




【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。

Transformer 模型在许多自然语言处理任务中表现出极高的有效性。虽然通过增加模型维度和层数可以提升其能力,但这也会显著增加计算复杂度。专家混合(Mixture of Experts, MoE)架构提供了一种优雅的解决方案:通过引入稀疏性,使模型能够高效扩展,而无需按比例增加计算成本。
在本文中,你将了解 Transformer 模型中的专家混合架构,具体包括:
-
为什么 MoE 架构对于高效扩展 Transformer 模型是必要的
-
MoE 的工作原理及其关键组成部分
-
如何在 Transformer 模型中实现 MoE
为什么 Transformer 需要专家混合架构
专家混合(Mixture of Experts, MoE)概念最早由 Jacobs 等人在 1991 年提出。它使用多个“专家”模型处理输入,并通过“门控”机制选择使用哪一个专家。
MoE 在 2021 年的 Switch Transformer 和 2024 年的 Mixtral 模型中得到了复兴。在 Transformer 模型中,MoE 对每个输入仅激活部分参数,这使得可以定义大规模模型,同时每次计算只使用其中的一部分。
以 Mixtral 模型架构为例:
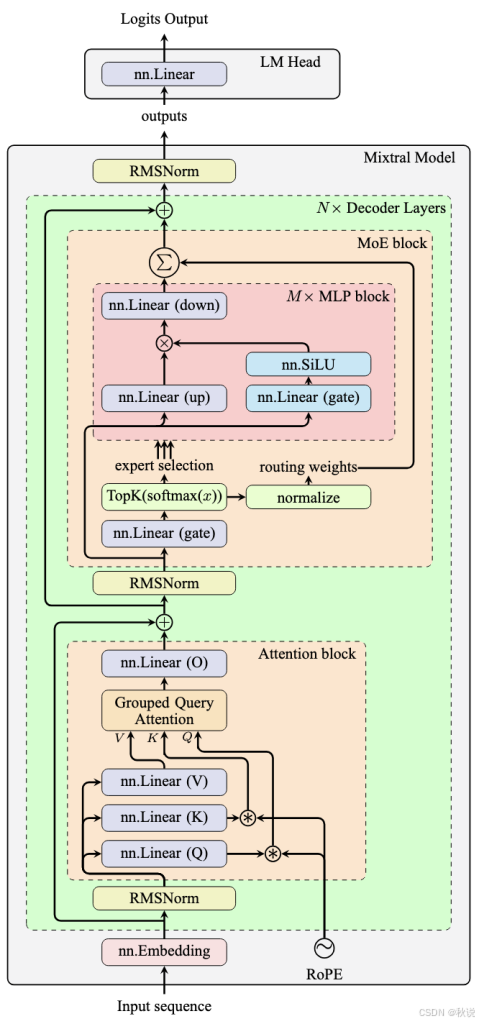
如前文所述,MLP 块为 Transformer 层引入了非线性,而注意力块仅通过线性组合对输入序列的信息进行重组。Transformer 模型的“智能”主要体现在 MLP 块中。
这也解释了为什么 MLP 块通常包含 Transformer 模型中最多的参数和计算负载。训练 MLP 块以在各种任务上表现良好具有挑战性,因为不同任务可能需要相互矛盾的行为。
一种解决方案是为每个任务创建专门的模型,并使用路由器选择合适的模型。另一种方法是将多个模型和路由器合并为一个单一模型,并一并训练。MoE 的核心正是这一思想。
MoE 通过引入稀疏性实现这一点:多个专家网络中每次只激活稀疏子集。MoE 架构仅修改 MLP 块,而所有专家共享同一个注意力块。每个 Transformer 层拥有独立的一组专家,使各层之间可以自由组合。这允许创建大量专家而不显著增加参数总量,从而在扩展模型的同时保持较低计算成本。
核心观点是:不同的输入适合不同的专门化计算。通过拥有多个专家网络并配合路由机制选择使用的专家,模型能够以更少的计算资源实现更优的性能。
专家混合(MoE)的工作原理
MoE 架构由三个关键组件组成:
-
专家网络(Expert Networks):
多个独立的神经网络(专家)处理输入,类似于其他 Transformer 模型中的 MLP 块。 -
路由器(Router):
决定哪些专家处理每个输入的机制。通常由一个线性层加 softmax 组成,生成针对 N N N 个专家的概率分布。路由器输出通过“门控机制”选择前 k k k 个专家。 -
输出组合(Output combination):
前 k k k 个专家处理输入,并根据路由器归一化概率的加权和组合输出。
基本 MoE 操作如下:对于来自注意力块输出序列的每个向量 x x x,路由器将其与矩阵相乘生成 logits(图中门控层)。经过 softmax 转换后,这些 logits 通过前 k k k 操作筛选,得到 k k k 个索引和 k k k 个概率。索引用于激活专家(图中 MLP 块),处理原始注意力块输出。专家输出按路由器归一化概率加权求和,得到最终结果。
概念上,MoE 块计算公式为:
MoE ( x ) = ∑ i ∈ TopK ( p ) p i ⋅ Expert i ( x ) \text{MoE}(x) = \sum_{i \in \text{TopK}(p)} p_i \cdot \text{Expert}_i(x) MoE(x)=i∈TopK(p)∑pi⋅Experti(x)
其中 k k k 是模型超参数,即使 k = 2 k=2 k=2 通常也能获得良好性能。
在 Transformer 模型中实现 MoE
下面是一个使用 PyTorch 实现的 Transformer 层示例,其中 MoE 替代了传统的 MLP 块:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
def __init__(self, dim, intermediate_dim):
super().__init__()
self.gate_proj = nn.Linear(dim, intermediate_dim)
self.up_proj = nn.Linear(dim, intermediate_dim)
self.down_proj = nn.Linear(intermediate_dim, dim)
self.act = nn.SiLU()
def forward(self, x):
gate = self.gate_proj(x)
up = self.up_proj(x)
swish = self.act(gate)
output = self.down_proj(swish * up)
return output
class MoELayer(nn.Module):
def __init__(self, dim, intermediate_dim, num_experts, top_k=2):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
self.dim = dim
self.experts = nn.ModuleList([
Expert(dim, intermediate_dim) for _ in range(num_experts)
])
self.router = nn.Linear(dim, num_experts)
def forward(self, hidden_states):
batch_size, seq_len, hidden_dim = hidden_states.shape
hidden_states_reshaped = hidden_states.view(-1, hidden_dim)
router_logits = self.router(hidden_states_reshaped)
routing_probs = F.softmax(router_logits, dim=-1)
top_k_probs, top_k_indices = torch.topk(routing_probs, self.top_k, dim=-1)
top_k_probs = top_k_probs / top_k_probs.sum(dim=-1, keepdim=True)
output = []
for i in range(self.top_k):
