








一、类的内存对齐
1.1规则
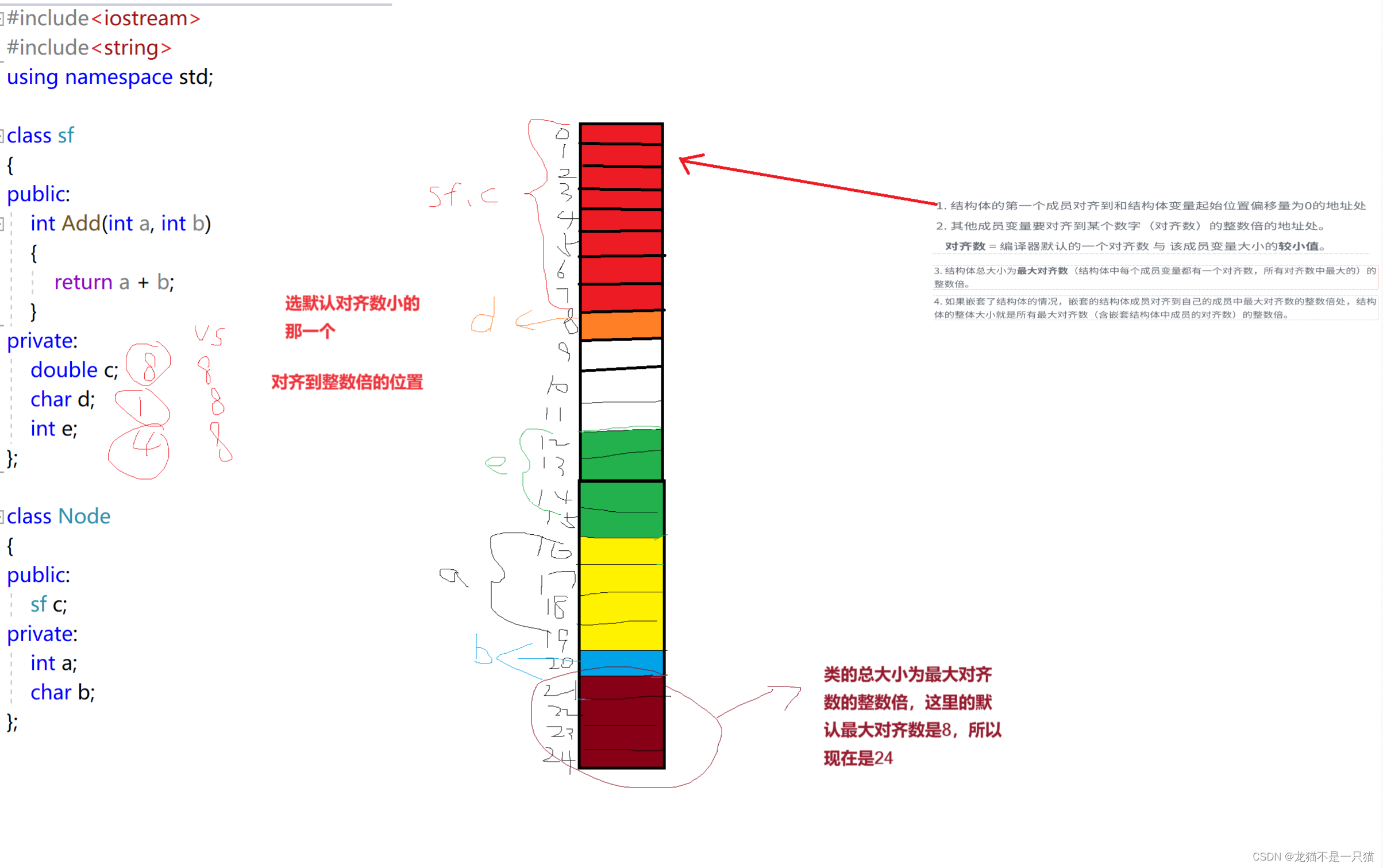
1.类的第一个成员对齐到和类的起始位置偏移量为0的地址处
2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的一个对齐数与该成员变量的大小的较小值
——VS中默认对齐数为8
——Linux中gcc没有默认对齐数,对齐数就是成员自身的大小
