






 本文详细介绍了使用Python爬虫从网页抓取图片的过程,涉及requests库发送HTTP请求,re库处理正则表达式提取图片源地址,以及os库进行文件操作。步骤包括获取网络源代码、提取图片地址、获取二进制源码、保存图片到文件夹等。
本文详细介绍了使用Python爬虫从网页抓取图片的过程,涉及requests库发送HTTP请求,re库处理正则表达式提取图片源地址,以及os库进行文件操作。步骤包括获取网络源代码、提取图片地址、获取二进制源码、保存图片到文件夹等。
当我们想要从浏览器中下载大量的图片时,我们可以用爬虫。
爬虫需要用到的三个重要的包requests、re和os包。
requests是一个常用的第三方库,它提供了一组简洁而强大的函数,用于发送HTTP请求和处理响应。
re是Python中的标准库之一,用于处理正则表达式)。正则表达式是一种强大的模式匹配语言,用于在文本中查找、匹配和操作字符串。
os是Python中的标准库之一,用于与操作系统交互,例如访问文件系统、运行新的进程等。
接下来让我们来学习如何爬虫百度图片吧。
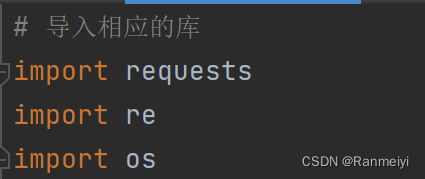
一、导入相应的库
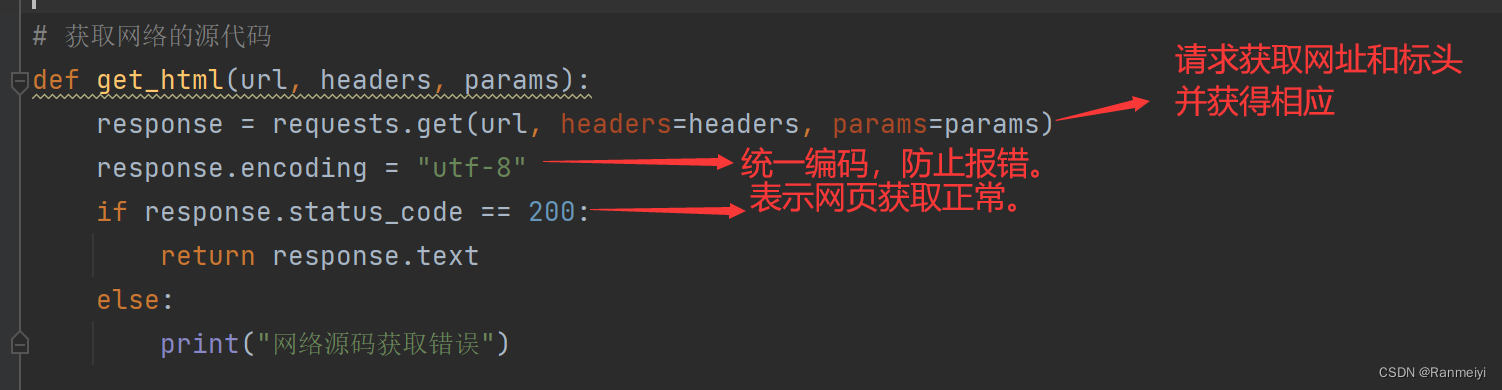
二、获取网络源代码
我们要创建一个函数,来获取网络的源代码。
