




未经许可,禁止转载。
选择
将编译程序分成若干个“遍”是为了 (D.利用有限的机器内存,但降低了执行效率)
A.提高程序的执行效率
B.使程序的结构更加清晰
C.利用有限的机器内存并提高执行效率
D.利用有限的机器内存,但降低了执行效率
词法分析器的输入是(B.源程序)
A.单词符号 B.源程序
C.语法单位 D.目标程序
如果L(M)=L(M’),则M与M’ (A.等价)
A.等价 B.M与M’都是二义的
C.M与M’都是无二义的 D.他们的状态数相等
如果文法G是无二义的,则它的任何句子α (A.最左推导和最右推导对应的语法树必定相同)
A.最左推导和最右推导对应的语法树必定相同
B.最左推导和最右推导对应的语法树可能不同
C.最左推导和最右推导必定相同
D.可能存在两个不同的最左推导,但它们对应的语法树相同
在规范归约中,用什么来刻画可归约串 (B.句柄)
A.直接短语 B.句柄 C.最左素短语 D.素短语
采用自上而下分析,必须 (A.消除左递归)
A.消除左递归 B.消除右递归 C.消除回溯 D.提取公共左因子
文法 G:E-> E+T | T
T-> T*P | P
P-> (E) | i
则句型P+T+i的句柄为 (D.P)
A.P+T B.T C.i D.P
若B为非终结符,则A→a·Bβ为____项目。 (D.待约)
A.接受 B.归约 C.移进 D.待约
移进项目:A→α・aβ(点后面是终结符 a)
待约项目:A→α・Bβ(点后面是非终结符 B)
规约项目:A→α・(点在产生式末尾)
接受项目:S’→S・(其中 S’ 为拓广文法的开始符号)
两个LR(1)项目集如果除去______后是相同的,则称这两个LR(1)项目同心。(C.搜索符)
A.项目 B.活前缀
C.搜索符 D.前缀











选C,因为C的字符串不以b开头。

S->iSeS->iiSeS
S->iS->iiSeS
存在两棵分析树,所以是二义性文法。
 选B,三元式。
选B,三元式。
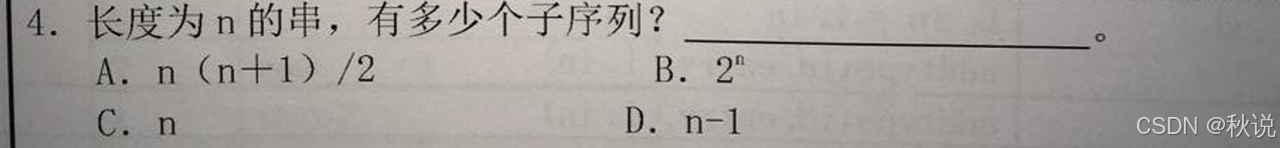
子序列是删除某些字符得到的,因此对于ab,有空、a、b、ab四种,所以选B。

寄存器优化属于与机器高度相关的底层优化,中间表示阶段尚未涉及具体的机器寄存器特性,选D。

选A
(1)else没有匹配的if——语法分析阶段负责检查语句结构是否符合语法规则,例如else必须与最近的未匹配if配对
(2)数组下标越界——语义分析阶段进行静态检查
(3)使用的函数没有定义——语义分析阶段通过符号表验证标识符是否存在。若函数未声明或未定义,符号表查询失败,语义分析报错。
(4)在数中出现非数字字符——词法分析阶段将字符流转换为记号,若扫描到123a等非法数值形式,直接判定为词法错误。

空间和时间上DFA都较优,A错。
LL (1) 文法需要满足三个条件,即无左递归、无公共左因子以及对于每个非终结符的各个产生式的候选式的 First 集两两不相交,B错。
C是分析阶段构成前端,不是两个都构成前端,C错。

选B。

S 属性的 SDD(属性文法)中,所有属性均为综合属性,且仅依赖于子节点的属性,不依赖父节点或兄弟节点的属性。这是 S 属性文法的定义,A对。
L 属性的 SDD 中,属性可以是继承属性或综合属性。L 属性文法要求继承属性仅依赖于父节点、兄弟节点的继承属性,以及自身的综合属性,B对。
自底向上的语法分析(如LR分析)能处理L属性的SDD,但需通过标记非终结符将嵌入动作移至产生式末端以适配归约流程,D错。