3.类的总大小为最大对齐数(类中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍。
4.如果出现类的嵌套,嵌套的类的成员对齐到自己的成员中最大对齐数的整数倍处
offsetof(type,成员)计算偏移量

1.2原因
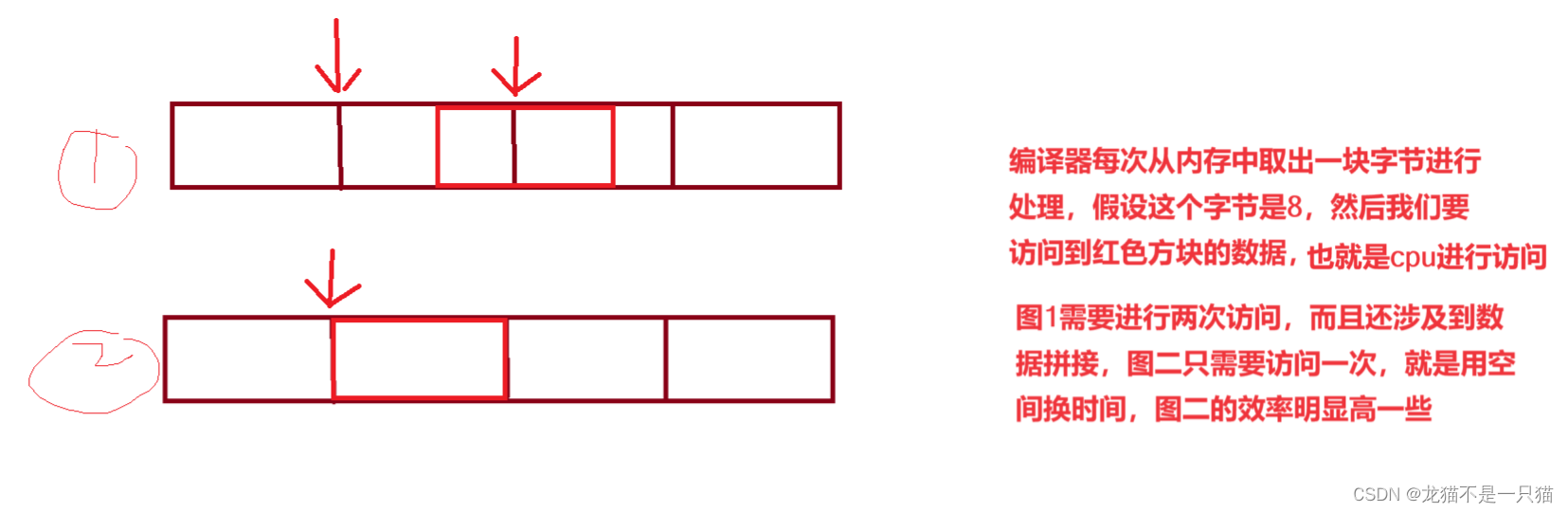
1.不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常
