






算法细节
首先,梯度提升回归是一种迭代的集成学习方法,其目标是利用多个弱学习器(通常为决策树)逐步修正前一模型的不足,最终构成一个强预测模型。
它采用加法模型的思想,每一步都在已有模型上加上一个新的弱学习器,方向选取是沿着损失函数的负梯度方向前进,从而实现损失的最小化。
模型训练
接下来咱们通过一个虚拟数据案例,用 Python 代码实现梯度提升回归的训练过程~
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
# 1. 数据生成
np.random.seed(42)
n_samples = 500
X = np.linspace(0, 10, n_samples).reshape(-1, 1)
# 目标函数:非线性正弦函数,加上均值为0、标准差为0.3的高斯噪声
y = np.sin(X).ravel() + np.random.normal(scale=0.3, size=n_samples)
# 数据集划分(训练集与测试集)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. 模型训练:设置弱学习器的个数、学习率和树的最大深度
gb_reg = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gb_reg.fit(X_train, y_train)
# 3. 模型预测
y_train_pred = gb_reg.predict(X_train)
y_test_pred = gb_reg.predict(X_test)
# 4. 绘制 Training Loss Curve(训练损失曲线)
# gb_reg.train_score_ 为每轮迭代在训练集上的损失
train_loss = gb_reg.train_score_
plt.figure(figsize=(10, 6))
plt.plot(np.arange(len(train_loss)), train_loss, color='red', lw=2, marker='o', label='Training Loss')
plt.xlabel('Number of Estimators', fontsize=12)
plt.ylabel('Loss', fontsize=12)
plt.title('Training Loss Curve', fontsize=14)
plt.legend()
