 Python初学者的简单爬虫实践:下载小说
Python初学者的简单爬虫实践:下载小说





 本文介绍了如何使用Python进行简单的网络爬虫,以下载小说为例,涉及requests库获取网页HTML内容和BeautifulSoup解析HTML提取所需数据。通过分析小说章节页面的源代码,提取div class='showtxt'标签中的文本,最终将所有章节保存为TXT文件。
本文介绍了如何使用Python进行简单的网络爬虫,以下载小说为例,涉及requests库获取网页HTML内容和BeautifulSoup解析HTML提取所需数据。通过分析小说章节页面的源代码,提取div class='showtxt'标签中的文本,最终将所有章节保存为TXT文件。
仅做学习用途!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
看小说请支持正版!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
做了小飞船打外星人之后,课本剩下的两个大项目都不想做,一个看都没看,一个做起来越做越生气。
于是把目光放到了我康康康康康康康!!!仙博客更新过的 python爬虫上
找到了一个比较傻瓜式的简单博客教程,
开始了python的爬虫之旅~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
一:查看元素
先打开笔趣阁中的一篇小说(此为盗版网站,请支持正版!)笔趣阁_圣墟,
然后单击鼠标右键,点击审查元素(不同浏览器的叫法可能不同,但是离不开审查,检查,查看元素这些),
会发现网站右边(不同浏览器地方不同,但是都差不多,我的是搜狗浏览器而不是大多数用的chr~~~)出现了很多看不懂的代码,这些代码相当于是网站的源代码(你可以在本地修改这些代码,网站显示的内容也会相应改变,当然,刷新就会回到原样,一个有趣而简单的使用见附1),在出现的代码框的左上角有一个小箭头,点了之后,鼠标移到那,代码和网页的对应部分就会变蓝以示清白。
简单python爬虫的原理可以说就是抓相应源代码下来,然后分析这些代码从中剥离出需要的部分。
点开小说的任一章节,审查元素,找到章节内容对应的代码,会看到所有的内容文字都属于div class = showtxt的标签中
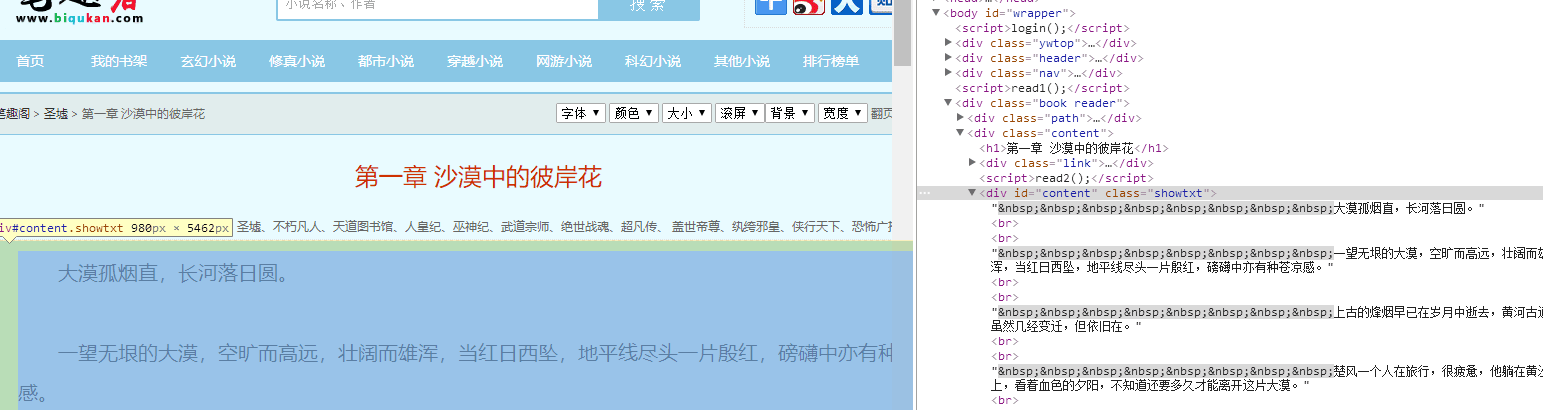
这些属于html的内容,我也不太懂,但大概懂这些标签中的层次关系。
我们第一层次要做的,就是抓取好这一章这些所有的内容文字。
第二层次要做的就是抓取全部章节,转到txt文件中。
然后就搞定啦
BB了这么多,下面开始代码相关的解析~~~~~
二:requests
