







 MiniGPT-4是阿卜杜拉国王科技大学博士开发的开源项目,模仿GPT4的多模态能力,允许文本和图片输入。用户可以通过开源模型生成广告文案等,目前提供在线体验和本地部署选项,尽管由于需求量大可能需要错峰使用或本地运行。
MiniGPT-4是阿卜杜拉国王科技大学博士开发的开源项目,模仿GPT4的多模态能力,允许文本和图片输入。用户可以通过开源模型生成广告文案等,目前提供在线体验和本地部署选项,尽管由于需求量大可能需要错峰使用或本地运行。
hatGPT 的对话能力,想必大家也早已体验过了,无论是文本生成能力,还是写代码的能力,甚至是上下文的关联对话能力,无不一次又一次地震撼着我们。
你还记不记得发布会上,GPT4 的多模态能力吗?输入不仅是可以是文字,还可以是文本和图片。
比如输入:(看图)手套掉下去会怎样?
输出:它会掉到木板上,并且球会被弹飞。

甚至画个网站的草图,GPT4 就可以立马生成网站的 HTML 代码。
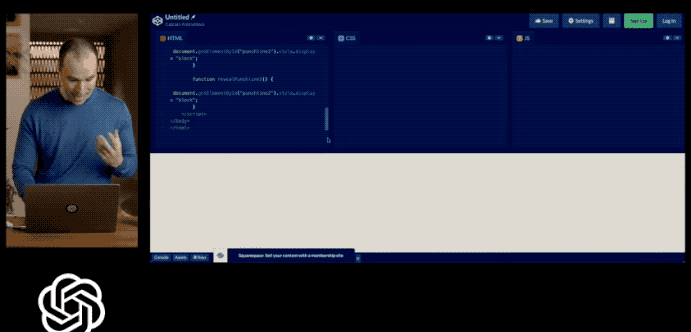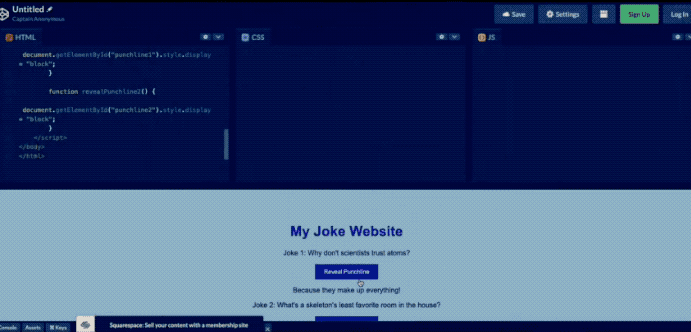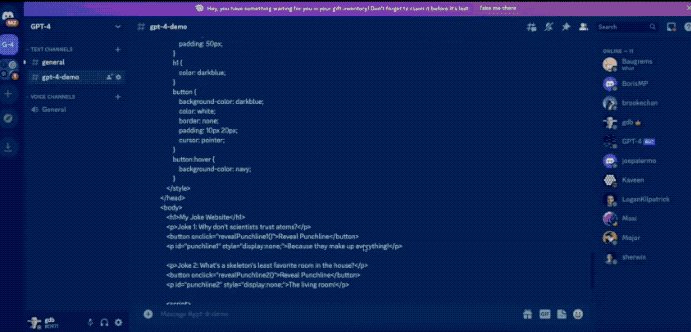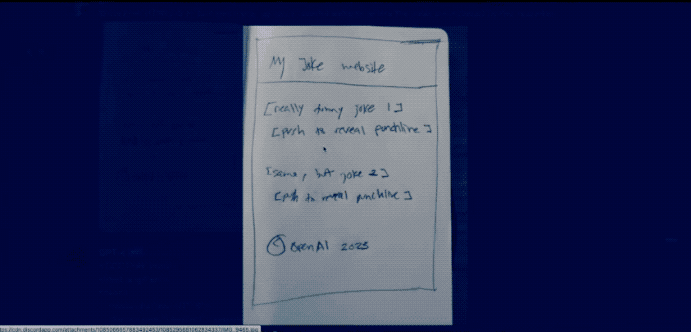
然而,已经过去一个多月了!OpenAI 至今也没有提供发布会所展示的多模态处理能力!
