






结构体:不同类型值的集合 数组:同一类型值的集合
一.结构体声明
struct + 结构体类型名
{
成员列表;
}变量列表;
struct tag//struct + 结构体类型名
{
member_list;//结构体成员列表
}varible_list;//变量列表1.变量的创建和初始化
a.变量的创建
结构体类型 + 变量名

b.结构体初始化
可以按顺序初始化,也可以不按顺序初始化
不按顺序初始化就要用到'.'结构体成员访问操作符,通过:变量名.成员名 的形式进行初始化

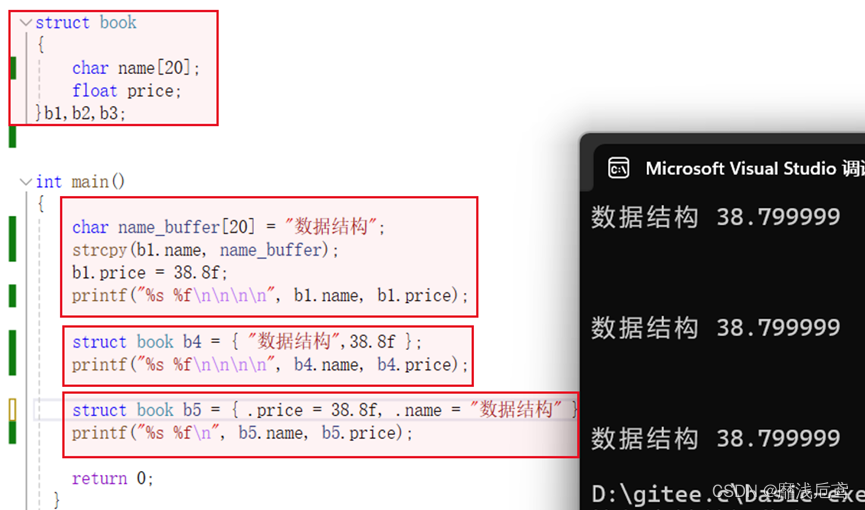
注意:结构体成员中数组的初始化要小心

b1.name是数组名,表示的是数组首元素地址
数组的初始化应该遍历数组进行
strcpy通过拷贝name_buffer中的数据到b1.name指向的数组中,完成对数组的初始化
2.结构的特殊声明(匿名结构体)
在声明结构时可以不完全声明,即省略结构体类型名
匿名结构体只能使用一次,即创建的时候使用

注意:

上面的代码ps = &b1是错误的,为什么?
这是因为匿名结构体没有名字,只能使用一次,即使两个结构体内部成员一样,也是不同类型的结构体,所以ps和&b1类型不兼容
二.结构体自引用
即结构体自己调用自己,有点像递归

上面的代码表示,可以通过struct node访问到数据data,并且通过struct中的struct node* next访问到与data同类型的下一个数据
注意:结构体自引用要小心使用typedef重命名

上面的代码是有问题的:
typedef重命名struct node为ne,要先重命名后才能使用ne,而不是同时重命名同时使用
代码可改为下列所示:

三.结构体大小
1.结构体内存对齐
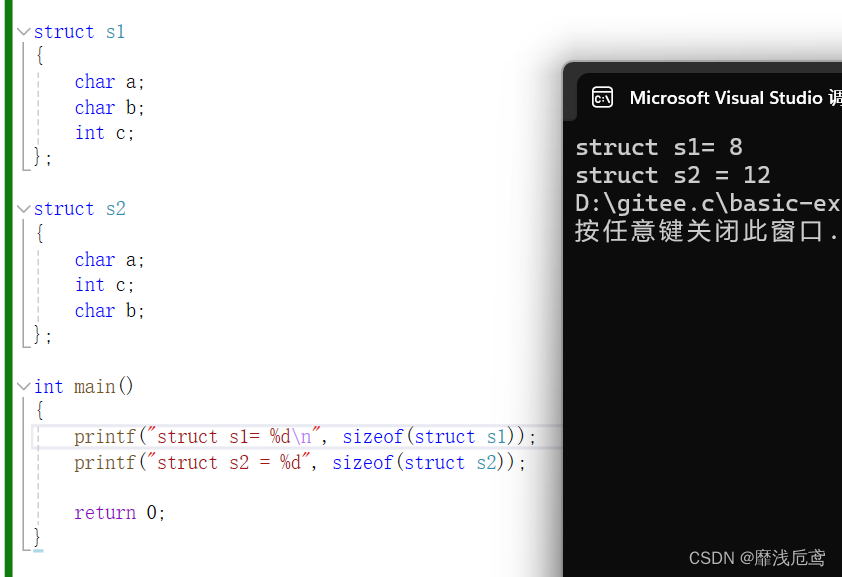
为什么两个结构体的成员类型,数量一样,改变了顺序,他们的大小就不一样了??
这是因为结构体成员在内存中存在对齐现象
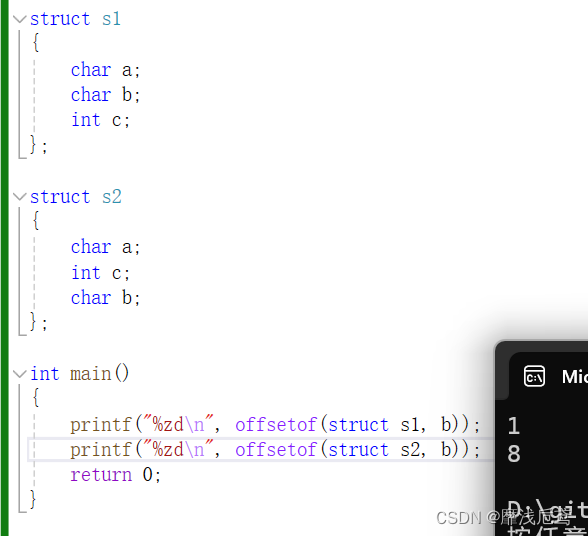
a,offsetof宏,计算结构体成员相较于结构体变量起始位置的偏移量
包含头文件stddef.h

