







前言
在 Python 中,搜索算法用于在数据集合中查找特定元素。常见的搜索算法包括 线性搜索、二分搜索、哈希搜索 等。
一、线性搜索(Linear Search)
1. 原理
从数据集合的第一个元素开始,逐个检查每个元素,直到找到目标元素或遍历完整个集合。
2. 实现
def linear_search(arr, target):
for i, value in enumerate(arr):
if value == target:
return i # 返回目标元素的索引
return -1 # 未找到目标元素3. 特点
-
时间复杂度:O(n)
-
适用场景:无序数据集合
-
优点:简单直观,适用于小规模数据
-
缺点:效率低,不适合大规模数据
4. 示例
arr = [3, 5, 2, 8, 10]
target = 8
print(linear_search(arr, target)) # 输出: 3二、二分搜索(Binary Search)
1. 原理
在 有序 数据集合中,通过不断将搜索范围缩小一半来查找目标元素。
2. 实现
def binary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid # 找到目标元素
elif arr[mid] < target:
left = mid + 1 # 目标在右半部分
else:
right = mid - 1 # 目标在左半部分
return -1 # 未找到目标元素3. 特点
-
时间复杂度:O(log n)
-
适用场景:有序数据集合
-
优点:效率高,适合大规模数据
-
缺点:要求数据必须有序
4. 示例
arr = [2, 3, 5, 8, 10]
target = 8
print(binary_search(arr, target)) # 输出: 3三、哈希搜索(Hash Search)
1. 原理
利用哈希表(字典)存储数据,通过哈希函数快速定位目标元素。
2. 实现
def hash_search(arr, target):
hash_table = {value: index for index, value in enumerate(arr)}
return hash_table.get(target, -1) # 返回目标元素的索引,未找到返回 -13. 特点
-
时间复杂度:
-
平均:O(1)
-
最差:O(n)(哈希冲突时)
-
-
适用场景:需要快速查找的数据集合
-
优点:查找速度快
-
缺点:需要额外空间存储哈希表
4. 示例
arr = [3, 5, 2, 8, 10]
target = 8
print(hash_search(arr, target)) # 输出: 3四、深度优先搜索(DFS)
1. 原理
用于遍历或搜索树或图结构,沿着一条路径尽可能深地搜索,直到达到目标或无法继续为止。
2. 实现
def dfs(graph, start, target, visited=None):
if visited is None:
visited = set()
visited.add(start)
if start == target:
return True
for neighbor in graph[start]:
if neighbor not in visited:
if dfs(graph, neighbor, target, visited):
return True
return False3. 特点
-
时间复杂度:O(V + E)(V 为顶点数,E 为边数)
-
适用场景:树或图的路径搜索
-
优点:适合寻找所有可能的解
-
缺点:可能陷入无限循环(需记录已访问节点)
4. 示例
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
print(dfs(graph, 'A', 'F')) # 输出: True五、广度优先搜索(BFS)
1. 原理
用于遍历或搜索树或图结构,逐层扩展搜索,直到找到目标。
2. 实现
from collections import deque
def bfs(graph, start, target):
queue = deque([start])
visited = set([start])
while queue:
node = queue.popleft()
if node == target:
return True
for neighbor in graph[node]:
if neighbor not in visited:
visited.add(neighbor)
queue.append(neighbor)
return False3. 特点
-
时间复杂度:O(V + E)(V 为顶点数,E 为边数)
-
适用场景:树或图的路径搜索,特别是最短路径问题
-
优点:找到的路径一定是最短的
-
缺点:空间复杂度较高
4. 示例
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
print(bfs(graph, 'A', 'F')) # 输出: True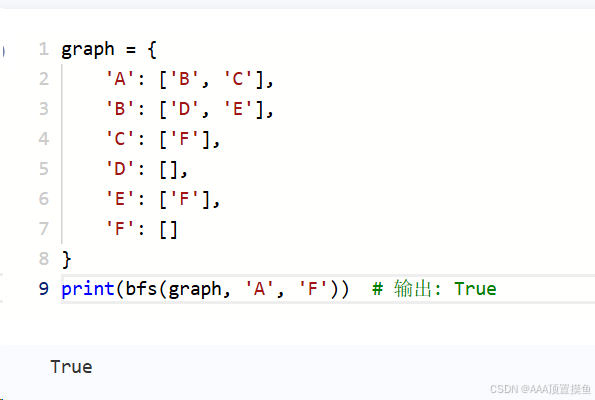
六、总结
| 算法 | 时间复杂度 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 线性搜索 | O(n) | 无序数据集合 | 简单直观 | 效率低 |
| 二分搜索 | O(log n) | 有序数据集合 | 效率高 | 要求数据有序 |
| 哈希搜索 | O(1)(平均) | 快速查找 | 查找速度快 | 需要额外空间 |
| 深度优先搜索 | O(V + E) | 树或图的路径搜索 | 适合寻找所有可能的解 | 可能陷入无限循环 |
| 广度优先搜索 | O(V + E) | 树或图的最短路径搜索 | 找到的路径一定是最短的 | 空间复杂度较高 |
选择建议:
-
如果数据无序且规模小,使用线性搜索。
-
如果数据有序,使用二分搜索。
-
如果需要快速查找,使用哈希搜索。
-
如果是树或图结构,使用 DFS 或 BFS。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









