






目录
关联容器
关联容器和顺序容器有着根本的不同:关联容器中的元素是按关键字来保存和访问的,而顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
关联容器支持高效的关键字查找和访问。
两个主要的关联容器(associative-container),set和map。
set 中每个元素只包含一个关键字。set 支持高效的关键字查询操作一一检查一个给定关键字是否在 set 中。
map 的元素是关键字-值 (key-value)对(也称键-值对)。其中关键字起到索引的作用,值则表示与索引相关联的数据。字典是一个很好的使用 map 的例子:可以将单词作为关键字,将单词释义作为值。
标准库针对set和map一共提供8种不同的关联容器。1.是否运行关键字重复;2.是否按顺序保存元素
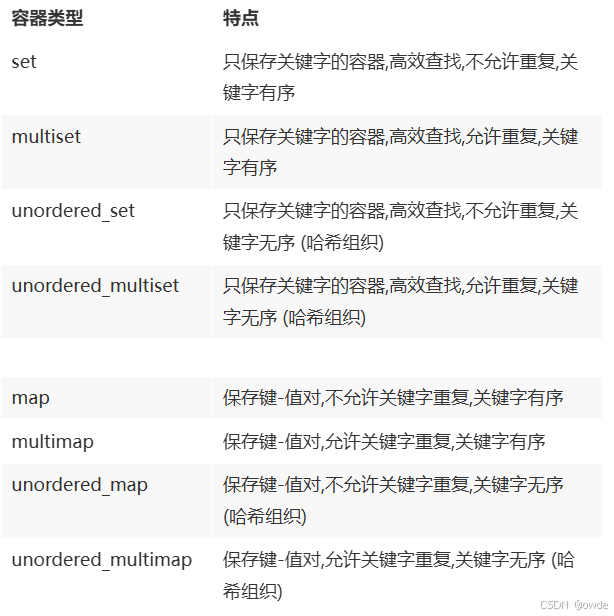
set和multiset定义在头文件set中;map和multimap定义在头文件map中;无序容器则定义在头文件unordered set和unordered map中。
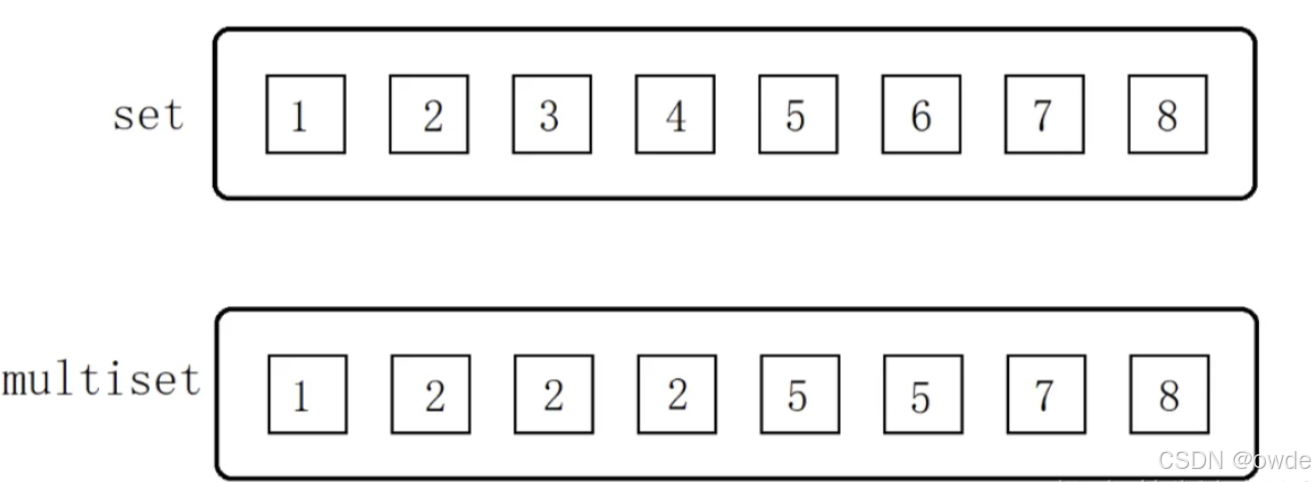
set和multiset集合
set和multiset会根据特定的排序准则,自动将元素排序。两者不同之处在于multiset 允许元素重复而 set 不允许。如下图:
使用set或multiset,必须先包含头文件<set>:
#include <set>
上述两个类型都被定义为命名空间std内的class template:
namespace std {
template <typename T,
typename Compare = less<T>,
typename Allocator = allocator<T> >
class set;
template <typename T,
typename Compare = less<T>,1
typename Allocator = allocator<T> >
class multiset;
}其中T是能进行排序的数据类型。第二个参数是进行排序的规则,默认为升序(小于,<),第三个是内存分配器,不用管。
set 和multiset通常用平衡二叉树(balanced binary tree,确切说是红黑树)实现。这样在插入数据时能自动排序,使得查找元素时有良好性能。其查找函数具有对数O(logn)时间复杂度。
但是,自动排序也造成set和multiset的一个重要限制:你不能直接改变元素值,因为这样会打乱原本正确的顺序。
从其接口也能反映这种情况:
set和multiset不提供任何函数可以直接访问元素。
通过迭代器访问元素时都是常量。
定义及初始化
set的定义和初始化如下:
#include <set>
#include <iostream>
using namespace std;
//输出s(升序)的所有数据
void Show(const set<int>& s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
//输出s(降序)的所有数据
void Show(const set<int,greater<int>>&s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
int main()
{
set <int> s0;//创建一个空的int set集合