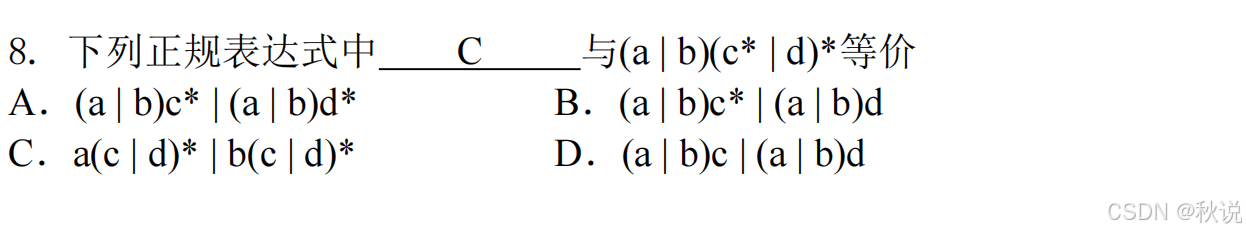
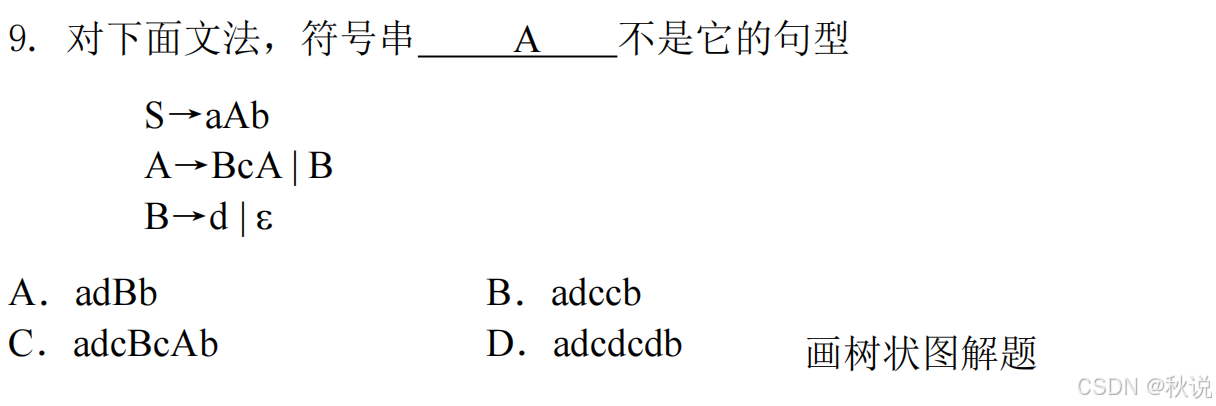

以下选项中,©不是词法分析器的功能。
A.识别数值常量
B.过滤源程序中的注释
C.发现括号不匹配
D.扫描源程序并识别记号
有穷自动机M和N等价,是指©
A.M和N的状态数和边数相等
B.终止状态数相等
C.M和N能识别的字符串集合相等
D.M和N定义在同一个字母表上
若文法G是(D)的,则称G是LL(1)文法
A.不含左递归
B.不含左公因子
C.无二义
D.LL(1)分析表中无多重定义
填空
一个语言是上下文无关的,当且仅当存在一个下推自动机PDA识别该语言。
上下文无关文法的产生式左侧仅允许存在一个非终结符。

答:编译是指一次性转机器码再执行,高效但不灵活;解释是指逐句转译并执行,灵活但效率低;二者既对立又统一,对立于机制特性,统一于实现语言转换,互补推动技术进步。
已知函数 f 原型为:int *f(char ,char ),则函数 f 的类型表达式为:char × char → pointer(integer)。
按逻辑上划分,编译程序第二步工作是语法分析。
词法分析器的输出结果是单词,包含单词的种别编码和自身值。
文法 G[S]:S→xSxly识别的语言L[G]为:L(G)={y,xyx,xxyxx,…,x^nyx^n∣n≥0}
与逆波兰式 Xab+abc*+ -=对应的中缀表达式是:X=a+b-(a*b+c)
移进—规约分析是指在移进过程中,当发现栈顶呈现_可规约符号串_时,就用相应产生式的_左部_符号进行替换。
LR(0)分析法的名字中“L”表示_从左到右进行分析_,“R”表示_采用最右推导的逆过程即最左归约_,“0”表示_不向前看输入字符_。
同心集合并不会产生_移进-规约_冲突,但可能产生_规约-规约_冲突。
目标程序运行的动态分配策略中,包含_栈式_和_堆式_分配策略。
使用栈式存储分配意味着,运行时每当进入一个过程就有一个相应的_活动记录_被压入栈中。


