







 前缀微调是一种针对文本生成任务的优化方法,通过在Transformer的自注意力模块中添加连续向量序列。研究发现,尽管初始版本存在训练敏感性问题,改进后的前缀微调在少量参数下表现出与全量微调和适配器微调相当的效果,且优于传统迁移学习方法。
前缀微调是一种针对文本生成任务的优化方法,通过在Transformer的自注意力模块中添加连续向量序列。研究发现,尽管初始版本存在训练敏感性问题,改进后的前缀微调在少量参数下表现出与全量微调和适配器微调相当的效果,且优于传统迁移学习方法。
前缀微调(Prefix tuning)最初被 (Xiang Lisa Li, 2021)提出用于微调文本生成任务。类似提示词的原理,适当的上下文可以引导语言模型生成特定的词,而无需更改其参数。例如,如果希望LM生成一个词(例如,群众),可以在上下文中添加其常见的搭配(例如,人民),语言模型将对所需的词分配更高的概率。将这种直觉扩展到生成单个词或句子以外,我们希望找到一个上下文,可以引导语言模型解决自然语言生成(NLG)任务。寻找这样合适的上下文存在理论上的可能,但在计算上具有很大的挑战性。
为此, (Xiang Lisa Li, 2021)提出了一种为特定任务添加连续的向量序列的方法。如下图所示,它在每一层transformer的自注意力模块中的key、value向量前添加一个向量序列,再通过后向传播来求解。后来,经过一系列实验发现,直接求解这个前缀向量对学习率和参数的初始化非常敏感,导致微调的性能不稳定。因此,论文原作者又对训练过程进行了改进,训练时加入了一个多层感知网络(MLP),如图中虚线框中部分所示,推理时可以删除这个多层感知网络,只保留其输出值。
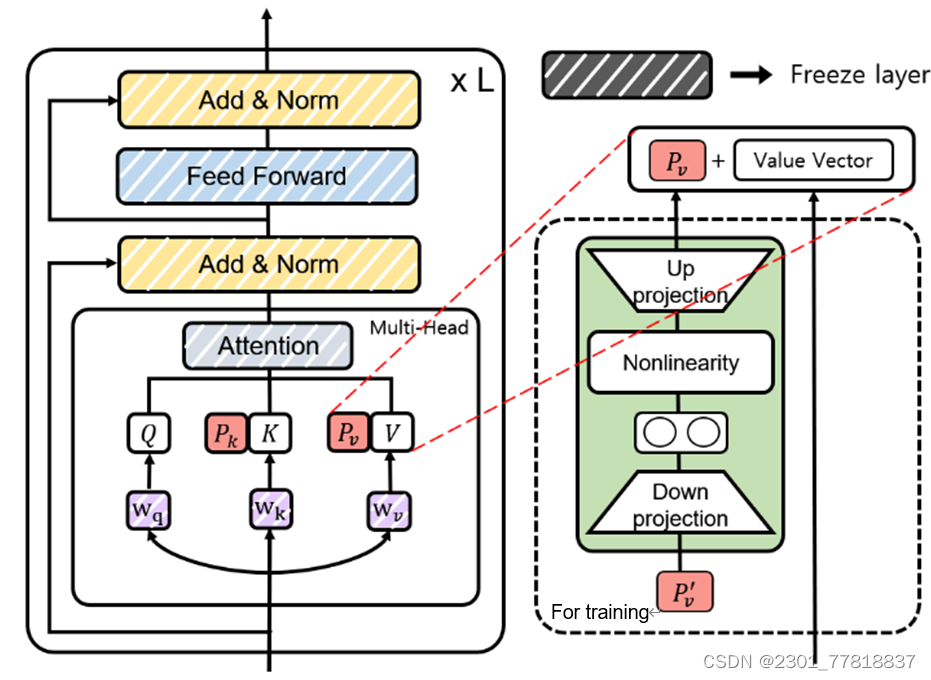
通过对比实验发现,前缀微调在使用更少的参数的情况下(0.1%的参数),得到了与全量微调和适配器微调&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