原本以为还要再等几个月的官方更新,才能体验上这个功能,没想到,我看到了这么一个项目。
该项目名为 MiniGPT-4,是阿卜杜拉国王科技大学的几位博士做的。
最主要的是,完全开源!效果如视频所示:
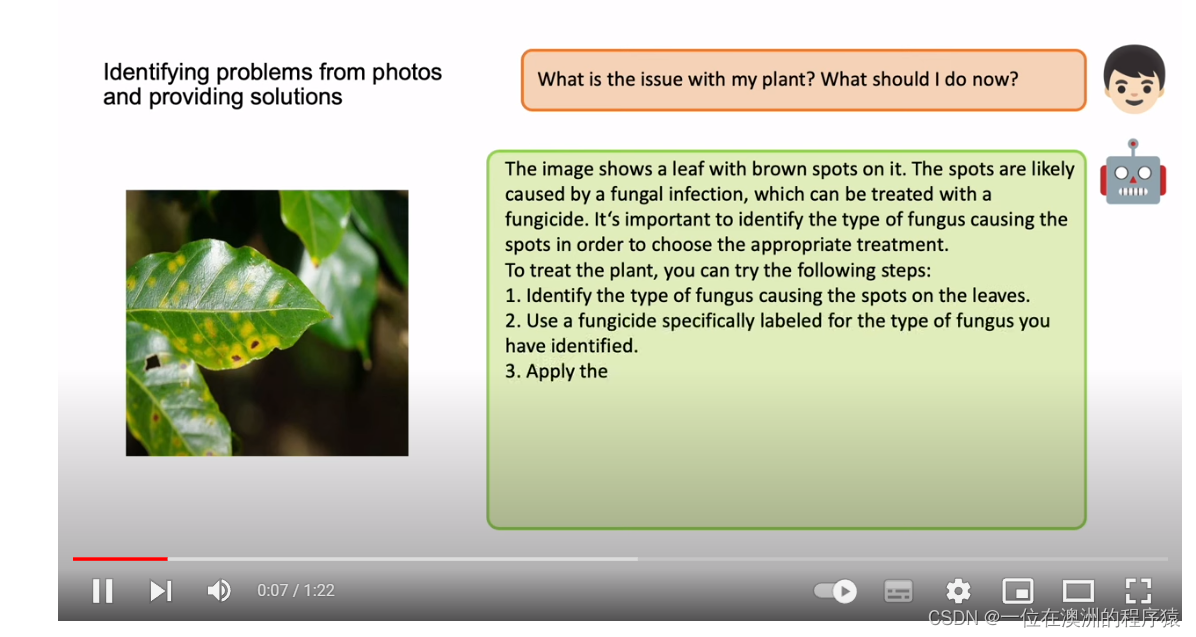
链接在这里:
https://www.youtube.com/watch?v=__tftoxpBAw
可以看到,MiniGPT-4 能够支持文本和图片的输入,实现了多模态的输入功能。
GitHub:https://github.com/Vision-CAIR/MiniGPT-4
在线体验:https://minigpt-4.github.io