requests是一个功能强大的库,可以很方便的获取一个网页的html信息。
常用的函数有 requests.get(某网站),返回值就是这个网站的html的信息。
有中文官方文档查看。
好的,现在下载requests,打开命令行,输入
pip install requests 下载即可
先来简单的使用一下,编译如下代码
import requests
r = requests.get("http://www.biqukan.com/0_178/15661946.html")
print(r.text)就两行,两个函数,第一个是requests.get(),获取网页信息,第二个r.text转为字符串来输出。
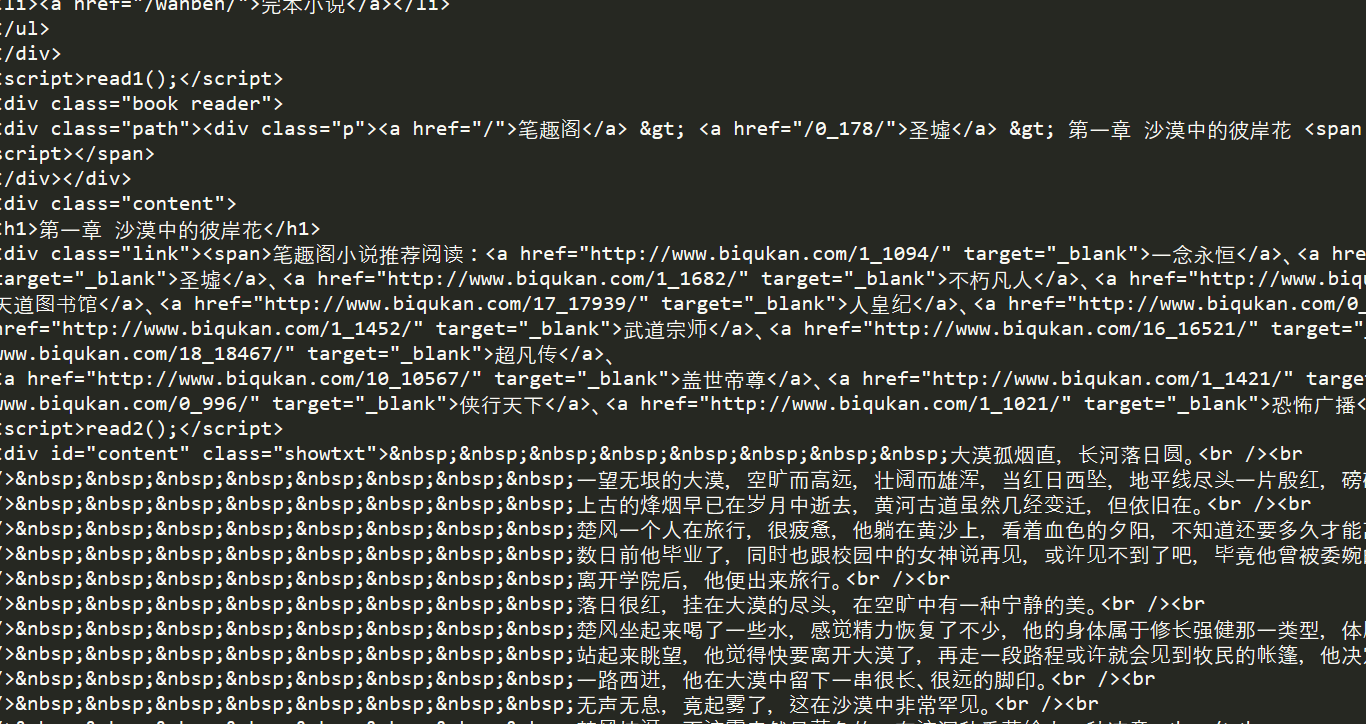
这个代码的输出就是网页的源代码内容。
很明显,我们要的是文章的内容,而不是这么一大串乱七八糟的代码和一些别的内容。
这就是这个简单爬虫的最重要部分
三:BeautifulSoup
得到了一长串的html内容,下面要做的就是解析html内容,身为一个新手,最好用的应该就是BeautifulSoup。
下载方式:打开命令行 输入 pip install beautifulsoup4
同样的,这个库也有官方中文文档
下载好了之后怎么使用这个库来帮助我们进行html的解析呢
运行代码
import requests
from bs4 import BeautifulSoup
r = requests.get(" http://www.biqukan.com/0_178/15661946.html")
html = r.text
bf = BeautifulSoup(html)#传递一个字符串,返回一个BeautifulSoup对象,这个对象可以很方便的帮助解析html信息
texts = bf.find_all('div' , class_='showtxt')#返回一个列表,找出所有div标签下面,class属性是showtxt的东西,前面说过,所有文章内容都是在showtxt下面的
print(texts[0])就两行代码是新的。
运行输出如下
可以看到,文本的确是文本了,但是格式很奇怪,而且有很多brbrbrbr
只需要在print(texts)前加一行
texts = texts[0].text.replace('\xa0'*8,'\n\n')
即可
texts[0]是列表的第一个元素,这里列表也只有一个元素,因为只有一个地方满足class_ = 'showtxt'的条件
texts[0].text滤除br,只显示文本
然后再删除多余的空格改成回车:replace('\xa0'*8,'\n\n')
再运行程序,就会输出最想要的结果,也就是该章小说已经储存进了我们的程序中啦!