2.数据结构(尤其是栈)应该尽可能的在边界对齐。因为为了访问未对齐的内存,编译器需要进行两次访问,对齐了的内存,编译器只需要进行一次访问。
二、位段
2.1介绍
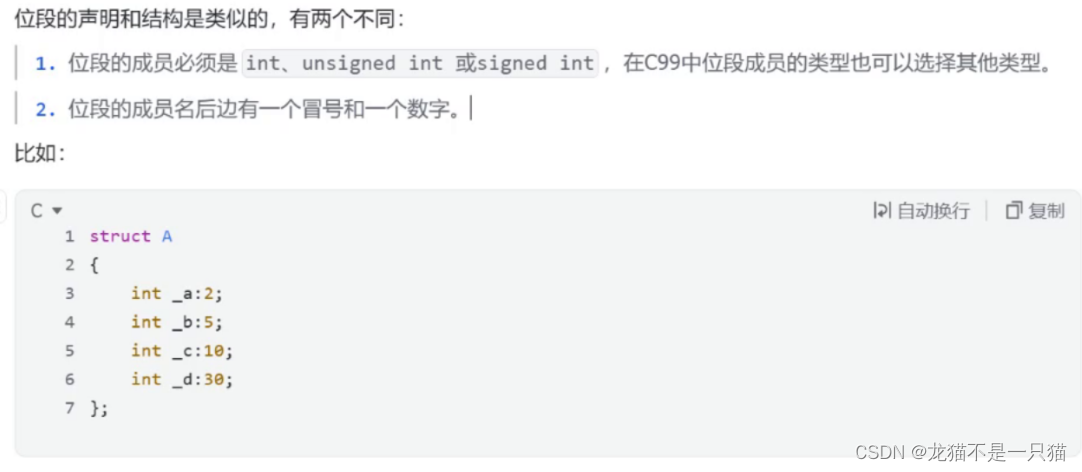
2.2内存分配问题
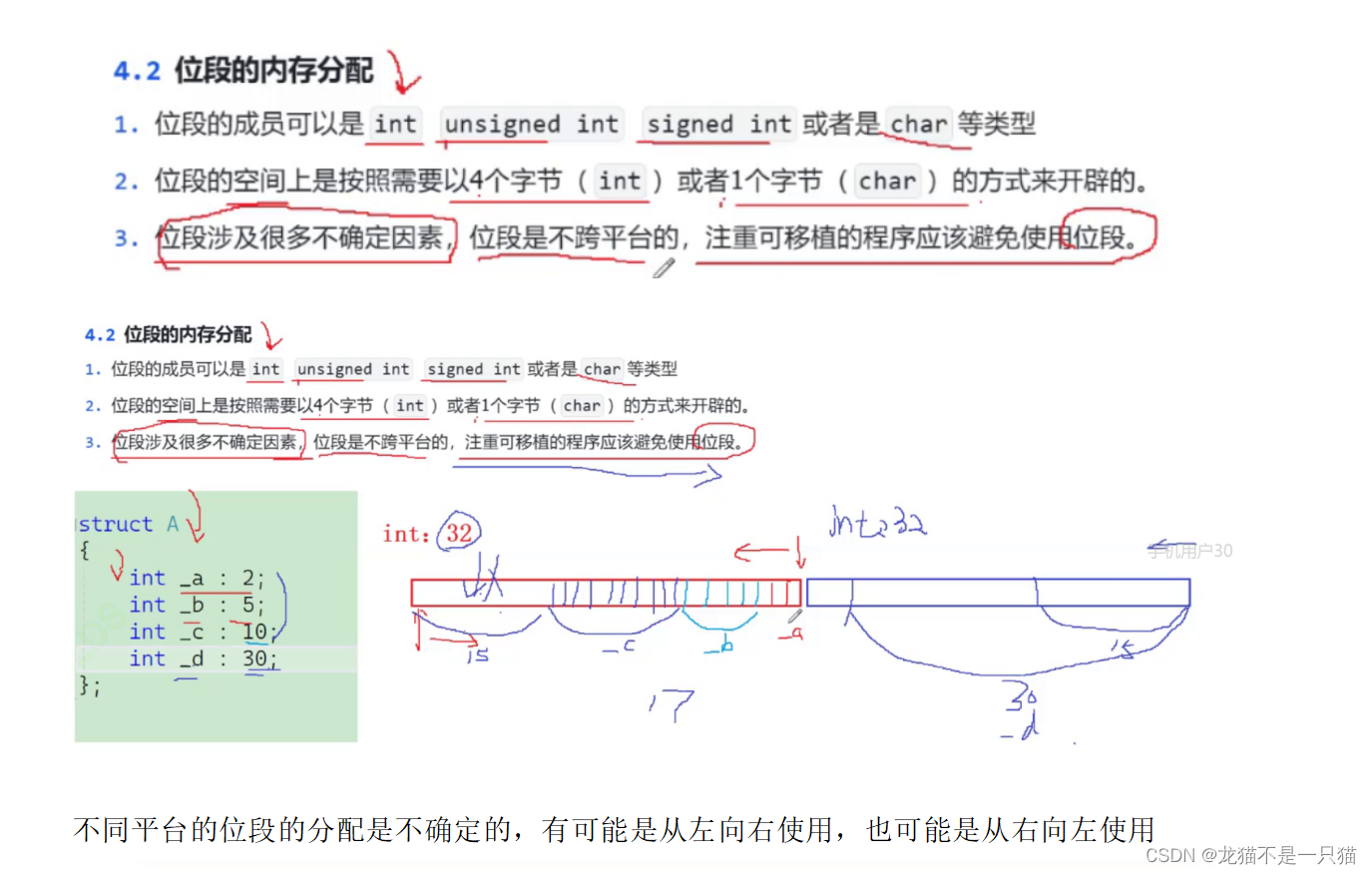
2.3跨平台问题

2.4使用的注意事项

三、位图的应用
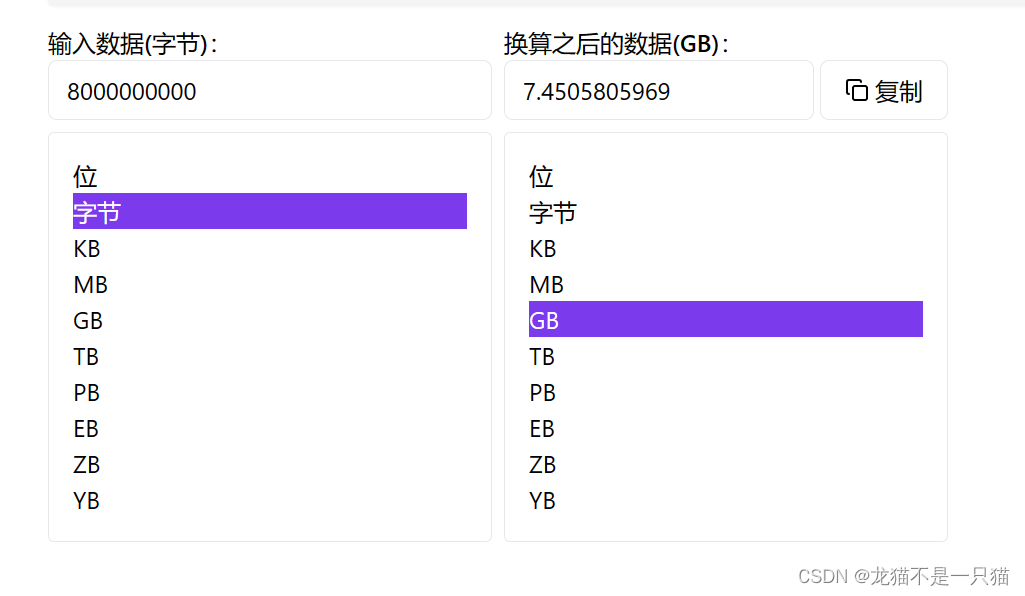
