




1.结构体类型的声明
<1>结构体类型的声明

如图中所示就是结构体变量声明的例子,在其中,必须要加上struct这个结构体关键字,struct后面则是加上结构体类型名,大括号内的内容是成员变量,在末尾有一个分号,我们可以在大括号和分号之间进行结构体类型的创建也可以在主函数内创建(两种方式所不同的差别是变量的作用域不同,一个全局一个局部)。
在引用结构体变量的成员时需要用到.操作符或者->操作符。
<2>匿名结构体类型
匿名结构体类型就是在struct后面不加上结构体类型名。
这样的操作是在你只想对这个类型使用一次,以后再也不使用了的情况下使用。

对于上述代码,如果你对它使用p=&a这样的操作后,编译器会报警告,认为不能这样操作,这是因为两个结构体都没有具体的名字(两个结构体虽然成员类型相同,但是没有名字,编译器就会认为这两个是不一样的)。
<3>结构体的自引用
-->问题1:
在结构体中包含一个类型为结构体本身的成员是否可以呢?
用结构体模拟一个链表来举例:
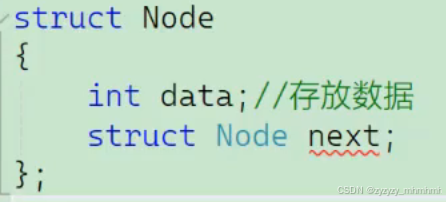
我们会发现一个问题,我的Node next中包含了无数个date和Node next,那么这个结构体的内存 大小是多少呢,我们并不知道,所以这样的自引用方式肯定是不对的。
但是如果把next改成*next就会成功了,即变成一个指针的形式,所以结构体变量里面包含一个 同类型的结构体变量是做不到的。
-->问题2:
在结构体自引用的过程中,夹杂了ttypedef对匿名结构体类型重命名,也容易出现问题,比如:

如果这样书写代码编译器就会在第四行报警告,因为不认识第四行中的Node,这是因为其前面没有加上struct,这是一个顺序问题,是先有了结构体再重命名,而在上面不加struct则是在没有命名之前就使用了命名之后的东西,明显是不对的方式。
2.结构体的内存对齐
对齐现象的演示:
在c语言中如何计算结构体的大小呢?举下面这个例子:
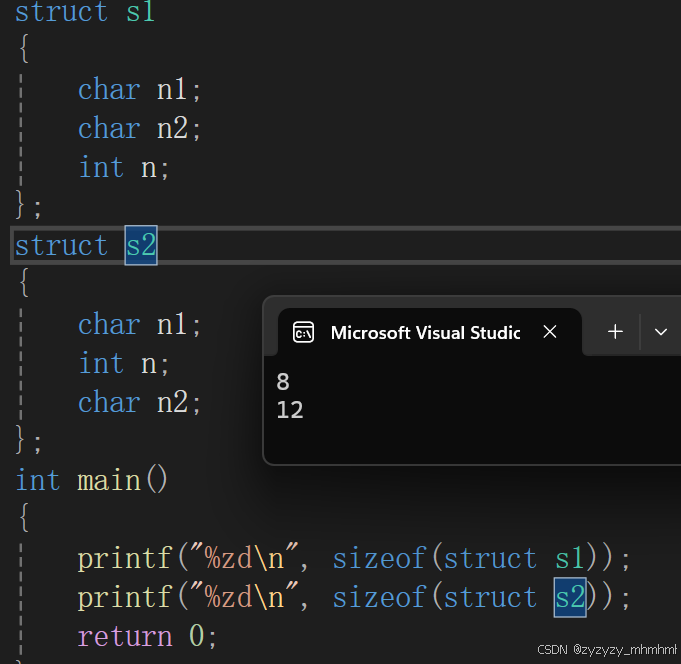
我最初的想法是两个结果都是6,但是并不是这样的,那是为什么呢。
那是因为结构体的成员在内存中是存在对齐现象的。
为了解释上述现象,我们可以对其进行验证,这是我们需要用到一些没有学习过的知识即: offsetof,这在C语言中是一个宏的定义。
我们可以在cpulspuls官网中查询到他的具体功能如下:

