






微博是中国最受欢迎的社交媒体之一,主要以文字和图片为主,特别在实时性和KOL的关注度方面表现突出。许多网友在这个平台上积极分享自己的观点和看法,形成了一个非常活跃的社区。此外,我注意到,在每次热点事件发生时,微博的热搜总是最早披露相关信息的媒体平台,其他媒体一般都会有一定的时间延迟。
因此,我用python开发了一个爬虫采集工具,叫【爬微博搜索软件】。
软件界面如下:
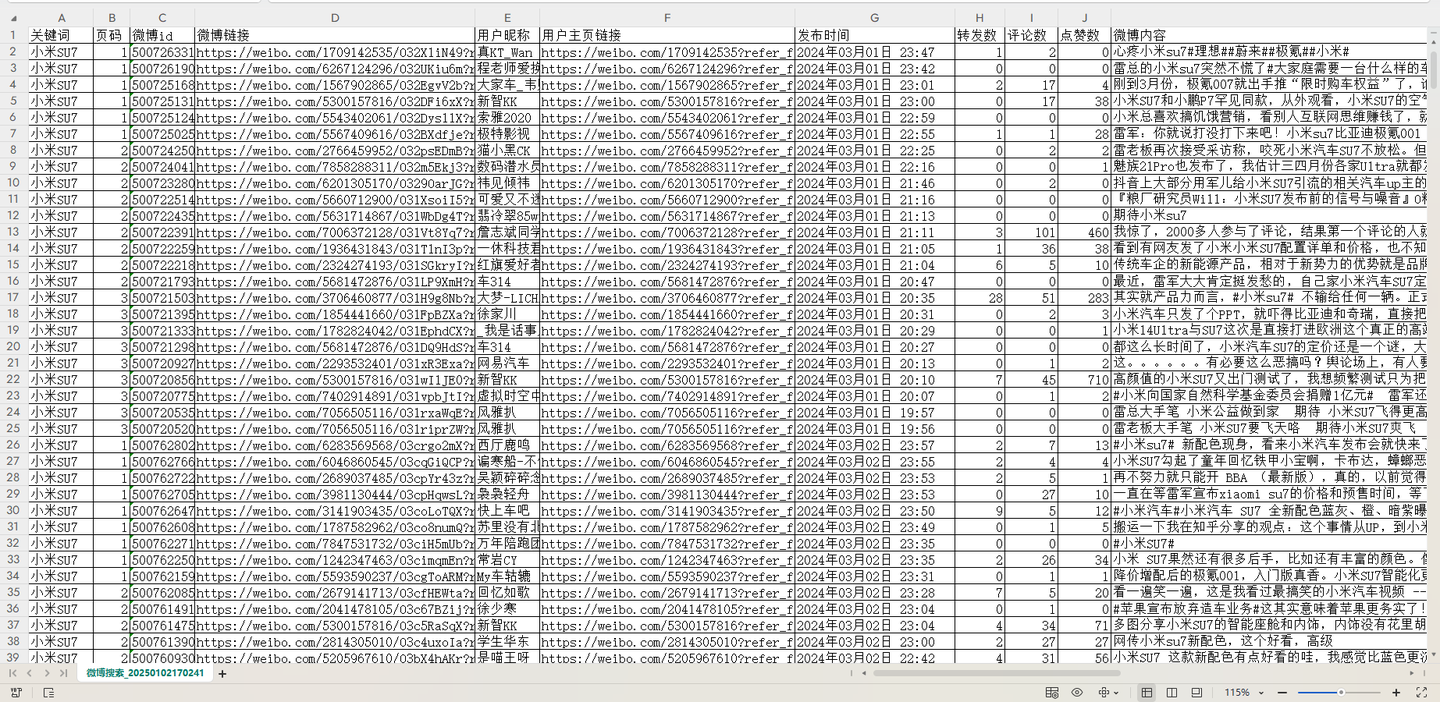
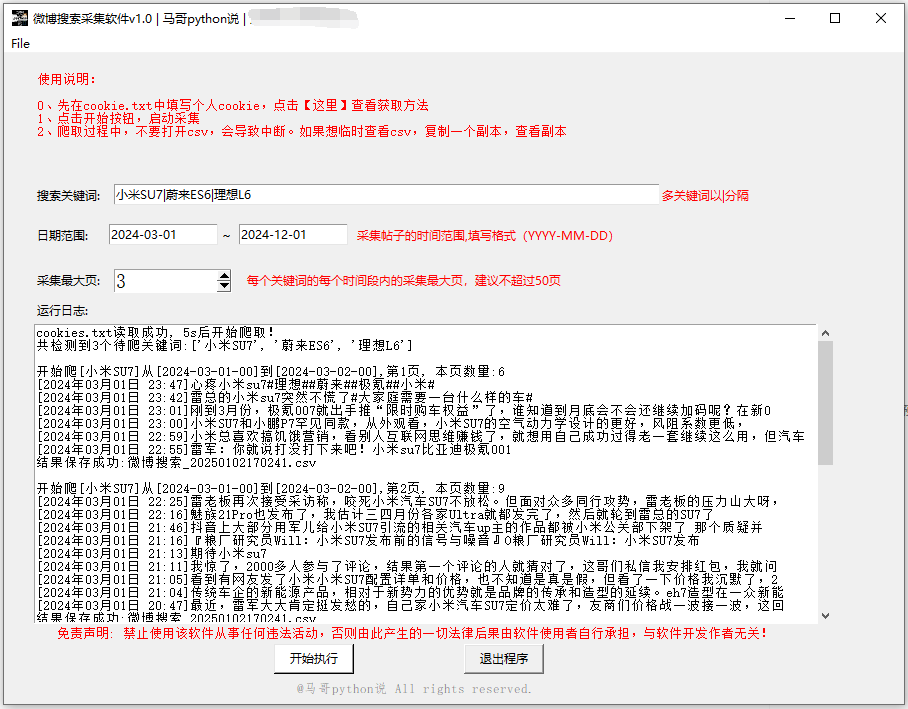 爬取结果:(截图中展示的就是全部字段了)
爬取结果:(截图中展示的就是全部字段了)
 软件运行演示:小破站:BV1morrYgEcf
软件运行演示:小破站:BV1morrYgEcf
几点重要说明,请详读了解:
1. Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
2. 软件通过爬虫程序爬取,经本人专门测试,运行持久,稳定性较高!
3. 先在cookie.txt中填入自己的cookie值,方便重复使用(内附cookie获取方法)
4. 支持多个关键词串行爬取
5. 支持按时间段范围采集贴子
6. 爬取过程中,每爬一页,存一次csv。并非爬完最后一次性保存!防止因异常中断导致丢失前面的数据(每条间隔1~2s)
7. 爬取过程中,有log文件详细记录运行过程,方便回溯
