







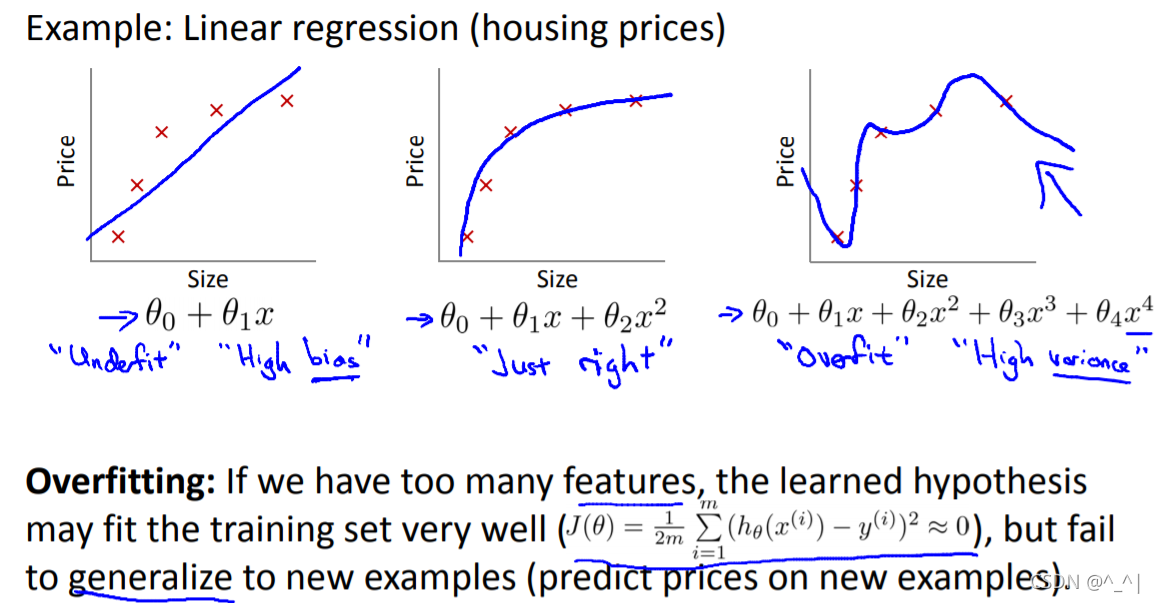
机器学习中常常提到的正则化到底是什么意思?
正则化是解决过拟合的方法之一。

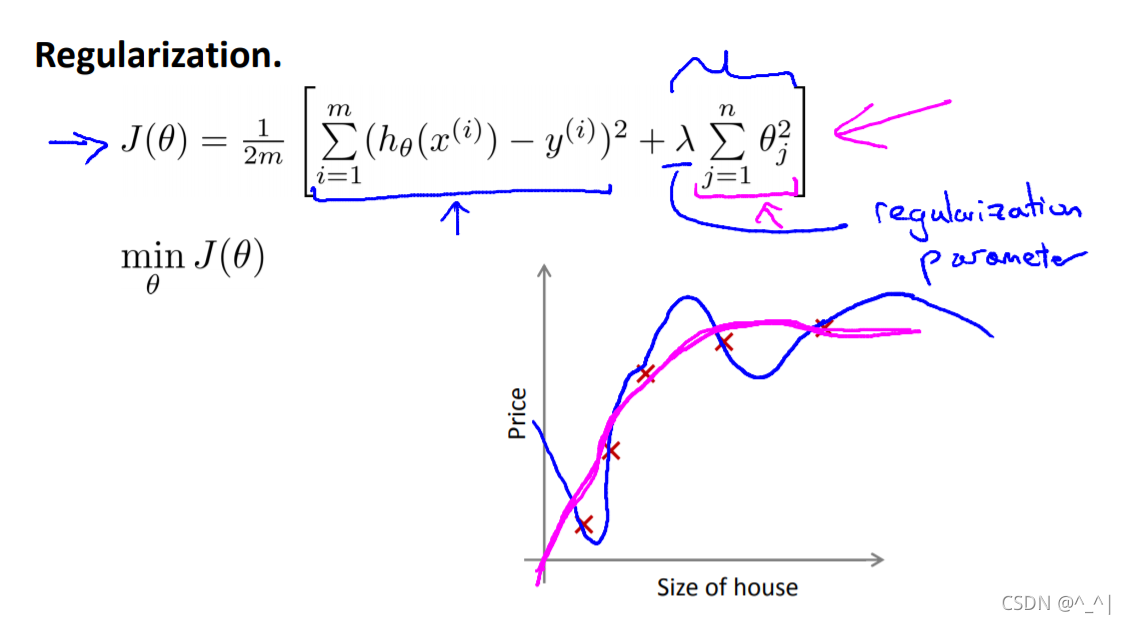
对于正则项的系数有这样的说明:当
λ
\lambda
λ越大,则相应的
θ
\theta
θ越小。
其实这里同样可以理解为,我们既希望原目标函数达到尽可能小,同时我们希望 θ 2 \theta^2 θ2 的和尽可能小(也即是 θ \theta θ 的非零项不要太多从而造成过拟合)
