







文章目录
“整篇文章较长,干货很多!建议收藏后,分章节阅读。”
一、设计方案
整体设计方案思维导图:
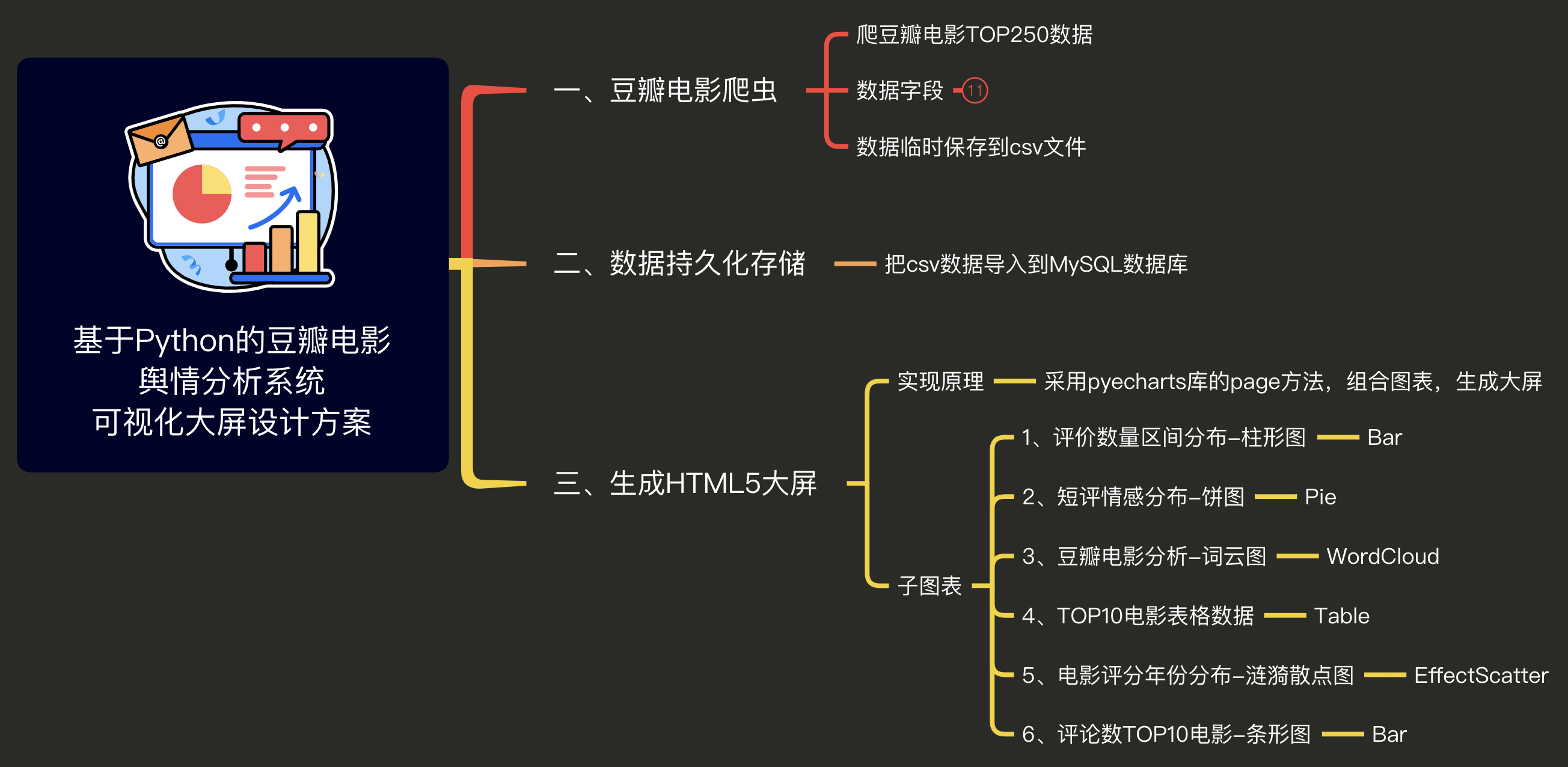
整篇文章,也将按照这个结构来讲解。
若有重点关注部分,可点击章节目录直接跳转!
二、项目背景
针对TOP250排行榜的数据,开发一套可视化数据大屏系统,展示各维度数据分析结果。
TOP250排行榜
三、电影爬虫
注意:
完整源码,公众号[老男孩的平凡之路]回复[豆瓣大屏]可得!
3.1 导入库
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
from sqlalchemy import create_engine # 连接数据库
3.2 发送请求
定义一些空列表,用于临时存储爬取下的数据:
movie_name = [] # 电影名称
movie_url = [] # 电影链接
movie_star = [] # 电影评分
movie_star_people = [] # 评分人数
movie_director = [] # 导演
movie_actor = [] # 主演
movie_year = [] # 上映年份
movie_country = [] # 国家
movie_type = [] # 类型
short_comment = [] # 一句话短评
向网页发送请求:
res = requests.get(url, headers=headers)
3.3 解析页面
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
for movie in soup.select('.item'):
name = movie.select('.hd a')[0].text.replace('\n', '') # 电影名称
movie_name.append(name)
url = movie.select('.hd a')[0]['href'] # 电影链接
movie_url.append(url)
star = movie.select('.rating_num')[0].text # 电影评分
movie_star.append(star)
star_people = movie.select('.star span')[3].text # 评分人数
star_people = star_people.strip().replace('人评价', '')
其中,需要说明的是,《大闹天宫》这部电影和其他电影页面排版不同:

所以,这里特殊处理一下:
if name == '大闹天宫 / 大闹天宫 上下集 / The Monkey King': # 大闹天宫,特殊处理
year0 = movie_infos.split('\n')[1].split('/')[0].strip()
year1 = movie_infos.split('\n')[1].split('/')[1].strip()
year2 = movie_infos.split('\n')[1].split('/')[2].strip()
year = year0 + '/' + year1 + '/' + year2
movie_year.append(year)
country = movie_infos.split('\n')[1].split('/')[3].strip()
movie_country.append(country)
type = movie_infos.split('\n')[1].split('/')[4].strip()
movie_type.append(type)
3.4 存储到csv
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['电影名称' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









