







文章目录
什么是操作系统
- 操作系统 Operating System 是一组控制和管理计算机 硬件 和 软件 资源合理地对各类作业进行 调度,方便用户使用计算机的程序集合。
- 操作系统的核心目标是,使系统资源的利用率高,系统的吞吐量大。
操作系统的形成
用户想要调用硬件,需要使用硬件的驱动程序,那么如果换了硬件就需要更换驱动,这样可移植性差,于是出现了操作系统。
操作系统负责提供设备驱动框架来驱动不同的底层设备,同时提供了用户接口框架给上层用户。
后来操作系统一并将软件驱动纳入,形成软件操作系统。

从程序看OS
提出问题:从hello world文件开始
- hello world文件在磁盘中是怎么存储的?
- 怎么存决定了怎么读
- 利用文件系统
- .c文件怎么变成让CPU认识的指令的?
2.1 是否这些指令所有CPU都认识呢?
2.2 是否编译成0101这种二进制文件系统就能运行了呢?- 我们现在的编程大多是 基于OS的程序设计
- 而还有一种就是裸机编程,程序可以不需要操作系统直接调动硬件
- 软件多次运行或者同时运行,CPU如何管理多个任务的?
- 对于运行时的数据如何进行内存存放,内存如何管理?
总结下来就是,操作系统如何进行:
- 管理CPU —— 进程和线程 —— 调度与同步机制
- 管理内存 —— 内存管理
- 管理磁盘 —— 文件系统
- 管理IO —— IO设备
目前编译器帮我们解决了诸多问题
编译器帮助我们解决了前两个问题:管理CPU和管理内存。
- 调用进程线程来运行程序
- 编译器链接内存地址
调用指令
gcc -v
可以看到如下信息:
目标:x86_64-redhat-linux
说明gcc编译的指令集是面向x86架构的CPU,作用于linux操作系统的
gcc(编译器)解决了文件对于不同架构的CPU与不同的操作系统的问题。
gcc的编译过程
指令:
gcc helo.c -E -o a.i # 将hello.c文件预处理
gcc a.i -S -o a.s # 对预处理后的文本文件进行编译
gcc a.s -c -o a.o # 对汇编文件进行汇编,生成二进制文件
gcc a.o -o a.out # 对各种库和文件进行链接,生成可执行文件
cc1 hello.c -o /tmp/cceVNE1I.s # 编译器ccl gcc -S
as -o /tmp/cc8ATX9H.o /tmp/cceVNE1I.s # 汇编器as gcc -c
ld -o build /tmp/cc8ATX9H.o ...../*.o -lc # 链接器ld gcc
指令:
file a.out
可以调出可执行文件适用的CPU,操作系统等信息
CPU的运作

CPU通过缓存对内存进行调度,其中,内存分为两种:
- 数据内存:存放数据。
- 控制器:
- 在硬件通信中,需要高低电压的信号来互相通信,而高低电压的持续时间需要软件控制,而代码中会需要进行休眠来控制电压持续时间,如果CPU自己来做,就会造成CPU休眠(死机),所以创造出了控制器。
- CPU告诉控制器,我需要什么类型的信号,由控制器进行操作,这样就能让CPU在控制器发信号和休眠的时间内做其他事情了。
CPU对任务的切换
CPU在执行程序的时候,如何实现对任务的切换呢?
例如,对一个C程序:
#include <stdio.h>
int reslut() {
int a = 1;
int b = 2;
return a + b;
}
int main() {
int k = reslut();
return 0;
}
- CPU开始执行main()
- 跳转到reslut()
- 在CPU的寄存器内记录下a, b的数据,然后进行运算
- 跳转回main()
那CPU是怎么知道要跳转到哪里的?
- CPU的寄存器中有一个名叫程序计数器(Program Counter, PC),程序计数器指示了下一条需要从内存中提取的指令的地址。当指令被提取后,程序计数器会自动更新为下一条需要提取的指令的地址,从而确保指令能够按正确的顺序执行。
- 另一个重要的寄存器是 栈指针(Stack Pointer, SP)。栈指针指向内存中当前栈的顶端。它包含了函数调用过程中传递的参数、局部变量以及未保存在寄存器中的临时变量。通过堆栈指针,CPU可以管理函数调用期间的数据和返回地址。
- 在进行多任务时,由于CPU内寄存器只有那么多,所以在切换任务前,PC 指针会保存当前任务的下一条语句的地址,然后将栈指针SP以及栈内的数据保存到内存的TCB任务控制块中,之后再跳转到另一个任务中。在任务完毕时,根据PC指针位置跳转,然后将对应数据从内存下载到栈内,这就是CPU和内存间的load/store操作。
- 任务切换,也称上下文切换(Context Switch)
CPU的四个重要组成
- 指令集:由CPU结构特点决定
- 资源:寄存器
- 工作模式
- 中断模式和系统调用
CPU提供两种模式:
- 特权模式 :也称为内核模式(Kernel Mode),是CPU可以执行所有指令和访问所有资源的模式。在这个模式下,CPU可以直接访问硬件、管理内存和执行系统级操作。
- 非特权模式 :也称为用户模式(User Mode),是CPU在执行普通用户程序时的模式。在此模式下,程序只能访问有限的资源,无法直接进行敏感操作或访问硬件。
对于不同的模式,也会有不同的寄存器。一般情况下,大家都公用寄存器,但是有些模式下,会有专属寄存器,当这个寄存器存储此模式的栈指针SP,就会有它独属的上下文。
PSW状态寄存器
在程序中,经常会有分支、判断,那么CPU如何知道判断后的状态如何呢?
