






进行爬虫的入门教程,主要是爬取网页的图片并且下载到本地
准备工作以及使用requests模块
准备工作:安装python和pycharm
浏览器工具:1.(打开浏览器并按F12即可打开开发者工具)
2.主要用到的工具有:Element,Console(Js逆向调试),Source(网页中的资源
所在),Network(抓包工具)。
一般来说,网页访问时,第一次发送请求到服务器,会返回html代码(空壳),
第二次至第n次才是返回数据。
爬虫工具:requests模块(需要安装),
可在pycharm的左下角点击terminals,输入 pip install requests 即可安装

安装成功后再次安装会显示已经安装(第一次安装会显示安装成功。)
1.使用requests请求发送Get请求和Post请求
(1)在Network中查看请求方式,决定使用Get请求还是Post请求
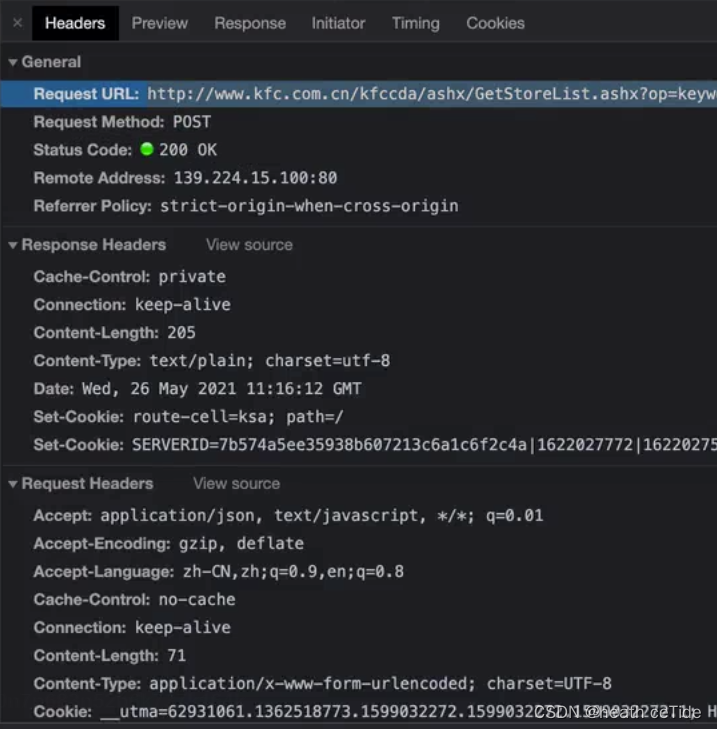
(2)发送Get请求(一般情况下是获取html的源代码)【此处以4399小游戏网站为例】
import requests
url = "http://www.4399.com"
#地址为4399游戏网站
resp = requests.get(url)
#发送Get请求
resp.encoding = 'gbk'
#规定编码方式,防止出现乱码(根据不同网站本身的编码方式写)
print(resp.text)
#打印出该网站的html源代码
with open("my4399.html", mode="w", encoding='gbk') as f:
f.write(resp.text)
#将获取的源代码写在文件上
print("over")(3)发送Post请求(一般是返回数据)【此处以百度翻译的网站为例】
import requests
url = "https://fanyi.baidu.com/sug"
data = {
"kw": input("请输入一个你想翻译的单词")
}
#此处的kw为参数(可通过查看Network的XHR看到参数是什么),输入后会返回相应的翻译后的数据
resp = requests.post(url, data=data)
#此处返回的是json数据
print(resp.json())
#若得到的是json数据,则直接用resp.json()即可得到数据了
正则表达式以及re模块
正则表达式(用来匹配字符串的表达式语言)
相关使用网站:https://tools.oschina.net/regex/
- 正则表达式支持普通字符
- 元字符:(可以用一个字符匹配多个内容)
\d用来匹配所有数字(0~9) \w能够匹配数字(0~9),字符(a~z),下划线_(无法匹配汉字)
\W,和\D的意思是与他们的小写取反(\W的意思是除了\w的都满足)
精准匹配:[abc]可以匹配带有a或者b或者c的
[^abc]表示取反,除了abc的都可以匹配。
3.量词(控制元字符出现的频次)
+表示前面的元字符出现一次或者多次 如(\d+)
*表示前面的元字符出现零次或者多次
?表示前面的元字符出现零次或者一次
4.惰性匹配(主要有两个A.*B找由A开始,B结束的最远的一个,A.*?B表示从A开始,B结束的最短的一个)
python内置re模块(写正则表达式)
提供的方法有
- re.findall() 少量数据时使用
- re.search() 只输出一个(单个数据时使用)
- re.finditer() 迭代器(适合大量数据时使用)
- re.compile() 预加载
import requests
import re
url = "http://www.4399.com"
resp = requests.get(url)
resp.encoding = 'gbk'
result = re.findall(r"\d", resp.text)
#re的方法中都是(r"正则表达式", "文本")
print(result)
#由此可以打印出网站中的数字通过正则表达式可以获取到自己需要的数据。
xpath入门以及爬取图片的链接地址
xpath介绍:是针对xml的表达式语言,可从xml中直接提取数据
而我们要获取的html属于是xml的子集,那么xpath自然也可以获取到html的内容了
xpath的下载:在terminals上面下载 pip insatll lxml
引入时写from lxml import etree(如果报错可以写from lxml import etree换行
etree = html.etree)
resp = requests.get(url)
resp.encoding = "gbk"
et = etree.HTML(resp.text)
