







目录
之前我们在 bfs 中有介绍过[Lc15_bfs+floodfill] 图像渲染 | 岛屿数量 | 岛屿的最大面积 | 被围绕的区域,现在我们来看看 dfs 又是如何解决的呢
0.floodfill算法简介
floodfill算法又叫洪水灌溉或者洪水淹没
- 比如有一个区域,负数表示低谷,0表示平原,正数表示山峰。
- 此时发大水把这些区域淹了。其中平原和山峰可能不会改变,但是低谷水位就要上升。
- 这种类型题目就是,我们要在这个区域中找出水位会上升的区域或者说找到会被洪水淹的区域。
其实这道题说白了就是把 性质相同的一个连通块 找出来。
比如这里就是把所有是负数的连通块找到,注意只能上下左右相连,斜着不能连!
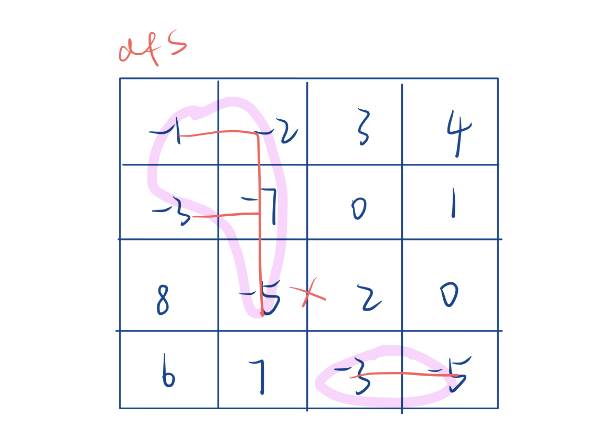
floodfill算法解决的问题就这么简单,它解决方法也非常简单
- 可以用深度优先遍历和宽度优先遍历。
- dfs就是一条路走到黑,如果无法走就回溯到上一层,然后能走就继续走,直到走到一个不能走的位置。(上下左右就是每层的选择,走到叶子节点的时候就找到连通块啦~)
此时就把一个连通区域找到了。
bfs从一个位置开始把和我相连的位置加入到队列里,然后继续在扩一层在扩一层…
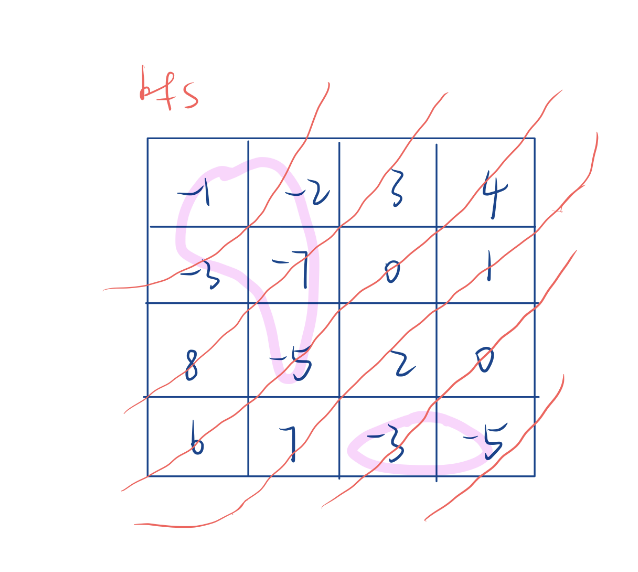
- 因此floodfill算法有两种解决方式,要么dfs、要么bfs。
- 你会发现这个dfs和我们前面单词搜索,黄金矿工解法非常相似,到一个位置之后就上下左右扫描,当和我性质相同就递归进去。
这里主要用的是dfs。bfs在前面的优选算法里面,本质其实就是暴搜。
1.图像渲染
链接:733. 图像渲染
有一幅以 m x n 的二维整数数组表示的图画 image ,其中 image[i][j] 表示该图画的像素值大小。你也被给予三个整数 sr , sc 和 color 。你应该从像素 image[sr][sc] 开始对图像进行上色 填充 。
为了完成 上色工作:
- 从初始像素开始,将其颜色改为
color。 - 对初始坐标的 上下左右四个方向上 相邻且与初始像素的原始颜色同色的像素点执行相同操作。
- 通过检查与初始像素的原始颜色相同的相邻像素并修改其颜色来继续 重复 此过程。
- 当 没有 其它原始颜色的相邻像素时 停止 操作。
最后返回经过上色渲染 修改 后的图像 。
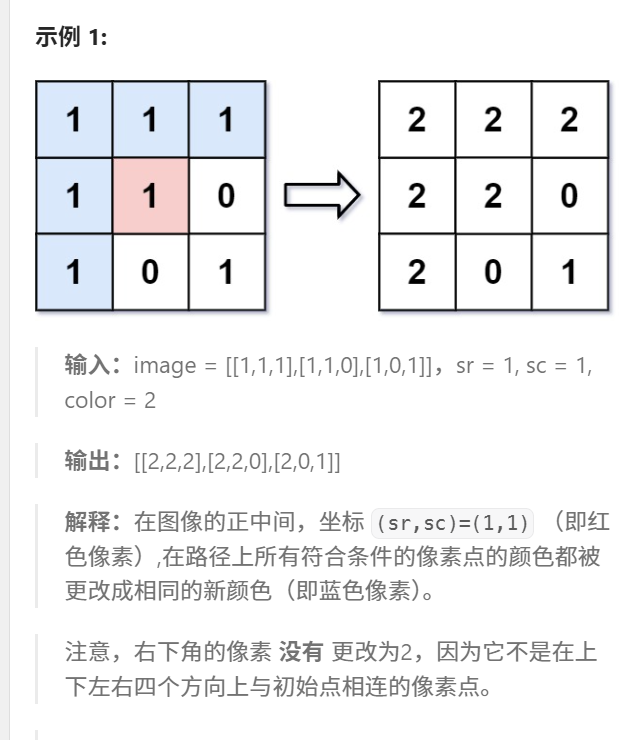
题解
题目说这么多,其实就是给一个矩阵,在给一个初始的坐标,然后把和这小格性质相同的连通块找到然后变成newcolor。注意只能上下左右去找!
- 关于题目的详细解释,可以去的 BFS 相应文章中查看
class Solution {
public:
int dx[4]={0,0,1,-1};
int dy[4]={1,-1,0,0};
int m,n,ret,_color;
vector<vector<int>> floodFill
(vector<vector<int>>& image, int sr, int sc, int color)
{
m=image.size();
n=image[0].size();
ret=image[sr][sc];
image[sr][sc]=color;
_color=color;
