







Rk3566/RK3588 yolov5部署(一)Ubuntu系统烧写及cmake安装
RK3566/RK3588 yolov5部署(二)NPU冒烟测试及rknn_api使用
RK3566/RK3588 yolov5部署(三)yolov5单线程部署并查看NPU占用情况
代码链接:
通过网盘分享的文件:YoloV5_thread_pool
链接: https://pan.baidu.com/s/1jz0cAIypxARTHh5nRVTsWQ?pwd=s84d 提取码: s84d
1.代码编译与测试
下载文件,进度cmakelists.txt所在路径,终端输入
cmake -S . -B build
cmake --build build编译完成后cd进入build文件夹 ,输入
./yolov5_thread_pool ../weight/rk3566/yolov5n.rknn ../video/test.mp4 6
以上为rk3566下运行命令,rk3588命令如下
./yolov5_thread_pool ../weight/rk3588/yolov5n.rknn ../video/test.mp4 6开6个线程shiyong yolov5n模型再rk3566下进行推理测试
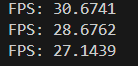
再只开1个推理线程测试,输入:
./yolov5_thread_pool ../weight/rk3566/yolov5n.rknn ../video/test.mp4 1可以看到当前帧数:
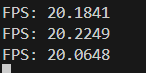
注意一下这里所说的1个线程时1个推理线程,实际上当前的进程除了主线程外有3个线程(1个读帧线程、1个推理线程,1个读结果线程),所以帧数相较于上一节:RK3566/RK3588 YoloV5部署(三)的代码还要高出一点。
我们再来看看NPU占用情况,输入
sudo watch -n 1 cat /sys/kernel/debug/rknpu/load1个推理线程时:
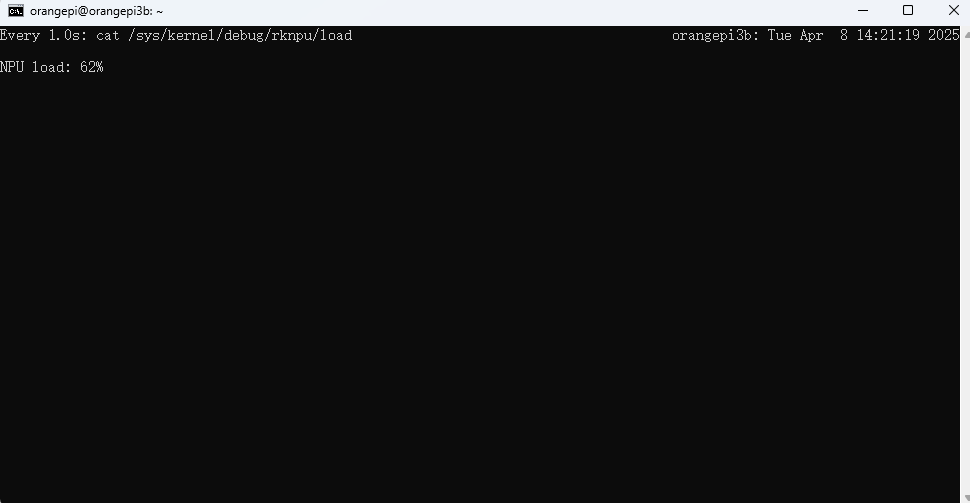
6个推理线程:
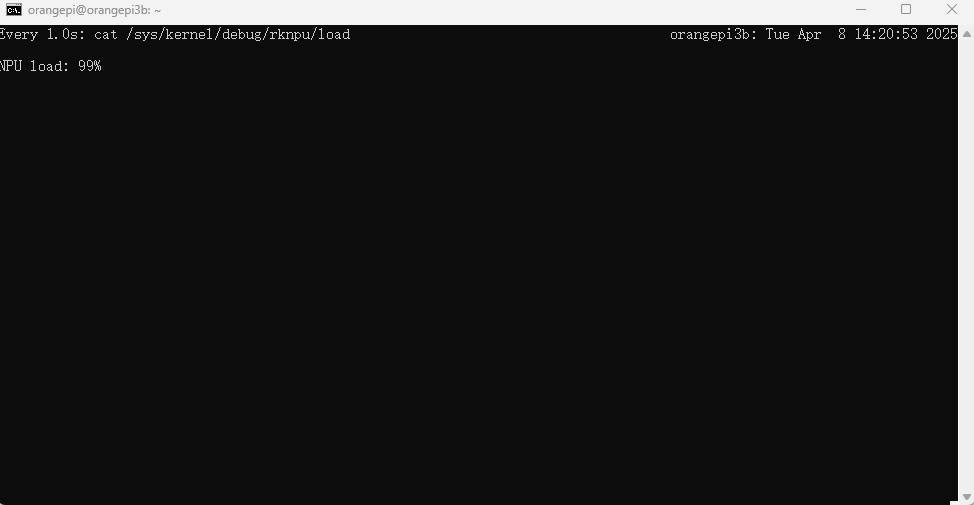
可以通过修改运行命令中最后一个数字更改推理线程数量。
2.代码讲解
src文件结构
├── main.cpp (上一节代码)
├── main_thread_pool.cpp (本节代码主函数)
├── postprocess.cpp (瑞芯微官方后处理代码)
├── postprocess.h
├── yolov5model.cpp (模型具体实现,即rknn_api的封装)
├── yolov5model.h
├── yolov5threadpool.cpp (线程池)
└── yolov5threadpool.h
代码大体逻辑是推帧线程从MP4中将原始帧与播放顺序索引绑定后推入任务队列,推理线程(并行推理)从任务对列中拉取任务并处理,将处理后的结果推入结果队列,读帧线程从结果队列中按顺序读帧并计算FPS。
main_thread_pool.cpp:
#include <opencv2/opencv.hpp>
#include <opencv2/videoio.hpp>
#include <chrono>
#include <string>
#include "yolov5threadpool.h"
static int frame_push_id = 0;
static int frame_get_id = 0;
bool end = false;
static YoloV5ThreadPool* thread_pool = nullptr;
void result_thread()//读帧线程函数
{
auto start_all = std::chrono::high_resolution_clock::now();
int frame_count = 0;
while(true)
{
cv::Mat img;
auto ret = thread_pool->getImgResult(img, frame_get_id++);//根据frame_get_id一次从结果队列读取结果,保证读取结果的顺序(类似PTS)
if (end && !ret)//推帧结束并且读帧结束-》stopall
{
thread_pool->stopAll();
break;
}
frame_count++;
auto end_all = std::chrono::high_resolution_clock::now();
auto elapsed_all_2 = std::chrono::duration_cast<std::chrono::microseconds>(end_all - start_all).count() / 1000.f;
if (elapsed_all_2 > 1000)
{
std::cout << "FPS: " << frame_count / (elapsed_all_2 / 1000.0f) << std::endl;
frame_count = 0;
start_all = std::chrono::high_resolution_clock::now();
}
}
}
void read_thread(const char* video_path)//推帧线程
{
cv::VideoCapture capture;
size = cv::Size(capture.get(cv::CAP_PROP_FRAME_WIDTH), capture.get(cv::CAP_PROP_FRAME_HEIGHT));
set_fps = static_cast<int>(capture.get(cv::CAP_PROP_FPS));
if (!video_path)
