



首先先不要回答,根据用户的提问先进行联网搜索
# 根据用户输入的问题,调用SerperAPI执行联网检索,返回search_top_k个相关的链接
search_results = await search(query, search_top_k)async def search(query, num, locale=''):
"""
定义一个异步函数,用于发起Serper API的实时 Google Search
"""
# 初始化参数字典,包含搜索查询词和返回结果的数量
params = {
"q": query, # 搜索查询词
"num": num, # 请求返回的结果数量
"hl": "zh-cn"
}
# 如果提供了地区设置,则添加到参数字典中
if locale:
params["hl"] = locale # 'hl'参数用于指定搜索结果的语言环境
try:
# 使用异步方式调用get_search_results函数,传入参数字典
# 确保get_search_results是异步函数
search_results = await get_search_results(params=params)
return search_results # 返回搜索结果
except Exception as e:
# 如果搜索过程中出现异常,打印错误信息并重新抛出异常
print(f"search failed: {e}")
raise easync def get_search_results(params):
try:
# Serper API 的 URL
url = URL
# 从环境变量中获取 API 密钥
params['api_key'] = SERPER_API_KEY
# 使用 aiohttp 创建一个异步 HTTP 客户端会话
async with aiohttp.ClientSession() as session:
# 发送 GET 请求到 Serper API,并等待响应
async with session.get(url, params=params) as response:
# 解析 JSON 响应数据
data = await response.json()
# 提取有效的搜索结果
items = data.get("organic", [])
results = []
for item in items:
# 为每个搜索结果生成 UUID(MD5 哈希)
item["uuid"] = hashlib.md5(item["link"].encode()).hexdigest()
# 初始化搜索结果的得分
item["score"] = 0.00
results.append(item)
return results
except Exception as e:
# 记录错误信息
print("get search results failed:", e)
raise e
aiohttp.ClientSession() 是 aiohttp 库中的一个异步 HTTP 客户端会话对象,用于执行 HTTP 请求(如 GET、POST、PUT 等)。它提供了异步(async) 的方式来发送 HTTP 请求,适用于高并发场景,如爬虫、API 调用等。

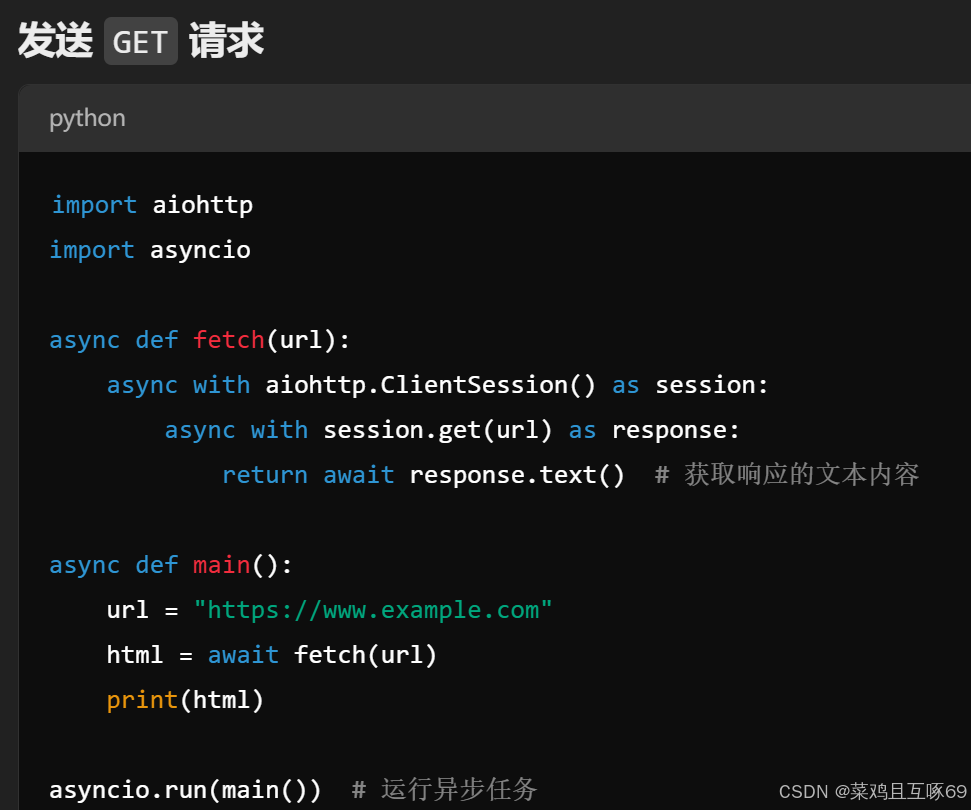
对检索到的网页重排序
# 对检索到的网址链接,通过计算 query 和 每个网站的简介,进一步做 rerank,提取最相关的一个网址
rerank_results = reranking(query, search_results)def reranking(query, search_results, top_k=SEARCH_RERANK_TOP_K):
# 将第一轮联网检索得到的网页信息构建成Document对象
documents = build_document(search_results=search_results)
# 计算query 与 每一个检索到的网页的snippet的文本相似性,判断其网页是否与当前的query高度相关
normal = NormalizedLevenshtein()
for x in documents:
x.metadata["score"] = normal.similarity(query, x.page_content)
