






#本栏是我在学习yolov5时将学习的过程记录下来#
目录
一、下载Yolov5
ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite![]() https://github.com/ultralytics/yolov5上面的链接是YOLOV5在github上面的开源项目,先自行下载。
https://github.com/ultralytics/yolov5上面的链接是YOLOV5在github上面的开源项目,先自行下载。
- 可以直接利用git在git bush输入命令
git clone https://github.com/ultralytics/yolov5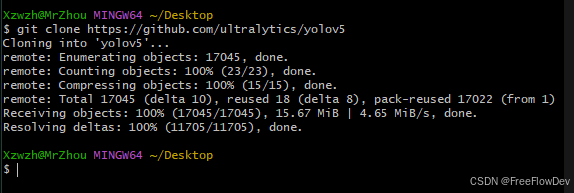
- 也可以到github上下载压缩包
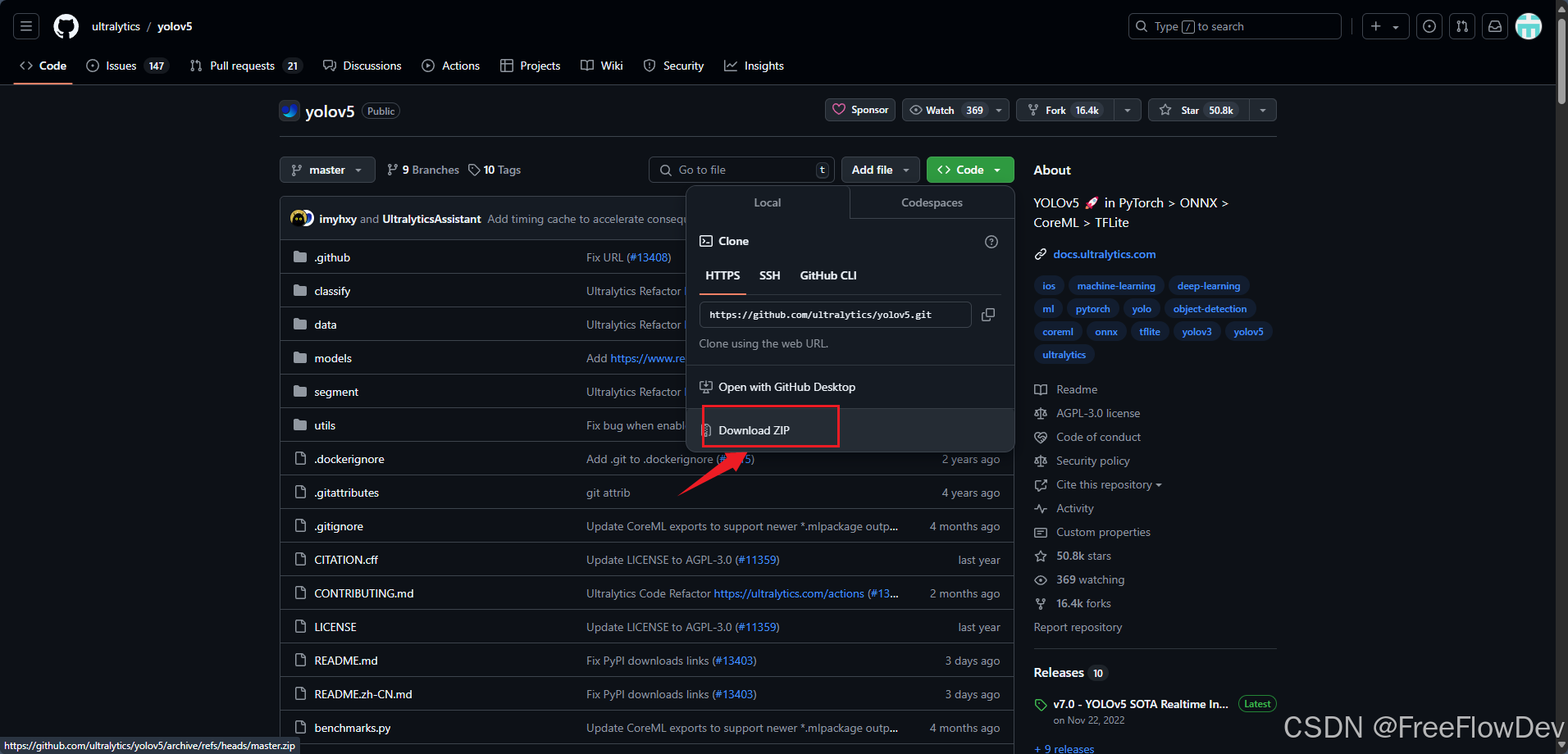
二、运行代码
1.安装requirements.txt
打开刚刚下载的代码,首先查看里面的README.md文件,里面有对yolov的介绍。
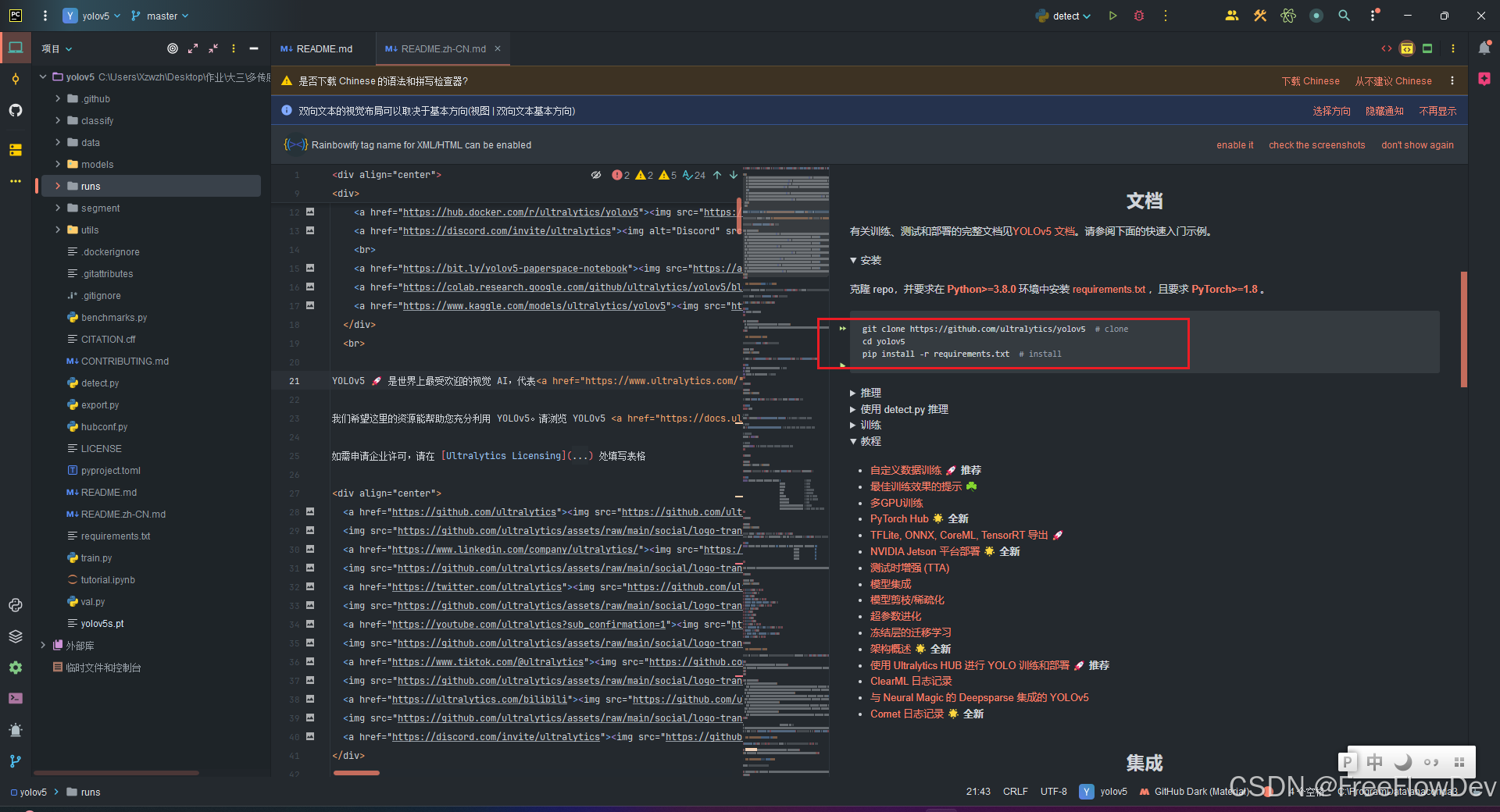
看到这里,需要在yolov5这个目录下运行(我一般喜欢在命令行里面操作)
pip install -r requirements.txt 安装requirements.txt
2.使用detect.py推理
- 可以直接运行detect.py文件
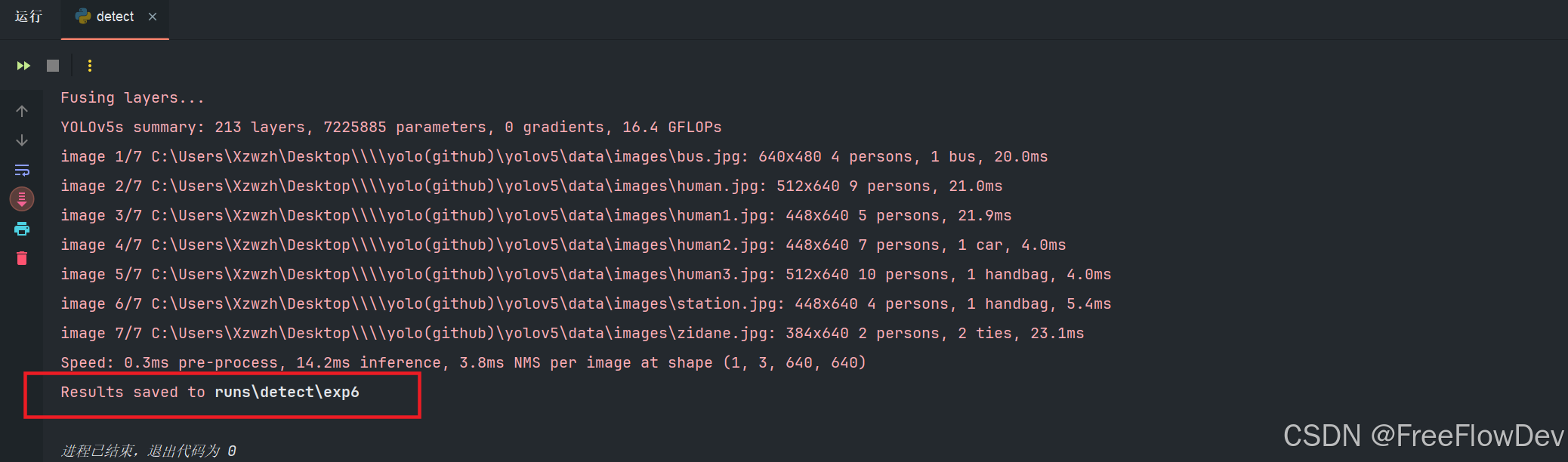
运行之后,会在 ./runs/detect/ 文件目录下生成 exp 文件夹,这个文件夹下生成的就是进行推理后的图片或者视频。
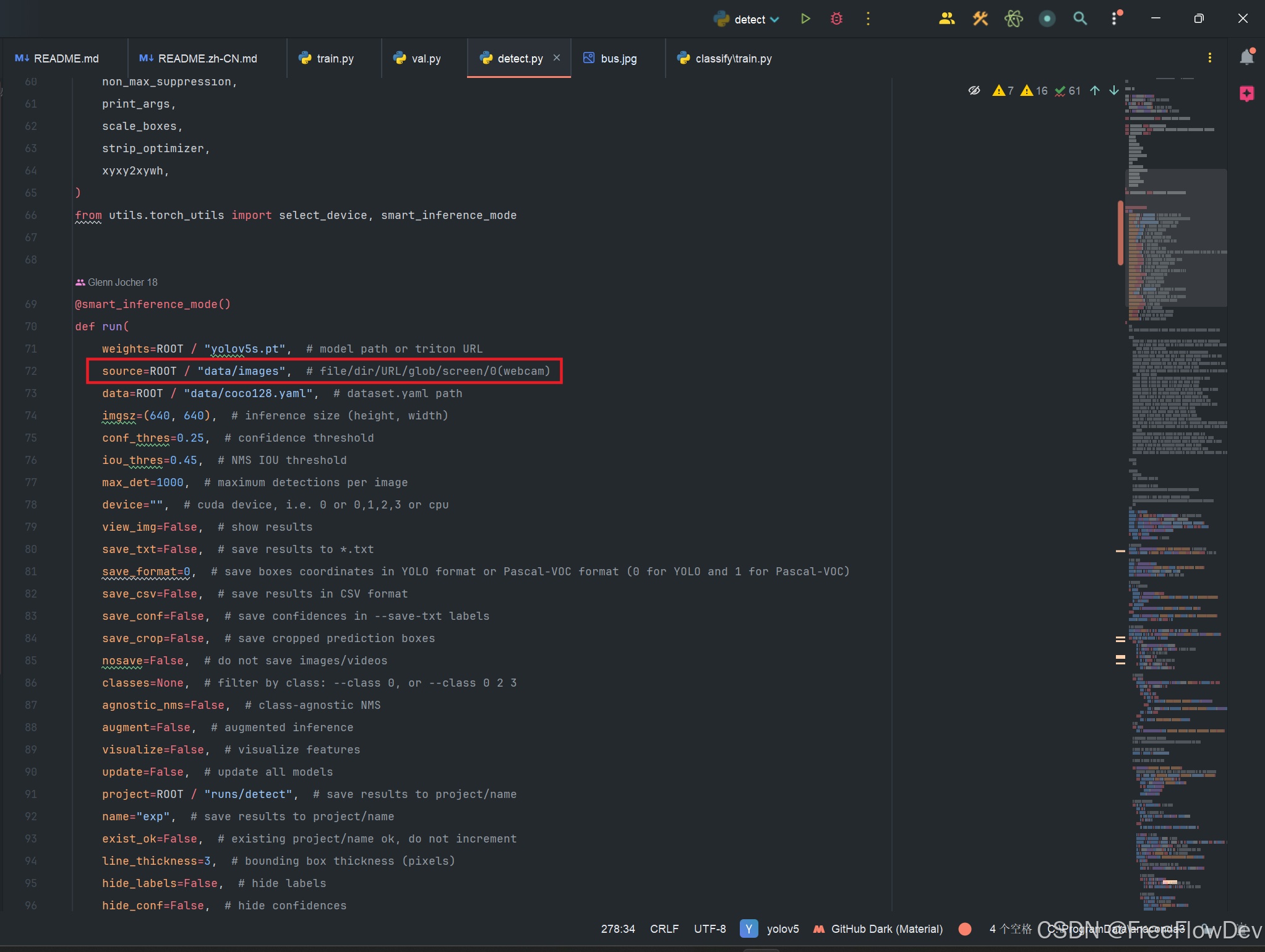