expert_idx = top_k_indices[:, i]
expert_probs = top_k_probs[:, i]
expert_output = torch.stack([
self.experts[exp_idx](hidden_states_reshaped[j])
for j, exp_idx in enumerate(expert_idx)
], dim=0)
output.append(expert_probs.unsqueeze(-1) * expert_output)
output = sum(output).view(batch_size, seq_len, hidden_dim)
return output
class MoETransformerLayer(nn.Module):
def __init__(self, dim, intermediate_dim, num_experts, top_k=2, num_heads=8):
super().__init__()
self.attention = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.moe = MoELayer(dim, intermediate_dim, num_experts, top_k)
self.norm1 = nn.RMSNorm(dim)
self.norm2 = nn.RMSNorm(dim)
def forward(self, x):
input_x = x
x = self.norm1(x)
attn_output, _ = self.attention(x, x, x)
input_x = input_x + attn_output
x = self.norm2(input_x)
moe_output = self.moe(x)
return input_x + moe_output
完整的 MoE Transformer 模型由多个此类 Transformer 层组成,每层包含注意力子层和 MoE 子层,其中 MoE 子层类似于传统 Transformer 中的 MLP 子层。
在 MoELayer 类中,forward() 方法的输入形状为 (batch_size, seq_len, hidden_dim)。由于每个序列向量独立处理,输入首先被重塑为 (batch_size * seq_len, hidden_dim)。路由器和 softmax 生成 routing_probs,形状为 (batch_size * seq_len, num_experts),表示每个专家对输出的贡献。
top-k 操作选择专家及其对应概率。在 for 循环中,每个向量由对应专家处理,并将输出堆叠在一起。循环生成一个加权张量列表 output,最终求和得到输出,并重塑回原始形状 (batch_size, seq_len, hidden_dim)。
Expert 类与前文中的 MLP 块相同,但 MoE 子层使用多个实例,而不是单个 Transformer 层中的 MLP。
我们可以使用以下代码测试 Transformer 层:
batch_size = 4
seq_len = 10
dim = 16
intermediate_dim = 72
num_experts = 8
x = torch.randn(batch_size, seq_len, dim)
model = MoETransformerLayer(dim, intermediate_dim, num_experts)
y = model(x)
共享专家(Shared Experts)
上述实现是最简单的 MoE 架构。最近,DeepSeek 模型提出并推广了一种新思路:在 MoE 架构中加入少量“共享专家”,这些共享专家会对任何输入始终被使用。数学上,MoE 的计算公式变为:
MoE ( x ) = Expert ∗ ( x ) + ∑ i ∈ TopK ( p ) p i ⋅ Expert i ( x ) \text{MoE}(x) = \text{Expert}^*(x) + \sum_{i \in \text{TopK}(p)} p_i \cdot \text{Expert}_i(x) MoE(x)=Expert∗(x)+i∈TopK(p)∑pi⋅Experti(x)
其中额外的专家就是共享专家。显然,你可以使用多个共享专家。在所有情况下,共享专家不依赖路由器,而是无条件处理输入。
要实现共享专家,可以复用前面的代码,并在 MoETransformerLayer 类中添加额外的专家网络:
class MoETransformerLayer(nn.Module):
def __init__(self, dim, intermediate_dim, num_experts, top_k=2, num_heads=8, num_shared_experts=1):
super().__init__()
self.attention = nn.MultiheadAttention(dim, num_heads, batch_first=True)
self.moe = MoELayer(dim, intermediate_dim, num_experts, top_k)
# 共享专家
self.shared_experts = nn.ModuleList([
Expert(dim, intermediate_dim) for _ in range(num_shared_experts)
])
self.norm1 = nn.RMSNorm(dim)
self.norm2 = nn.RMSNorm(dim)
def forward(self, x):
# 注意力子层
input_x = x
x = self.norm1(x)
attn_output, _ = self.attention(x, x, x)
input_x = input_x + attn_output
# MoE 子层
x = self.norm2(input_x)
moe_output = self.moe(x)
for expert in self.shared_experts:
moe_output += expert(x)
return input_x + moe_output
总结
本文详细介绍了 Transformer 模型中的专家混合(MoE)架构及其实现方法。通过引入多个专家网络和路由机制,MoE 能在保证计算效率的前提下扩展模型规模,提高对不同输入的处理能力。
掌握 MoE 架构后,可在实际项目中针对不同任务灵活设计专家网络,提升模型性能,同时控制计算成本,为大规模 Transformer 模型的高效部署提供基础。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