作者还提供了网页 Demo,可以直接体验:
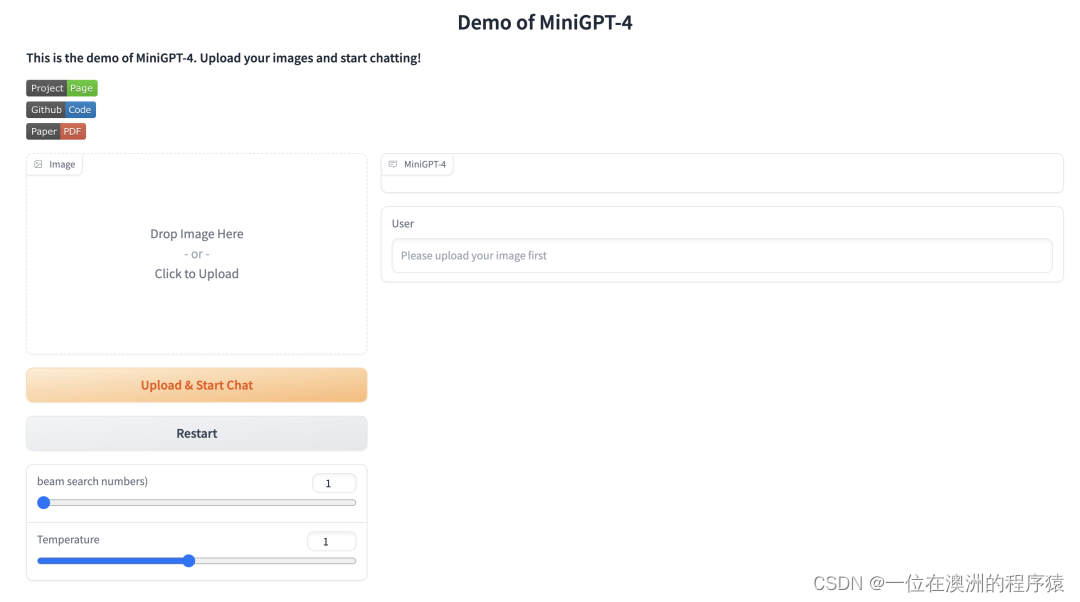 MiniGPT-4 是在一些开源大模型基础上训练得到的,fine tune 分为两个阶段,先是在 4 个 A100 上用 500 万图文对训练,然后再用一个一个小的高质量数据集训练,单卡 A100 训练只需要 7 分钟。
MiniGPT-4 是在一些开源大模型基础上训练得到的,fine tune 分为两个阶段,先是在 4 个 A100 上用 500 万图文对训练,然后再用一个一个小的高质量数据集训练,单卡 A100 训练只需要 7 分钟。