NFA是以表达式主导,大多数编程语言采用NFA引擎,DFA是文本主导。
可以使用是否支持忽略优先量词和分组捕获来判断引擎类型:支持则为 NFA,不支持则为 DFA。
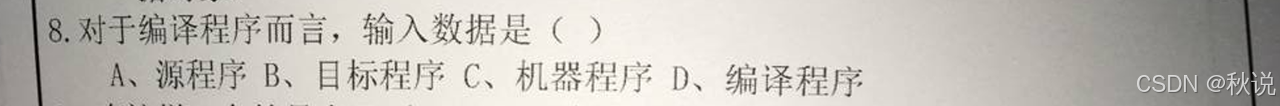
对编译程序而言,输入数据是源程序,输出结果是目标程序。
综合
下面是产生字母表S = { 0, 1, 2}上数字串的一个文法:
S -> DSD | 2
D -> 0 | 1
写一个语法制导定义,它打印一个句子是否为回文数(一个数字串,从左向右读和从右向左读都一样时,称它为回文数)。请用print函数打印出true or false。
解:
1.基本情况:单个数字 2 是一个回文数(如题目中 S → 2 所示)。
2.递归情况:首尾数字相同(即最左边的 D1 和最右边的 D2 相等);中间部分(S1)也是一个回文数。

S′ → S // 开始产生式,S'是拓广文法的开始符号
print(S.val) // 解析完成后打印最终结果:true(是回文)或false(非回文)
S → D1 S1 D2 // 递归结构:回文数由相同的首尾数字包裹中间部分构成
S.val = // 当前S是否为回文取决于两个条件:
(D1.val = D2.val) // 1. 首尾数字必须相同
and S1.val // 2. 中间部分S1也必须是回文
S → 2 // 基础情况:单个数字2自身构成回文
S.val = true // 直接返回true
D → 0 // 终结符0映射为数值0
D.val = 0
D → 1 // 终结符1映射为数值1
D.val = 1

