







目录

任务目标:
希望创建一个脚本,用户可以输入想要下载图片的关键字以及下载文件数量,然后程序可以爬取百度图片。
前言
最开始,我们想要爬取图片,首先需要打开百度图库,然后在搜索栏中输入自己想要的图片(比如说壁纸)。
接着右键检查,点击网络:
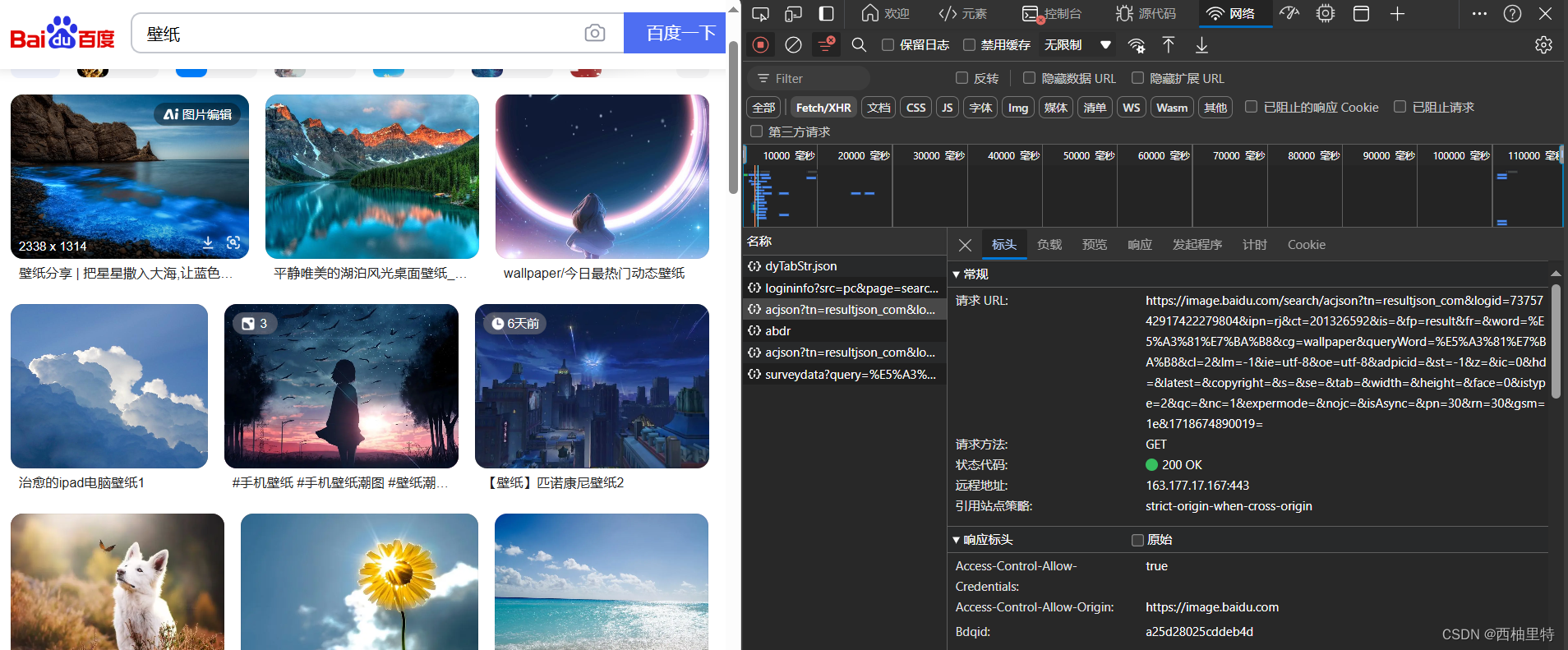
起初可能没有名称信息,刷新界面就可以了。
打开![]() 信息,查看标头内容
信息,查看标头内容
可以看到请求URL为:
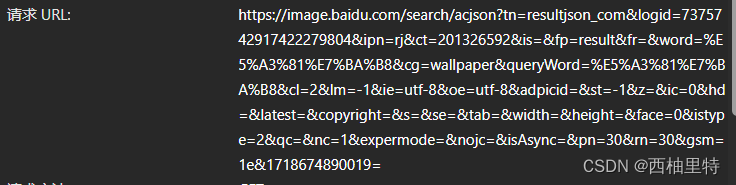
复制这串URL,然后在浏览器中打开