s0.insert(5); //插入数据
s0.insert(3);
s0.insert(1);
s0.insert(2);
s0.insert(4);
s0.insert(4);//相同数据插入失败
set <int> s1(s0); //利用原来的set对象,创建一个新的set对象
set <int> s2 = s1;//同上
set <int> s3(s0.begin(), --s0.end());//利用迭代器创建一个新的set对象
set <int> s4{ 1, 6, 3, 5, 4, 2 };//利用初始化列表创建一个set对象,可以无序
cout << "s0:"; Show(s0); //输出数据
cout << "s1:"; Show(s1);
cout << "s2:"; Show(s2);
cout << "s3:"; Show(s3);
cout << "s4:"; Show(s4);
cout << "降序的集合" << endl;
set <int, greater<int> > s5; //创建一个降序的set集合
s5.insert(10);//插入数据
s5.insert(40);
s5.insert(30);
s5.insert(20);
cout << "s5:"; Show(s5);//输出数据
return 0;
}
multiset定义和初始化如下:
#include <set>
#include <iostream>
using namespace std;
//输出s(升序)的所有数据
void Show(const multiset<int>& s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
//输出s(降序)的所有数据
void Show(const multiset<int, greater<int>>& s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
int main()
{
multiset <int> s0;//创建一个空的int set集合
s0.insert(5); //插入数据
s0.insert(3);
s0.insert(1);
s0.insert(2);
s0.insert(4);
s0.insert(4);//可以插入相同数据
multiset <int> s1(s0); //利用原来的set对象,创建一个新的set对象
multiset <int> s2 = s1;//同上
multiset <int> s3(s0.begin(), --s0.end());//利用迭代器创建一个新的set对象
multiset <int> s4{ { 1, 6, 3, 5, 4, 2 } };//利用初始化列表创建一个set对象
cout << "s0:"; Show(s0); //输出数据
cout << "s1:"; Show(s1);
cout << "s2:"; Show(s2);
cout << "s3:"; Show(s3);
cout << "s4:"; Show(s4);
cout << "降序的集合" << endl;
multiset <int, greater<int> > s5; //创建一个降序的set集合
s5.insert(10);//插入数据
s5.insert(40);
s5.insert(30);
s5.insert(20);