看到detect.py文件 source=ROOT / "data/images" 这个就是输入内容的目录,可以将想要推理的图片或者视频放到这个文件夹下,然后再运行detect.py文件,就会在 exp 文件夹里面生成相应的推理图片或视频。
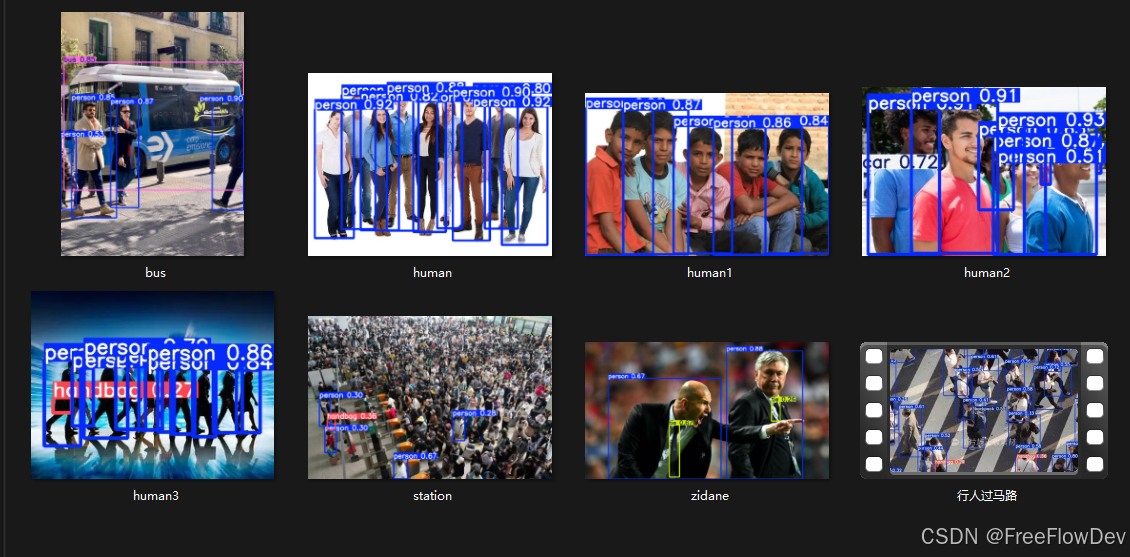
行人过马路(yolov5测试)
- 当然,也可以直接在命令行里面进行操作
在yolov5目录下终端运行detect.py文件
python detect.py --weights yolov5s.pt --source 0 # 开启电脑摄像头
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
'path/*.jpg' # glob
'https://youtu.be/LNwODJXcvt4' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
可以使用python detect.py --source 0 调用电脑的摄像头,当然也可以外接摄像头,只需要把source 0 改成 source 1或source 2 即可
三、yolov5网络介绍
1.计算机视觉任务
### 在介绍yolov5之前,先来介绍一下4种计算机视觉任务,可以参考下面这篇博客:
- Image Classification 图像分类
判断一张图像属于哪一类。这种任务的目标是将输入的图像归类到特定的类别,例如判断一张图像中是猫还是狗。
-
Object Localization 目标检测
- Semantic Segmentation 图像语义分割
将图像划分为不同的区域或类别。分割又分为语义分割和实例分割。语义分割将相同类别的对象视为一个整体,而实例分割则需要区分出每个单独的对象。
-
Instance Segmentation 实例分割
2.YOLOV5原理介绍
核心思想