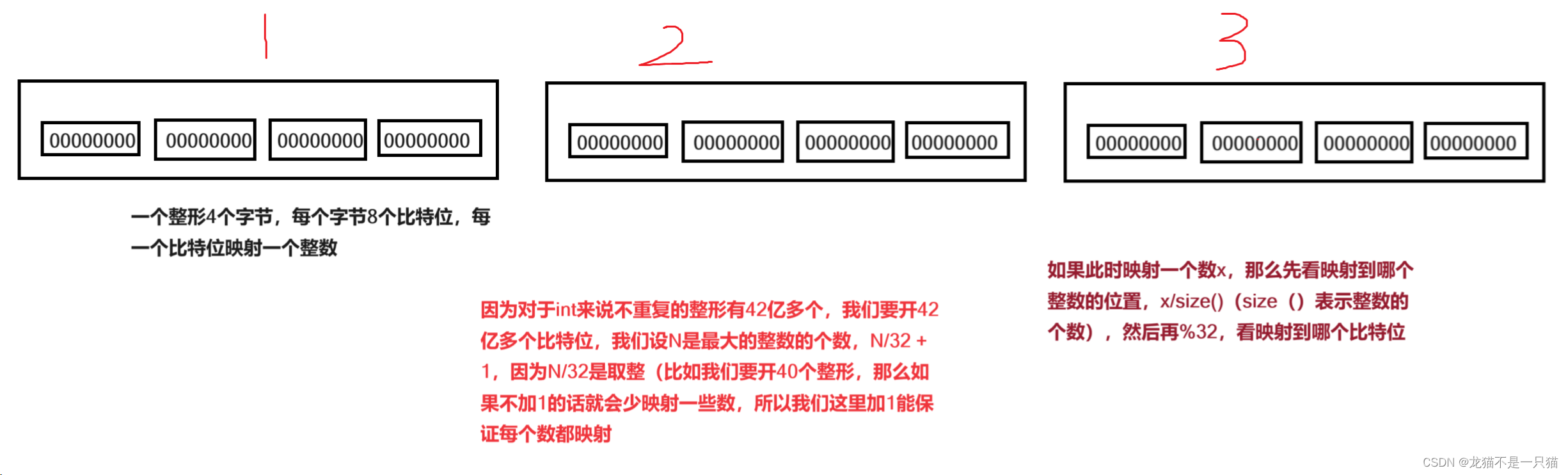
3.1 给40亿个不重复的无符号整数,找给定的一个数。(int的范围可以到达42亿多)
方法1(不可取):用二分的方法,80亿个字节大概需要7.4个G,没有那么大的存储空间,虽然二分的查找效率很高,但是需要数据处于有序的状态
方法2:位图
我们利用哈希桶的原理,用每一个数映射一个比特位,大概42亿个比特位,加起来应该是0.5个G左右,这样消耗的内存低,并且每一个数映射一个比特位,又保证了查找效率O(1)
