







1.总体思路
在我们平时所遇到的链表根据三个维度可以进行如下划分:单向与双向;带头与不带头;循环与非循环。
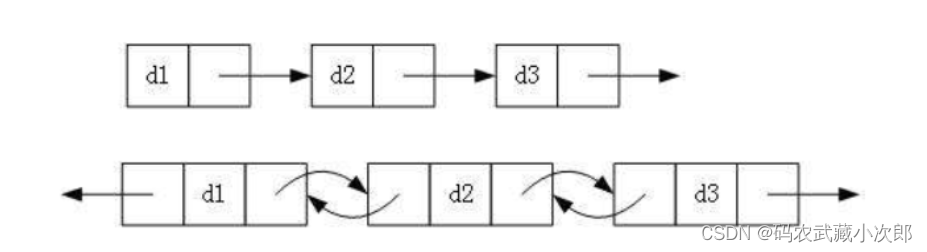
单向与双向
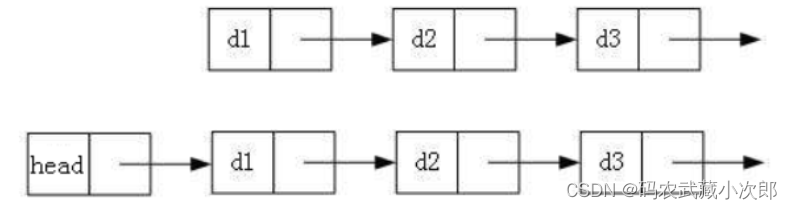
带头与不带头