b.对齐规则
结构体第一个成员总是在起始位置(偏移量为0)
其他成员要对齐到某个对齐数的整数倍位置处
对齐数:编译器默认对齐数与该成员大小的较小值
vs默认对齐数为8
linux中的gcc没有默认对齐数,即对齐数大小为结构体成员大小
结构体大小为(所有成员中)最大对齐数的整数倍
c.为什么存在对齐
平台或称移植原因:不是所有硬件平台都能访问任意地址的任意数据
性能原因:数据结构尤其是栈应尽可能地在自然边界上对齐;访问未对齐的内存,处理器可能需要做两次内存访问,而对齐的内存仅需访问一次
d.修改默认对齐数(一般改为二的次方)
#pragma预处理指令

2.结构体传参
结构体变量作为参数传出去
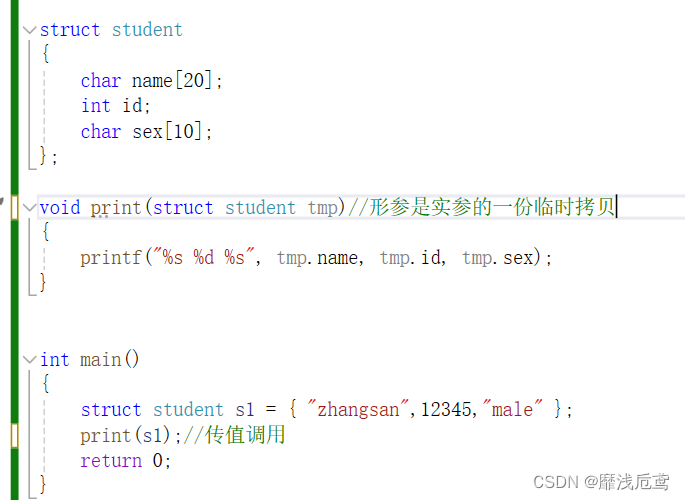

推荐使用传址调用,因为,形参是实参的一份临时拷贝,给函数传参有一个压栈的过程,传的越多新开辟的空间越大,耗时越长
四.结构体实现位段
1.什么是位段
位段的声明和结构体是类似的
位段成员必须是整数家族;c99中也可以使用其他类型
位段成员后面有一个冒号和一个数字
位段中的位指二进制位(bit)

2.位段的内存分配
按照需要以一个字节或者四个字节的方式开辟
位段不跨平台,注重可移植性的程序应避免使用位段
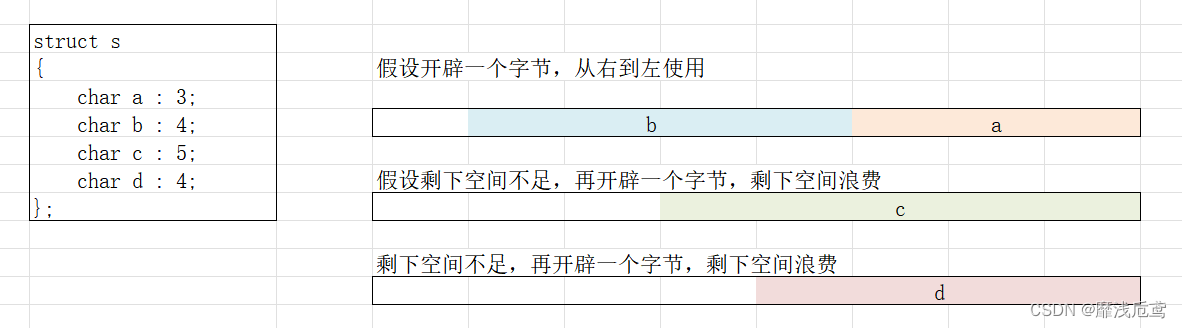
3.位段跨平台问题
int位段被当成有符号数还是无符号数不确定
位段最大数目不确定:
16位机,sizeof(int) = 2Byte
32/64位机,sizeof(int) = 4Byte
开辟的字节从左向右还是从右向左使用不确定
剩下的空间不足以存放下一个成员时,剩下的空间浪费还是使用不确定
4.位段的应用
网络协议中,ip数据报的格式:
数据是需要进行封装才能在网络中的传播,并且要尽可能封装的小,才能在网络中传播得快


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