YOLOv5 将一张图片分成 S×S 的网格,每个网格会预测 B 个边界框(Bounding Boxes),并对每个边界框预测以下内容:
-
边界框位置和大小:用 (x,y,w,h) 表示,分别代表中心点的坐标和宽高。
- (x , y) 是边界框相对于当前网格单元的归一化坐标。
- (w , h) 是边界框的宽和高,相对于整个图片的归一化值。
-
置信度得分:表示该边界框内是否包含目标以及边界框预测的准确性。
-
类别概率分布:预测目标属于每个类别的概率分布,总类别数为 C。
这部分通常使用独热编码形式,其中每个类别的概率值加起来为 1。
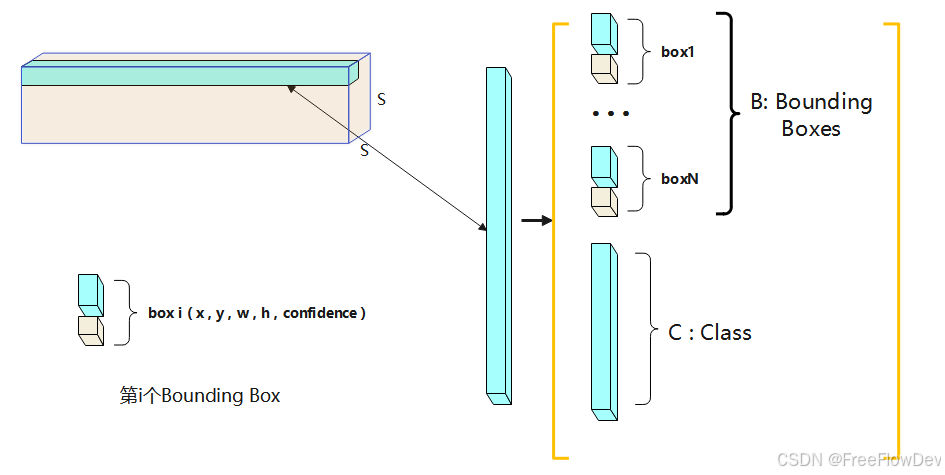
每个网格单元的输出可以表示为:
- (x , y) 表示中心点像素坐标
- (w , h) 表示与预测框的宽和高
- confidence 表示Object的置信度
- C 表示类别数
整个图像的最终输出张量大小为:
S×S×(B×5+C)
5 = (x , y,w,h,confidence)
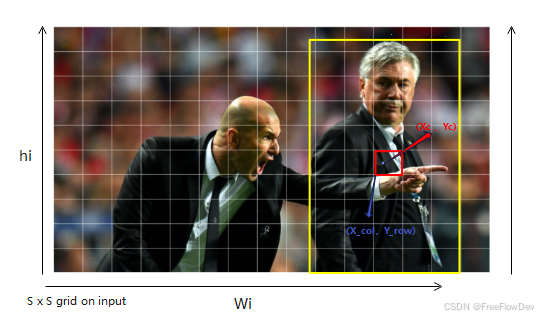
Xc 、Yc是物体的中心点像素坐标。hi、Wi是整个图片的高和宽。S是划分的网格数。X_col =12、Y_row = 6 (第12列第6行)
人工标记的OBject宽度和高度
模型架构
(1)模块介绍
在了解yolov5网络结构图之前先要了解一些基本的模块
## CNN(卷积神经网络)##
可以参考一下两篇博客,前面那篇博客是对CNN的详细介绍,后面那篇博客是我做的手写数字识别。
## ConvBNSiLU ##
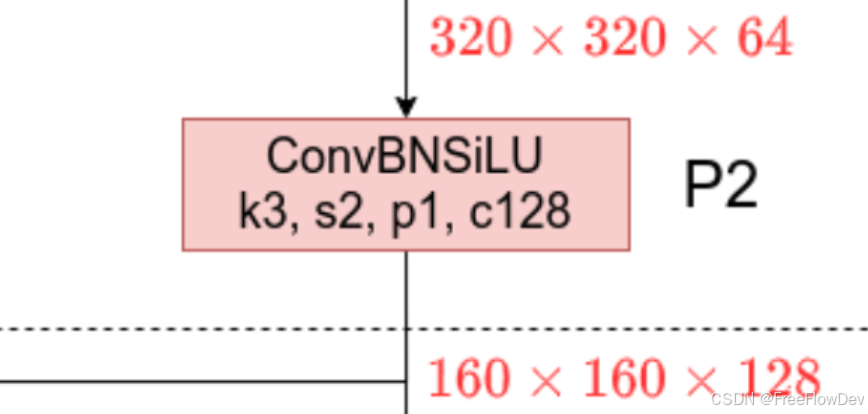