plt.grid(True)
plt.show()
# 5. 绘制 Predicted vs True Plot(预测值与真实值对比图)
plt.figure(figsize=(10, 6))
plt.scatter(X_test, y_test, color='blue', alpha=0.6, label='True Values', s=50)
plt.scatter(X_test, y_test_pred, color='green', alpha=0.6, label='Predicted Values', s=50)
plt.xlabel('Input Feature', fontsize=12)
plt.ylabel('Target Value', fontsize=12)
plt.title('Predicted vs True Values', fontsize=14)
plt.legend()
plt.grid(True)
plt.show()
# 6. 绘制 Residual Plot(残差图)
residuals = y_test - y_test_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_test_pred, residuals, color='magenta', alpha=0.6, s=50)
plt.axhline(y=0, color='black', linestyle='--', lw=2)
plt.xlabel('Predicted Values', fontsize=12)
plt.ylabel('Residuals', fontsize=12)
plt.title('Residual Plot', fontsize=14)
plt.grid(True)
plt.show()
# 7. 绘制 Residual Histogram(残差直方图)
plt.figure(figsize=(10, 6))
plt.hist(residuals, bins=30, color='orange', edgecolor='black', alpha=0.8)
plt.xlabel('Residual', fontsize=12)
plt.ylabel('Frequency', fontsize=12)
plt.title('Residual Histogram', fontsize=14)
plt.grid(True)
plt.show()