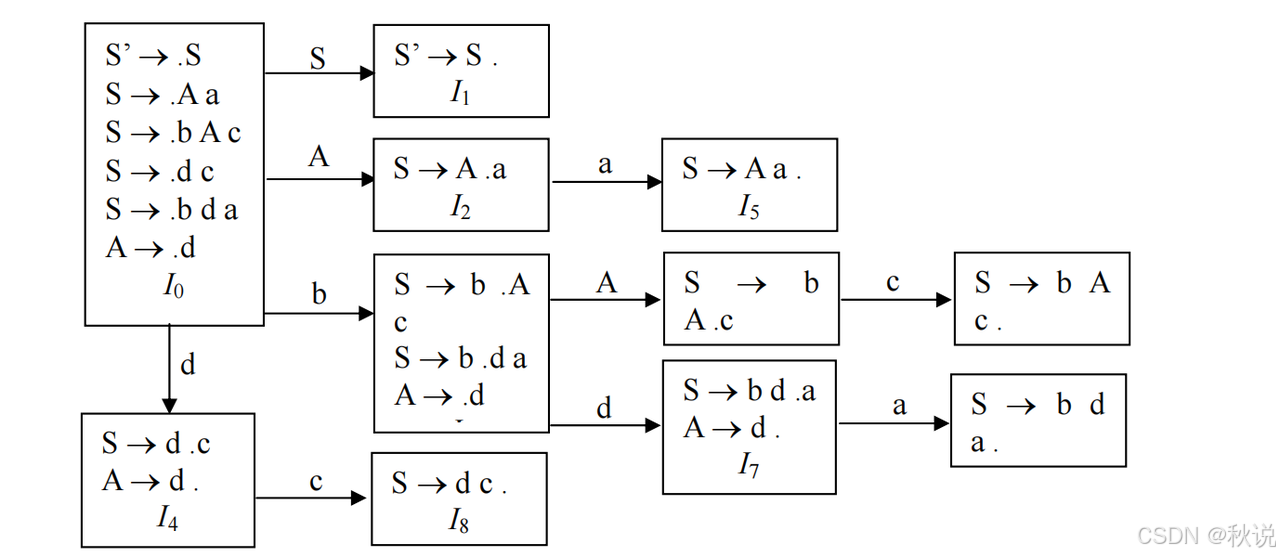
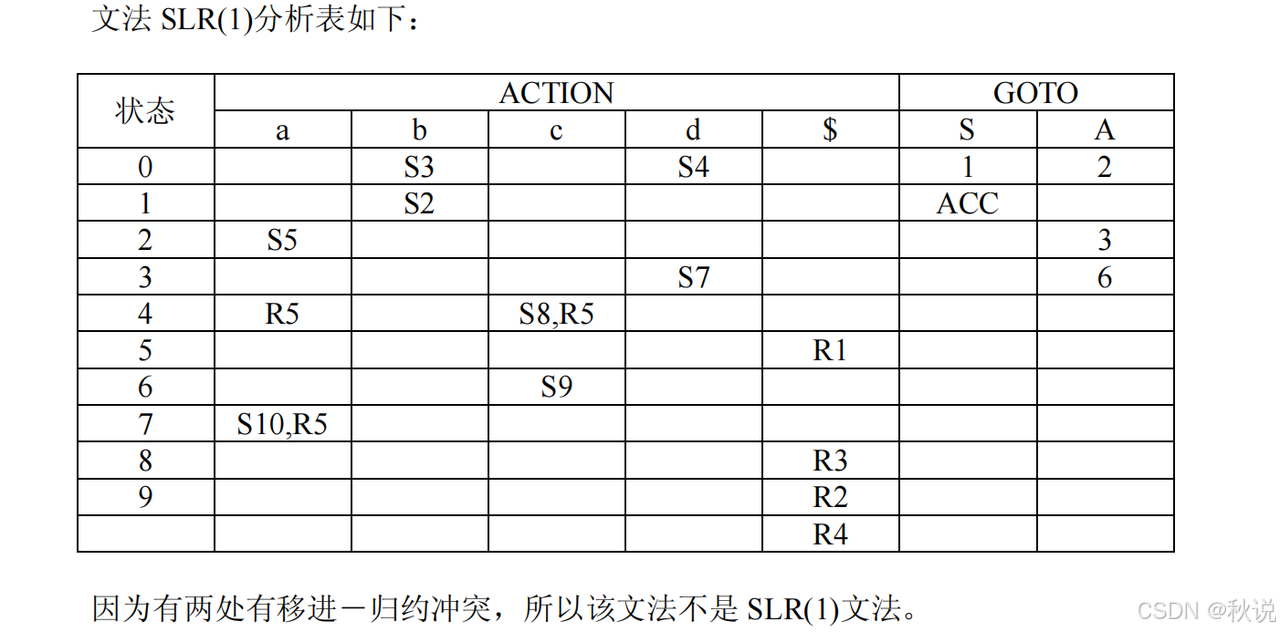