ConvBNSiLU是一种常见的卷积神经网络结构,由卷积层(Conv)、批归一化层(Batch Normalization,简称BN)和SiLU激活函数组成。从图中可以看出,当经过一个ConvBnSiLU时,特征图的大小会减小到原来的四分之一(320 x 320 --> 160 x 160 ),通道数会翻倍(64 -> 128)。其作用主要是进行特征提取。
| k | Kernel size(卷积核大小),k3表示使用3x3的卷积核 |
| s | Stride (步长),s2表示卷积核每次滑动 2 个像素 |
| p | Padding (填充),p1表示边缘每边填充1个像素 |
| c | Channels (通道数),c128表示输出特征图有 128 个通道 |
-
ConV
其中Conv可以参考以下博客了解:
-
BN
进行BN操作的原因:由于在训练深度神经网络的过程中,其训练过程中的每一层的输入概率分布都与前一层连接的权值矩阵和偏置向量有关。后一层的输入概率会随着前一层的权值矩阵和偏置向量的变化而变化。这种输入分布的变化会导致训练的优化目标动态变化,优化器需要不断适应,使得梯度更新的效率降低,增加了训练的不稳定性。这就使得非线性饱和且具有激活函数的深度神经网络训练起来变得非常困难。而且需要小心选择参数的初始值, 减小学习率, 小的学习率使得梯度下降训练过程的收敛速度变慢。这个现象被称为中间协变量迁移。例如,使用 Sigmoid 激活函数时,如果输入值过大或过小,梯度会接近 0,从而使得权重无法更新。而BN就是为了解决这个问题。
BN是Batch Normalization(批归一化)的缩写,其主要作用是为了提高网络训练的速度和加快训练过程中的收敛速度。BN就是对网络中每一层的小批量输入进行归一化处理,保持分布的稳定性,从而加速训练和提升模型性能。其计算过程如下:
前面两个公式是在计算小批量数据的均值和方差,m是批量大小,是均值,
是方差。然后进行归一化处理,
是一个很小的正数,用于避免除零。最后进行缩放和平移,其中,
(缩放因子)和
(偏移量)是可学习参数,用于恢复网络的表达能力。它们让网络在需要时可以还原或调整归一化后的分布。