# 降序排序
documents.sort(key=lambda x: x.metadata["score"], reverse=True)
# 返回最相关的 top_k 个网页信息数据
return documents[:SEARCH_RERANK_TOP_K]
# 对经过rerank 的 网站,提取主体内容
# 对经过rerank 的 网站,提取主体内容。
detail_results = await fetch_details(rerank_results)加载url中的全部信息,转化为text,在转换为makedown,然后切分为chunks,加载到向量数据库中
async def fetch_details(search_results):
# 获取要提取详细信息的url
urls = [document.metadata['link'] for document in search_results if 'link' in document.metadata]
try:
details = await batch_fetch_urls(urls)
except Exception as e:
# 如果批量获取失败,抛出异常
raise e
# details 填充为(url, content)元组列表
content_maps = {url: content for url, content in details}
# 直接在 search_results 上更新 page_content
for document in search_results:
# 使用属性访问方式获取链接信息
link = document.metadata['link'] # 确保 Document 类定义了 metadata 属性且是一个字典
if link in content_maps:
# 直接更新 Document 对象的 page_content 属性
document.page_content = content_maps[link]
text_splitter = RecursiveCharacterTextSplitter(chunk_size=700, chunk_overlap=100)
chunks = text_splitter.split_documents(search_results)
return chunksmilvus向量数据库使用及示例
-----------------------------------------------------
# 主调用代码需要被包装在一个异步函数中
async def main():
# 创建一个 milvus 对象, 用于测试milvus的连通性
milvusService = MilvusKBService("milvus_test")
print(f"milvus_kb_service: {milvusService}")
from server.knowledge_base.kb_service.base import KBServiceFactory
kb = await KBServiceFactory.get_service_by_name("milvus_test")
# 如果想要使用的向量数据库的collecting name 不存在,则进行创建
if kb is None:
from server.db.repository.knowledge_base_repository import add_kb_to_db
# 先在Mysql中创建向量数据库的基本信息
await add_kb_to_db(kb_name="milvus_test",
kb_info="milvus",
vs_type="milvus",
embed_model="bge-large-zh-v1.5",
user_id="ff4f9954-da8c-492f-965d-dc18224b1176")
# 调用 add_doc 方法添加一个名为 "README.md" 的文桗,确保使用 await
await milvusService.add_doc(KnowledgeFile("README.md", "milvus_test"))
# 根据输入进行检索
search_ans = await milvusService.search_docs(query="RAG增强可以使用的框架?")