三、提取图片的源地址
我们继续创建一个函数,来提取图片的源地址。

四、获取图片的二进制源码
我们创建函数,获取图片的二进制源码。
通过获取图片的二进制源码,让图片的格式正常。

五、定义一个新建文件夹函数
我们创建一个新建文件夹函数,让我们的图片保存到文件夹里。

六、保存图片
我们再创建一个函数,来执行保存图片。

七、定义main函数
这一步我们定义一个main函数,来调用前面创建的get_html函数。
首先我们要获取网络的url。
我们先点击鼠标右键,再点击检查或者点击F12。
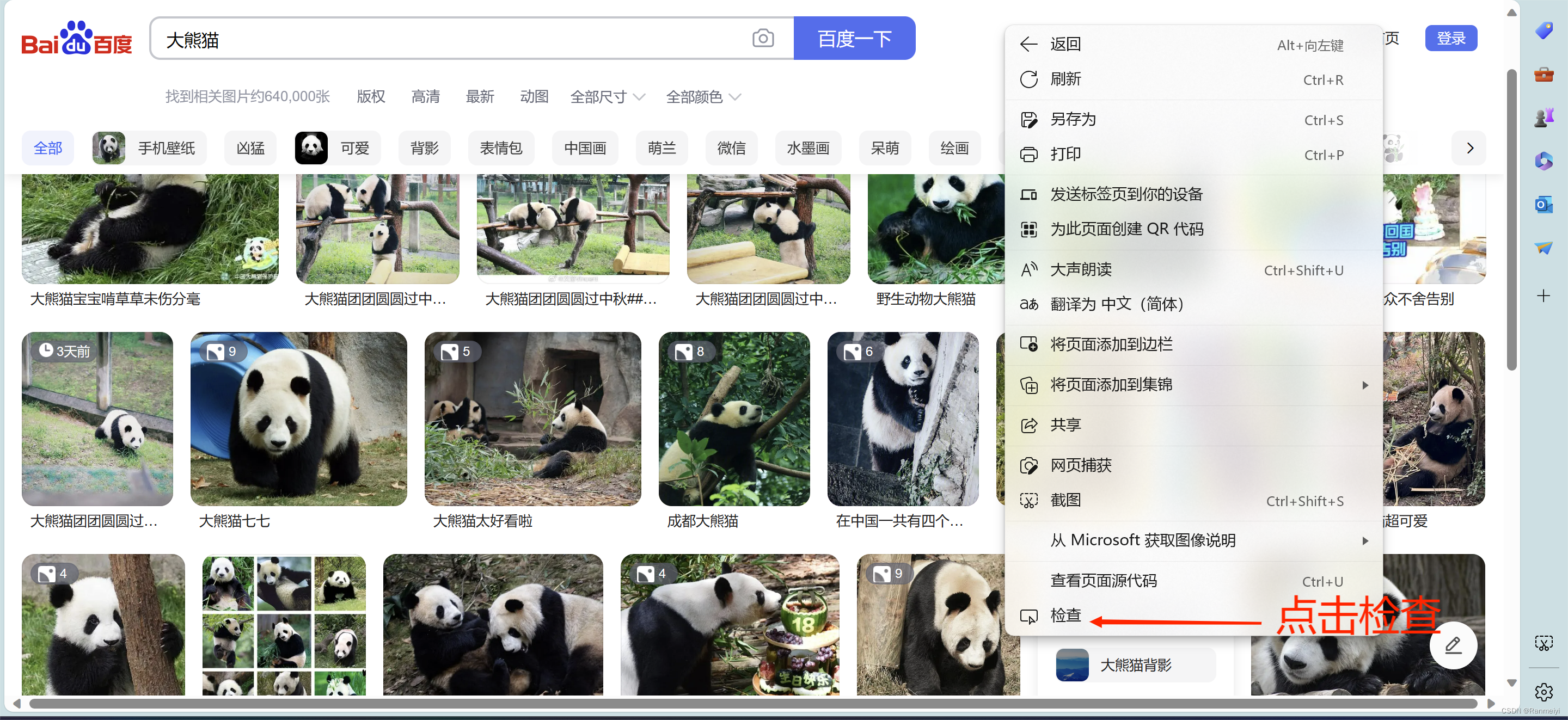
然后点击网络。
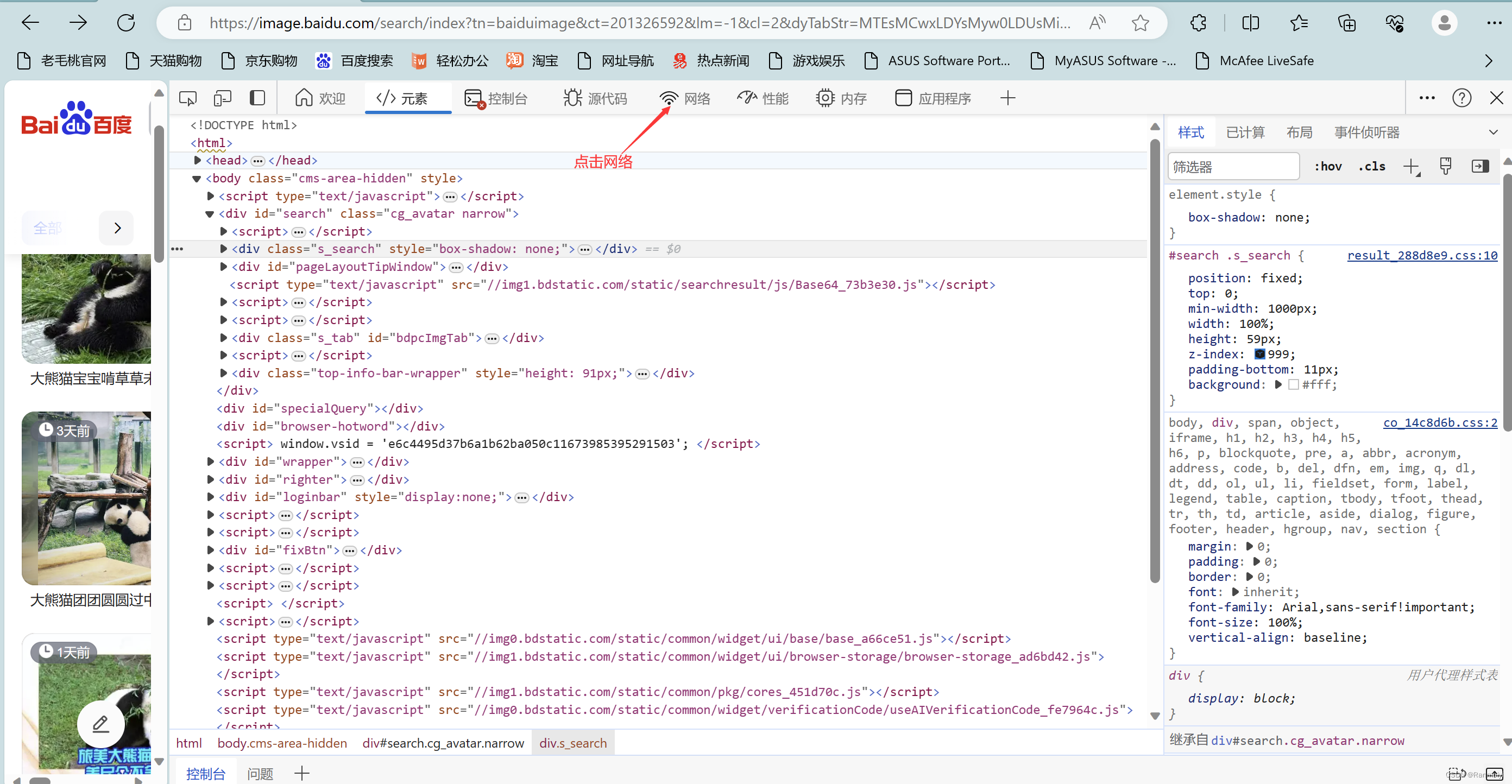
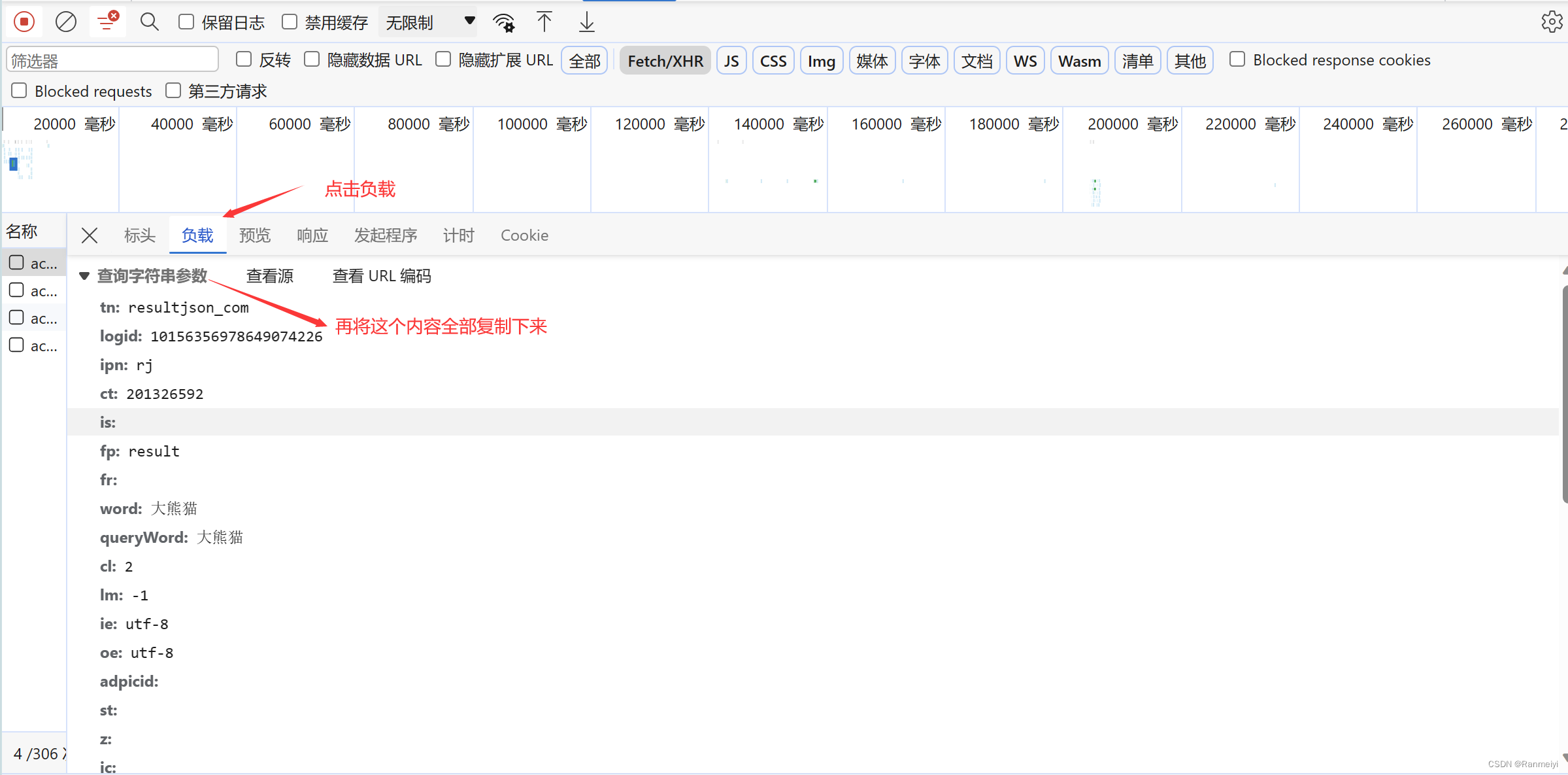