-
SiLU
SiLU是一种激活函数,其公式为:
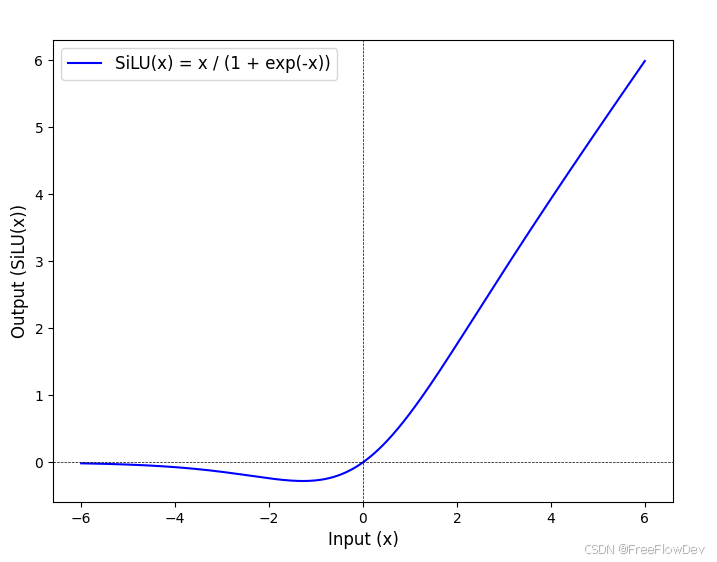
SiLU(Sigmoid Linear Unit)是一种平滑的非线性激活函数,能够动态调整输出,根据输入大小在正值区域近似线性,在负值区域平缓衰减,避免了梯度消失和“神经元死亡”问题。SiLU 增强了卷积层的特征表达能力,通过平滑的激活特性促进梯度高效流动,同时与卷积(Conv)和批归一化(BN)协同工作,提高网络的训练稳定性和最终性能。
## C3 ##
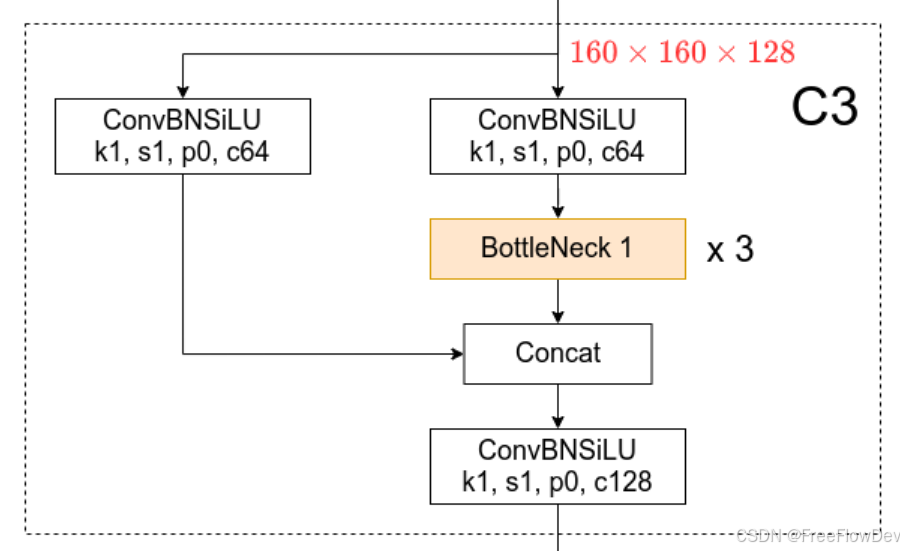
从图中可以看出C3模块中含有三个卷积层,首先将输入分为两部分,一部分直接经过ConBNSiLU卷积层,另外一部分经过卷积层后再经过3次BottleNeck层,然后这两条路径通过Concat合并,最后合并的特征再通过一个卷积层进行通道数的调整。注意,这里的卷积层(k1,s1,p0),带入输出尺寸的公式可以得出,这几个卷积的输出尺寸与输入尺寸相同。第一层通过压缩通道数分成两个路径(通道数64)进行卷积,最后合并,还原原来的通道数(128)。也就是说C3模块并未改变尺寸大小和通道数。用于提取和融合多层次特征。
## SPPF ##
池化
在介绍SPPF之前,先要了解池化操作。池化是一种在卷积神经网络 (CNN) 中常用的操作,用于对特征图进行降维,同时保留关键信息。池化的主要作用是:减少特征图的尺寸,降低计算复杂度并提取特征的空间不变性,增强模型对位置和比例变化的鲁棒性,同时防止过拟合。池化操作有不同的方式,其中最常见的两种是 最大池化 (Max Pooling) 和 平均池化 (Average Pooling)。
- 最大池化:从局部区域中提取最大的数值作为输出,突出区域内的主要特征,保留显著信息。