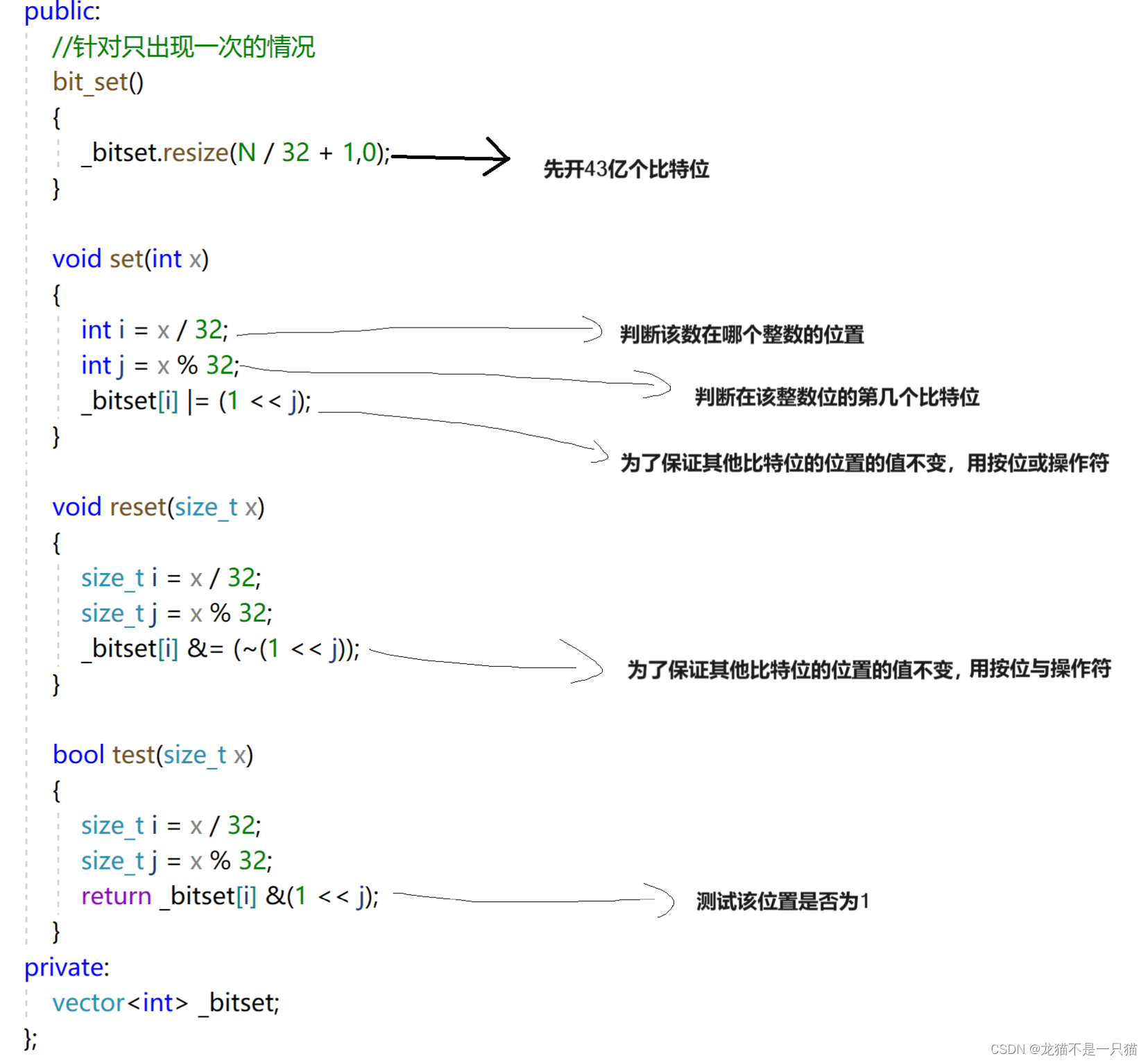
3.2 给定100亿个整数,设计算法找到只出现一次的整数
用两个位图来表示这个整数出现的次数

3.3给两个文件,分别有100亿个整数,我们只有1G的内存,如何找到两个文件的交集
同上
3.4位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过两次的所有整数
同上
四、布隆过滤器
4.1作用和介绍
作用:可以提高测试数据在该数据库中是否存在,如果有上千百亿的数据都从数据库中寻找的话,那么效率就会非常非常低,用了布隆过滤器之后,可以排除掉一部分不在数据库里面的数据。
介绍:布隆过滤器就是一个字符串映射多个位,这个可以大大减少误判的可能性,一个字符串映射多个位可以降低误判的可能性,但是此时的空间效率就降低了,布隆过滤器的实质目的就是为了提高空间效率,这样得不偿失,我们只能根据适用情况判断到底映射几个位
4.2误判的概率与什么有关?
