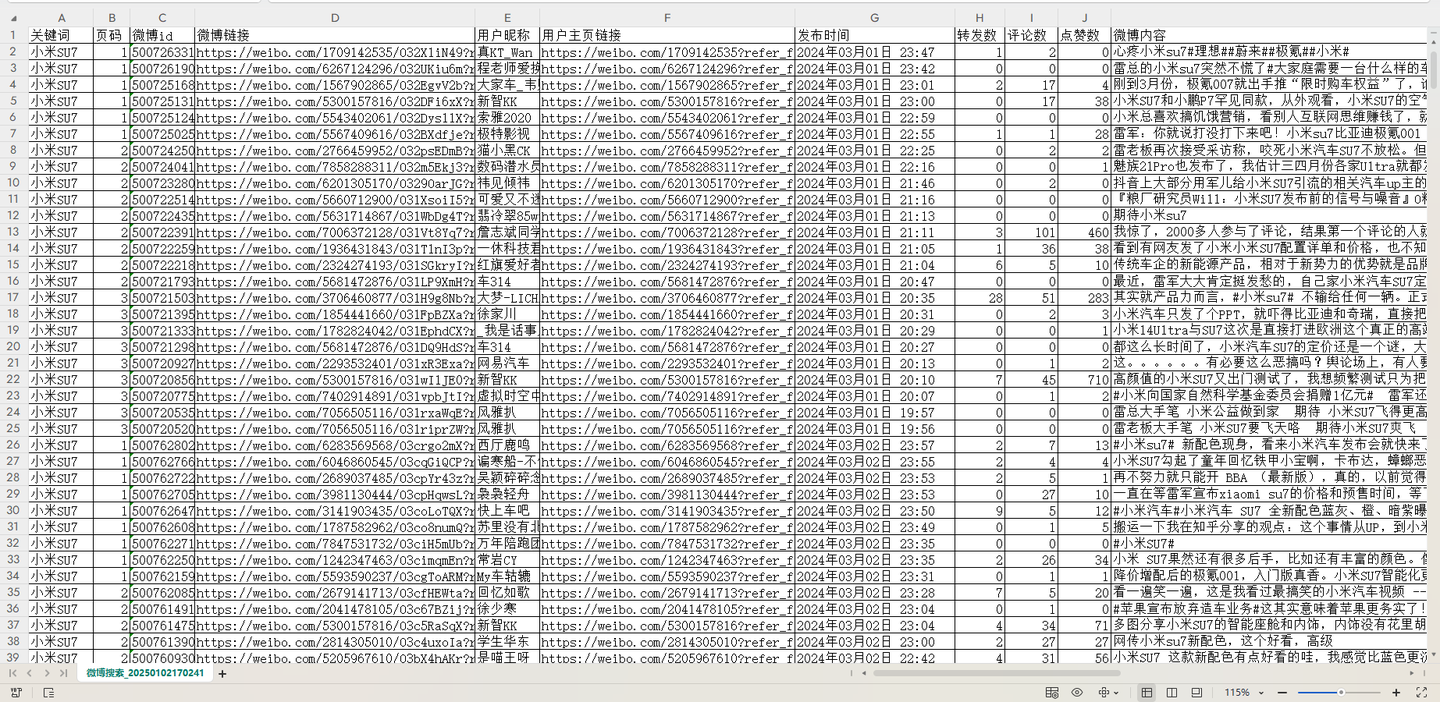
·
软件有几条关键的注意事项和说明: 软件全部模块采用python语言开发,主要分工如下:
软件全部模块采用python语言开发,主要分工如下:
tkinter:GUI软件界面
requests:爬虫请求
BeautifulSoup:解析响应数据
pandas:保存csv结果、数据清洗
logging:日志记录
出于版权考虑, 暂时闭源,仅提供软件使用权限。
主要技术栈:
完全基于 Python 语言进行开发,Python 以其简洁的语法、丰富的库资源以及强大的功能,成为数据采集与处理领域的首选语言。在软件的开发过程中,多个关键模块协同工作,共同构建起软件的核心功能架构。
tkinter 作为 Python 的标准 GUI 库,承担起构建软件图形用户界面的重任。它为用户提供了一个直观、便捷的操作界面,通过各种可视化组件,如按钮、文本框、列表框等,用户可以轻松地与软件进行交互,设置数据采集的参数和条件。在软件的主界面中,tkinter 创建了输入框用于用户输入关键词和设置时间范围,以及按钮用于触发数据采集操作,使得整个操作流程简单易懂,即使是没有编程经验的用户也能快速上手。
requests 模块则专注于处理网络请求,它是软件与微博服务器进行数据交互的桥梁。通过发送 HTTP 请求,requests 模块能够获取指定网页的内容,无论是普通的 GET 请求获取微博页面的基本信息,还是在需要模拟用户登录等场景下使用的 POST 请求,requests 模块都能高效地完成任务。它还支持设置各种请求头信息,以应对微博服务器可能的反爬虫机制,确保数据请求的顺利进行。
BeautifulSoup 是一款强大的 HTML 和 XML 解析库,它能够将 requests 获取到的网页内容进行解析,提取出其中有用的数据。在处理微博页面时,BeautifulSoup 可以根据 HTML 标签和属性,精准地定位到微博的发布时间、用户昵称、微博内容等关键信息,将复杂的网页结构转化为易于处理的数据格式,为后续的数据处理和保存提供了便利。
pandas 是 Python 中用于数据处理和分析的核心库,在【爬微博搜索软件】中,它主要负责数据的保存和清洗工作。在数据保存方面,pandas 可以将采集到的微博数据以 csv 文件的形式高效地保存到本地,并且支持对文件的追加写入操作,确保每次采集的数据都能完整地保存下来。在数据清洗环节,pandas 提供了丰富的函数和方法,能够对采集到的数据进行去重、缺失值处理、格式转换等操作,提高数据的质量和可用性。
logging 模块用于记录软件运行过程中的各种信息,包括请求的发送、数据的解析、保存结果以及可能出现的错误等。通过详细的日志记录,用户可以在软件运行出现问题时,快速回溯问题发生的过程,定位错误原因,从而及时采取措施进行修复。logging 模块还支持设置不同的日志级别,用户可以根据实际需求选择记录的详细程度,方便在开发和调试过程中进行问题排查。
关键代码展示
以下是软件中一些关键功能的代码实现,通过这些代码片段,可以更直观地了解软件的工作原理和实现方式。
发送请求并解析数据:
# 发送请求
r = requests.get(url, headers=h1, params=params)
# 解析数据
soup = BeautifulSoup(r.text, 'html.parser')
在这段代码中,首先使用 requests 库的 get 方法向指定的 url 发送请求,同时传入自定义的请求头 h1 和参数 params,以获取微博网页的内容。获取到响应后,利用 BeautifulSoup 库将响应的文本内容解析为一个可操作的对象 soup,后续可以通过 soup 对象提取网页中的各种数据。
解析微博链接:
# 微博链接
wb_url = 'https:' + item.find('div', {'class': 'from'}).find('a').get('href')
wb_url_list.append(wb_url)
这段代码用于从解析后的网页内容中提取微博链接。通过查找包含微博链接的 HTML 元素,利用其 class 属性定位到具体的 div 标签,再进一步找到其中的 a 标签,并获取其 href 属性值,从而得到微博的链接。将提取到的链接添加到 wb_url_list 列表中,以便后续进行数据保存或其他处理。
保存结果数据到 csv 文件:
# 保存数据
df = pd.DataFrame(
{
'关键词': kw,
'页码': page,
'微博id': id_list,
'微博链接': wb_url_list,
'用户昵称': name_list,
'用户主页链接': user_link_list,
'发布时间': create_time_list,
'转发数': repost_count_list,
'评论数': comment_count_list,
'点赞数': like_count_list,
'微博内容': text_list,
}
)
# 保存csv文件
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('结果保存成功:{}'.format(self.result_file))
这里使用 pandas 库创建一个 DataFrame 对象 df,将采集到的各种微博数据,包括关键词、页码、微博 id、链接、用户信息、发布时间、互动数据以及微博内容等,按照相应的字段进行整理。然后使用 to_csv 方法将 DataFrame 对象保存为 csv 文件,mode=‘a+’ 表示以追加模式写入文件,避免覆盖已有的数据;index=False 表示不保存行索引;header 参数用于指定是否写入表头,根据实际情况进行设置;encoding=‘utf_8_sig’ 确保文件编码正确,防止中文乱码问题。最后,通过 tk_show 方法提示用户数据保存成功,并显示保存的文件名。
最后,【爬微博搜索软件】在公众号【老男孩的平凡之路】首发。
再次声明,工具仅用于学习交流使用,请勿用作商业用途!

















 325
325

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