我们再选择Fetch/XHR这里,再点击如下图标注的地方。
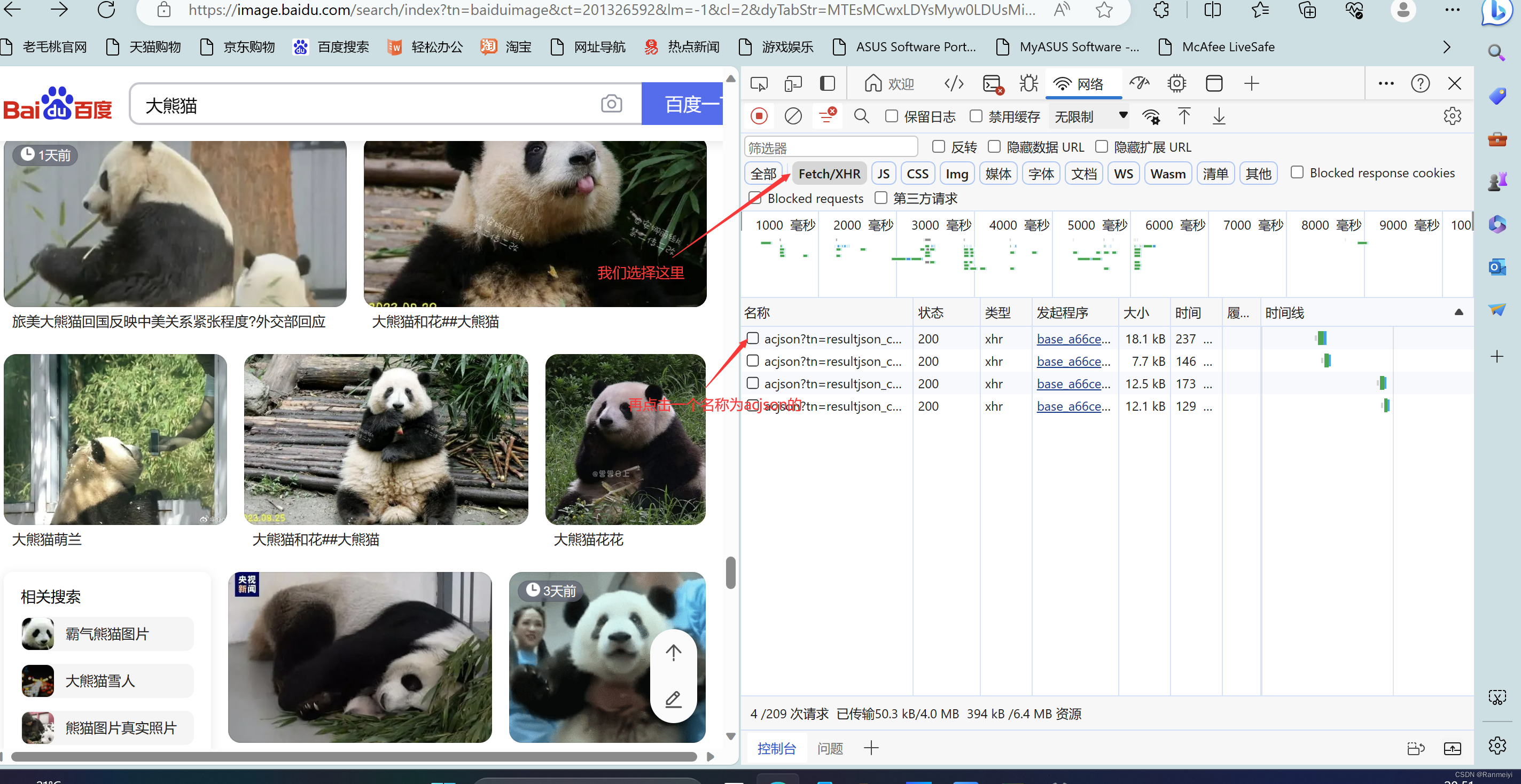
进入下面图上这个位置,再将上面的请求url复制下来。
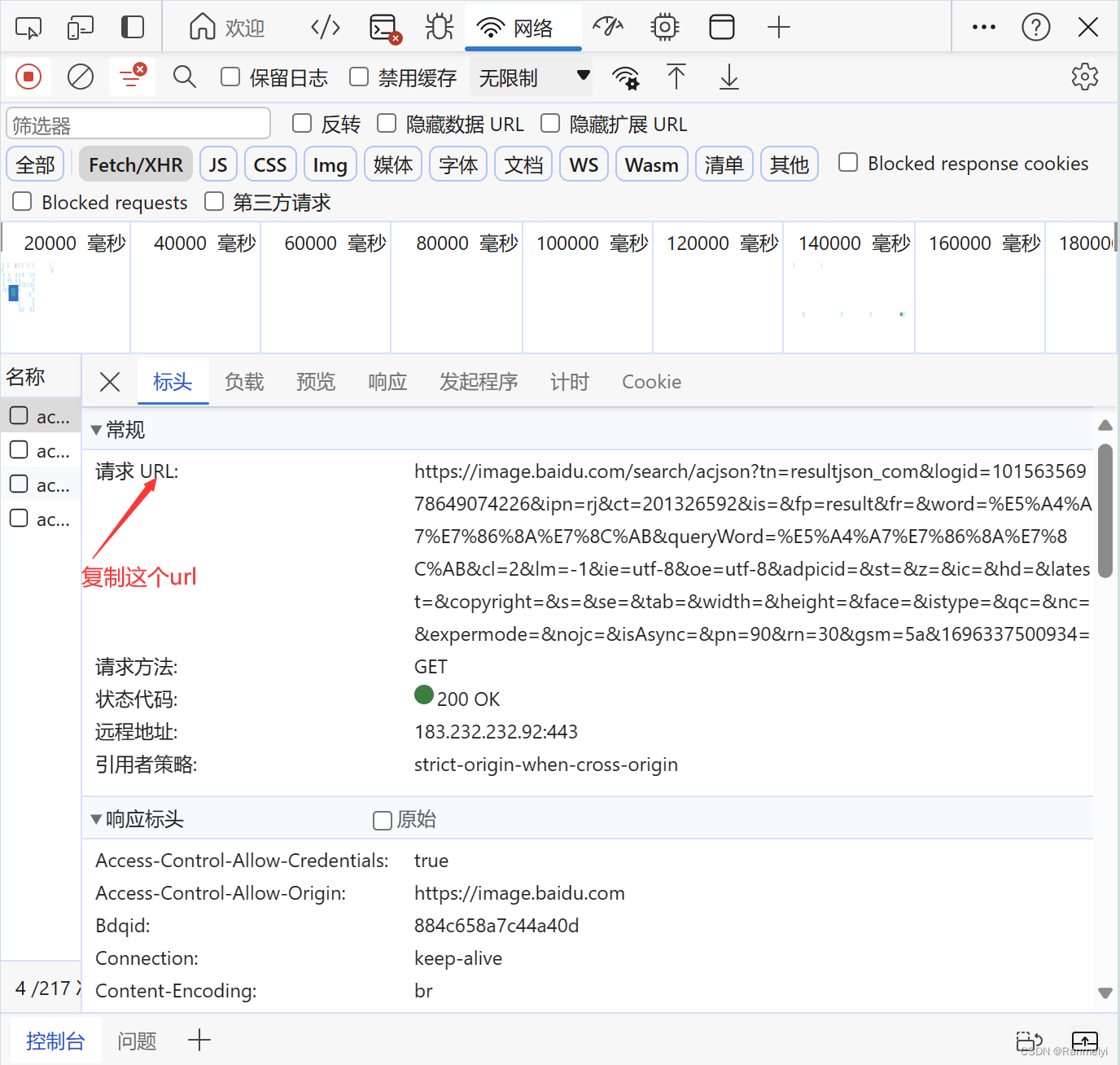
再将复制的url,粘贴在下图的地方。
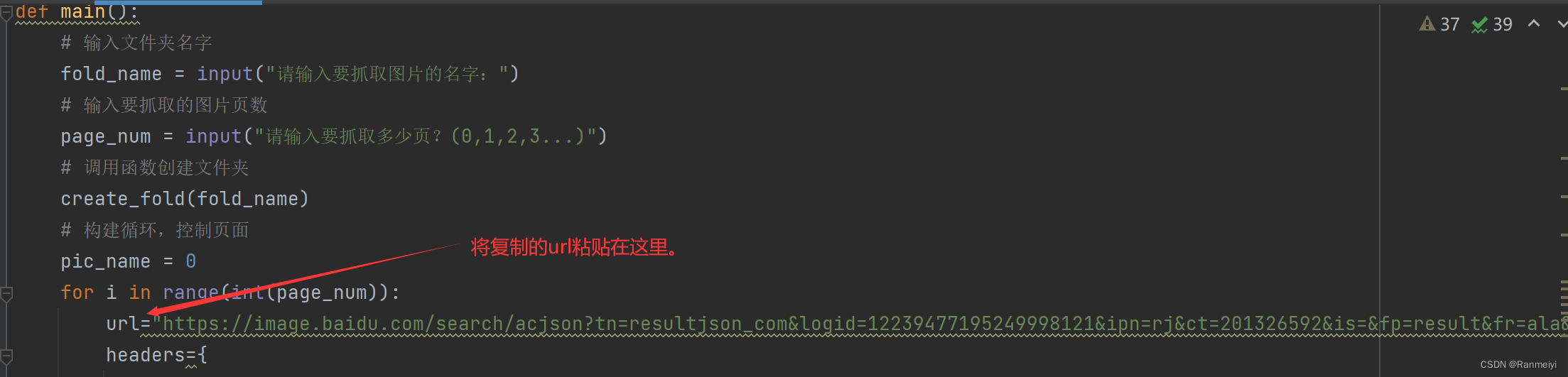
