




【精选优质专栏推荐】
- 《AI 技术前沿》 —— 紧跟 AI 最新趋势与应用
- 《网络安全新手快速入门(附漏洞挖掘案例)》 —— 零基础安全入门必看
- 《BurpSuite 入门教程(附实战图文)》 —— 渗透测试必备工具详解
- 《网安渗透工具使用教程(全)》 —— 一站式工具手册
- 《CTF 新手入门实战教程》 —— 从题目讲解到实战技巧
- 《前后端项目开发(新手必知必会)》 —— 实战驱动快速上手
每个专栏均配有案例与图文讲解,循序渐进,适合新手与进阶学习者,欢迎订阅。

前言
随着大型语言模型(LLM)的普及,越来越多的开发者希望在本地环境中运行这些模型,而无需依赖云端服务。本教程旨在指导读者从零开始,使用 Python 和 FastAPI 搭建一个可本地运行的 LLM API。
通过以下步骤,你将能够:
-
在本地安装并配置 Ollama:一个用户友好的框架,可运行 LLaMA、Gemma 或 Mistral 等开源 LLM,并提供基本接口。
-
使用 FastAPI 构建轻量且稳健的 REST API,通过 HTTP 请求实现用户与模型的交互。
-
通过本地端点发送提示并获取几乎实时的 LLM 响应,无需依赖云服务提供商。
正文
本教程假设你的计算机已安装 Python 3.9 或更高版本,并具备基础至中等的 Python 知识。基于此,代码设计用于在诸如 Visual Studio Code 等 IDE 中创建的 Python 项目中实现——注意,这不是在线笔记本友好的教程,因为我们需要在本地下载并使用 LLM。
本地安装 Ollama 并下载 LLM
根据操作系统的不同,可从 Ollama 官网下载相应版本。下载并启动后,打开终端并输入以下命令:
ollama run llama3
该命令将在本地拉取(下载)一个 Llama 3 LLM——截至撰写本文时,默认下载的模型标记为 llama3:latest。首次下载可能耗时较长,具体取决于网络带宽。下载完成后,终端将自动启动一个对话助手,你即可开始交互。
不过,我们将采用不同方法,展示如何构建基于 Python 的本地 LLM API。为此,请切换至 IDE。
在 VS Code(或其他 IDE)中创建 Python 项目
假设使用 VS Code(其他 IDE 操作略有差异),在文件目录中创建新项目文件夹,命名为 local-llm-api 或类似名称。
在该文件夹内创建两个文件:main.py 和 requirements.txt。Python 文件暂时留空,在 requirements.txt 中添加以下内容并保存:
fastapi
uvicorn
requests
使用本地 LLM 时,建议设置虚拟环境,以隔离依赖、避免库版本冲突,并保持开发环境整洁。在 VS Code 中操作如下:
1.按 Command + Shift + P 打开命令面板。
2.输入或选择 Python: Create Environment,然后选择 Venv。
3.选择合适的 Python 版本(本文示例为 Python 3.11)。
4.系统会提示选择之前创建的 requirements.txt 安装依赖,这一步非常重要,因为 Python 程序运行需要 FastAPI、Uvicorn 和 Requests。