对于offsetof,它可以计算结构体成员相较于结构体变量起始位置的偏移量。
那么什么东西是偏移量呢,在内存的开始位置往后每一个内存单元,就相当于一个偏移量,类比为很多个格子,但是最开始的那个内存单元所对应的偏移量是0而不是1,依次往下。
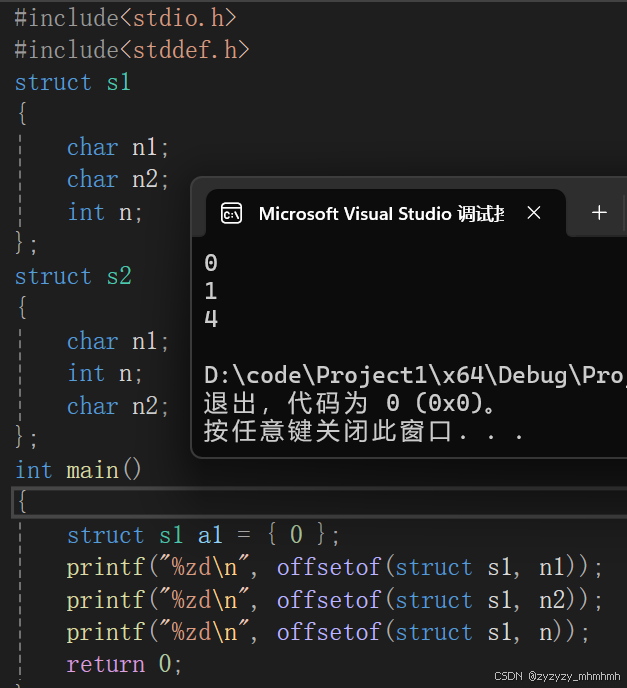
以上是对offsetof的应用,再对照上述程序的结果,我们可以由此可以得到以下的示意图(最上面的红线我们把它当作结构体变量内存的开始):
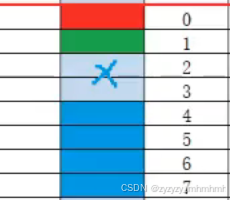
然后我们会发现,其中2,3所对应的内存单元是空的,所以在最开始的时候我们可以看到那个8个字节的结果。同理也可以验证struct s2的情况。了解了对齐的规则,接下来我们来了解一下,对齐的具体内容。
<1>对齐规则

在第二条中,所谓的整数倍的地址处,其实就是找偏移量为整数倍的地方,等一下再举例来解释,结构体的总大小取决于第三点。
--->下面举例一下:
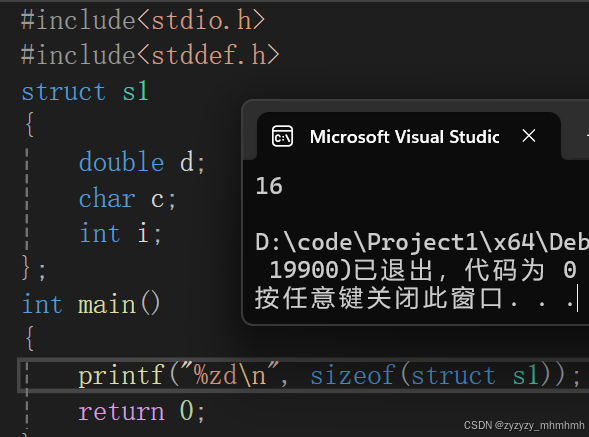
按照上面规则来分析:
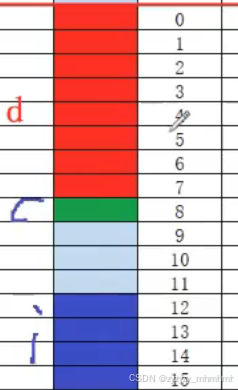
如何解释上面这张图呢,第一个成员为double,有8个字节,所以从偏移数为0的位置开始,如何在是第二个成员,char字节为1如果默认对齐数是8(当前为vs环境),所以对齐数是1,1的倍数是8,就接着上一个成员开始,然后到最后一个成员,由规则看可以知道,对齐数是4,如何找作为4的倍数的偏移位就是12,如何开始往下四个字节。显然的是中间的8,10,11偏移位这三个字节的大小被我们浪费掉了。
在所有的对齐数中,最大的是double的对齐数为8,所以最终结果为8的倍数,所以上述图中的16个字节就是最终答案。
--->现在来举例一下第四种情况:
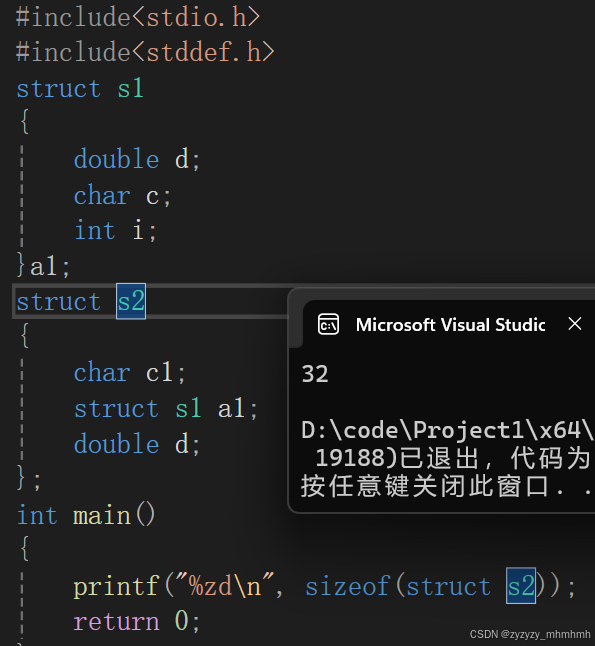
下面根据规则4来解释为什么struct s2的大小是32个字节:

如图所示,char成员先占据偏移量为0的那个字节,然后到第二个成员,也就是嵌套的那个结构体类型,它需要对齐到自身最大对齐数的整数倍数处,易得其最大对齐数为8,所以这个结构体变量从偏移量为8的位置开始,然后一直向下占据16个字节,最后一个成员double的位置很容易就可以得到,最后是这个结构体类型占据多少字节,它是所有最大对齐数的整数倍数,所以32是正确的,即s2就占据32个字节的大小。
<2>为什么存在内存对齐
以下是大部分参考书的说法:

如果存在对齐的话,那么访问效率会大大提升,所以内存的对齐是十分有必要的。
在设计结构体时,我们既要要求对齐,又要节省空间,我们可以:起让占用空间小的成员尽量放在一起,这样就可以更有效(并不是等同于小的必须要放在前面)。
<3>修改默认对齐数
在c语言中修改默认对齐数需要使用#pragma pack(num)这个语句来修改默认对齐数。其中的num就是你先要的默认对齐数。注意:一般我们设置默认对齐数也有一定的技巧,一般都设为2的n次方,当然这个n也包含了0在内。
3.结构体传参
和平常的自定义函数类似,在传递的参数是结构体类型的变量时,我们有传值调用和传址调用。
但是在这种前提下,如果我们采用传值调用的方式对结构体变量进行传递,会新创建一个结构体变量,从而占据大量空间(特别是遇到结构体内存较大的情况下)。那么我们会有以下的两个总结。
<1>函数传参的时候,参数是需要压栈的,所以会有时间和空间上的系统开销。
<2>如果传递一个结构体对象的时候结构体过大,参数压栈的系统开销比较大,所以会导致性能的下降。
4.结构体实现位段
<1>什么是位段:
位段的声明和结构体是类似的,有两点不同:
1.位段的成员必须是int,unsigned int,signed int,在c99中位段成员的类型也可以选择其他的类型。
2.位段的成员后面必须有一个冒号和一个数字。
举例如下:

这个代码是什么意思呢,首先要了解位段中的位是比特位的意思,那么这个代码就是让这个int_a的大小只占2个比特位,其余类推。明显的,这是一种节省空间的方法。
<2>位段的内存分配
1. 位段的成员可以是int, unsigned int,signed int 或者是char等类型。
2.位段的空间是按照需要以4个字节或者1个字节来开辟空间的。
<3>位段的跨平台问题

总结:跟结构体相比位段可以达到同样的效果,也可以很好的节省空间,但是有跨平台的问题存在。
<4>位段的应用

<5>位段使用的注意事项


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