我们还需要复制它的请求标头。
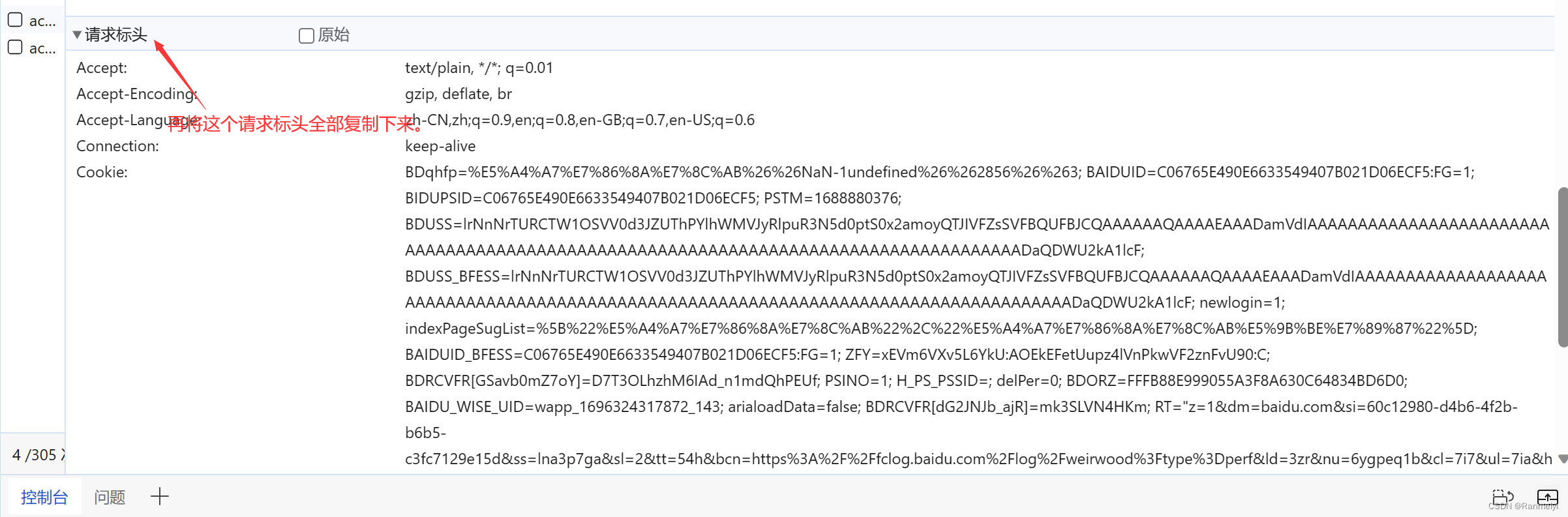
并粘贴至此处。
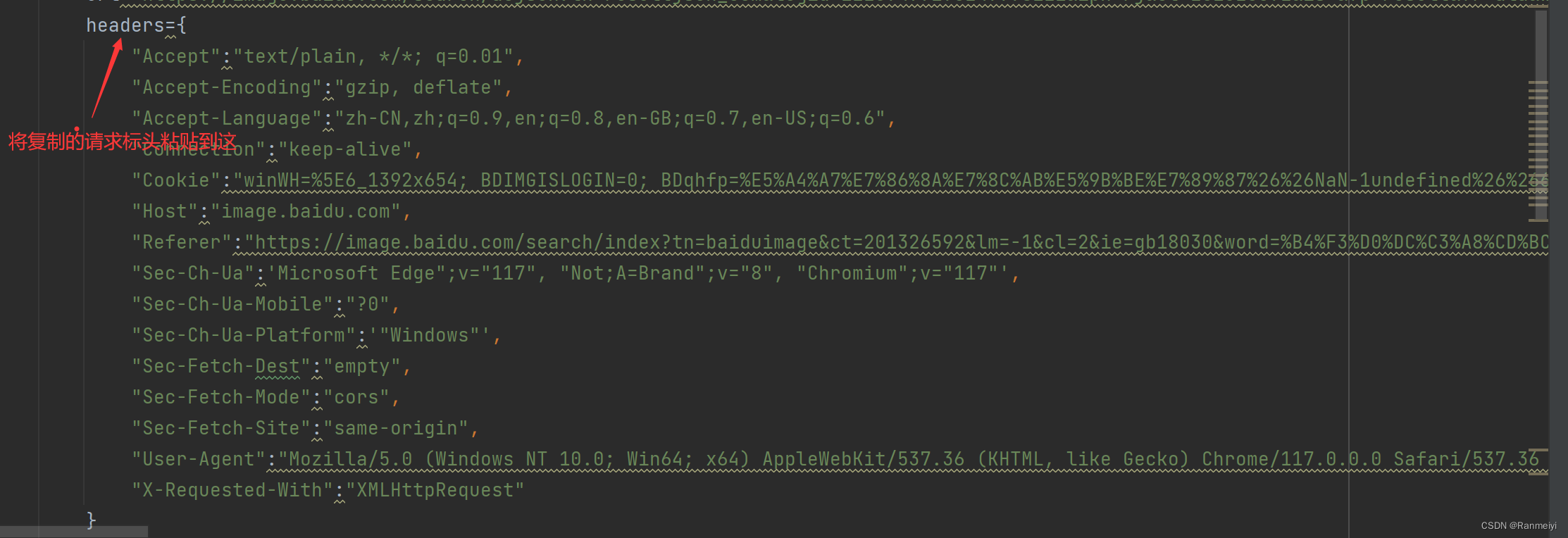
接下来,都根据下面图上的标注来一步一步的进行。
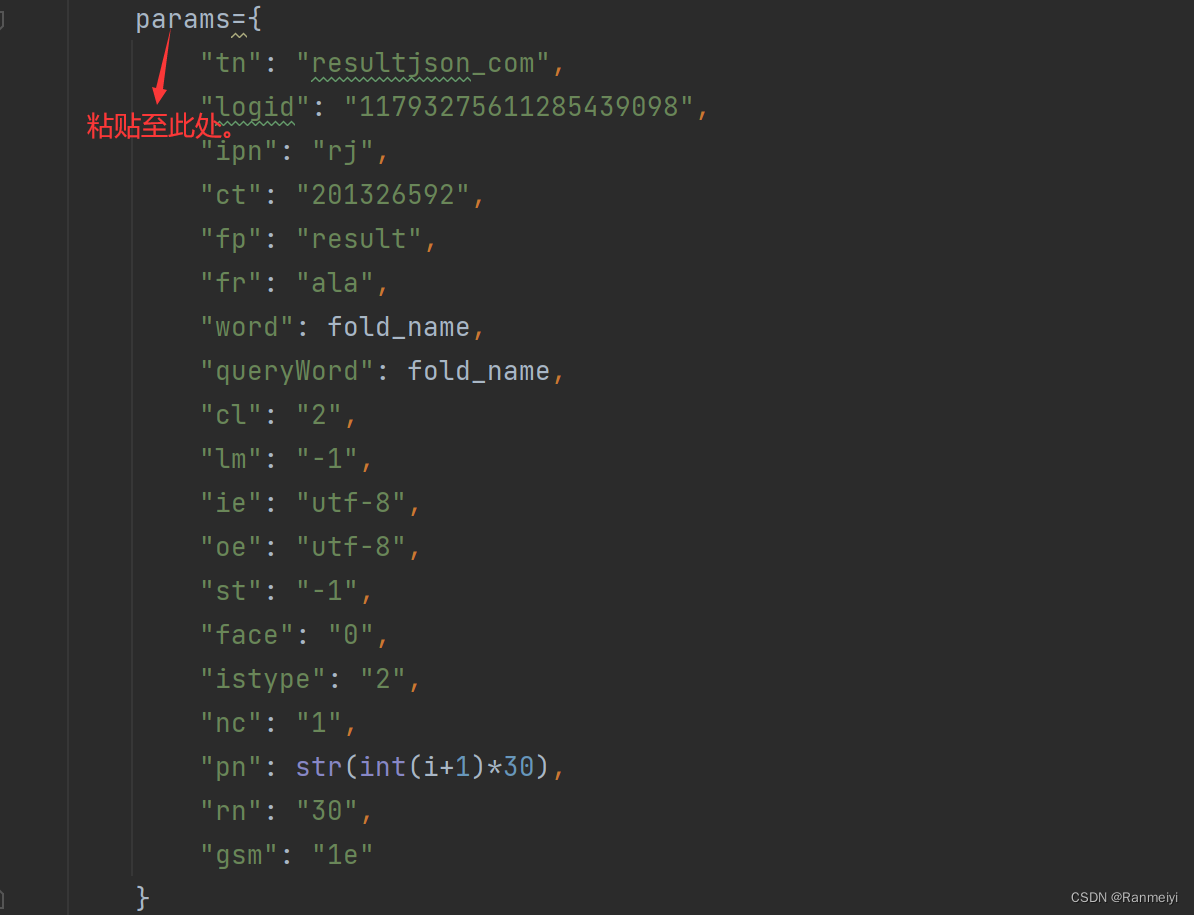
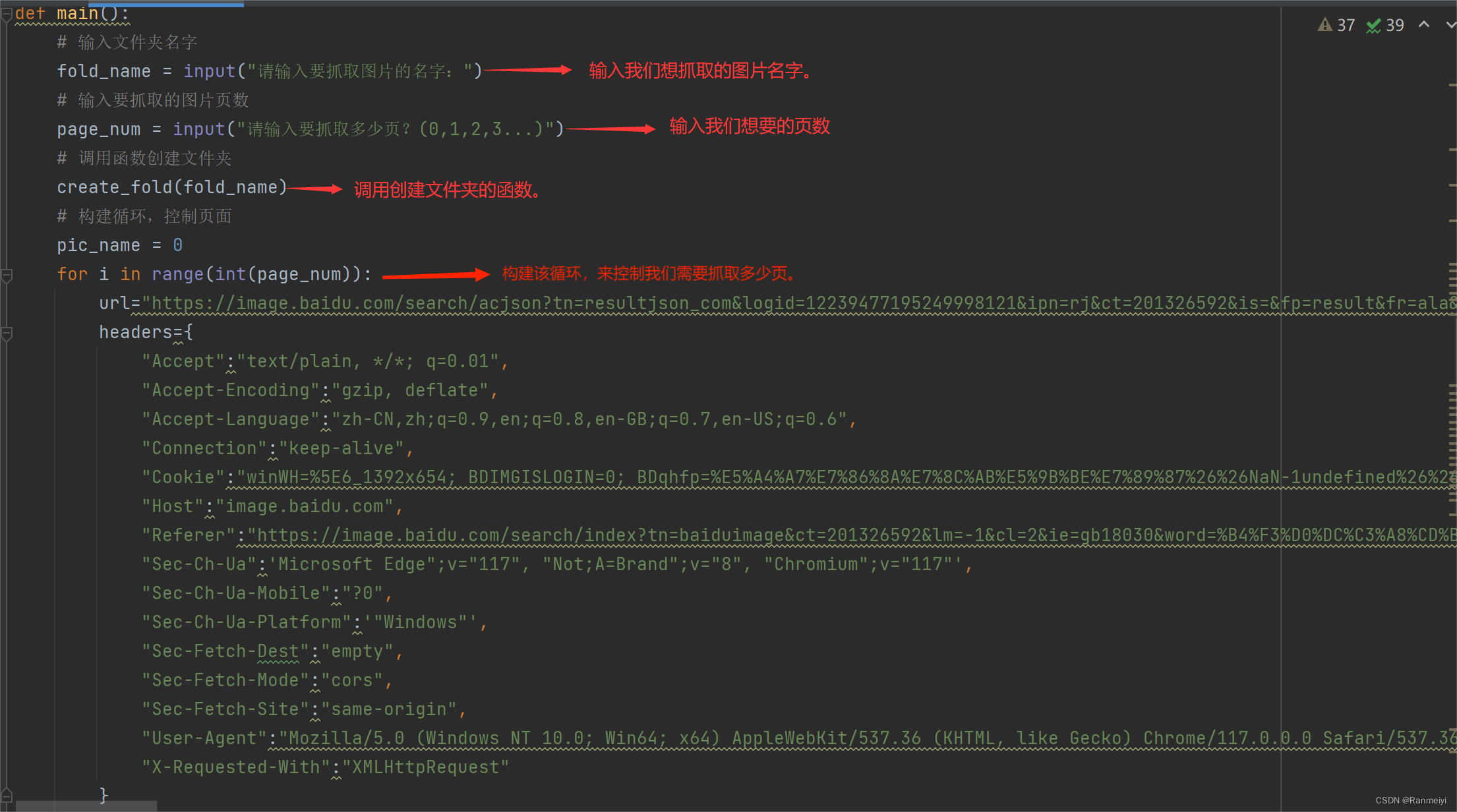