5.若最后一步无法执行,可在 IDE 终端中运行:
pip install fastapi uvicorn requests
主 Python 程序
回到之前创建的空 main.py 文件,添加以下代码:
from fastapi import FastAPI
from pydantic import BaseModel
import requests
import json
import uvicorn
import os # 为使用环境变量添加
app = FastAPI()
class Prompt(BaseModel):
prompt: str
@app.post("/generate")
def generate_text(prompt: Prompt):
try:
# 使用环境变量获取主机和模型名,若无则使用默认值
ollama_host = os.getenv("OLLAMA_HOST", "http://localhost:11434")
ollama_model = os.getenv("OLLAMA_MODEL", "llama3:latest")
response = requests.post(
f"{ollama_host}/api/generate", # 主机地址
json={"model": ollama_model, "prompt": prompt.prompt}, # 使用 ollama_model
stream=True,
timeout=120 # 给模型响应时间
)
response.raise_for_status() # 对 HTTP 错误 (4xx 或 5xx) 抛出异常
output = ""
for line in response.iter_lines():
if line:
data = line.decode("utf-8").strip()
if data.startswith("data: "):
data = data[len("data: "):]
if data == "[DONE]":
break
try:
chunk = json.loads(data)
output += chunk.get("response") or chunk.get("text") or ""
except json.JSONDecodeError:
print(f"Warning: Could not decode JSON from line: {data}") # 调试用
continue
return {"response": output.strip() or "(Empty response from model)"}
except requests.RequestException as e:
return {"error": f"Ollama request failed: {str(e)}"}
if __name__ == "__main__":
# 开发时 reload=True 有用,生产环境建议 reload=False
uvicorn.run("main:app", host="127.0.0.1", port=8000, reload=False)
关键代码解析:
-