- 平均池化:计算局部区域内所有数值的平均值作为输出,用于平滑特征并提供整体的均衡表示。
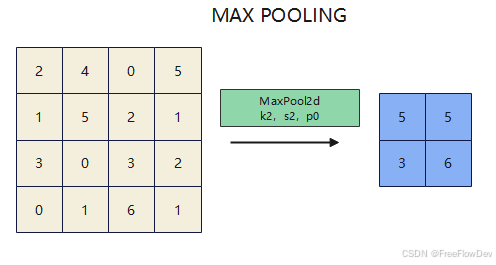
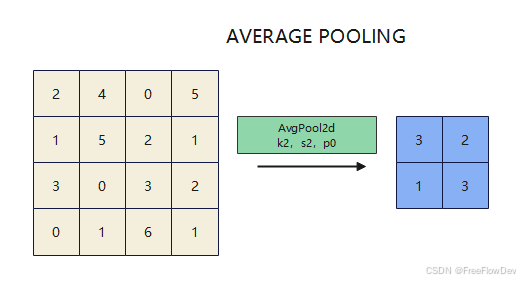
| k | 池化核大小(决定窗口尺寸) |
| s | 窗口移动步长,控制输出尺寸 |
| p | 边缘填充像素(影响池化结果边界特征) |
| ceil_mode | 决定在池化操作中,输出的维度是否使用向上取整来计算。 |
在SPPF模块中,有两个卷积层和一个池化层。首先对于输入的特征图进行第一层卷积,压缩通道数(1024 -->512),减小计算。然后进行三个MaxPooling(最大池化)操作,不改变特征图的大小,提取多尺度信息。然后进行Concat进行特征拼接,形成包含更多上下文信息的多尺度特征。最后再进行一次卷积,将拼接后的特征融合并恢复为原通道数1024。
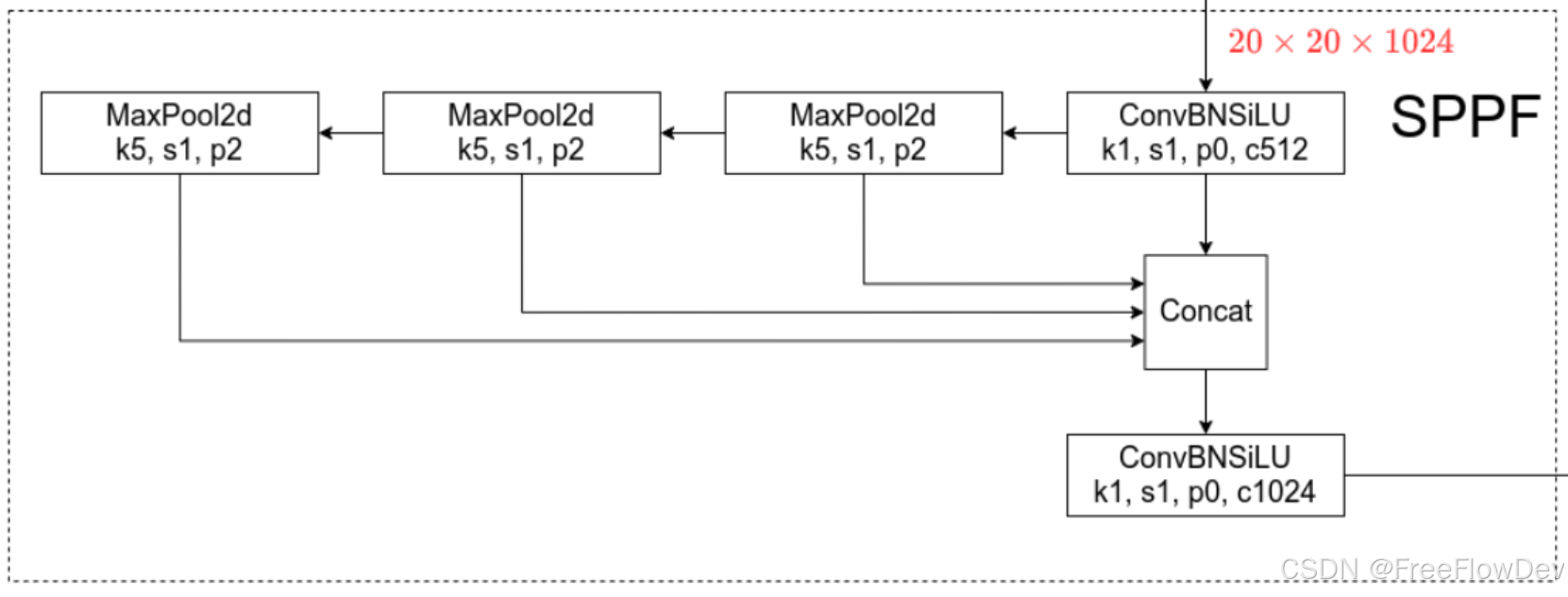
SPPF特点及作用:
-
多尺度特征提取:通过多次池化操作捕捉不同感受野的信息,从而提取多尺度的特征。尤其适合目标检测任务,能够更好地处理目标的大小差异。
-
高效实现:使用三个最大池化操作代替传统 SPP 模块中的复杂操作,计算量更小但效果相近。
-
模块化设计:结构简单,仅包含卷积、池化和拼接操作,易于集成。
-
特征增强:通过拼接丰富特征图,结合全局和局部信息,提高模型对目标的识别能力。
(2)yolov5网络结构图
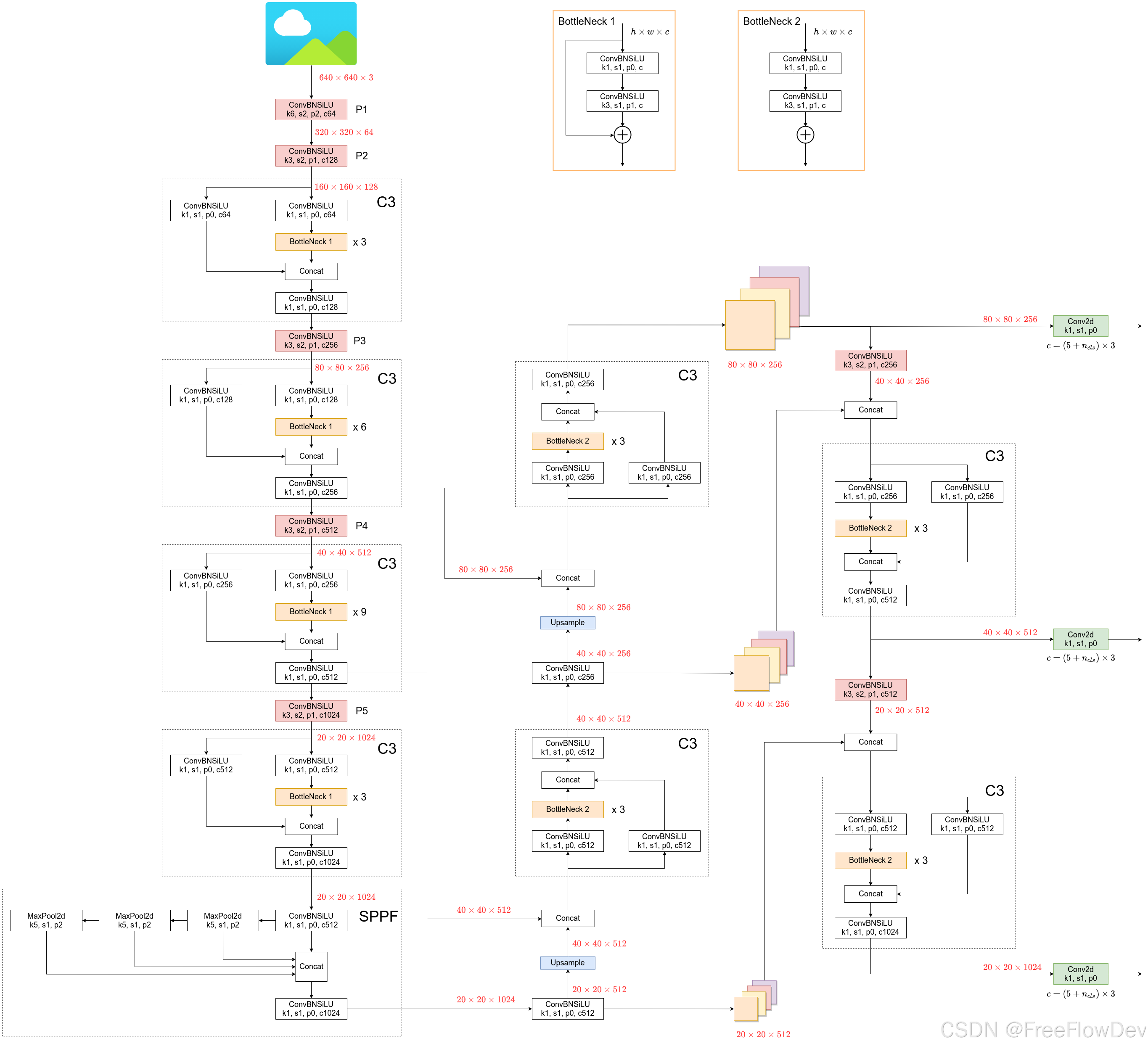
YOLOv5 基于轻量级卷积神经网络(CNN)其网络由三部分组成:
1、Backbone(主干网络)
- 用于提取特征(例如 ResNet 或 CSPNet)。
- YOLOv5 使用了 CSPDarknet 作为主干,结合了跨阶段部分网络(CSP,Cross Stage Partial Network)的设计,减少冗余梯度计算,提升速度与精度。