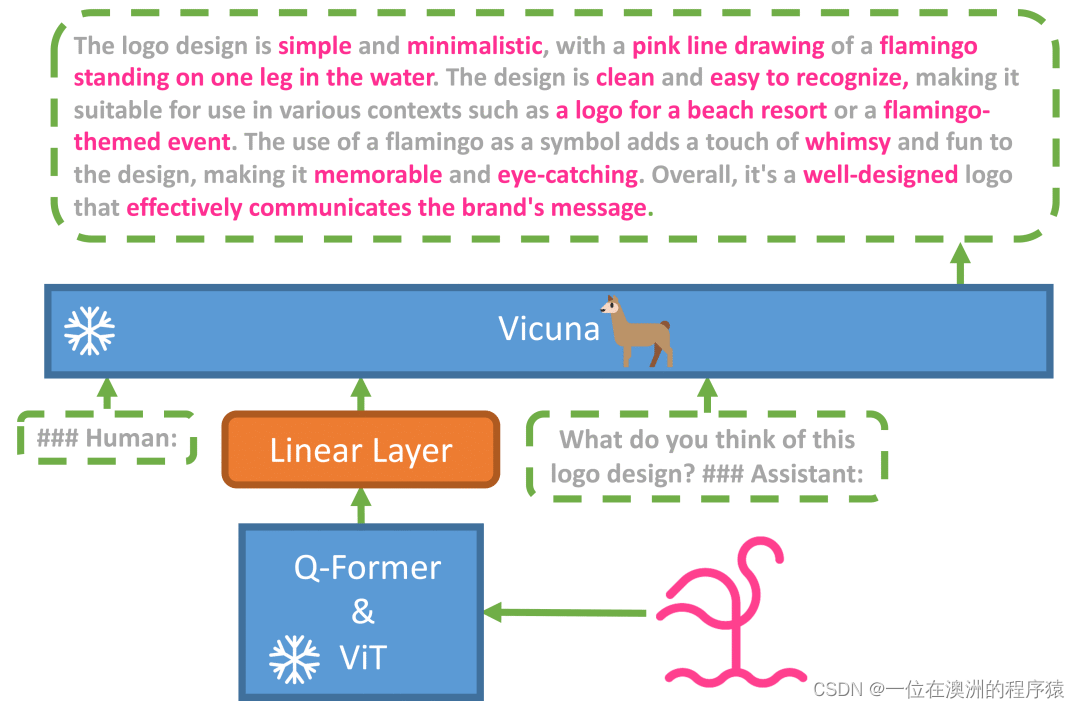
给大家看几个例子:

通过商品图,直接生成广告文案:
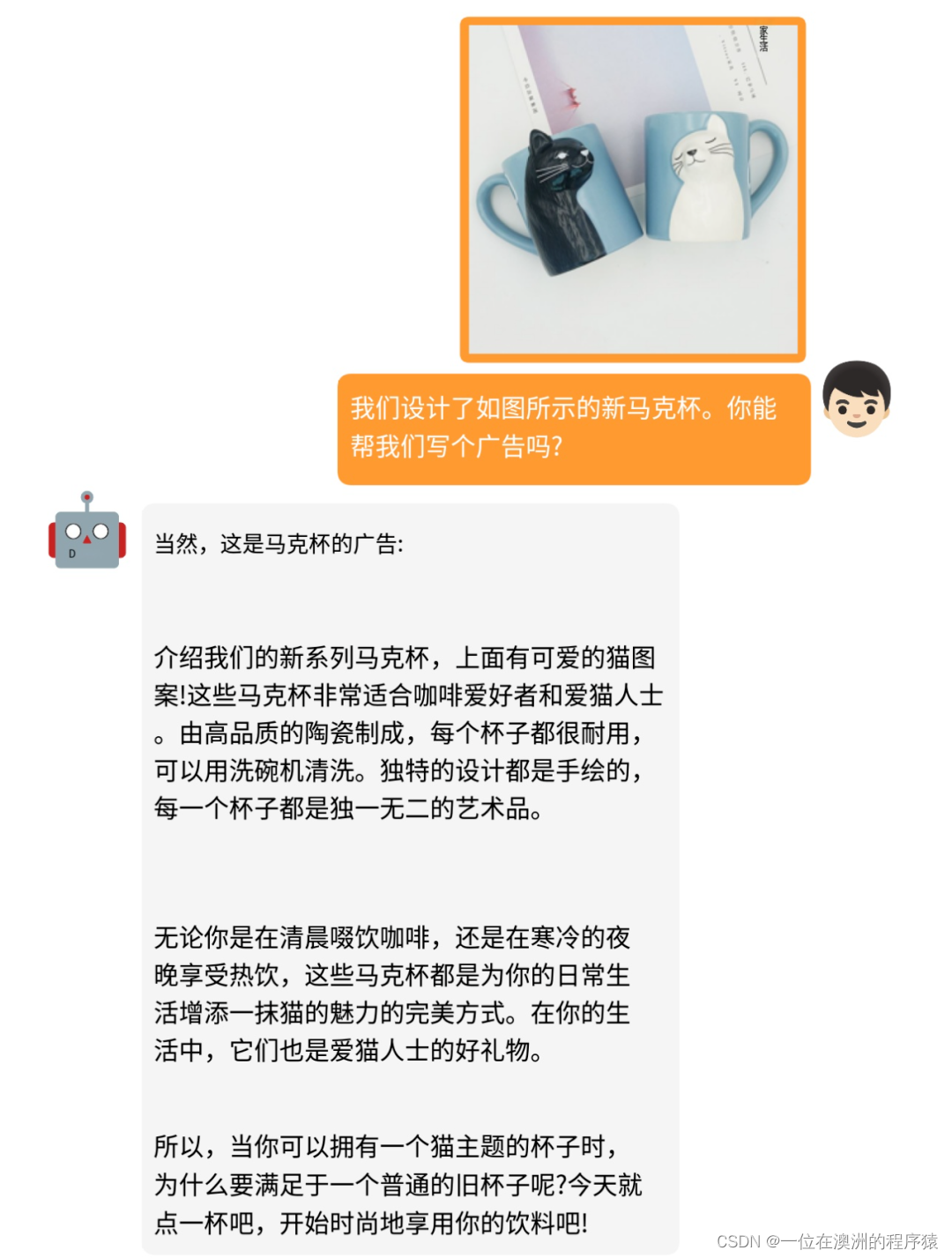
不过目前使用的人数较多,可以错峰使用,或者本地部署一个服务。
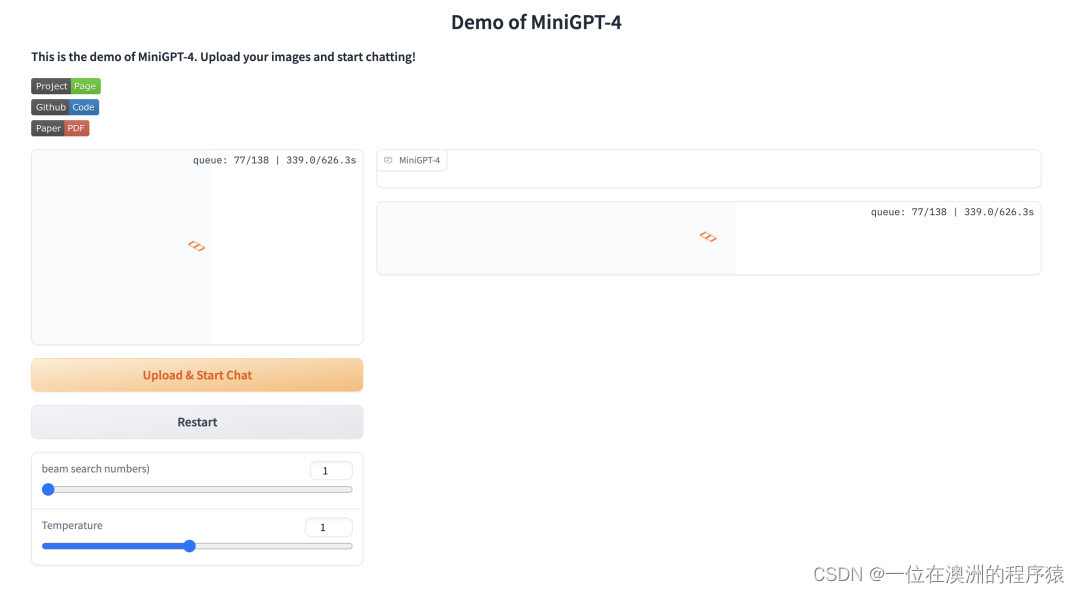
本地部署也不复杂,根据官方教程直接配置环境:
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4然后下载预训练模型:
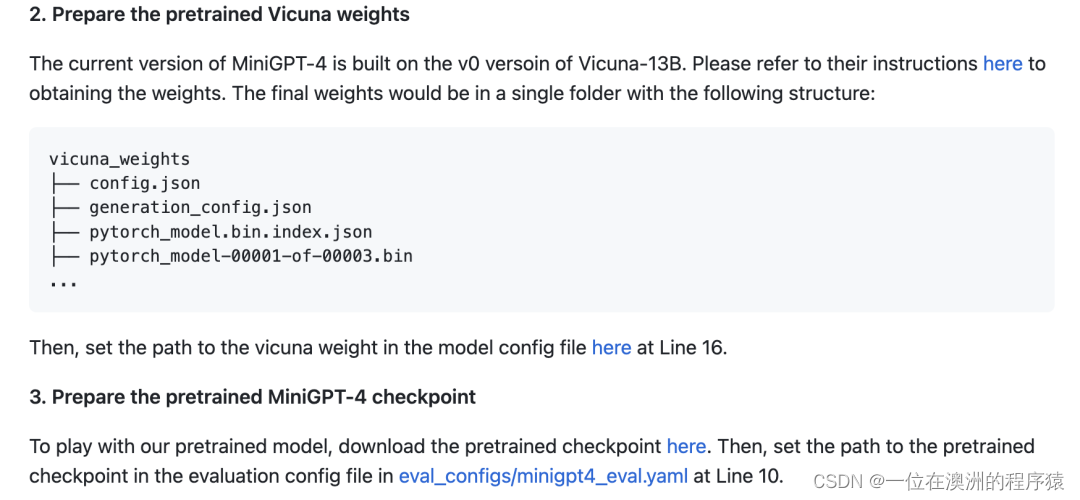
输入指令直接运行:
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml这个过程需要保证有网络,需要下载一些 BLIP 之类的依赖库。
相信不久的将来,不仅仅是可以多模态输入,还可以多模态输出。
我们可以输入:文本、图像、音频、视频
AI 就能根据我们的需求,生成我们需要的文本、图像、音频、甚至是视频。
一起期待一下吧~
今天分享到这里,喜欢的一键三连!

















 5491
5491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









