






 本文详细介绍了NumPy和Pandas的高级用法,包括数组操作、数据读写、索引、数据清洗及时间序列处理。展示了如何利用NumPy进行高效数值计算,以及Pandas在数据处理和分析中的强大功能。
本文详细介绍了NumPy和Pandas的高级用法,包括数组操作、数据读写、索引、数据清洗及时间序列处理。展示了如何利用NumPy进行高效数值计算,以及Pandas在数据处理和分析中的强大功能。
numpy方法的使用 numpy方法:快速,方便,科学计算的基础库,重在数值计算,多用于大型,多维数组上执行数值运算
import numpy as np
np.arange方法
np.array(range(10)) = np.arange(10)
a=np.arange(24) #创建数组
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])
a.reshape(4,6) #改变数组为四行六列
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
a.reshape(2,3,4) # 改变数组为两块三行四列 可以把2理解为分成两块
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
b = a.reshape((a.shape[0]*a.shape[1],)) shape[0]为行shape[1]为列
a.flatten() 将二维数组自动展开
当把数组a进行 加减乘除运算时 是将数组里的每个元素都进行加减乘除操作
当数组之间进行加减乘除时 必须有同维度的才能计算 例如a.reshape(4,6)与a.reshape(1,6) 和a.reshape(4,1)具有相同行数或列数可以进行运算shape(3,3,2)与shape(3,2)同样可以进行运算
使用numpy读取数据
t1 = np.loadtxt("file_path",delimiter=",",dtype="int",unpack="1") #delimiter为分隔的意思 dtype为科学计数法 unpack相当于转置 即是把行转化为列
数组的拼接
np.vstack((t1,t2)) #将t1 t2竖直拼接
np.hstack((t1,t2)) #将 t1 t2水平拼接
numpy的索引方式
t[:,2:4] #取第三列到第五列的值
t[:,2:4] = 0 #取第三列到第五列的值 并改为0
t<10 # 返回布尔类型True False
t[t<10] =1 # 取小于10的 并改为1
np.where(t<10,0,10) # 将t<10的设为0 t>10的值设为10
t.clip(10,20) # 将小于10的替换为10 大于20的替换为20
t = t.astpy(float) # 将int整型 转化为浮点类型
np.zeros((3,4)) #构造全为0的数组 np.one构造全为1的数组
np.eye(4) #创建一个对角线全为1的正方形数组(方阵)
np.argmax(t,axis=0) # 取每一行上面最大值
np.argmin(t,axis=1) # 取每一列上面最小值
pandas的使用 可用来处理numpy不能处理的非数值类型数据比如字符串,时间序列
pandas常用数据类型有 Series (一维 带标签数组)DateFrame(二维 series容器)
import pandas as pd
Series 的创建以及使用
t = pd.Series([1,18,2,3,1],index=list("abcde"))
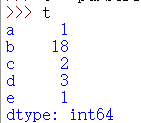
将字典转化为series类型
t1["age"] #取索引为age的值 =t1[1] 也可以通过位置来取
t1.index #取索引
t1.values # 取值
pd.read_csv("file_path") #pandas读取数据 csc文件
DataFrame 的创建和使用既有行索引(index 0轴 axis=0)又有列索引(column 1轴 axis=1 )
t =pd.DataFrame(np.arange(12).reshape((3,4)))
t
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
t1=pd.DataFrame(np.arange(12).reshape((3,4)),index=list("abc"),columns=list("wxyz"))
t1
w x y z
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
t1.loc["a","w"] t1.loc["a",["x","y"]] # 根据标签索引行数据
t1.loc["a":"c",["x","y"]] # 取a到c行的 xy数据
t1.iloc[1,:] # 取第二行的数据
t1.iloc[:,2] #取第三列的数据
t1.iloc[:,[2,1]] # 取第三列二列的数据
t1.iloc[[0,2][2,1]] # 取第一行第三行的 第三列和第二列的数据
t1.iloc[1:,:2] = 30 # 取第一行之后的每一行中的第三列之前的每一列数据替换为30
t2 = {"name":["xiaoming","xiaohua"],"age":[26,30],"tel":[10098,10090]}
pd.DataFrame(t2)
name age tel
0 xiaoming 26 10098
1 xiaohua 30 10090
t3 = [{"name":"xiaoming","age":26,"tel":10098},{"name":"xiaoting","age":46,"tel":10022},{"name":"xiaowanging","age":36,"tel":10008}]
pd.DataFrame(t3)
name age tel
0 xiaoming 26 10098
1 xiaoting 46 10022
2 xiaowanging 36 10008
df.head(5) #显示前五行 默认是5行
df.tail() #显示后几行
df.info() #显示df的概览
df.describle() #展示最大值最小值方差等
df.sort_values(by="依据",ascending=False)
df[:20]["values"] # 取前二十行values列的值
df[(df["name"].str.len()>5)&(df["age"]>20)] #取名字字符串大于5 且年龄大于20的数据 &代表且 |代表或
在数据中存在NAN 先判断是否为NAN
pd.isnull(df)或pd.notnull(df)
处理方法1 删除数据
dropna(axis=0,how="any",inplace=False) # 删除 how默认为any 指删除某一行有一个为NAN的那一行 all指删除全为NAN的那一行 inplace =True 指原地修改 就地修改
处理方法2 填充数据
t["age"][1] = np.nan # 将age那一列的第二行数据替换为NAN
t.fillna(t.mean()) #将为NANvalue填充均值
t["age"].fillna(t["age"].mean()) #只对age那一列进行操作
t[t==0] = np.nan #处理为0的数据 当需要计算平均值时需要把0处理为NAN 因为0会参与运算,NAN 不会
DataFrame 索引的方法和属性
t1.index = ["d","e","f"] #直接更换df的索引
t1.reindex(["d","e","h"])
w x y z
d 0.0 1.0 2.0 3.0
e 4.0 5.0 6.0 7.0
h NaN NaN NaN NaN
t1.set_index("x") # 把x设置为索引
w y z
x
1 0 2 3
5 4 6 7
9 8 10 11
t1.set_index("x",drop=False) #drop=false 指不丢弃x那一列
w x y z
x
1 0 1 2 3
5 4 5 6 7
9 8 9 10 11
t1["w"].unique() # 取某一列不唯一的值
([0, 4, 8])
t1.set_index(["x","z"]) #设置两个索引
w y
x z
1 3 0 2
5 7 4 6
9 11 8 10
pandas时间序列 :
将不规则的时间字符串转换为pandas时间序列
pd.todatetime()
重采样
t.resample("M") #按月份进行重采样 当从月份变为天数 为升采样 天数变为月份为降采样

















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