8. 结果csv含11个字段,有:关键词,页码,微博id,微博链接,用户昵称,用户主页链接,发布时间,转发数,评论数,点赞数,微博内容。
以上是现有功能,软件版本持续更新中。
软件全部模块采用python语言开发,主要分工如下:
tkinter:GUI软件界面
requests:爬虫请求
BeautifulSoup:解析响应数据
pandas:保存csv结果、数据清洗
logging:日志记录
出于版权考虑,暂不公开源码,仅向用户提供软件使用。
部分代码实现:
发送请求并解析数据:
# 发送请求
r = requests.get(url, headers=h1, params=params)
# 解析数据
soup = BS(r.text, 'html.parser')
解析微博链接:
# 微博链接
wb_url = 'https:' + item.find('div', {'class': 'from'}).find('a').get('href')
wb_url_list.append(wb_url)
保存结果数据到csv文件:
# 保存数据
df = pd.DataFrame(
{
'关键词': kw,
'页码': page,
'微博id': id_list,
'微博链接': wb_url_list,
'用户昵称': name_list,
'用户主页链接': user_link_list,
'发布时间': create_time_list,
'转发数': repost_count_list,
'评论数': comment_count_list,
'点赞数': like_count_list,
'微博内容': text_list,
}
)
# 保存csv文件
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('结果保存成功:{}'.format(self.result_file))
开始采集前,先把自己的cookie值填入cookie.txt文件。
pc端微博cookie获取说明:
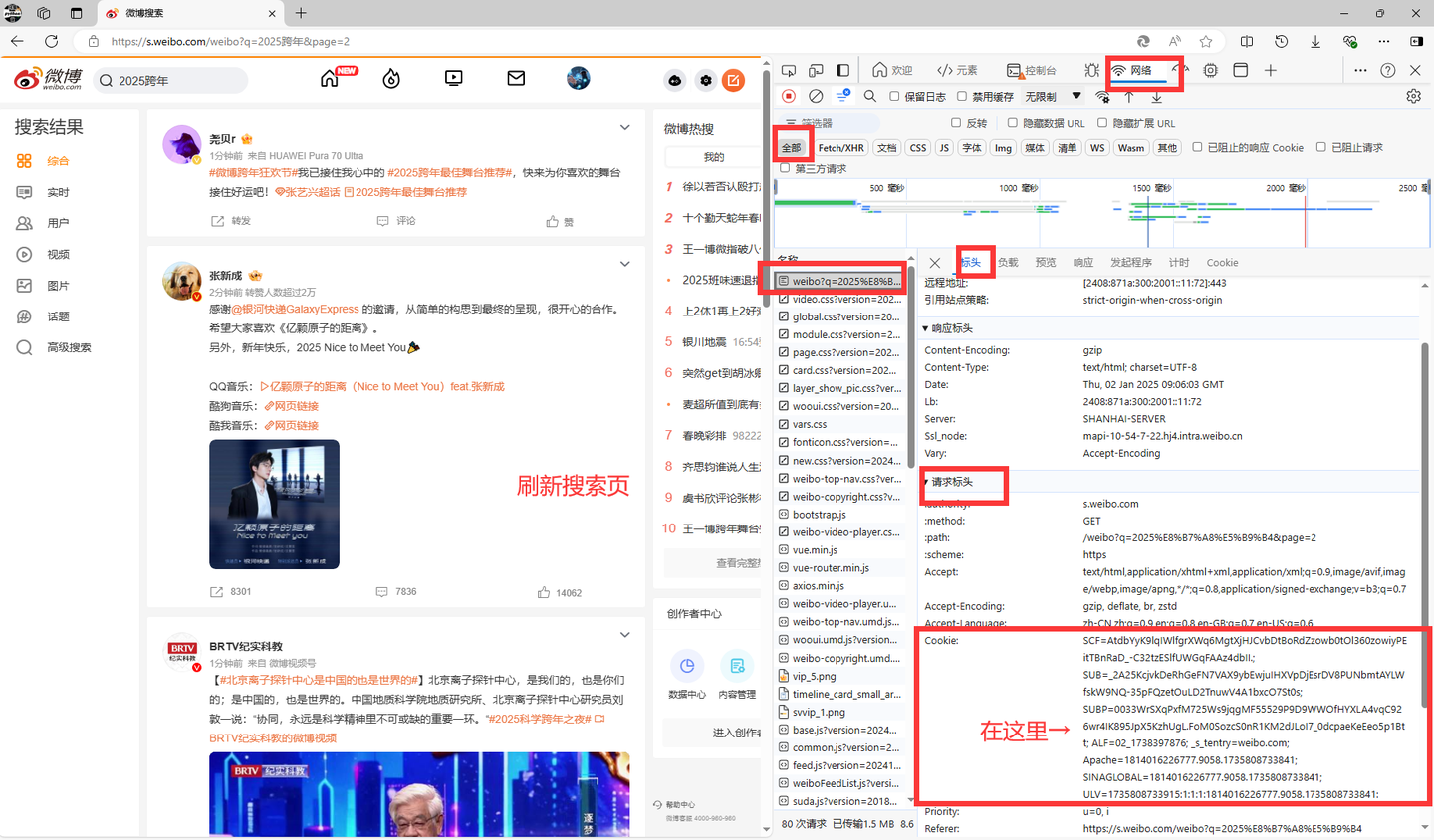 然后把复制的cookie值填写到当前文件夹的cookie.txt文件中。
然后把复制的cookie值填写到当前文件夹的cookie.txt文件中。
用户登录界面: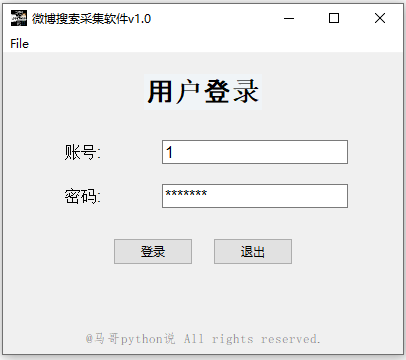
根据自己的实际情况,在软件界面填写采集条件,点击开始按钮:

完成采集后,在当前文件夹生成对应的csv文件,文件名以时间戳命名,方便查找。
暂不支持自动化付费,直接与我对接即可。
软件采用一机一码机制,一个卡密只能在一台电脑运行、不可多电脑运行。
一台电脑仅允许运行一个软件,不支持软件多开。
软件【爬微博搜索软件】首发于众公号【老男孩的平凡之路】,欢迎交流!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