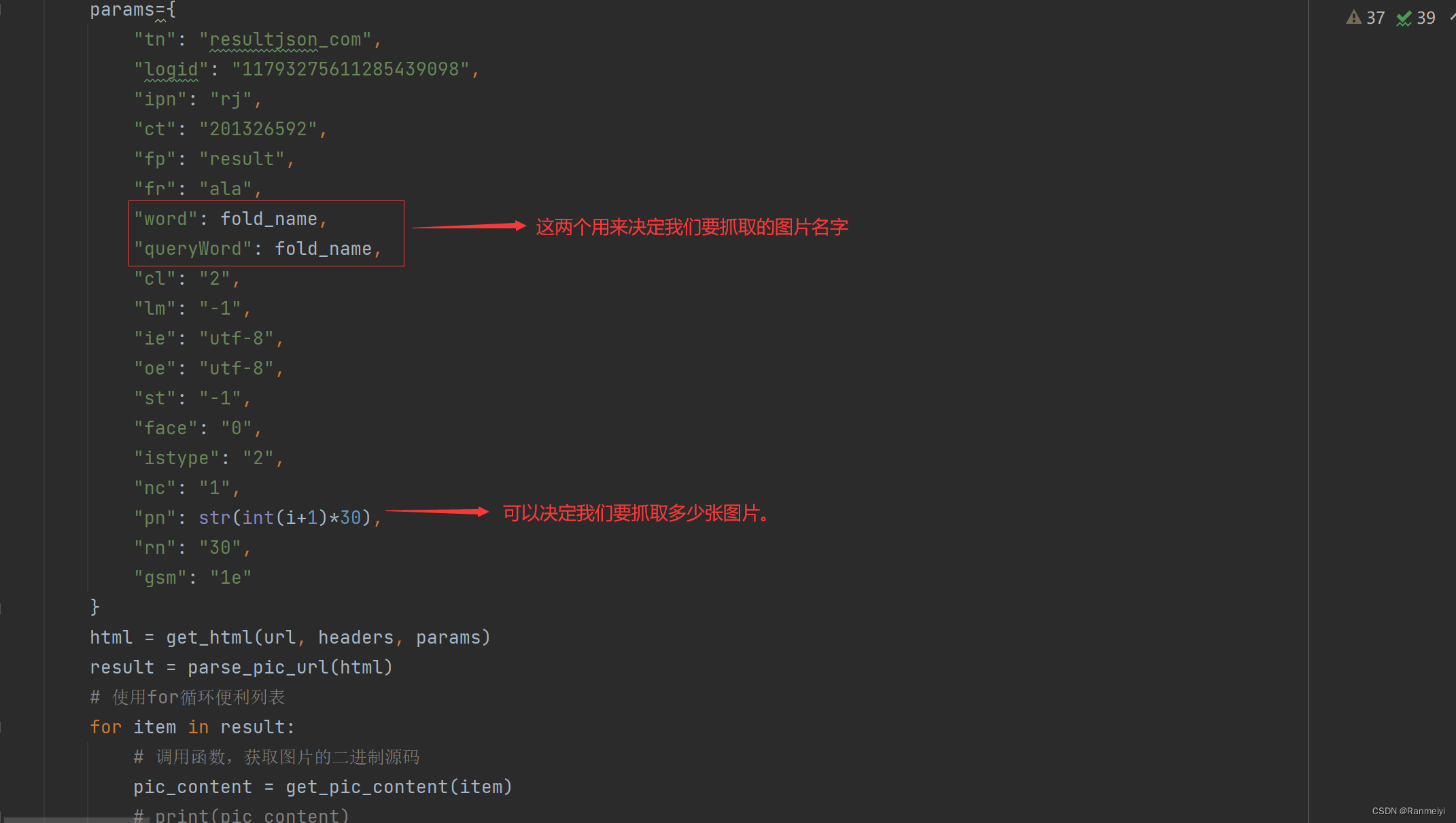
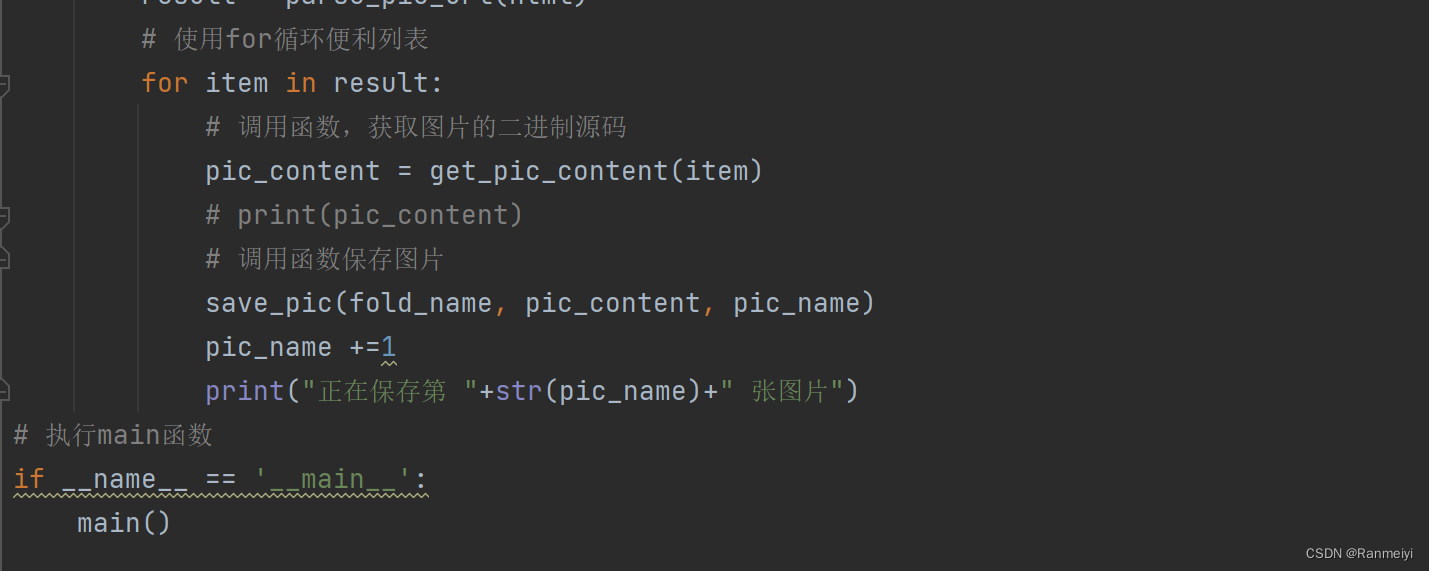
以上内容就是我们如何来抓取图片的步骤。希望能够帮助大家。

















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