2、Neck(颈部网络)
- 用于整合不同层的特征,生成更好的特征表示。
- YOLOv5 使用了 PANet(Path Aggregation Network)结构,优化特征融合,并增强小目标检测能力。
3、Head(头部网络)
- 负责生成最终的边界框和分类输出。
- YOLOv5 采用了 Anchor-Based 方法,预测边界框的偏移值及分类结果。
详细内容可参考:
四、模型训练过程
1.coco128数据集训练
下载coco128数据集
wget https://ultralytics.com/assets/coco128.zip -OutFile coco128.zip
在终端运行上述代码,就会在终端所示目录下下载coco128.zip压缩包,即为训练用的数据集

首先创建一个与yolov5同级的目录,名称为datasets,将解压后的coco128文件夹放到该文件夹下
然后在yolov5目录的终端下运行以下代码,训练模型
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt

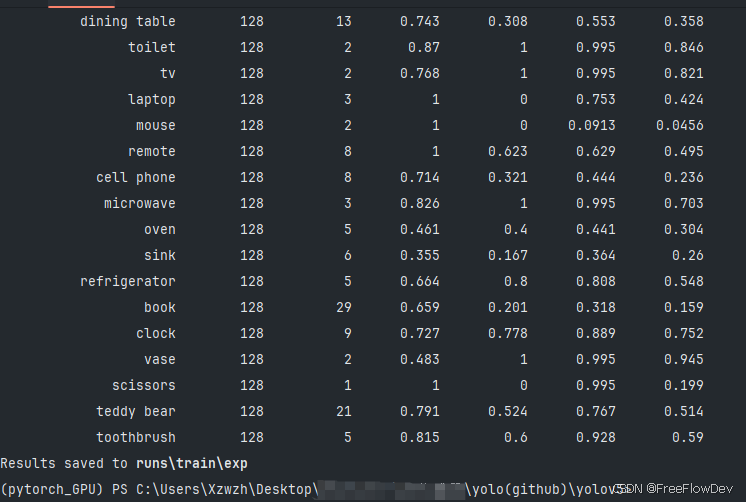
出现如上页面,模型便训练完成。
2.参数介绍
-- img 640 : 设置输入图像的尺寸为 640
-- batch 16 : 设置训练批次大小为 16
--epoch 3 : 训练 3 个周期。
--data coco128.yaml : 指定数据配置文件 coco128.yaml,它包含了数据集路径和类别信息。
--weights yolov5s.pt : 使用预训练的 YOLOv5s 模型进行微调。