cout << "s5:"; Show(s5);//输出数据
return 0;
}
说明:multiset可以存放相同的元素。
特性
set 集合
- 唯一性:set中的元素是唯一的,当尝试插入一个已经存在于set中的元素时,插入操作将被忽略,不会产生重复元素。这一特性在数据去重方面极为便捷,比如在处理大量日志数据时,需要统计出现过的不同 IP 地址,使用set可以轻松实现去重。
- 自动排序:set会自动根据元素的比较规则(默认为小于运算符<)对元素进行排序。这意味着,在遍历set时,元素将按照升序依次输出。例如,在一个存储整数的set中,插入元素5、3、8后,遍历set会得到3、5、8的顺序。
multiset 集合
- 允许重复元素:这是multiset与set的主要区别。在multiset中,可以插入多个相同的元素,每个元素都会被正确存储和排序。例如,在一个存储单词出现次数的系统中,如果需要记录每个单词在文本中出现的所有位置,multiset可以方便地存储这些重复的位置信息。
- 自动排序:与set一样,multiset会根据元素的比较规则(默认为小于运算符<)自动对元素进行排序。这使得在查找和遍历multiset时,元素按照有序的方式呈现。例如,在一个存储员工年龄的multiset中,即使有多个员工年龄相同,遍历multiset时,年龄也会按照从小到大的顺序依次输出。
添加元素和删除元素
通过insert函数插入数据。通过erase删除元素。
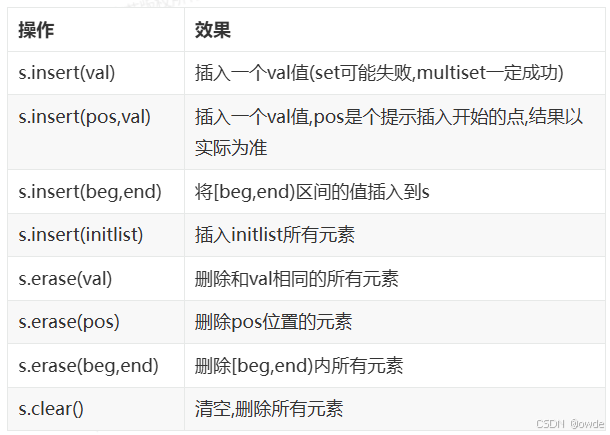
注意对于插入insert函数,其返回值有区别。

返回类型之所以不相同,原因是: multiset 允许元素重复而 set 不允许。因此,如果将某元素插入到 set 内,而该 set 已经包含该元素,插入数据将失败。所以set 的返回类型是以pair组织起来的两个值,pair结构中的first成员表示新元素的位置,second成员表示是否插入成功。
对于插入多个值的情况,返回值没有实际意义也就不返回了(void)。
//输出s(升序)的所有数据
void Show(const set<int>& s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
//输出s(升序)的所有数据
void Show(const multiset<int>& s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
int main()
{
set<int> s1;
s1.insert(4);
s1.insert(1);
s1.insert(5);
s1.insert(2);
cout << "s1:"; Show(s1);
auto p = s1.insert(5);
if (p.second)
cout << "往s1插入5成功" << endl;
else
cout << "往s1插入5失败" << endl;
cout << endl;
multiset<int> s2;
s2.insert(3);
s2.insert(7);
s2.insert(5);
s2.insert(1);
cout << "s2:"; Show(s2);
s2.insert(5);
cout << "往s2插入5后" << endl;
cout << "s2:"; Show(s2);
return 0;
}
常用迭代器