CPU还有一个寄存器是 程序状态字寄存器(Program Status Word, PSW),用于记录状态。对于程序中的左值,右值等数据都是不会记录的,而是将结果写入状态寄存器,保存数据判断的结果。
寄存器的总结
寄存器分为:
-
普通寄存器
-
特殊功能寄存器
- PC寄存器:保存下一个任务的地址
- SP寄存器:保存数据存放的栈指针
- PSW寄存器:保存状态记录
寄存器的保护
那么在一个程序执行中,如果切换任务或中断时,那么PC、SP和PSW需要压栈存入内存保护起来。
在任务执行完毕时,这三个值就不需要保护了。
CPU的工作过程
CPU对任务的执行分三步:
- 取指
- 解码
- 执行
一开始这三步顺序执行,之后为了提升效率,CPU同时执行这三步,所以这种组织形式被称为 “流水线(pipeline)”。
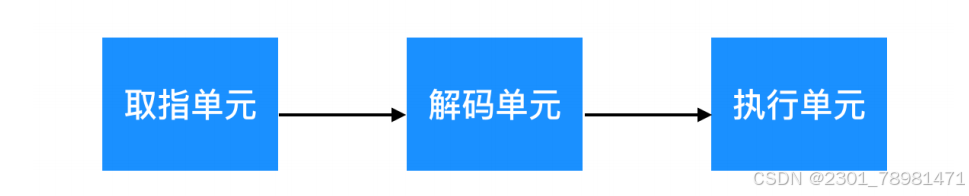
由于判断、循环的存在,如果经过取指、解码后得出的结果是不执行,那就浪费了资源和时间,所以现在的高级CPU都是有指令预测功能,中间多达十几道工序来最大化效率。
比流水线还要先进的是 超标量(superscalar) CPU
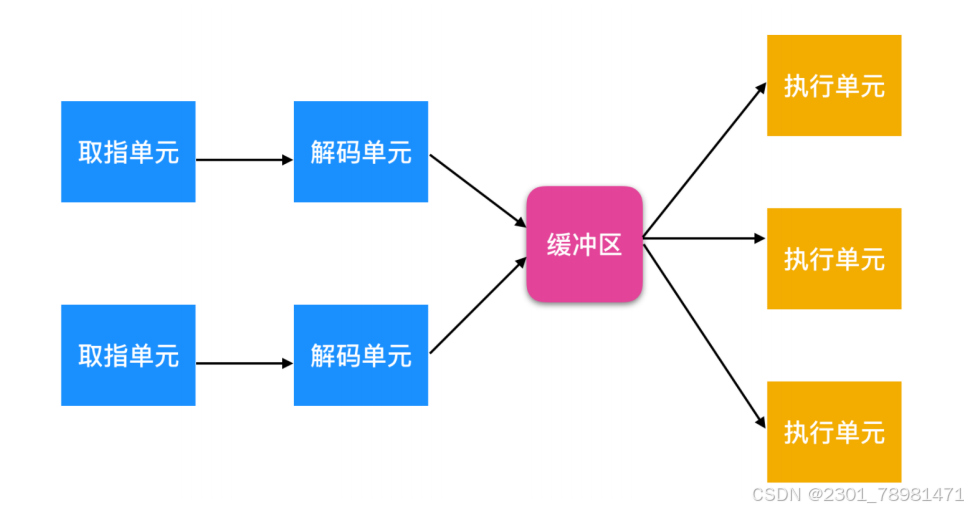
同时读取、解码多条指令,然后将指令存放在缓冲区中,然后由执行单元从中取指令执行。
这种方式可能造成 指令乱序 的问题:由于同时取指,所以有可能缓冲区中的指令跟源代码的顺序不一致,导致一些问题。
内存
计算机中的第二个主要组件是内存。理想情况下,内存应该是非常快速的(比执行一条指令还要快,以避免拖慢CPU的执行效率),同时容量足够大且成本低廉。然而,当前的技术手段无法同时满足这三个要求。因此,存储系统采用了一种分层次的结构来解决这个问题。
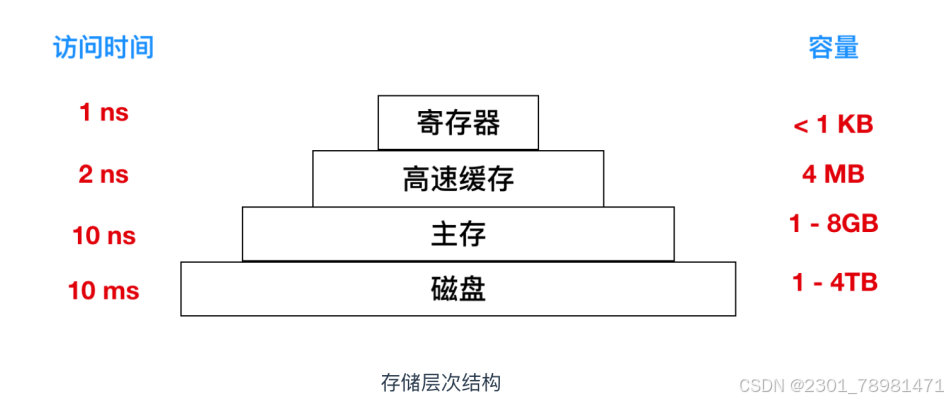
顶层的存储器速度最高,但是容量最小,成本非常高,层级结构越向下,其访问效率越慢,容量越大,但是造价也就越便宜。
高速缓存cache
- 当应用程序需要从内存中读取数据时,高速缓存硬件会检查所需的高速缓存行是否在高速缓存中。如果在,这就是高速缓存命中(cache hit),高速缓存会满足该请求,无需通过总线将请求发送到主内存。
- 高速缓存命中通常只需要两个时钟周期。如果未命中,则需要从主内存中提取数据,这将消耗大量时间。
- 高速缓存行的数量受限于其高昂的成本。有些机器会有两到三级高速缓存,每一级比前一级容量更大但速度略慢。
局部性原理
