







一、背景介绍
1.1 爬取目标

用python开发的爬虫采集软件,可自动按笔记链接抓取笔记的详情数据。
为什么有了源码还开发界面软件呢?方便不懂编程代码的小白用户使用,无需安装python,无需改代码,双击打开即用!
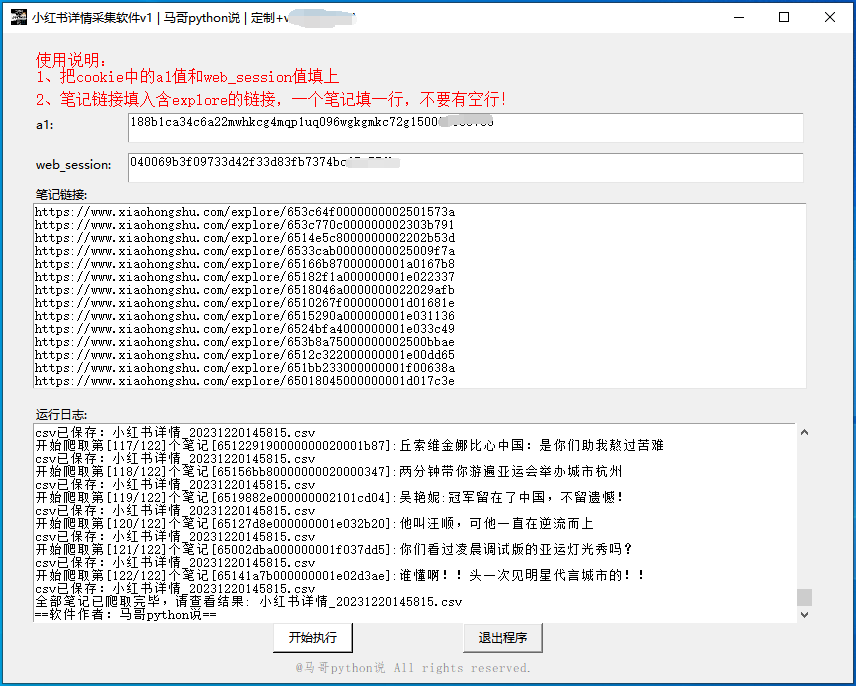
软件界面截图:
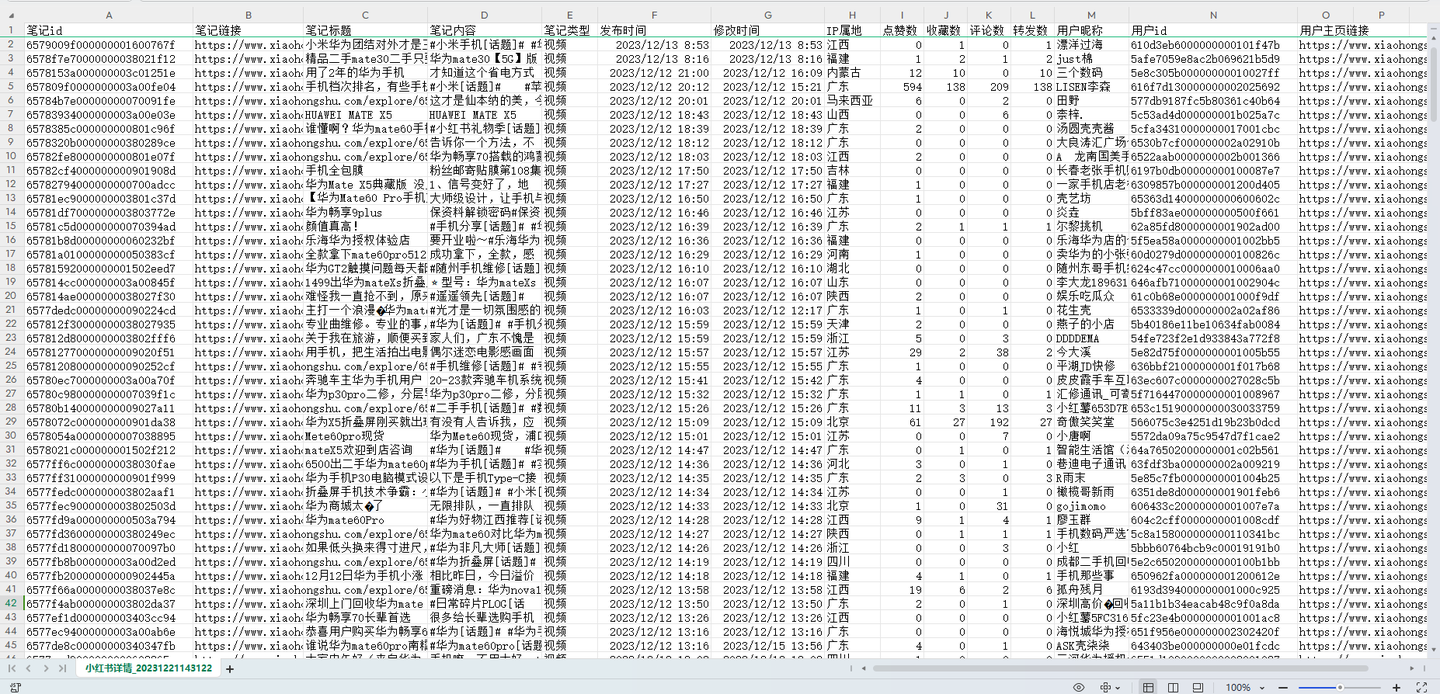
爬取结果截图:
以上。
1.2 演示视频
软件使用演示:
【软件演示】爬小红薯详情软件
1.3 软件说明
几点重要说明:
以上。
二、代码讲解
2.1 爬虫采集模块
首先,定义接口地址作为请求地址:
# 请求地址
url = 'https://edith.xiaohongshu.com/api/sns/web/v1/feed'
定义一个请求头,用于伪造浏览器:
# 请求头
h1 = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Content-Type': 'application/json;charset=UTF-8',
'Cookie': '换成自己的cookie值',
'Origin': 'https://www.xiaohongshu.com',
'Referer': 'https://www.xiaohongshu.com/',
'Sec-Ch-Ua': '"Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"macOS"' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2619
2619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