set和multiset支持双向迭代器,不支持随机迭代器,可以往前和往后,但不能+1,-1(这是随机迭代器)等。 常用的迭代器如下:

set和multiset常用的运算符
set和multiset类既支持常用的=,==,!=,< , >等运算符,也可以通过调用其成员函数来执行相应的操作。下面列举了其常用的操作。

//输出s(升序)的所有数据
void Show(const set<int>& s)
{
for (auto i : s)
cout << i << " ";
cout << endl;
}
int main()
{
set<int> s1;
s1.insert(4);
s1.insert(1);
s1.insert(5);
s1.insert(2);
cout << "s1:"; Show(s1);
set<int> s2;
s2 = s1;
cout << "s2:"; Show(s2);
if (s1 == s2)
cout << "s1 == s2" << endl;
s2.insert(7);
cout << "往s2插入7后,";
if (s1 > s2)
cout << "s1 > s2";
else if (s1 < s2)
cout << "s1 < s2";
//cout << s1[1] << endl;//错误
return 0;
}
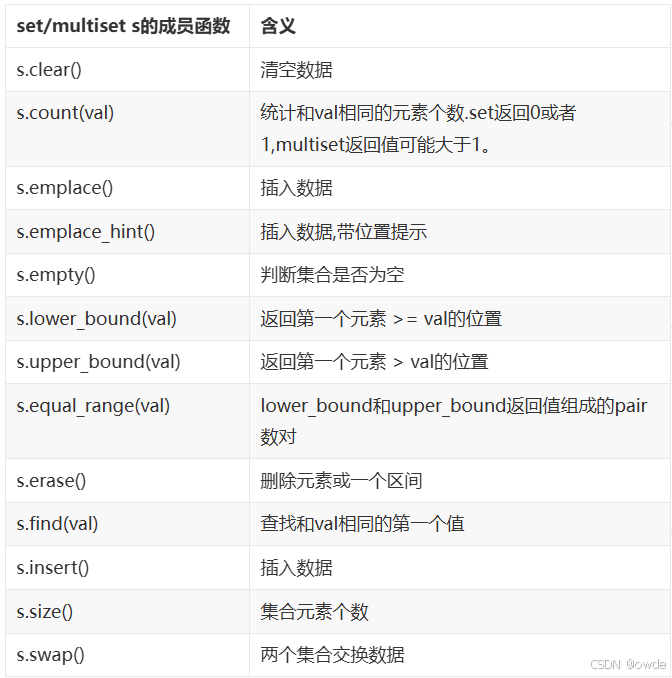
set和multiset常用成员函数
下面列举set和multiset对象常用的成员函数
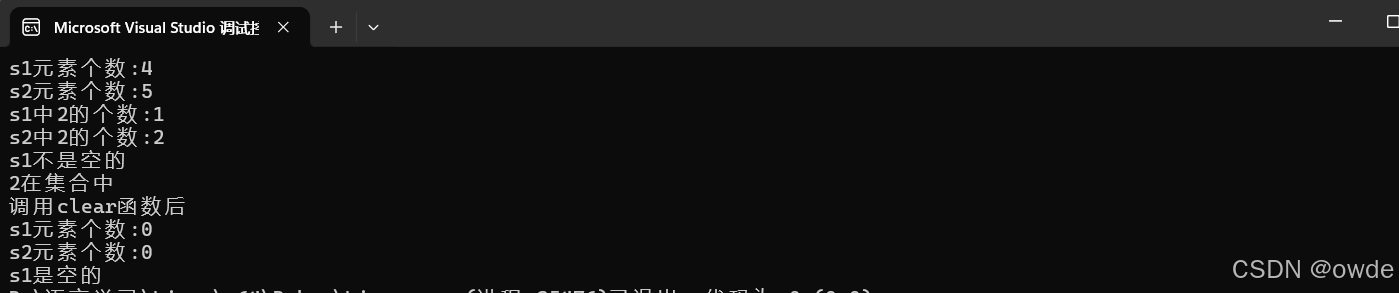
例子:
int main()
{
set<int>s1{ 1,4,2,3,2 }; //有一个重复的2不能添加
multiset<int>s2{ 1,4,2,3,2 };//有一个重复的2可以添加
cout << "s1元素个数:" << s1.size() << endl;
cout << "s2元素个数:" << s2.size() << endl;
cout << "s1中2的个数:" << s1.count(2) << endl;
cout << "s2中2的个数:" << s2.count(2) << endl;
if (s1.empty())
cout << "s1是空的" << endl;
else
cout << "s1不是空的" << endl;
int key = 2;
if (s1.find(key) != s1.end())//成功返回元素的迭代器,失败返回尾后迭代器
cout << key << "在集合中" << endl;
else
cout << key << "不在集合中" << endl;
s1.clear();
s2.clear();
cout << "调用clear函数后" << endl;
cout << "s1元素个数:" << s1.size() << endl;
cout << "s2元素个数:" << s2.size() << endl;
if (s1.empty())
cout << "s1是空的";
else
cout << "s1不是空的";
return 0;
}
set应用场景
set在C++中是一个内部自动有序且不含重复元素的容器,它的应用场景广泛且多样。以下是一些set的常见应用场景:
1.去重操作
当需要从一个数据集合中去除重复元素时,set是一个很好的选择。由于其不允许存储重复的元素,因此可以很容易地实现去重功能。这在处理原始数据或进行数据分析时特别有用。 题目: 给定一个字符串数组 words,请返回一个由 words 中所有不重复单词组成的列表,并按字母顺序排序。