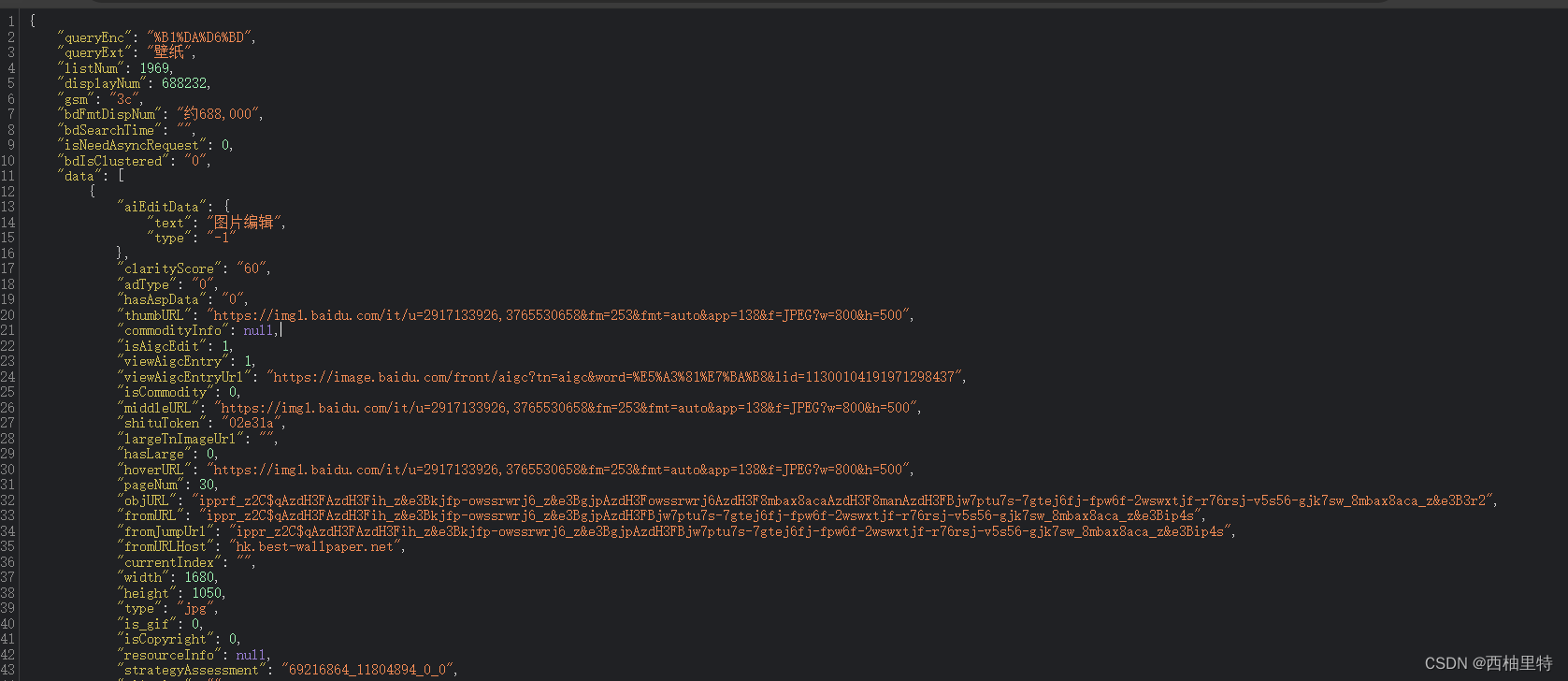
这个就是我们搜索的壁纸图片的网页内容。
怎么找到图片的URL呢?在上述内容中,找到data,可以发现里面每隔一个aiEditData,下面代码的形式是一样的,就相当于一张图片。
找到hoverURL:
![]()
复制在浏览器中打开就是一张图片了:

所以爬取的实质就是找到网页里面图片的hoverURL,然后进行下载。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1248
1248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