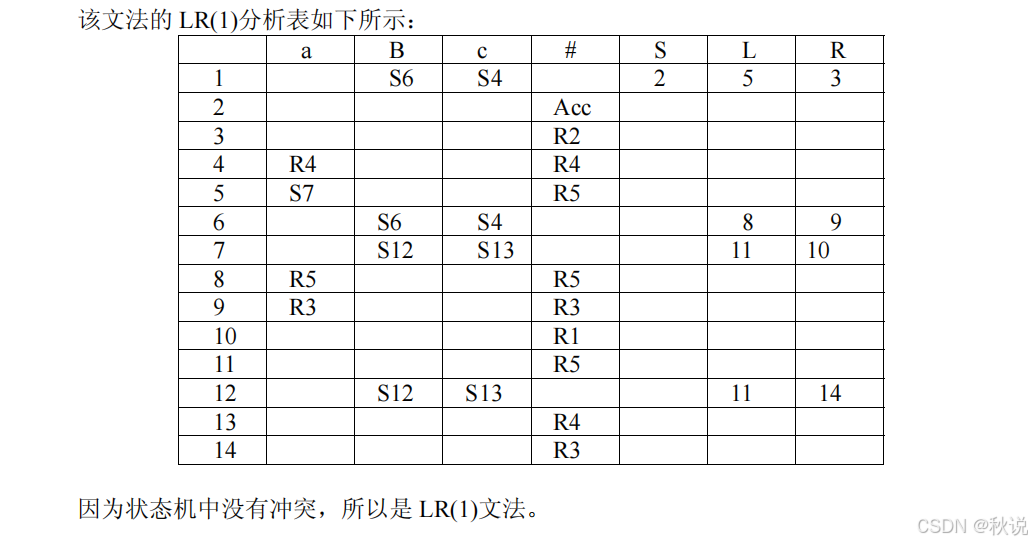


(1)
产生式 S → (L)
语义规则:S.count = L.count + 1
产生式 S → a
语义规则:S.count = 0
产生式 L → L₁, S
语义规则:L.count = L₁.count + S.count
产生式 L → S
语义规则:L.count = S.count
(2)
S → ( L )
{ L.depth = S.depth + 1; }
S → a
{ print(S.depth); }
L → L₁ , S
{ L₁.depth = L.depth;
S.depth = L.depth; }
L → S
{ S.depth = L.depth; }

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。


较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。

较简单,不提供答案。
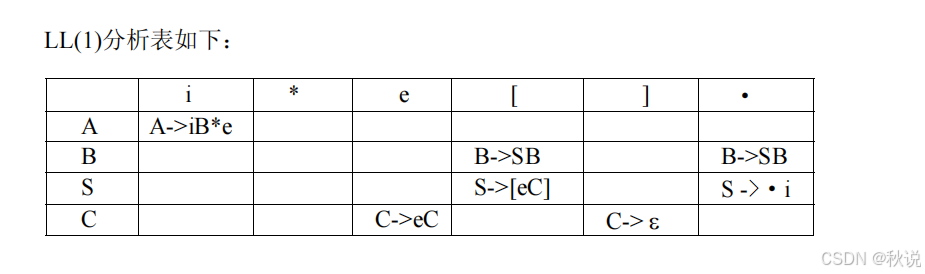
较简单,不提供答案。


较简单,不提供答案。

较简单,不提供答案。
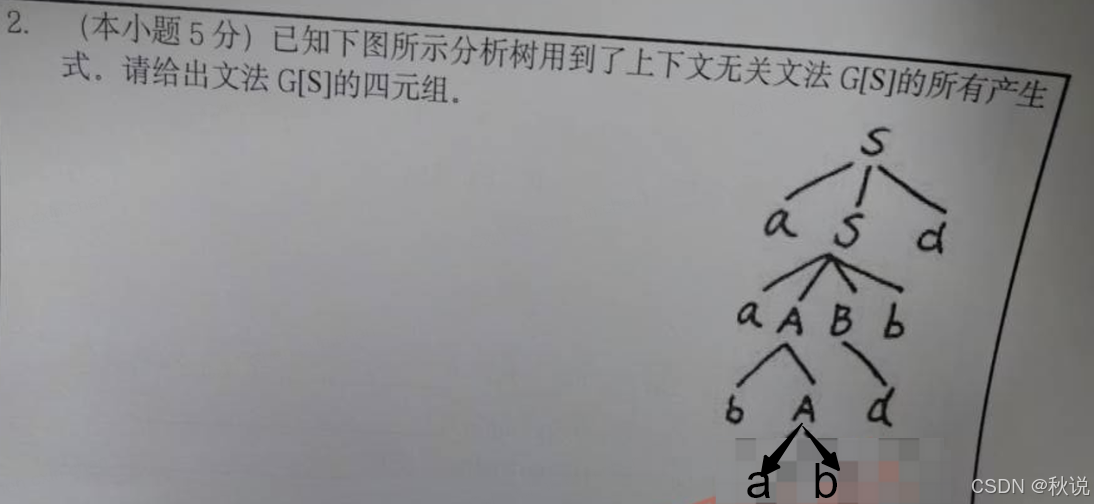
答:

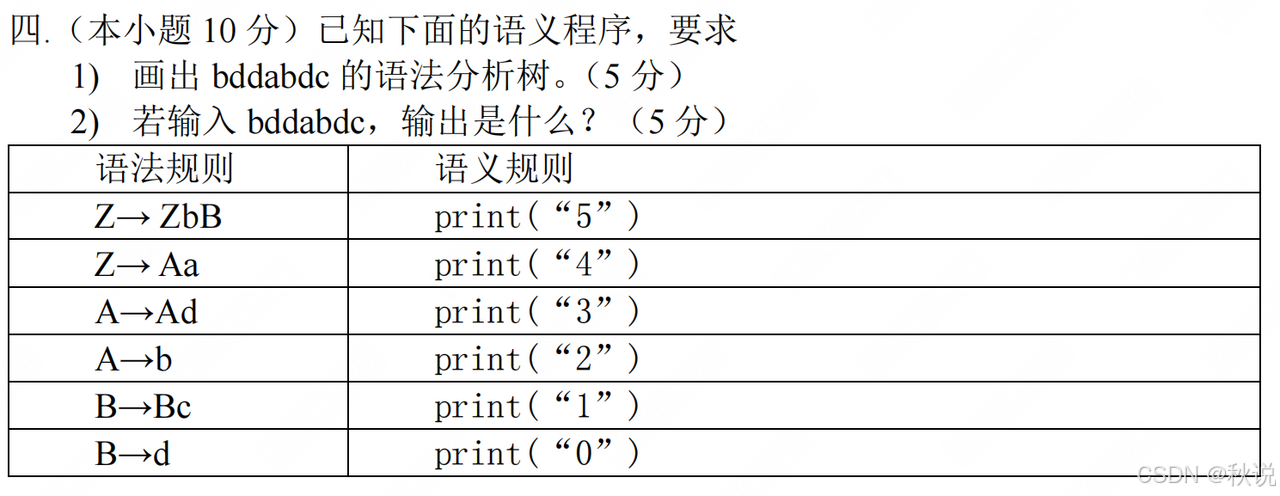
较简单,不提供答案。

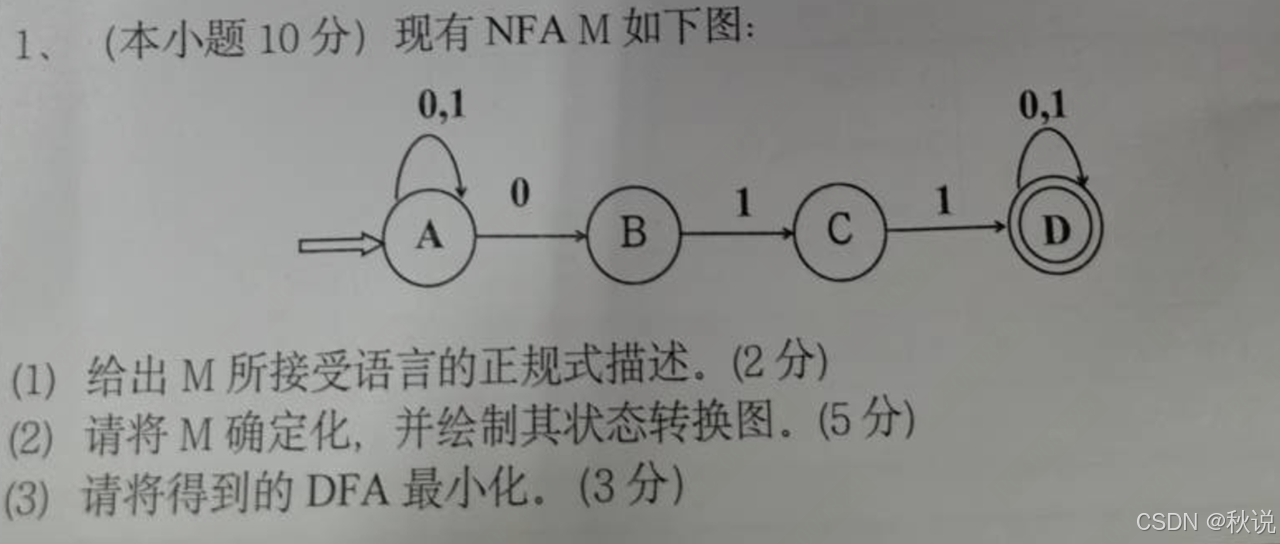
较简单,不提供答案。


















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