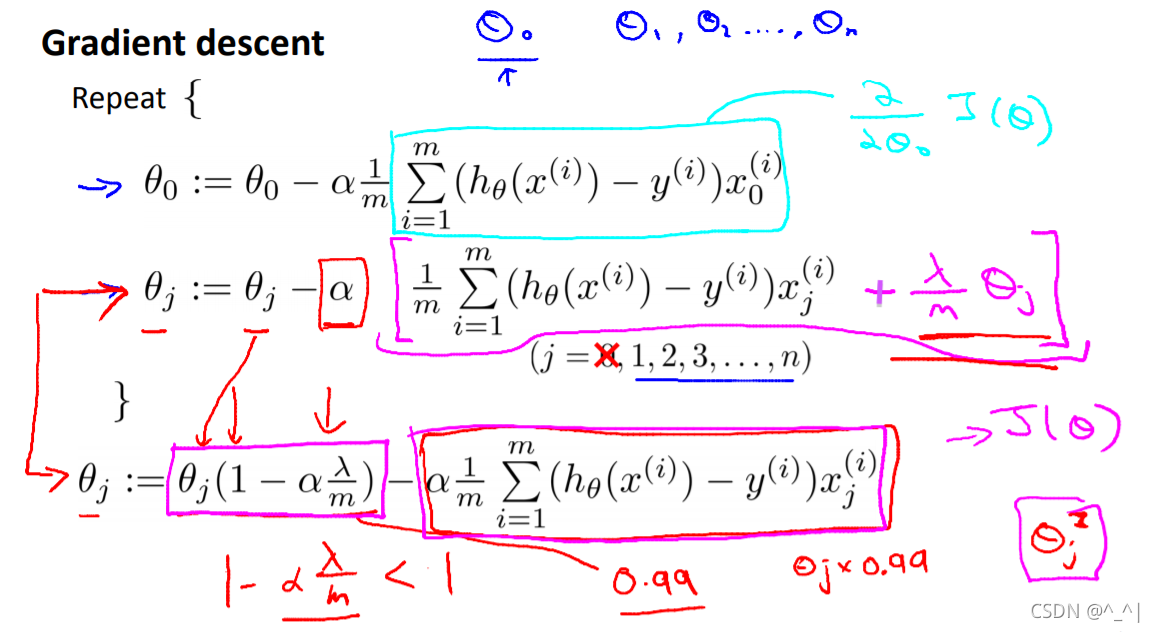
添加正则化处理后的梯度下降,最终形式可以看到
θ
j
\theta_j
θj前多了
(
1
−
α
λ
m
)
(1 - \alpha\frac{\lambda}{m})
(1−αmλ)项,是一个略小于1的值,从而有一定偏差,可以保证不会像原来那样出现完全拟合的情况。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









