






正则表达式
正则表达式是一种用于匹配、搜索和操作文本的强大工具。它是由一系列字符和特殊字符组成的模式,可以用于检查文本中是否包含特定的模式或者从文本中提取需要的信息。
当我们需要用正则表达式时,我们首先需要导入包import re.它提供各种正则表达式的匹配操作。
匹配方法一:我们可以直接用\s、\d分别来匹配空格和数字,有几个空格就用几个\s和有几个数字就用几个\d.然后用()创建一个group()组,将我们需要的模式放在里面,形成一个组。如下图所示:
注意:re.match只能从字符串的开头开始匹配。

结果如下:

方法二:我们为了省略\d 我们可以直接使用,\d{}来表示,{}里面输入数字的个数。如下图所示:

结果如下:

方法三:当我们遇见的数字和其他符号太多了时,我们直接在\b后面加一个+,匹配其他字符也是同样的道理。如下图所示:
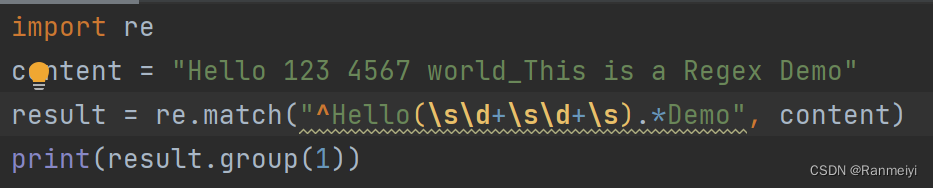
结果如下:

如果我们只想匹配我们需要的数据,我们可以用\D匹配掉我们不需要其他字符。如下图所示:

结果如下:

贪婪匹配
贪婪匹配(Greedy matching)是正则表达式中的一种匹配模式。当使用贪婪匹配时,正则表达式会尽可能地匹配更长的字符串。(.*表示匹配多个任意字符。)如下图所示:
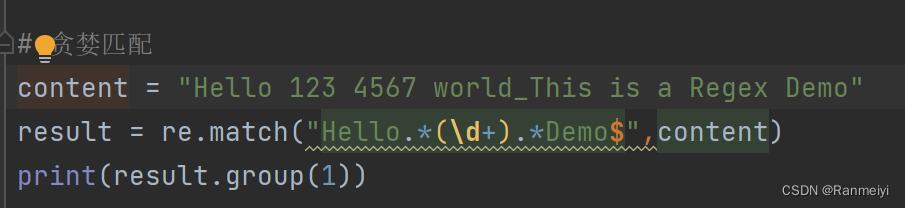
结果如下:

非贪婪匹配
非贪婪匹配(non-greedy matching)是一种正则表达式的概念,用于在匹配文本时尽可能少地匹配字符。我们通常用.*?来表示非贪婪匹配。如下图所示:

结果如下:

re.search扫描整个字符串并返回第一个成功匹配的。为了匹配方便,能用search就不用match.

结果如下:

我们解释一下,re.S的作用。

re.findall是找到 re 匹配的所有子串,并把它们作为一个列表返回。如下图所示:
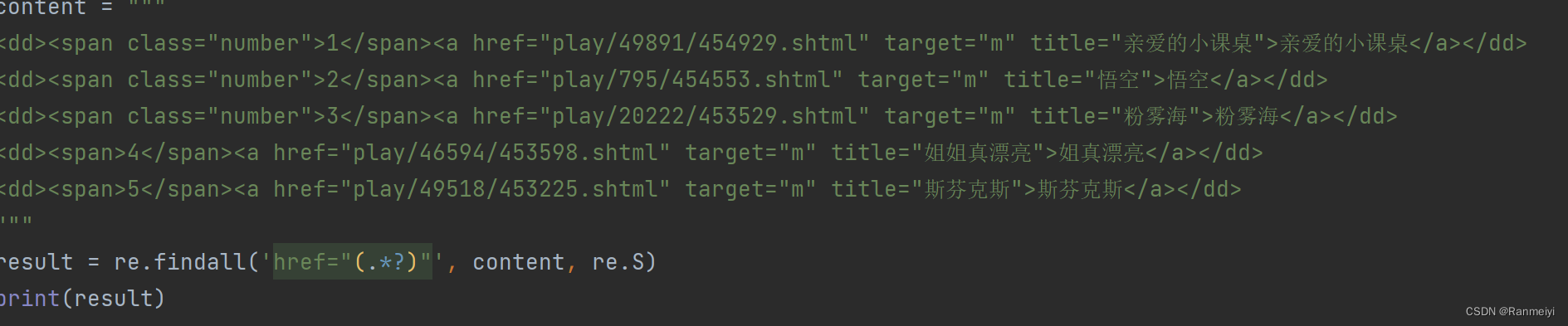
结果如下:

以上就是正则表达式的简单讲述。希望能对大家有帮助。

















 2695
2695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