hrefs = et.xpath("//ul[@class='pic-list2 clearfix']/li/a/@href")
# 处理一下href. 需要添加域名
new_hrefs = []
for href in hrefs:
new_hrefs.append(domain + href)
return new_hrefs
通过et.xpath()即可获取到链接地址以及文本等。
简单案例的总代码:
import requests
from lxml import etree
import re
import json
from concurrent.futures import ThreadPoolExecutor
domain = "https://desk.zol.com.cn"
def get_detail_href(url):
"""
该函数负责获取到每一个详情页的href的值
"""
resp = requests.get(url)
resp.encoding = "gbk"
et = etree.HTML(resp.text)
hrefs = et.xpath("//ul[@class='pic-list2 clearfix']/li/a/@href")
# 处理一下href. 需要添加域名
new_hrefs = []
for href in hrefs:
new_hrefs.append(domain + href)
return new_hrefs
def get_img_srcs(href):
"""
访问每一个详情页. 得到每个详情页背后对应的一组图片的下载路径
"""
resp = requests.get(href)
resp.encoding = "gbk"
obj = re.compile(r"var deskPicArr.*?=(?P<desk_str>.*?);", re.S)
# 提取页面中关于图片路径的信息
result = obj.search(resp.text).group("desk_str")
desk_dict = json.loads(result) # 把页面中提取到的字符串处理成字典
img_src_list = []
for item in desk_dict['list']:
ori = item.get("oriSize")
img_src = item.get("imgsrc")
img_src = img_src.replace("##SIZE##", ori)
img_src_list.append(img_src)
return img_src_list
def download_img(img_src):
"""
下载图片
:param img_src: xxxx
"""
name = img_src.split("/")[-1]
print(f"开始下载{name}")
resp = requests.get(img_src)
with open(f"img/{name}", mode="wb") as f:
f.write(resp.content)
print(f"{name}下载完毕!")
def main():
for i in range(1, 10):
url = "https://desk.zol.com.cn/pc/"
if i !=1 :
url = url + f"{i}.html"
print(url)
# 1. 抓取到首页中每个详情页的href
print("抓取到首页中每个详情页的href......")
hrefs = get_detail_href(url)
print("抓取到首页中每个详情页的href......搞定!")
print("访问每一个详情页. 得到每个详情页背后对应的一组图片的下载路径")
img_list = [] # 装着所有的图片下载地址
for href in hrefs:
# 2. 访问每一个详情页. 得到每个详情页背后对应的一组图片的下载路径
img_src_list = get_img_srcs(href)
for img in img_src_list:
img_list.append(img)
print("访问每一个详情页. 得到每个详情页背后对应的一组图片的下载路径....搞定!!!")
# 3. 开始下载图片
with ThreadPoolExecutor(20) as t:
for img in img_list: # img: 图片下载路径
t.submit(download_img, img)
print("all over!!!")
if __name__ == '__main__':
main()

















 973
973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