app = FastAPI():创建 Web API,通过 REST 服务启动 Python 程序后,监听并处理请求(提示)并调用本地 LLM。
-
class Prompt(BaseModel): 和 prompt: str:定义 JSON 输入模式,用于向 LLM 提供提示信息。
-
@app.post(“/generate”) 与 def generate_text(prompt: Prompt)::定义 API 端点函数,用于发送提示并获取模型响应。
核心请求代码:
response = requests.post(
"http://localhost:11434/api/generate",
json={"model": "llama3:latest", "prompt": prompt.prompt},
stream=True,
timeout=120
)
1.代码将提示发送至 Ollama 拉取的本地 LLM。
2.模型名称必须为已下载的本地模型(示例为 “llama3:latest”)。可在终端输入 ollama list 查看本地模型列表。
最后,程序读取流式响应并返回可读格式:
for line in response.iter_lines():
...
chunk = json.loads(data)
output += chunk.get("response") or chunk.get("text") or ""
return {"response": output.strip()}
运行与测试 API
保存 Python 文件后,点击 Run 图标或在终端运行 python main.py。IDE 输出中应显示如下信息:
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
这表示 REST 服务器已启动,可通过以下 URL 访问服务:
http://127.0.0.1:8000/docs
在浏览器中打开该 URL,若一切正常,将显示 FastAPI 文档界面,如下所示:
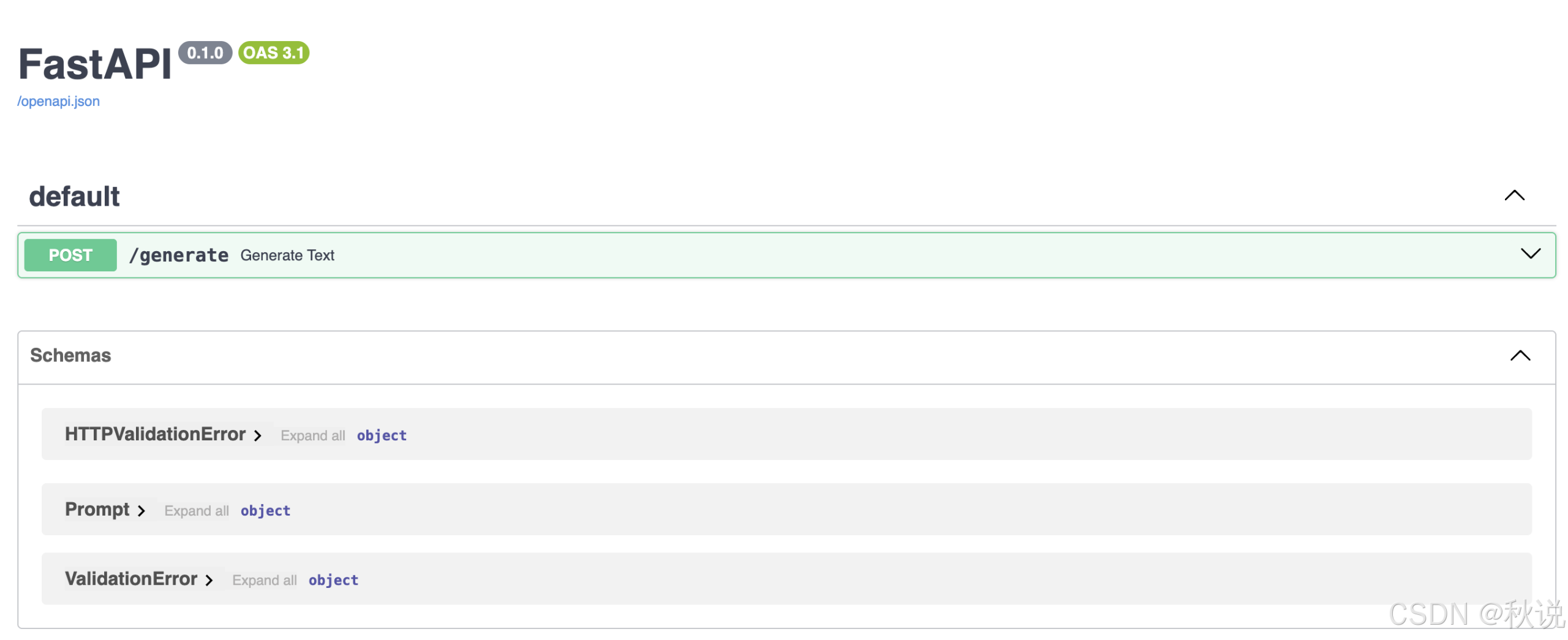
在界面中,点击 POST /generate 框旁的箭头展开,然后点击 Try it out 按钮。
在此输入自定义提示以向 LLM 提问。必须使用专门的 JSON 格式参数,将默认提示 “string” 替换为你的内容。例如:

点击 Execute 按钮后,几秒钟内向下滚动即可查看响应:
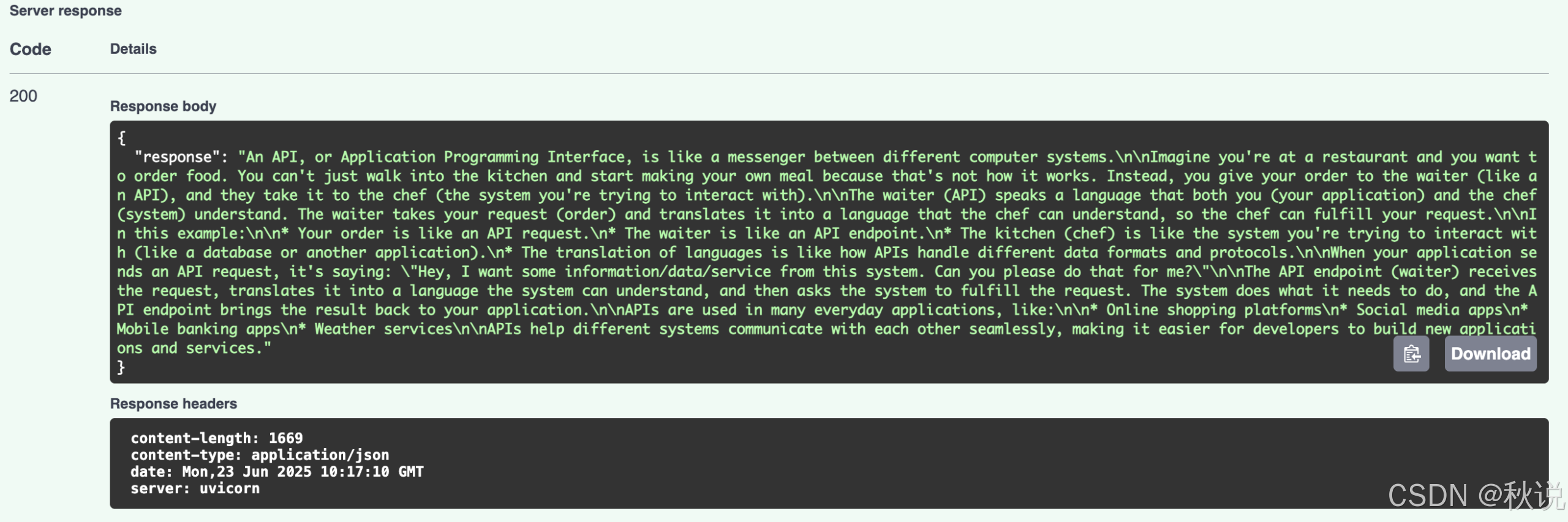
此时,我们已成功搭建自己的本地 LLM API。
在此基础上,可能的改进方向包括:
- 构建前端界面以调用基于 FastAPI 的 API,例如使用 Streamlit;
- 还可尝试使用微调模型以满足定制化或特定领域的需求,如市场营销、保险、物流等。
结语
本文逐步展示了如何搭建并运行首个本地大型语言模型 API,使用 Ollama 下载的本地模型,并通过 FastAPI 提供基于 REST 服务的快速模型推理接口。整个过程均在本地 IDE 中运行 Python 程序完成,无需依赖云端服务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