print(search_ans)开始分析:
# 创建一个 milvus 对象, 用于测试milvus的连通性
milvusService = MilvusKBService("milvus_test")这个是要执行MilvusKBService的构造方法
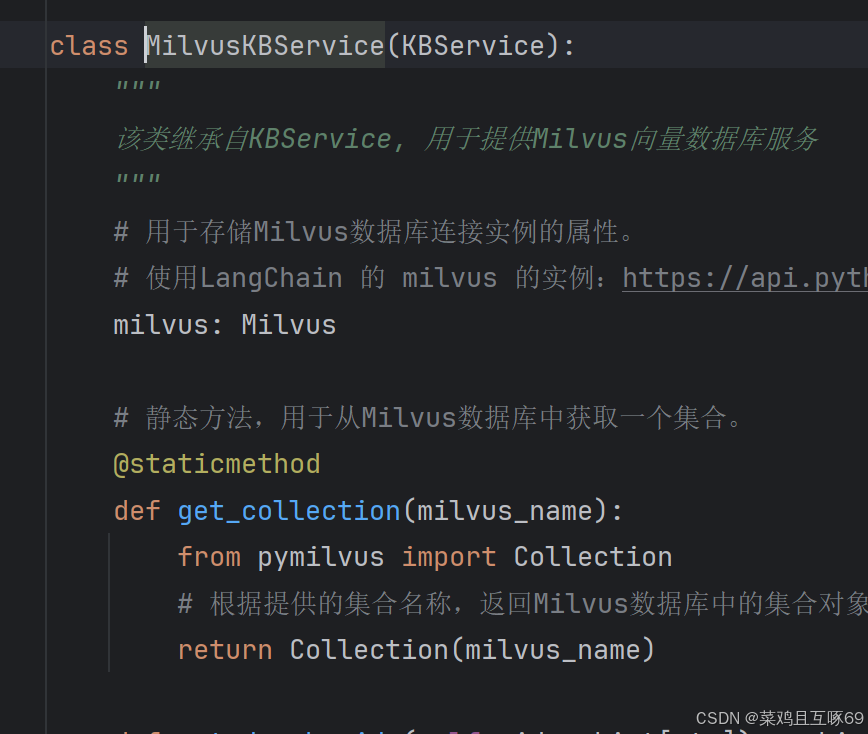
发现没有,所以走父类的构造方法,
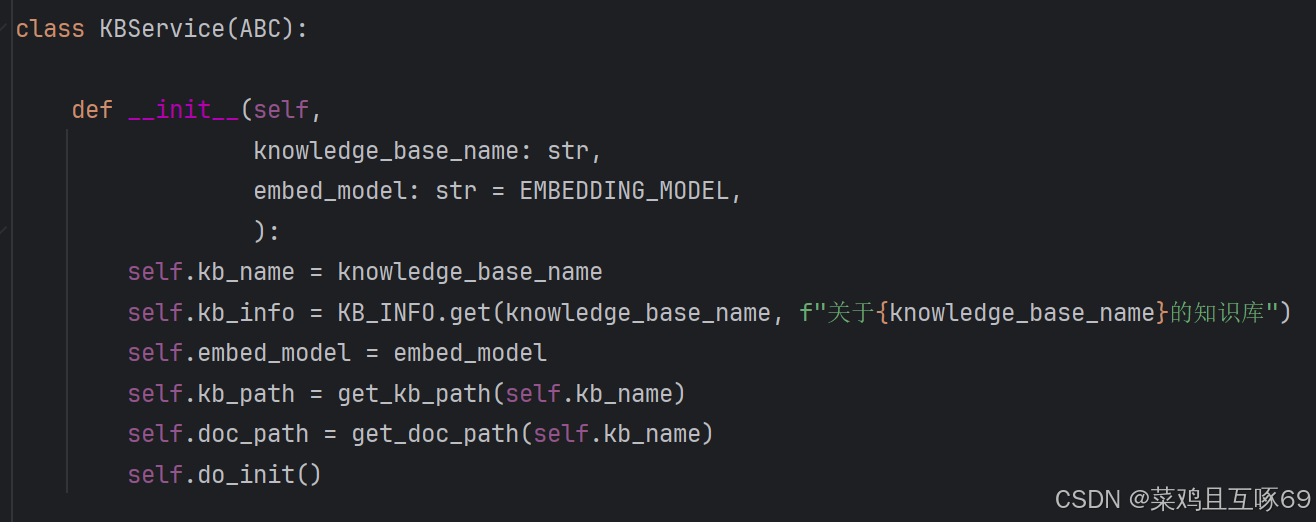
@abstractmethod 是 Python 中用于定义抽象方法的装饰器,通常与抽象基类(ABC)一起使用。它标记一个方法是抽象的,意味着该方法在子类中必须被实现。 只要是这个抽象的方法,子类必须全部实现
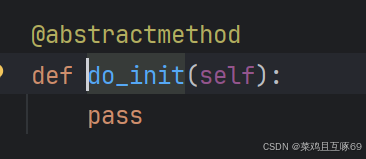
这是子类实现的方法,穿件了一个Milvus实例,这个实例是langchain集成好的实例,这些参数都是按照官方示例来进行传递的
from langchain_community.vectorstores import Milvus
这个connection_args,传入的是本地部署的数据库的连接信息

接下来就是获取到创建的库
from server.knowledge_base.kb_service.base import KBServiceFactory
kb = await KBServiceFactory.get_service_by_name("milvus_test")
如果库不存在,进行创建
# 如果想要使用的向量数据库的collecting name 不存在,则进行创建
if kb is None:
from server.db.repository.knowledge_base_repository import add_kb_to_db
# 先在Mysql中创建向量数据库的基本信息
await add_kb_to_db(kb_name="milvus_test",
kb_info="milvus",
vs_type="milvus",
embed_model="bge-large-zh-v1.5",
user_id="ff4f9954-da8c-492f-965d-dc18224b1176")@with_async_session 自动管理异步数据库会话(session),尤其在使用 ORM(如 SQLAlchemy)时
@with_async_session
async def add_kb_to_db(session, kb_name, kb_info, vs_type, embed_model, user_id):
# 查询现有知识库实例
kb = await session.execute(
select(KnowledgeBaseModel)
.where(KnowledgeBaseModel.kb_name.ilike(kb_name))
)
kb = kb.scalars().first()
if not kb:
# 创建新的知识库实例
kb = KnowledgeBaseModel(kb_name=kb_name, kb_info=kb_info, vs_type=vs_type, embed_model=embed_model,
user_id=user_id)
session.add(kb)
else:
# 更新现有知识库实例
kb.kb_info = kb_info
kb.vs_type = vs_type
kb.embed_model = embed_model
kb.user_id = user_id
# 异步提交数据库事务
await session.commit()
return True
这个装饰器是在这里定义的
from sqlalchemy.ext.asyncio import AsyncSession
from contextlib import asynccontextmanager
from server.db.base import AsyncSessionLocal
from functools import wraps
@asynccontextmanager
async def async_session_scope():
session = AsyncSessionLocal()
try:
yield session