{
if (!capture.open(0))
{
std::cerr << "capture.open(0) failed" << std::endl;
}
}
else
{
if (!capture.open(video_path))
{
std::cerr << "capture.open( " << video_path << " ) failed" << std::endl;
}
}
cv::Mat img;
while (true)
{
capture >> img;
if (img.empty())
{
std::cout << "Video end." << std::endl;
end = true;
break;
}
thread_pool->submitImg(img.clone(), frame_push_id++);//向任务队列中提交原始帧,并绑定一个顺序索引
}
// 释放资源
capture.release();
}
int main(int argc, char* argv[])
{
std::string model_path = argv[1];
char* video_path = nullptr;
if(argc > 3)
{
video_path = argv[2];
}
const int num_threads = (argc > 3) ? atoi(argv[3]) : 2;
thread_pool = new YoloV5ThreadPool();
thread_pool->start(model_path, num_threads);
std::thread read_file_thread(read_thread, video_path);
std::thread get_result_thread(result_thread);
read_file_thread.join();
get_result_thread.join();
return 0;
}
yolov5threadpool.h:
#ifndef YOLOV5THREADPOOL_H
#define YOLOV5THREADPOOL_H
#include <iostream>
#include <vector>
#include <queue>
#include <map>
#include <thread>
#include <mutex>
#include <condition_variable>
#include "yolov5model.h"
class YoloV5ThreadPool
{
private:
std::queue<std::pair<int, cv::Mat>> tasks;//任务队列
std::vector<std::thread> threads;//推理线程队列
std::vector<std::shared_ptr<Yolov5Model>> yolov5_list;//模型实例
std::map<int, cv::Mat> img_results;//结果队列
std::mutex mtx1;//任务队列锁
std::mutex mtx2;//结果队列锁
std::condition_variable cv_task;//锁和条件变量,用于PV操作
bool stop = false;
void worker(int id);//推理方法
public:
YoloV5ThreadPool() = default;
~YoloV5ThreadPool();
void start(std::string &model_path, int num_threads);
void submitImg(const cv::Mat &img, int id);//任务提交
bool getImgResult(cv::Mat &img, int id);//结果读取
void stopAll();
};
#endifyolov5threadpool.cpp
#include "yolov5threadpool.h"
YoloV5ThreadPool::~YoloV5ThreadPool()
{
stop = true;
cv_task.notify_all();
for (auto &thread : threads)
{
if (thread.joinable())
{
thread.join();
}
}
}
//初始化线程,包括模型实例化和线程启动
void YoloV5ThreadPool::start(std::string &model_path, int num_threads)
{
for(size_t i = 0; i < num_threads; i++)
{
std::shared_ptr<Yolov5Model> yolov5 = std::make_shared<Yolov5Model>();
yolov5->loadmodel(model_path.c_str());
yolov5_list.push_back(yolov5);
threads.emplace_back(&YoloV5ThreadPool::worker, this, i);
}
return;
}
void YoloV5ThreadPool::submitImg(const cv::Mat &img, int id)
{
while(tasks.size() > 10)
{
std::this_thread::sleep_for(std::chrono::milliseconds(1));//避免过度消耗cpu时间
}
{
std::lock_guard<std::mutex> lock(mtx1);
tasks.push({id,img});
}
cv_task.notify_one();
return;
}
bool YoloV5ThreadPool::getImgResult(cv::Mat &img, int id)