1.与映射的哈希函数的个数有关
2.与映射的位有关
3.与哈希函数的特性有关
4.3布隆过滤器的实现
用三种不同的哈希函数进行实现,一共映射3个比特位

五、哈希切割
5.1给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
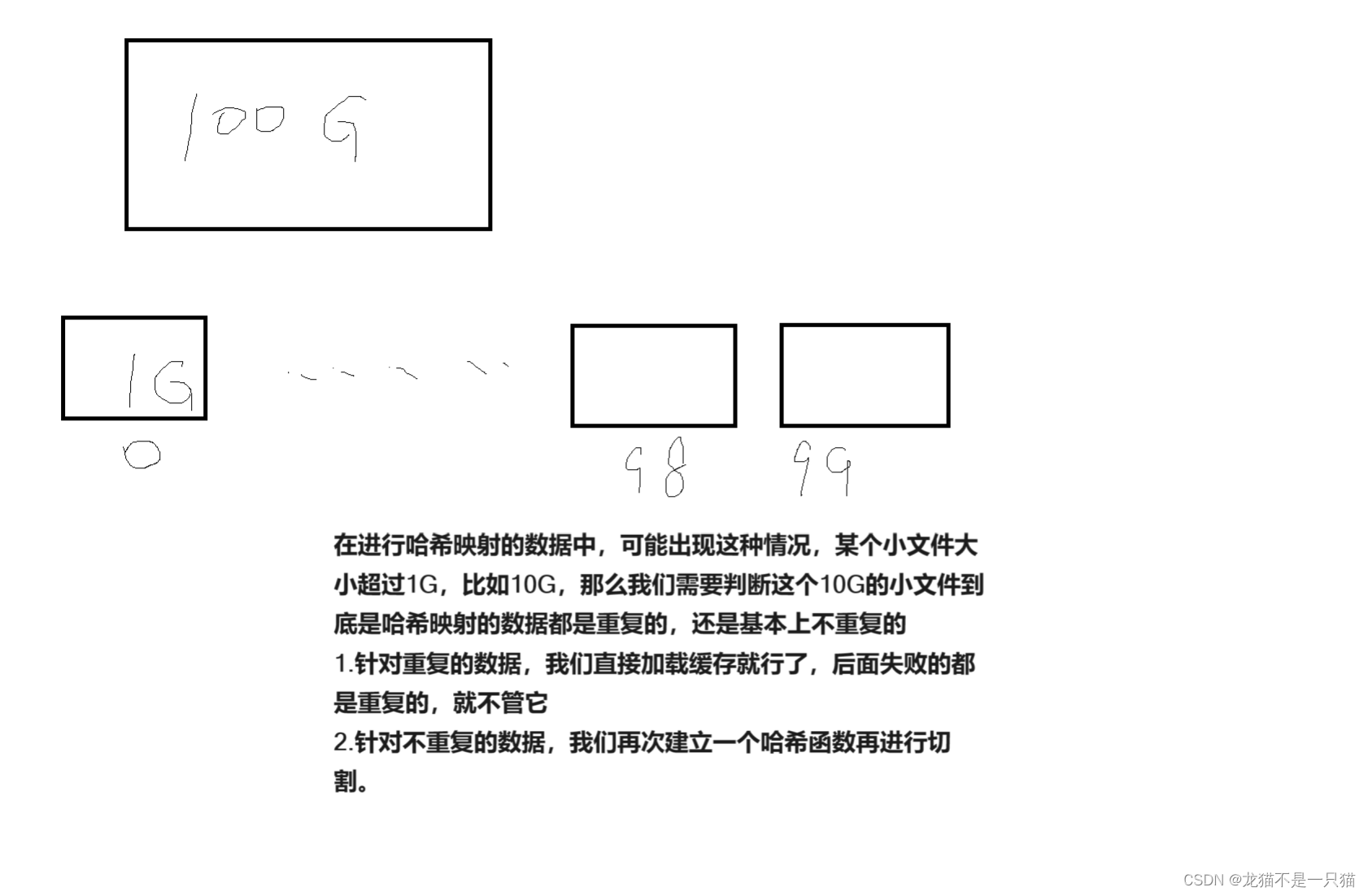
5.2给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?