预训练权重:YOLOv5s 模型(以及其他版本)都有在 COCO 数据集(或者其他大型数据集)上训练好的权重文件。这些权重文件(例如 yolov5s.pt)包含了在这些数据集上学习到的模型参数,包括卷积核权重、偏置、以及各种层的设置。换句话说,预训练模型已经经过了大量数据的训练,能提取通用的特征,例如边缘、形状、纹理等,这使得它可以在其他任务中发挥作用。用预训练模型可以快速获得更好的性能,尤其是在数据量有限的情况下。
微调(Fine-tuning):微调是指在已经训练好的预训练模型的基础上,使用新的数据进行进一步训练,通常这种训练所需的时间较短,因为模型已经具有了从原始数据集学到的通用特征。使用 --weights yolov5s.pt ,表示会用 YOLOv5s 的预训练权重作为初始模型,并基于 COCO128 数据集进行微调。微调时,模型会针对你的数据集(比如 COCO128)优化,适应新的目标检测任务。
3.训练结果分析
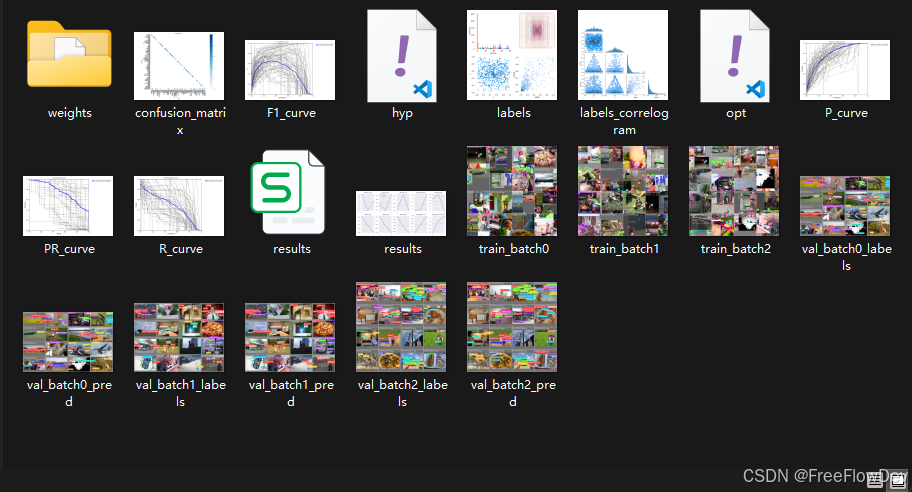
最终在 runs/train/exp 目录下生成了这些东西:
weights文件夹里面有best.pt和last.pt,分别是模型的最佳权重文件和最后一次训练的权重文件。confusion_matrix.png、F1_curve.png、P_curve.png、PR_curve.png、R_curve.png反映不同评价指标的可视化结果,如混淆矩阵和性能曲线(精度、召回率等)。results.csv 和 results.png是训练结果的详细数据和可视化图表。其他的这些batch图片是训练和验证过程中部分批次的标签和预测结果的图像。
### 本篇博客只是记录一下我学习yolov5时的过程及一些认识,这是我初识yolov5视觉目标检测,很多地方也不是很理解,如有错误,欢迎大家留言评论,批评指正 ###


















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