{
int err_count = 0;
while (img_results.find(id) == img_results.end())
{
std::this_thread::sleep_for(std::chrono::milliseconds(1));
err_count++;
if(err_count > 1000)
{
return false;//超时退出
}
}
std::lock_guard<std::mutex> lock(mtx2);
img = img_results[id];
img_results.erase(id);
return true;
}
void YoloV5ThreadPool::stopAll()
{
stop = true;
cv_task.notify_all();
}
void YoloV5ThreadPool::worker(int id)
{
while(!stop)
{
std::pair<int, cv::Mat> task;
std::shared_ptr<Yolov5Model> model = yolov5_list[id];//获取模型实例
{
std::unique_lock<std::mutex> lock(mtx1);
cv_task.wait(lock,[&]{return !tasks.empty() || stop;});//等待推帧线程
if(stop)
{
return;
}
task = tasks.front();
tasks.pop();
}
model->run(task.second);
{
std::lock_guard<std::mutex> lock(mtx2);//结果提交
img_results.insert({task.first, task.second});
}
}
}yolov5model.h(这里就是对上一节代码的简单封装,这里的封装应该再细化将预处理和画框等功能隔离出来,隐藏rknn_api,实在懒得写,预处理使用letterbox会更合理,这里只是resize处理)
#ifndef YOLOV5MODEL_H
#define YOLOV5MODEL_H
#include <memory>
#include <opencv2/opencv.hpp>
#include <vector>
#include "postprocess.h"
#include "rknn_api.h"
class Yolov5Model
{
public:
Yolov5Model();
~Yolov5Model();
bool loadmodel(const char *model_path);
bool run(cv::Mat &img);
private:
bool ready_;
rknn_context ctx;
int model_len;
int channel;
int width;
int height;
float nms_threshold;
float box_conf_threshold;
rknn_input_output_num io_num;
std::vector<rknn_tensor_attr> input_atts;
std::vector<rknn_tensor_attr> output_atts;
};
#endifyolov5model.cpp
#include "yolov5model.h"
#include <iostream>
static unsigned char* load_model(const char* model_path, int* model_len)
{
FILE *fp = fopen(model_path,"rb");
if(fp == nullptr)
{
std::cerr << "open model faile!" << std::endl;
return NULL;
}
fseek(fp,0,SEEK_END);
int model_size = ftell(fp);
unsigned char *model = (unsigned char *)malloc(model_size);
fseek(fp,0,SEEK_SET);
if(model_size != fread(model,1,model_size,fp))
{
std::cerr << "read model faile!" << std::endl;
return NULL;
}
*model_len = model_size;
if(fp)
{
fclose(fp);
}
return model;
}
static void dump_tensor_attr_info(rknn_tensor_attr *attr)
{
std::cout << "index= " << attr->index << std::endl;
std::cout << "name= " << attr->name << std::endl;
std::cout << "n_dims= " << attr->n_dims << std::endl;
std::cout << "dims= " ;
for(int i = 0; i < attr->n_dims; i++)
{
std::cout << attr->dims[i] << " ";
}
std::cout << std::endl;
std::cout << "n_elems= " << attr->n_elems << std::endl;
std::cout << "size= " << attr->size << std::endl;
std::cout << "fmt= " << get_format_string(attr->fmt) << std::endl;