。。。。。。。。。。。。。。。。。。。。。。
到这里,已经对这种简单爬虫实现有了一点小小的感觉,下面爬所有章节小说。
这个的思路如下:
1:找到所有章节的对应网站
2:依次爬取并写入txt文件中。
怎么找呢,我们打开这本小说的目录网站

审查元素的时候可以看到,每一章都对应一个网站后缀,
也就是说第二章的网站地址就是http://www.biqukan.com(前缀) /0_178/15661947.html(后缀)
如果我们能够建立起一个列表,从目录网站获取每一章的网站后缀,再加上固定的网站前缀,那么接下来的就仅是代码的拼接了!
跟之前爬取单章内容的方法类似。发现所有的章节目录网站这些信息都存储在 class = listmain 的标签中
运行代码
import requests
from bs4 import BeautifulSoup
r = requests.get("http://www.biqukan.com/0_178/")
html = r.text
bf = BeautifulSoup(html)
texts = bf.find_all('div' , class_='listmain')
print(texts)#不做解释部分输出如下:
<dt>《圣墟》最新章节列表</dt>
<dd><a href="/0_178/18803757.html">第九百九十章 万古时空一画卷</a></dd>
<dd><a href="/0_178/18777009.html">第九百八十九章 史上最强的人(附之前断更原因)</a></dd>
<dd><a href="/0_178/18732721.html">第九百八十八章 跃上苍</a></dd>
<dd><a href="/0_178/18710572.html">第九百八十七章 一剑断万古</a></dd>
<dd><a href="/0_178/18629635.html">第九百八十六章 是为上苍仙</a></dd>
<dd><a href="/0_178/18623441.html">第九百八十五章 共举大事</a></dd>
<dd><a href="/0_178/18608001.html">第九百八十四章 长使英雄泪满襟</a></dd>
<dd><a href="/0_178/18596234.html">第九百八十三章 擒仙</a></dd>
<dd><a href="/0_178/18583527.html">第九百八十二章 一个人挑战全阳间</a></dd>
<dd><a href="/0_178/18578505.html">第九百八十一章</a></dd>
<dd><a href="/0_178/18562616.html">第九百八十章 他乡遇故知</a></dd>
<dd><a href="/0_178/18552332.html">第九百七十九章 事了拂衣去</a></dd>
<dt>《圣墟》正文卷</dt>
<dd><a href="/0_178/15661946.html">第一章 沙漠中的彼岸花</a></dd>
<dd><a href="/0_178/15661947.html">第二章 后文明时代</a></dd>诶,更进一步,我们要的是<a>标签里面的 href 的网站
<a>标签在这代表的是超链接的网站的意思
import requests
from bs4 import BeautifulSoup
r = requests.get("http://www.biqukan.com/0_178/")
html = r.text
bf = BeautifulSoup(html)
texts = bf.find_all('div' , class_='listmain')
div = BeautifulSoup(str(texts[0]))#将之前的输入作为字符串再转换成一个BeautifulSoup对象
a = div.find_all('a')#在这些对象中,寻找<a>标签中的值,这里注意返回的是一个列表,这个列表有非常多的元素。
for each in a:
print( 'http://www.biqukan.com' + each.get('href'))#对列表中的每一个对象,也就是<a>标签中的东西,get他们的href~~~部分输出: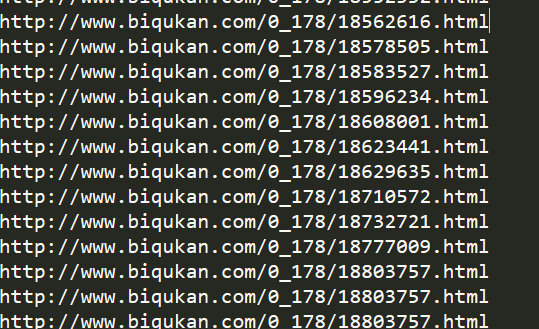
到这里,简单爬虫的关键内容已经完成啦。
接下来利用这些东西,整合一下代码即可
from bs4 import BeautifulSoup
import requests , sys
class downloader():
def __init__(self):
self.server = 'http://www.biqukan.com/'
self.target = 'http://www.biqukan.com/0_178/'
self.names = []
self.urls = []
self.nums = ()
def get_download_url(self):
req = requests.get(self.target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div',class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))########
a = a_bf.find_all('a')
self.nums = len(a[15:])
for i in a [15:]:
self.names.append(i.string)
self.urls.append(self.server + i.get('href'))
def get_contents(self,target):
req = requests.get(target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div' , id = 'content')
texts = texts[0].text.replace('\xa0'*8,'\n\n')
return texts
def write(self , name ,path ,text):
write_flag = True
with open(path , 'a' , encoding = 'utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write("\n\n")
dl = downloader()
dl.get_download_url()
print("stat:")
for i in range(dl.nums):
dl.write(dl.names[i],'shengxu.txt',dl.get_contents(dl.urls[i]))
sys.stdout.write("%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush()
代码认真看结合内容很容易就能看懂,不多做解释。
guinazongjie归纳总结:
这个第一个爬虫还是比较简单的,虽然我几乎没有任何的html和JAVASXXXXX知识,也还是能够顺畅的写下来。
真正的关键点应该还是BeautifulSoup库的几个函数和对象的使用,以及关于网页源代码的观察。
好了,就这样吧。。。。。。最后再说一句
支持正版!