局部性原理,就是指CPU访问存储器的时候,无论是去指令还是存取数据,所访问的存储单元都区域聚集在一个较小的连续区域中。也就是说,程序具有访问局部区域里的数据和代码的趋势。
代码演示
#include <stdio.h>
#include <stdint.h>
#include <time.h>
#define ROW_NUM (1024)
#define COLUMN_NUM (0x1<<14)
uint8_t data[ROW_NUM][COLUMN_NUM];
void initData() {
for (int i = 0; i < ROW_NUM; ++i) {
for (int j = 0; j < COLUMN_NUM; ++j) {
data[i][j] = 1;
}
}
}
uint32_t fun01() {
uint32_t sum = 0;
for (int i = 0; i < ROW_NUM; ++i) {
for (int j = 0; j < COLUMN_NUM; ++j) {
sum += data[i][j];
}
}
return sum;
}
uint32_t fun02() {
uint32_t sum = 0;
for (int j = 0; j < COLUMN_NUM; ++j) {
for (int i = 0; i < ROW_NUM; ++i) {
sum += data[i][j];
}
}
return sum;
}
void test(const char *name, uint32_t (*test_fun)()) {
clock_t start = clock();
test_fun();
clock_t end = clock();
printf("test %s cost time: %f\n", name, 1.0 * (end - start) / CLOCKS_PER_SEC);
}
int main() {
initData();
test("line01", fun01);
test("line02", fun02);
return 0;
}
申请了一个1024行,16K列的数组,也就是说每一行存放16K个元素(一般情况下高速缓存读取16K的数据)。
- func1():
- 每次读一行,然后将这一行的数据累加。
- func2():
- 每次读一列,然后将这一列的数据累加。
- 结果:
- func1()的效率显著高于func2()。
- 这是因为高速缓存每次从内存中读取一行,func1()一次累加只需要读取一次然后对缓存中的数据进行处理即可,这很快。
- 而func2()需要读取1024次才能将所有数据读取,自然慢很多。