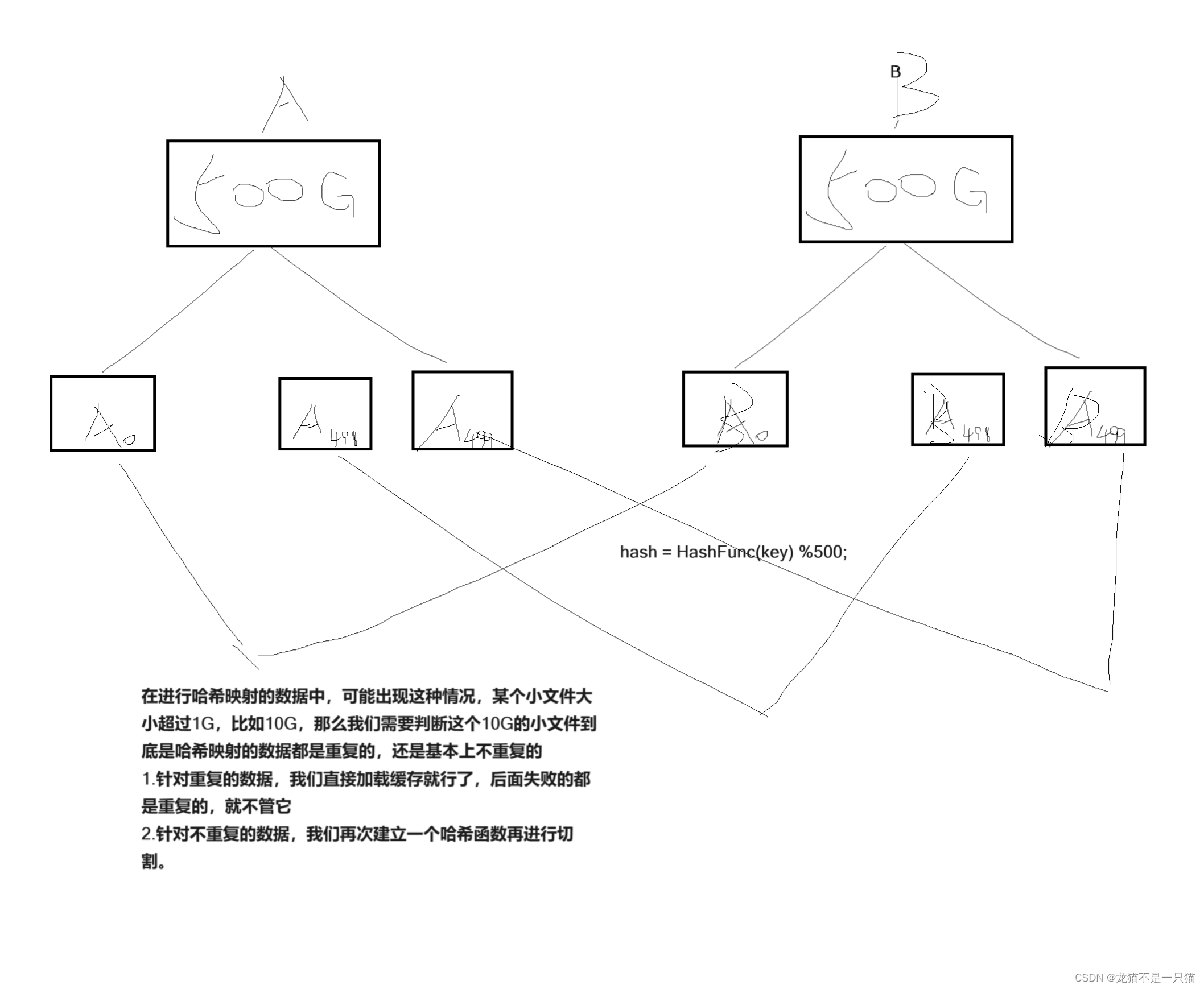
六、一致性哈希
下面这篇别人讲的文章非常详细,可参考
一致性哈希的文章



















 1181
1181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