示例:
输入:words = ["apple", "banana", "apple", "orange", "banana", "kiwi"]
输出:["apple", "banana", "kiwi", "orange"]
解释:去重后并按字母顺序排序得到的单词列表是 ["apple", "banana", "kiwi", "orange"]。
解题思路:
- 创建一个空的 set 对象,用于存储不重复的单词。
- 遍历字符串数组 words,将每个单词插入到 set 中。由于 set 会自动去重,并对单词排序。
- 将 set 中的单词转换为一个 vector 对象。
- 返回排序后的 vector 对象作为最终结果。
#include <iostream>
#include <vector>
#include <set>
#include <string>
using namespace std;
void UniqueWords(vector<string>& v) {
set<string> s(v.begin(), v.end()); // 利用set去重并自动排序
v = vector<string>{ s.begin(), s.end() }; // 将set中的单词复制到v中
}
int main() {
vector<string> v = { "apple", "banana", "apple", "orange", "banana", "kiwi" };
UniqueWords(v);
for (const auto& x : v) { //显示结果
cout << x << " ";
}
cout << endl;
return 0;
}
2.自动排序
如果需要对元素保持持续的排序状态,如维持一个按字母顺序排列的单词列表、存储并维护一个按年龄升序或降序排列的人口数据库等,std::set 可以实现这一功能。每次插入新元素,容器都会自动调整元素的顺序。 当然如果仅仅是排序,可以使用sort函数进行排序. sort排序是在排序瞬间的,如果又插入新的数据可能不再有序 set的有序是持续的,不管插入还是删除数据它始终有序
3.快速查找
由于set内部采用了高效的平衡查找二叉树(如红黑树),因此它提供快速的查找性能。包括检查元素是否已存在(.count() 或 .find()或.equal_range())、查找特定值的下一个/前一个元素(迭代器操作)。这对于实现诸如查找词汇表中的下一个更大词、或者在游戏中查找排名高于当前玩家的下一个玩家等场景很有用。
总结
set和multiset作为 C++ 标准库中强大的关联容器,各自以独特的特性在编程领域中占据重要地位。set通过唯一性和自动排序为数据去重、排序和快速查找提供了高效解决方案;multiset则凭借允许重复元素的特性,在统计元素出现次数等场景中发挥关键作用。深入理解它们的概念、特性、操作以及内部实现,能够帮助我们在面对各种编程任务时,准确选择合适的数据结构,编写出更加高效、优雅的代码。无论是在算法设计、数据处理还是系统开发中,set和multiset都将是我们得力的编程工具,助力我们在 C++ 的编程世界中不断探索前行。

















 1928
1928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