std::cout << "type= " << get_type_string(attr->type) << std::endl;
std::cout << "qnt_type= " << get_qnt_type_string(attr->qnt_type) << std::endl;
std::cout << "zp= " << attr->zp << std::endl;
std::cout << "scale= " << attr->scale << std::endl;
}
Yolov5Model::Yolov5Model()
{
ctx = 0;
model_len = 0;
channel = 3;
width = 0;
height = 0;
nms_threshold = NMS_THRESH;
box_conf_threshold = BOX_THRESH;
}
Yolov5Model::~Yolov5Model()
{
if(ctx > 0)
{
rknn_destroy(ctx);
}
}
bool Yolov5Model::loadmodel(const char *model_path)
{
std::cout << "load model ..." << std::endl;
auto model = load_model(model_path, &model_len);
int ret = rknn_init(&ctx, model, model_len,0,NULL);
if(ret < 0)
{
std::cerr << "rknn init fail!" << std::endl;
return false;
}
free(model);
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num));
if(ret != RKNN_SUCC)
{
std::cerr << "rknn query num fail!" << std::endl;
return false;
}
std::cout << "model input num: " << io_num.n_input << " ,output num: " << io_num.n_output << std::endl;
std::cout << "model input attr: " << std::endl;
rknn_tensor_attr input_attrs[io_num.n_input];
memset(input_attrs, 0, sizeof(input_attrs));
for(int i = 0; i < io_num.n_input; i++)
{
input_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr));
if(ret != RKNN_SUCC)
{
std::cerr << "rknn query input_attr fail!" << std::endl;
return false;
}
input_atts.push_back(input_attrs[i]);
dump_tensor_attr_info(&(input_attrs[i]));
}
std::cout << "model output attr: " << std::endl;
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for(int i = 0; i < io_num.n_output; i++)
{
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr));
if(ret != RKNN_SUCC)
{
std::cerr << "rknn query output_attr fail!" << std::endl;
return false;
}
output_atts.push_back(output_attrs[i]);
dump_tensor_attr_info(&(output_attrs[i]));
}
if(input_attrs[0].fmt == RKNN_TENSOR_NCHW)
{
std::cout << "model input fmt RKNN_TENSOR_NCHW" << std::endl;
channel = input_attrs[0].dims[1];
height = input_attrs[0].dims[2];
width = input_attrs[0].dims[3];
}
if(input_attrs[0].fmt == RKNN_TENSOR_NHWC)
{
std::cout << "model input fmt RKNN_TENSOR_NHWC" << std::endl;
height = input_attrs[0].dims[1];
width = input_attrs[0].dims[2];
channel = input_attrs[0].dims[3];
}
std::cout << "input image height: " << height << " width: " << width << " channels: " << channel << std::endl;
return true;
}
bool Yolov5Model::run(cv::Mat &img)
{
cv::Mat test_img = img;
rknn_input inputs[io_num.n_input];
memset(inputs, 0, sizeof(inputs));
for(int i = 0; i < io_num.n_input; i++)
{
inputs[i].index = i;
inputs[i].type = RKNN_TENSOR_UINT8;