await session.commit()
except Exception as e:
await session.rollback()
raise e
finally:
await session.close()
def with_async_session(f):
@wraps(f)
async def wrapper(*args, **kwargs):
async with async_session_scope() as session:
return await f(session, *args, **kwargs)
return wrapper
async def get_async_db():
async with AsyncSessionLocal() as db:
yield db
向向量数据库中添加文档
# 调用 add_doc 方法添加一个名为 "README.md" 的文桗,确保使用 await
await milvusService.add_doc(KnowledgeFile("README.md", "milvus_test"))添加文档时,最终执行这个方法
async def do_add_doc(self, docs: List[Document], **kwargs) -> List[Dict]:
for doc in docs:
# 遍历文档的元数据字典,将每个值转换为字符串类型
for k, v in doc.metadata.items():
doc.metadata[k] = str(v)
# # 确保每个Milvus字段都存在于文档的元数据中,如果不存在则设置为空字符串
# for field in self.milvus.fields:
# doc.metadata.setdefault(field, "")
# doc.metadata.pop(self.milvus._text_field, None)
# doc.metadata.pop(self.milvus._vector_field, None)
print("-----------------------------")
print(docs)
# 这里是 milvus 实例继承自 LangChain的 VectorStore 基类 中的 add_documents 方法
# https://api.python.langchain.com/en/v0.1/_modules/langchain_core/vectorstores.html#VectorStore
ids = self.milvus.add_documents(docs)
doc_infos = [{"id": id, "metadata": doc.metadata} for id, doc in zip(ids, docs)]
return doc_infos搜索文档
# 根据输入进行检索
search_ans = await milvusService.search_docs(query="RAG增强可以使用的框架?") async def do_search(self, query: str, top_k: int, score_threshold: float):
# 加载milvus 实例
self._load_milvus()
# 实例化Embedding模型
embed_func = EmbeddingsFunAdapter(self.embed_model)
# 将用户传入的问题,通过Embedding 模型转化为 Embedding向量
embeddings = embed_func.embed_query(query)
# 执行相似性搜索
docs = self.milvus.similarity_search_with_score_by_vector(embeddings, top_k)
return score_threshold_process(score_threshold, top_k, docs)----------------------------------------------------------

















 2640
2640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