主存
- 紧接高速缓存之下的是主存(Main Memory),也称为RAM(Random Access Memory,随机存取存储器)。这是一种断电易失性结构,没电了存储的信息就会丢失。
- 除了主存之外,许多计算机还配备了一定量的非易失性随机存取存储器。这类存储器与RAM不同,在电源断电后不会丢失内容。ROM(Read Only Memory,只读存储器) 的内容一旦存储后就不会被修改。
- 另一种是闪存(Flash Memory),也就是固态,多用于手机,8+256的256就是指闪存大小。
- 还有一种是 CMOS(Complementary Metal-Oxide-Semiconductor,互补金属氧化物半导体),多用于存储日期,断电易失。
磁盘
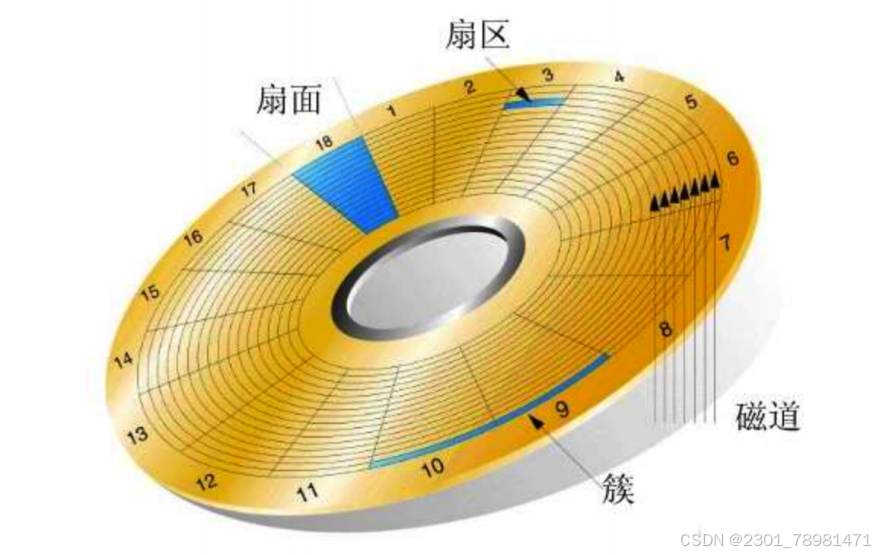
- 磁盘由主轴马达、碟片、机械臂、磁头四部分组成。
- 磁头转一圈,读取的一个环形区域叫做磁道(track)。
- 把一个给定臂的位置上的所有磁道合并起来,组成了一个柱面(cylinder) 。
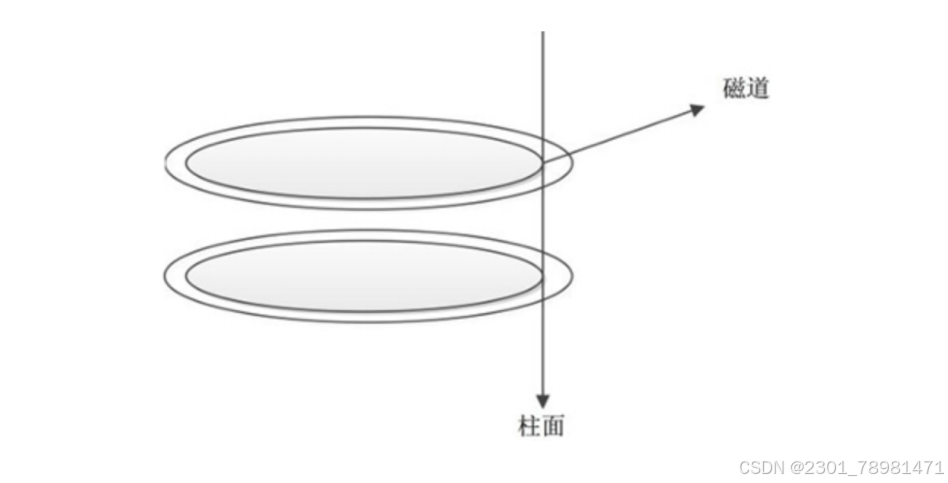
每个磁道划分若干扇区,扇区的值是 512 字节。
I/O设备
CPU总线宽为32bit,那么它是如何调动1T的U盘的呢?
- 在我们的设备里含有控制器,这个控制器的作用是与U盘进行交互。
- 1T的U盘需要40bit来调度,CPU发5次,每次只发8bit,控制器拼接这五次的地址然后调动对应的空间。
32位的CPU能调动4G的地址,但并不意味着可以用完4G的内存条,因为还有其他的I/O设备需要分配地址。
每种类型的设备控制器都是不同的,所以需要不同的软件进行控制。我们通过下载驱动,让软件操控驱动,由驱动去驱动对应硬件设备。
为了使设备驱动程序能够工作,必须把它安装在操作系统中,这样能够使它在内核态中运行。
I/O方式
- 忙等待(busy waiting,也叫轮询):CPU一直停在这等你发出信号,直到I/O操作完成。
- 中断:是设备驱动程序启动设备并且让该设备在操作完成时发生中断。设备驱动程序在这个时刻返回。操作系统接着在需要时阻塞调用者并安排其他工作进行。当设备驱动程序检测到该设备操作完成时,它发出一个 中断 通知操作完成。
- 当硬件中断时,保存现场然后跳转到中断项目表,查询对应中断函数,然后执行,完毕后恢复现场。

















 9007
9007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