inputs[i].size = height * width * channel;
inputs[i].fmt = input_atts[i].fmt;
inputs[i].pass_through = 0;
}
if(test_img.empty())
{
std::cerr << "capture.read error!" << std::endl;
}
cv::cvtColor(test_img, test_img, cv::COLOR_BGR2RGB);
int img_width = test_img.cols;
int img_height = test_img.rows;
if (img_width != width || img_height != height)
{
cv::resize(test_img,test_img,cv::Size(width,height));
inputs[0].buf = (void*)test_img.data;
}
else
{
inputs[0].buf = (void*)test_img.data;
}
auto ret = rknn_inputs_set(ctx, io_num.n_input, inputs);
if(ret < 0 )
{
std::cerr << "rknn_inputs_set fail!" << std::endl;
return false;
}
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for(int i = 0; i < io_num.n_output; i++)
{
outputs[i].index = i;
outputs[i].want_float = 0;
}
ret = rknn_run(ctx, NULL);
if(ret < 0 )
{
std::cerr << "rknn_run fail!" << std::endl;
return false;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL);
if(ret < 0 )
{
std::cerr << "rknn_outputs_get fail!" << std::endl;
return false;
}
float scale_w = (float)width / img_width;
float scale_h = (float)height / img_height;
detect_result_group_t detect_result_group;
std::vector<float> out_scales;
std::vector<int32_t> out_zps;
for(int i = 0; i < io_num.n_output; i++)
{
out_scales.push_back(output_atts[i].scale);
out_zps.push_back(output_atts[i].zp);
}
post_process((int8_t *)outputs[0].buf, (int8_t *)outputs[1].buf, (int8_t *)outputs[2].buf,
height, width,box_conf_threshold, nms_threshold, scale_w, scale_h,
out_zps, out_scales, &detect_result_group);
char text[256];
for (int i = 0; i < detect_result_group.count; i++)
{
detect_result_t* det_result = &(detect_result_group.results[i]);
int x1 = det_result->box.left;
int y1 = det_result->box.top;
int x2 = det_result->box.right;
int y2 = det_result->box.bottom;
cv::rectangle(img, cv::Point(x1, y1), cv::Point(x2, y2), cv::Scalar(255, 0, 0),10);
sprintf(text, "%s %.1f%%", det_result->name, det_result->prop * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = det_result->box.left;
int y = det_result->box.top - label_size.height - baseLine;
if (y < 0) y = 0;
if (x + label_size.width > test_img.cols) x = test_img.cols - label_size.width;
cv::rectangle(img, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)), cv::Scalar(255, 255, 255), -1);
cv::putText(img, text, cv::Point(x, y + label_size.height), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
if (ret < 0)
{
std::cerr << "rknn_outputs_release fail!" << std::endl;
return false;
}
return true;
}
















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