附1:
随意打开一个登录界面,比如说qq邮箱,切换到账号密码登录,会看到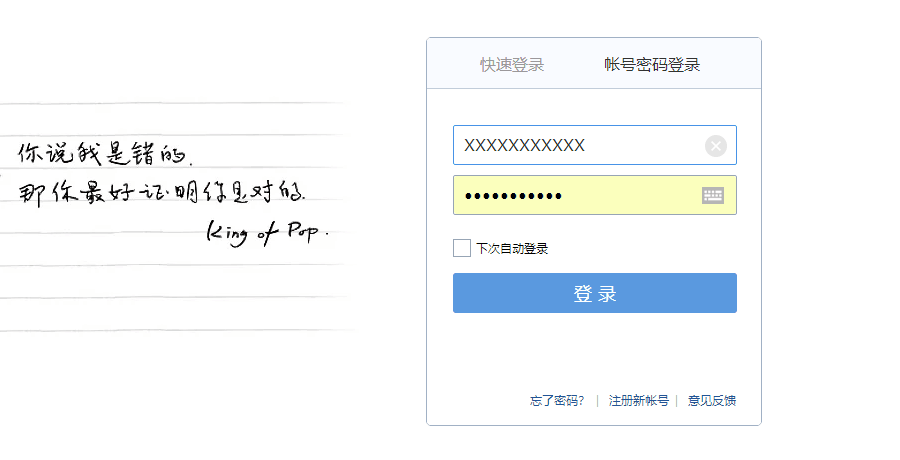
密码是显示不出来的,不过修改此处的属性就可以显示出来,审查元素找到这个地方的对应代码
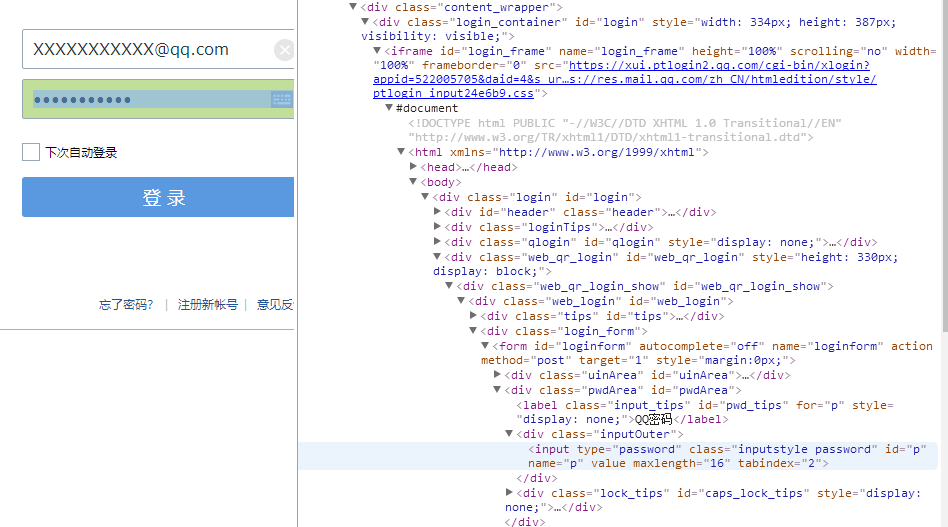
把password改成text并保存

在本地网页就可以看到这个密码
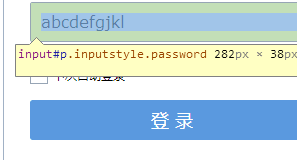
一刷新就没了,那么这个东西有什么用呢,简单来说,你可以趁你舍友上厕所的时候偷你舍友的QQ的密码,只要他保存了账号密码。
额,当然,仅做学习用途,侵犯他人隐私犯法。

















 1319
1319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