if(ret==color) return image; //!!!!边界
dfs(image,sr,sc);
return image;
}
void dfs(vector<vector<int>>& image, int i, int j)
{
for(int k=0;k<4;k++)
{
int x=i+dx[k],y=j+dy[k];
if(x>=0 && x<m && y>=0 && y<n
&& image[x][y]==ret)
{
image[x][y]=_color;
dfs(image,x,y);
}
}
}
};if(ret==color) return image; //!!!!开始前,处理边界
2.岛屿数量
链接:200. 岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
["1","1","1","1","0"],
["1","1","0","1","0"],
["1","1","0","0","0"],
["0","0","0","0","0"]
]
输出:1题解
这道题让找到由陆地构成的岛屿的数量,也就是让找到性质相同的连通块数量。
- 注意只能上下左右找。
- 1代表陆地,0代表水域。
我们一行一行扫描
- 扫描到第一个1的时候,我就把以这个1相连的所有为1的区域都标记一下
- 相当于找到了一块岛屿记录一下。
- 接下来继续扫描。但是有可能会碰到重复的情况,因此这里需要一个bool类型的数组 标记当前位置是否被找过。
- 或者可以修改原始值把它由1变成0。这里我们还用的是老方法bool类型数组。
之前走过下一就不能在走了。
class Solution {
public:
int dx[4]={0,0,1,-1};
int dy[4]={1,-1,0,0};
int ret=0,m,n;
vector<vector<bool>> check;
int numIslands(vector<vector<char>>& grid)
{
m=grid.size();
n=grid[0].size();
check.resize(m,vector<bool>(n,false));
for(int i=0;i<m;i++)
{
for(int j=0;j<n;j++)
{
if(!check[i][j] && grid[i][j]=='1')
{
check[i][j]=true;
ret++;
dfs(grid,i,j);
}
}
}
return ret;
}
void dfs(vector<vector<char>>& grid,int i,int j)
{
for(int k=0;k<4;k++)
{
int x=i+dx[k],y=j+dy[k];
if(x>=0 && x<m && y>=0 && y<n
&& !check[x][y] &&grid[x][y]=='1')
{
check[x][y]=true;
dfs(grid,x,y);
}
}
}
};- 一,这里的 grid 里是 char('1')
- 二,要注意一下无论是起始,还是结束都要对 check 进行一个判断,来防止进入死循环

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









