import requests
import parsel
import time
from datetime import datetime, timedelta
import pandas as pd
import logging
import traceback
import json
import sys
import os
import re
import pandas as pd
import numpy as np
import datetime
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
class App():
def __init__(self):
self.url = 'https://su.lianjia.com/ershoufang/huaqiao/pg' #苏州二手房
self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'}
def get_data_lianjia(self):
response = requests.get(url=self.url,headers=self.headers)
selector = parsel.Selector(response.text)
page_info = selector.css('.contentBottom div')
page_total_list = json.loads(page_info.xpath('.//@page-data').getall()[0])['totalPage']
df_all = pd.DataFrame()
for page in range(1,page_total_list+1):
print('======正在下载第{}页数据======='.format(page))
time.sleep(1)
url_str = self.url + '{}/'.format(page)
response = requests.get(url=url_str, headers=self.headers)
selector = parsel.Selector(response.text)
lis = selector.css('.sellListContent li')
dit={}
for li in lis:
title = li.css('.title a::text').get()
dit['标题'] = title
positionInfo = li.css('.positionInfo a::text').getall()
info = '-'.join(positionInfo)
dit['开发商'] = info
houseInfo = li.css('.houseInfo::text').get()
house_href = li.xpath('.//@href').getall()[2].split(r'/')[4]
dit['小区id'] = house_href
dit['小区名称'] = li.css('.positionInfo a::text').get()
#house_info_list = houseInfo.split('|')
#dit['户型'],dit['面积'],dit['方向'],dit['装修'],dit['楼层'],dit['建筑类型'] = house_info_list[0],house_info_list[1],house_info_list[2],house_info_list[3],house_info_list[4],house_info_list[5]
dit['房子信息'] = houseInfo
followInfo = li.css('.followInfo::text').get()
dit['发布周期'] = followInfo
Price = li.css('.totalPrice span::text').get()
dit['售价/万'] = Price
unitPrice = li.css('.unitPrice span::text').get()
dit['单价'] = unitPrice
df = pd.DataFrame(np.array(list(dit.values())).reshape(1,14),columns=list(dit.keys()))
#print(df)
df_all = pd.concat([df_all,df],axis=0)
#print(df_all)
#time.sleep(10)
#print(df_all)
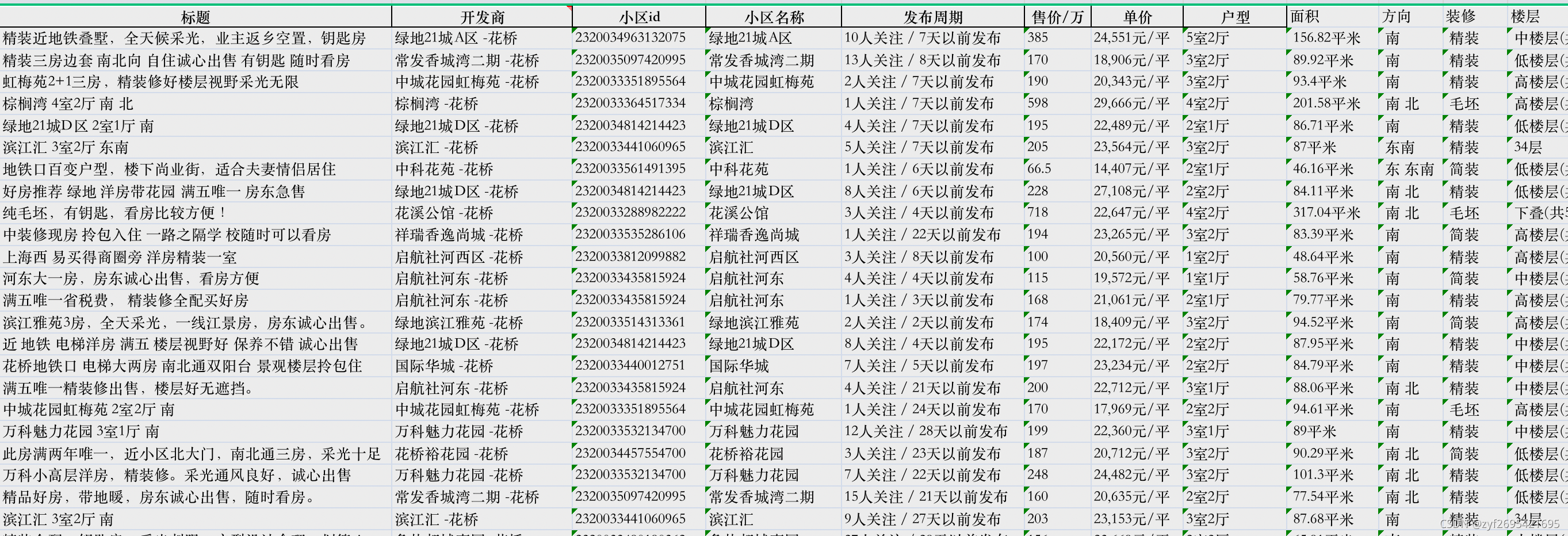
df_all.to_excel('花桥二手房一览_{}.xlsx'.format(datetime.datetime.now().strftime('%Y-%m-%d_%HH:%MM:%SS')),index=True)
if __name__ == '__main__':
app = App()
# cyscreen.return_data()
app.get_data_lianjia()

























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