-
数据生成与划分:利用正弦函数构造非线性关系,并加入噪声,随后划分训练集与测试集,以便分别训练模型和评估模型泛化能力。
-
模型训练:利用
GradientBoostingRegressor构造模型,设定弱学习器个数为 100、学习率为 0.1、最大树深为 3。训练过程中,每轮迭代会计算当前模型在训练集上的损失,并保存到train_score_中。
数据分析方面,我们整理了四方面图表供大家理解:
-
Training Loss Curve(训练损失曲线)
-
Predicted vs True Plot(预测值与真实值对比图)
-
Residual Plot(残差图)
-
Residual Histogram(残差直方图)
Training Loss Curve
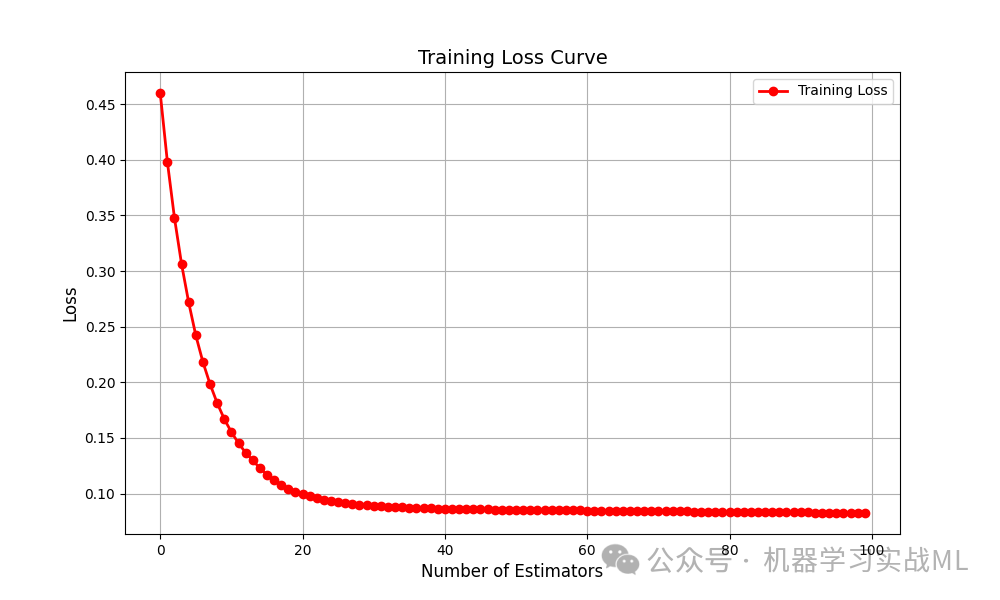
展示每轮迭代中训练集损失的变化情况。若曲线持续平滑下降,说明模型在不断地捕捉数据中的信息;若在后期出现平台期,则说明模型已接近最优。
若训练损失急剧下降后长时间不变,可能需要调整弱学习器的复杂度或学习率;反之,若损失下降缓慢或震荡,可能存在欠拟合或模型不稳定的问题。
Predicted vs True Plot
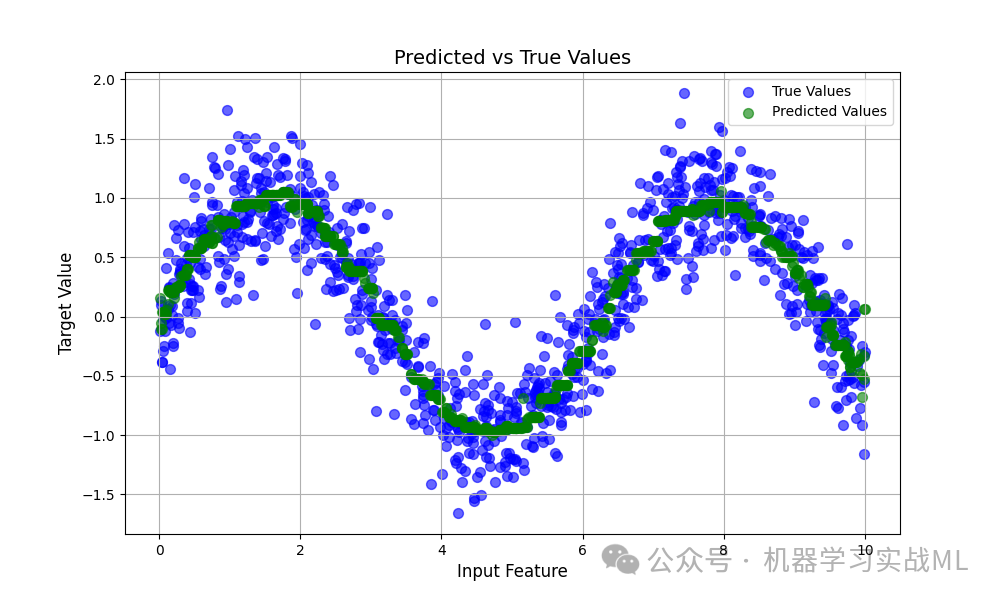
对比测试集中真实值与预测值的散点分布,理想情况下,所有点应分布在对角线附近,即。
如果大部分点偏离对角线,说明模型预测存在系统性偏差;观察不同区间的分布也能反映模型在各个取值范围内的表现一致性。
Residual Plot
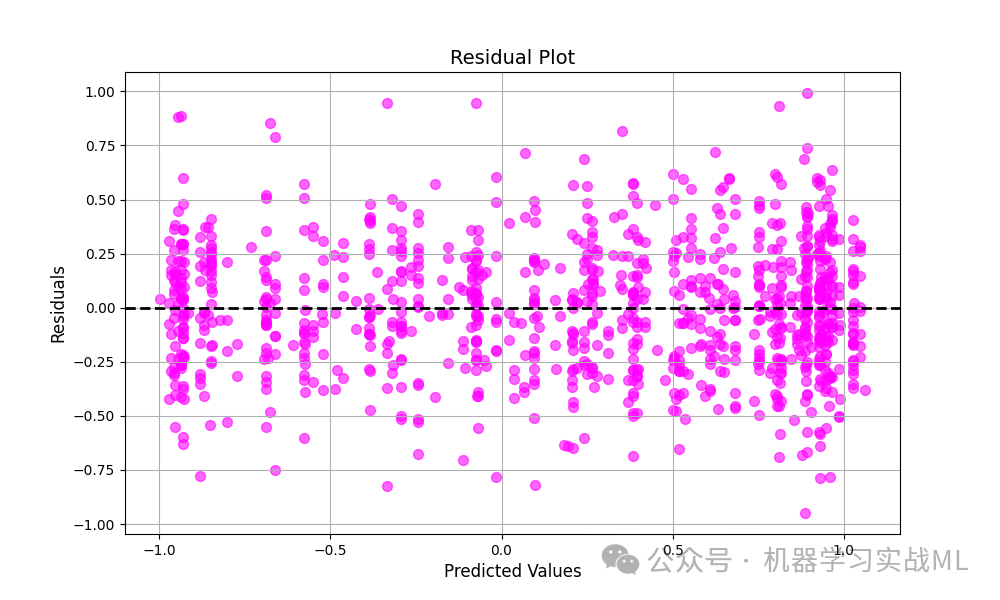
残差图用于检查预测误差是否随机分布。理想情况下,残差应在零附近随机分布,无明显的模式或趋势。
如果残差呈现某种模式(例如随预测值增大而增大),可能暗示模型存在异方差性或部分区域未被充分拟合。
Residual Histogram
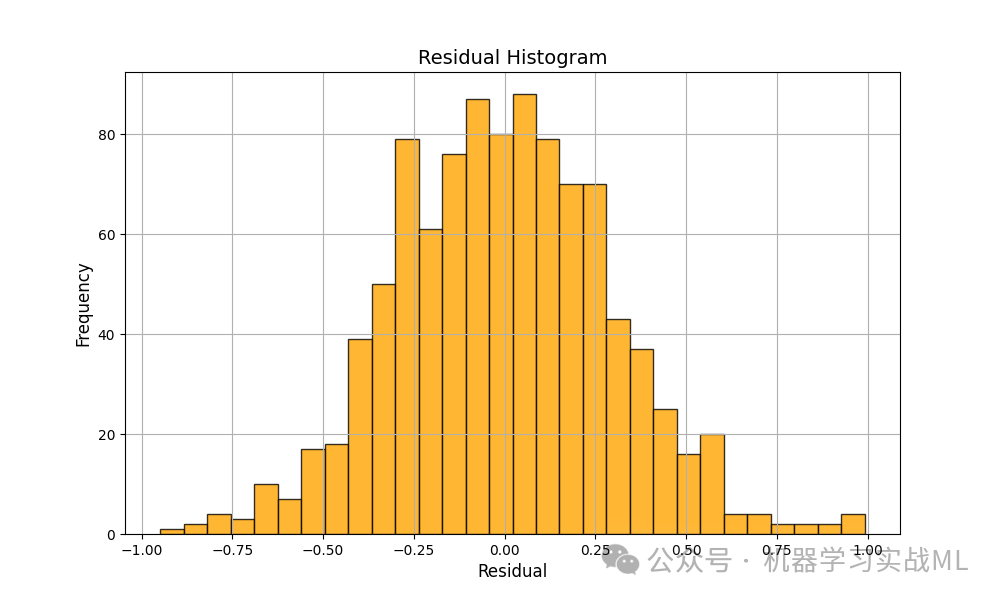
分析残差的分布形态,检测其是否近似正态分布。正态分布的残差通常说明模型假设合理,误差主要来自随机噪声。
如果直方图呈现明显偏态或多峰分布,可能需要进一步探究数据中的异常值、非线性关系未捕捉或者存在其他变量未考虑。


















 4502
4502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