循环与非循环
我们经过对单链表的学习不难发现,单向不带头非循环链表虽然看似结构简单,在力扣牛客上很常见,但是我们不能发现这种链表在处理头删、尾删、头插、尾插时对条件判断的繁琐和代码的冗长。这时候我们难免想去做出一些改动,因此双向带头非循环链表产生了。
2.代码实现
①类型声明
typedef int MyType;
typedef struct ListNode
{
MyType data;
struct ListNode* next;
struct ListNode* prev;
}LT;(将int类型typedef为MyType的好处是如果以后要将整型改为浮点型只需要在typedef处修改即可,操作简单)
②函数声明
LT* InitLT(void);
void LTPushFront(LT* phead, MyType x);//头插
void LTPopFront(LT* phead);//头删
void LTPushBack(LT* phead, MyType x);//尾插
void LTPopBack(LT* phead);//尾插
void LTInsert(LT* pos, MyType x);//中间pos位置前插入
void LTDelete(LT* pos);//删除pos位置处结点
void LTPrint(LT* phead);//打印链表
(增删查改是链表的常用操作)
③创建新结点
LT* CreateNewNode(MyType x)
{
struct ListNode* newnode = (LT*)malloc(sizeof(LT));
assert(newnode);
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}(无论是哪种插入都需要创建新结点,后续都会调用这一部分所以我们为了降低耦合性,把搭建新结点单独分装成一个函数)
④在pos结点前新结点
void LTInsert(LT* pos, MyType x)
{
assert(pos);
LT* newnode = CreateNewNode(x);
struct ListNode* prev = pos->prev;
prev->next = newnode;
newnode->prev = prev;
newnode->next = pos;
pos->prev = newnode;
}(之所以先写在中间位置插入的函数,是因为有了中间插入函数之后,头插和尾插将会变得很简单,这也正是双向带头循环链表的优越性)
⑤在头结点插入
void LTPushFront(LT* phead, MyType x)
{
if (phead->next == phead)
{
LT* newnode = CreateNewNode(x);
phead->next = newnode;
newnode->prev = phead;
newnode->next = phead;
phead->prev = newnode;
}
else
{
LTInsert(phead->next, x);
}
}(需要注意点在于只有头结点,即只含哨兵位的结点时,不能调用LTInsert函数)
⑥在尾结点后面插入
void LTPushBack(LT* phead, MyType x)
{
if (phead->prev == phead)
{
struct ListNode* newnode = CreateNewNode(x);
phead->prev = newnode;
phead->next = newnode;
newnode->next = phead;
newnode->prev = phead;
}
else
{
LTInsert(phead, x);
}
}⑦删除pos处的结点
void LTDelete(LT* pos)
{
assert(pos);
struct ListNode* posPrev = pos->prev;
struct ListNode* posNext = pos->next;
free(pos);
posPrev->next = posNext;
posNext->prev = posPrev;
}⑧删除头结点
void LTPopFront(LT* phead)
{
assert(phead);
struct ListNode* first = phead->next;
assert(first!= phead);
struct ListNode* second = first->next;
phead->next = second;
second->prev = phead;
free(first);
first = NULL;
/*assert(phead);
struct ListNode*first=phead->next;
assert(first!=phead);
LTDelete(first)*这是第二种写法,直接调用前面的LTDelete函数*/
}⑨删除尾结点
void LTPopBack(LT* phead)
{
assert(phead);
struct ListNode* last = phead->prev;
assert(last != phead);
struct ListNode* prev = last->prev;
prev->next = phead;
phead->prev = prev;
free(last);
last = NULL;
/* 第二种写法 assert(phead);
struct ListNode*last=phead->prev;
assert(last!=phead);
LTDelete(last);*/
}⑩打印链表
void LTPrint(LT* phead)
{
printf("head<=>");
struct ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d<=>", cur->data);
cur = cur->next;
}
printf("\n");
}3.代码演示
void Test(void)
{
LT* head = InitLT();
LTPrint(head);
LTPushFront(head, 1);
LTPrint(head);
LTPushFront(head, 2);
LTPrint(head);
LTPushBack(head, 2);
LTPrint(head);
LTPushBack(head, 3);
LTPrint(head);
LTPushBack(head, 4);
LTPrint(head);
LTPushBack(head, 5);
LTPrint(head);
LTPushBack(head, 6);
LTPrint(head);
LTPushBack(head, 7);
LTPrint(head);
LTPopBack(head);
LTPrint(head);
LTPopBack(head);
LTPrint(head);
LTPopBack(head);
LTPrint(head);
LTPopBack(head);
LTPrint(head);
}
int main()
{
Test();
return 0;
}调用以上test函数测试,测试结果如下:
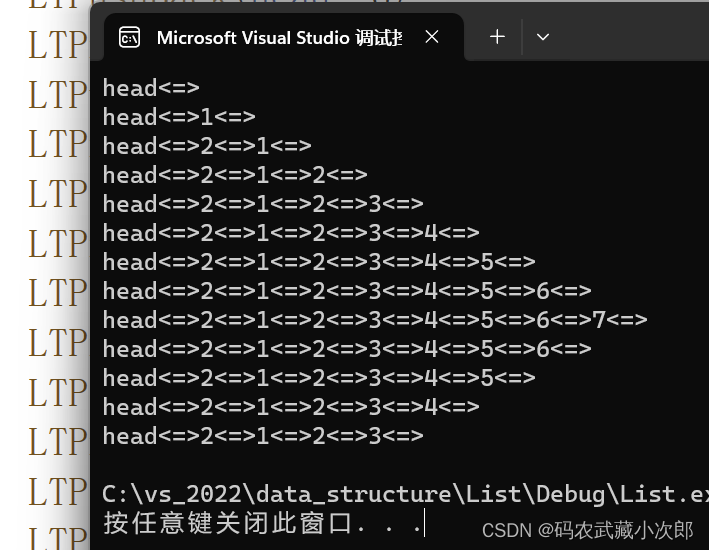
4.反思总结
通过双链表的代码实现,结合单链表的使用体验我们不免有这样的感受:单向不带头非循环链表就像是抽血时抽手指血,看似简单实则很痛;而双向带头循环链表就像是抽静脉血,看似高级实则并不痛苦。双向带头循环链表在各种插入删除方面都有其优势,所以日后我们可以多多使用双链表来存储数据,以达到简洁明了。
(作者第一篇文章,有所不足希望能在评论区指正,另外,跪求关注,老爷们的每个关注都很重要,求求啦)

















 6377
6377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









